 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupernova Event Dataset: Interpreting Large Language Model's Personality through Critical Event Analysis
Jun 13, 2025Large Language Models (LLMs) are increasingly integrated into everyday applications. As their influence grows, understanding their decision making and underlying personality becomes essential. In this work, we interpret model personality using our proposed Supernova Event Dataset, a novel dataset with diverse articles spanning biographies, historical events, news, and scientific discoveries. We use this dataset to benchmark LLMs on extracting and ranking key events from text, a subjective and complex challenge that requires reasoning over long-range context and modeling causal chains. We evaluate small models like Phi-4, Orca 2, and Qwen 2.5, and large, stronger models such as Claude 3.7, Gemini 2.5, and OpenAI o3, and propose a framework where another LLM acts as a judge to infer each model's personality based on its selection and classification of events. Our analysis shows distinct personality traits: for instance, Orca 2 demonstrates emotional reasoning focusing on interpersonal dynamics, while Qwen 2.5 displays a more strategic, analytical style. When analyzing scientific discovery events, Claude Sonnet 3.7 emphasizes conceptual framing, Gemini 2.5 Pro prioritizes empirical validation, and o3 favors step-by-step causal reasoning. This analysis improves model interpretability, making them user-friendly for a wide range of diverse applications.
Empowering Clinicians with Medical Decision Transformers: A Framework for Sepsis Treatment
Jul 28, 2024Offline reinforcement learning has shown promise for solving tasks in safety-critical settings, such as clinical decision support. Its application, however, has been limited by the lack of interpretability and interactivity for clinicians. To address these challenges, we propose the medical decision transformer (MeDT), a novel and versatile framework based on the goal-conditioned reinforcement learning paradigm for sepsis treatment recommendation. MeDT uses the decision transformer architecture to learn a policy for drug dosage recommendation. During offline training, MeDT utilizes collected treatment trajectories to predict administered treatments for each time step, incorporating known treatment outcomes, target acuity scores, past treatment decisions, and current and past medical states. This analysis enables MeDT to capture complex dependencies among a patient's medical history, treatment decisions, outcomes, and short-term effects on stability. Our proposed conditioning uses acuity scores to address sparse reward issues and to facilitate clinician-model interactions, enhancing decision-making. Following training, MeDT can generate tailored treatment recommendations by conditioning on the desired positive outcome (survival) and user-specified short-term stability improvements. We carry out rigorous experiments on data from the MIMIC-III dataset and use off-policy evaluation to demonstrate that MeDT recommends interventions that outperform or are competitive with existing offline reinforcement learning methods while enabling a more interpretable, personalized and clinician-directed approach.
Learning to Play Atari in a World of Tokens
Jun 03, 2024



Model-based reinforcement learning agents utilizing transformers have shown improved sample efficiency due to their ability to model extended context, resulting in more accurate world models. However, for complex reasoning and planning tasks, these methods primarily rely on continuous representations. This complicates modeling of discrete properties of the real world such as disjoint object classes between which interpolation is not plausible. In this work, we introduce discrete abstract representations for transformer-based learning (DART), a sample-efficient method utilizing discrete representations for modeling both the world and learning behavior. We incorporate a transformer-decoder for auto-regressive world modeling and a transformer-encoder for learning behavior by attending to task-relevant cues in the discrete representation of the world model. For handling partial observability, we aggregate information from past time steps as memory tokens. DART outperforms previous state-of-the-art methods that do not use look-ahead search on the Atari 100k sample efficiency benchmark with a median human-normalized score of 0.790 and beats humans in 9 out of 26 games. We release our code at https://pranaval.github.io/DART/.
Transformers in Reinforcement Learning: A Survey
Jul 12, 2023



Transformers have significantly impacted domains like natural language processing, computer vision, and robotics, where they improve performance compared to other neural networks. This survey explores how transformers are used in reinforcement learning (RL), where they are seen as a promising solution for addressing challenges such as unstable training, credit assignment, lack of interpretability, and partial observability. We begin by providing a brief domain overview of RL, followed by a discussion on the challenges of classical RL algorithms. Next, we delve into the properties of the transformer and its variants and discuss the characteristics that make them well-suited to address the challenges inherent in RL. We examine the application of transformers to various aspects of RL, including representation learning, transition and reward function modeling, and policy optimization. We also discuss recent research that aims to enhance the interpretability and efficiency of transformers in RL, using visualization techniques and efficient training strategies. Often, the transformer architecture must be tailored to the specific needs of a given application. We present a broad overview of how transformers have been adapted for several applications, including robotics, medicine, language modeling, cloud computing, and combinatorial optimization. We conclude by discussing the limitations of using transformers in RL and assess their potential for catalyzing future breakthroughs in this field.
Automatic Evaluation of Excavator Operators using Learned Reward Functions
Nov 15, 2022Training novice users to operate an excavator for learning different skills requires the presence of expert teachers. Considering the complexity of the problem, it is comparatively expensive to find skilled experts as the process is time-consuming and requires precise focus. Moreover, since humans tend to be biased, the evaluation process is noisy and will lead to high variance in the final score of different operators with similar skills. In this work, we address these issues and propose a novel strategy for the automatic evaluation of excavator operators. We take into account the internal dynamics of the excavator and the safety criterion at every time step to evaluate the performance. To further validate our approach, we use this score prediction model as a source of reward for a reinforcement learning agent to learn the task of maneuvering an excavator in a simulated environment that closely replicates the real-world dynamics. For a policy learned using these external reward prediction models, our results demonstrate safer solutions following the required dynamic constraints when compared to policy trained with task-based reward functions only, making it one step closer to real-life adoption. For future research, we release our codebase at https://github.com/pranavAL/InvRL_Auto-Evaluate and video results https://drive.google.com/file/d/1jR1otOAu8zrY8mkhUOUZW9jkBOAKK71Z/view?usp=share_link .
Sparse Curriculum Reinforcement Learning for End-to-End Driving
Mar 16, 2021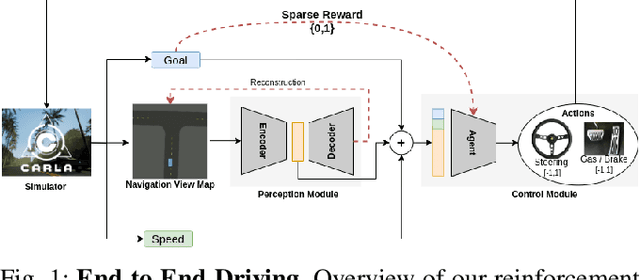
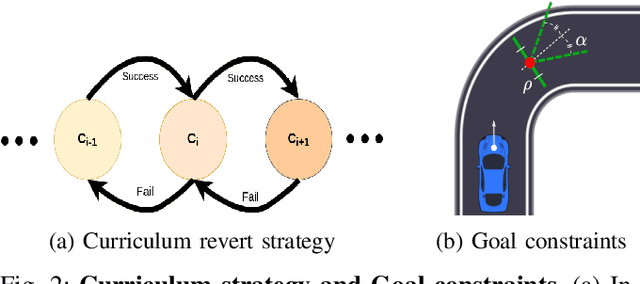
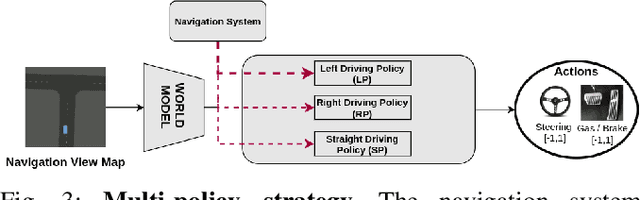
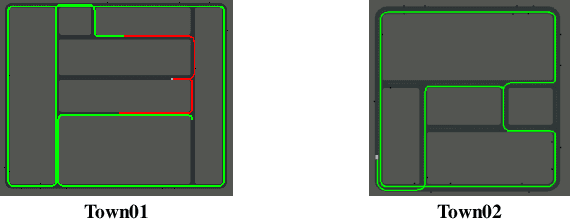
Deep reinforcement Learning for end-to-end driving is limited by the need of complex reward engineering. Sparse rewards can circumvent this challenge but suffers from long training time and leads to sub-optimal policy. In this work, we explore driving using only goal conditioned sparse rewards and propose a curriculum learning approach for end to end driving using only navigation view maps that benefit from small virtual-to-real domain gap. To address the complexity of multiple driving policies, we learn concurrent individual policies which are selected at inference by a navigation system. We demonstrate the ability of our proposal to generalize on unseen road layout, and to drive longer than in the training.
Egoshots, an ego-vision life-logging dataset and semantic fidelity metric to evaluate diversity in image captioning models
Mar 27, 2020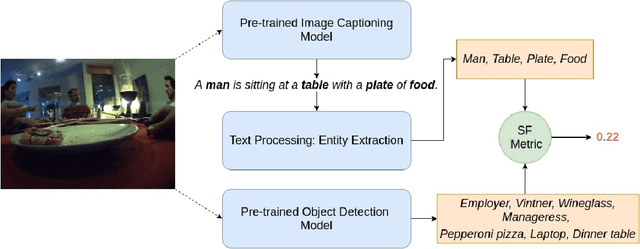

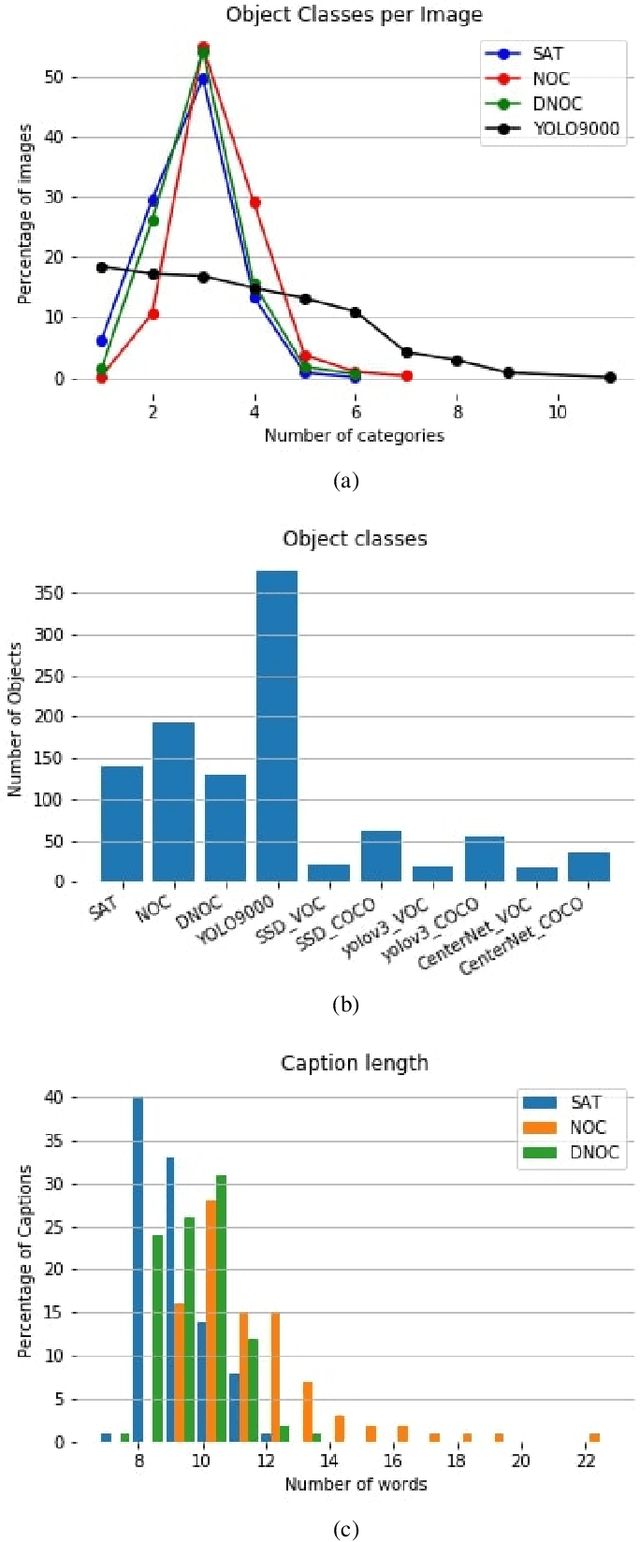
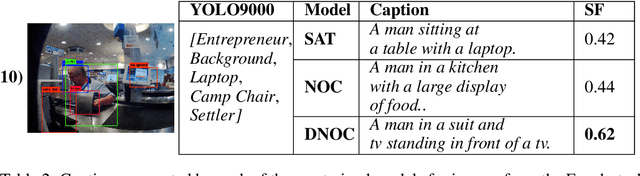
Image captioning models have been able to generate grammatically correct and human understandable sentences. However most of the captions convey limited information as the model used is trained on datasets that do not caption all possible objects existing in everyday life. Due to this lack of prior information most of the captions are biased to only a few objects present in the scene, hence limiting their usage in daily life. In this paper, we attempt to show the biased nature of the currently existing image captioning models and present a new image captioning dataset, Egoshots, consisting of 978 real life images with no captions. We further exploit the state of the art pre-trained image captioning and object recognition networks to annotate our images and show the limitations of existing works. Furthermore, in order to evaluate the quality of the generated captions, we propose a new image captioning metric, object based Semantic Fidelity (SF). Existing image captioning metrics can evaluate a caption only in the presence of their corresponding annotations; however, SF allows evaluating captions generated for images without annotations, making it highly useful for real life generated captions.