 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrasp Diffusion Network: Learning Grasp Generators from Partial Point Clouds with Diffusion Models in SO(3)xR3
Dec 11, 2024



Grasping objects successfully from a single-view camera is crucial in many robot manipulation tasks. An approach to solve this problem is to leverage simulation to create large datasets of pairs of objects and grasp poses, and then learn a conditional generative model that can be prompted quickly during deployment. However, the grasp pose data is highly multimodal since there are several ways to grasp an object. Hence, in this work, we learn a grasp generative model with diffusion models to sample candidate grasp poses given a partial point cloud of an object. A novel aspect of our method is to consider diffusion in the manifold space of rotations and to propose a collision-avoidance cost guidance to improve the grasp success rate during inference. To accelerate grasp sampling we use recent techniques from the diffusion literature to achieve faster inference times. We show in simulation and real-world experiments that our approach can grasp several objects from raw depth images with $90\%$ success rate and benchmark it against several baselines.
ActionFlow: Equivariant, Accurate, and Efficient Policies with Spatially Symmetric Flow Matching
Sep 06, 2024



Spatial understanding is a critical aspect of most robotic tasks, particularly when generalization is important. Despite the impressive results of deep generative models in complex manipulation tasks, the absence of a representation that encodes intricate spatial relationships between observations and actions often limits spatial generalization, necessitating large amounts of demonstrations. To tackle this problem, we introduce a novel policy class, ActionFlow. ActionFlow integrates spatial symmetry inductive biases while generating expressive action sequences. On the representation level, ActionFlow introduces an SE(3) Invariant Transformer architecture, which enables informed spatial reasoning based on the relative SE(3) poses between observations and actions. For action generation, ActionFlow leverages Flow Matching, a state-of-the-art deep generative model known for generating high-quality samples with fast inference - an essential property for feedback control. In combination, ActionFlow policies exhibit strong spatial and locality biases and SE(3)-equivariant action generation. Our experiments demonstrate the effectiveness of ActionFlow and its two main components on several simulated and real-world robotic manipulation tasks and confirm that we can obtain equivariant, accurate, and efficient policies with spatially symmetric flow matching. Project website: https://flowbasedpolicies.github.io/
Motion Planning Diffusion: Learning and Planning of Robot Motions with Diffusion Models
Aug 03, 2023Learning priors on trajectory distributions can help accelerate robot motion planning optimization. Given previously successful plans, learning trajectory generative models as priors for a new planning problem is highly desirable. Prior works propose several ways on utilizing this prior to bootstrapping the motion planning problem. Either sampling the prior for initializations or using the prior distribution in a maximum-a-posterior formulation for trajectory optimization. In this work, we propose learning diffusion models as priors. We then can sample directly from the posterior trajectory distribution conditioned on task goals, by leveraging the inverse denoising process of diffusion models. Furthermore, diffusion has been recently shown to effectively encode data multimodality in high-dimensional settings, which is particularly well-suited for large trajectory dataset. To demonstrate our method efficacy, we compare our proposed method - Motion Planning Diffusion - against several baselines in simulated planar robot and 7-dof robot arm manipulator environments. To assess the generalization capabilities of our method, we test it in environments with previously unseen obstacles. Our experiments show that diffusion models are strong priors to encode high-dimensional trajectory distributions of robot motions.
Diminishing Return of Value Expansion Methods in Model-Based Reinforcement Learning
Mar 07, 2023



Model-based reinforcement learning is one approach to increase sample efficiency. However, the accuracy of the dynamics model and the resulting compounding error over modelled trajectories are commonly regarded as key limitations. A natural question to ask is: How much more sample efficiency can be gained by improving the learned dynamics models? Our paper empirically answers this question for the class of model-based value expansion methods in continuous control problems. Value expansion methods should benefit from increased model accuracy by enabling longer rollout horizons and better value function approximations. Our empirical study, which leverages oracle dynamics models to avoid compounding model errors, shows that (1) longer horizons increase sample efficiency, but the gain in improvement decreases with each additional expansion step, and (2) the increased model accuracy only marginally increases the sample efficiency compared to learned models with identical horizons. Therefore, longer horizons and increased model accuracy yield diminishing returns in terms of sample efficiency. These improvements in sample efficiency are particularly disappointing when compared to model-free value expansion methods. Even though they introduce no computational overhead, we find their performance to be on-par with model-based value expansion methods. Therefore, we conclude that the limitation of model-based value expansion methods is not the model accuracy of the learned models. While higher model accuracy is beneficial, our experiments show that even a perfect model will not provide an un-rivalled sample efficiency but that the bottleneck lies elsewhere.
A Hierarchical Approach to Active Pose Estimation
Mar 08, 2022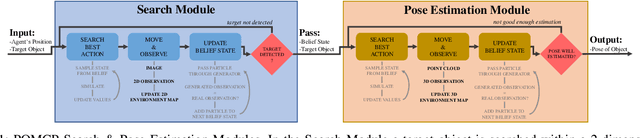
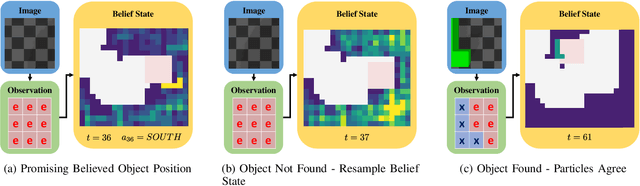
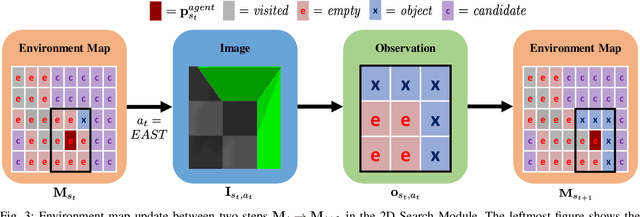
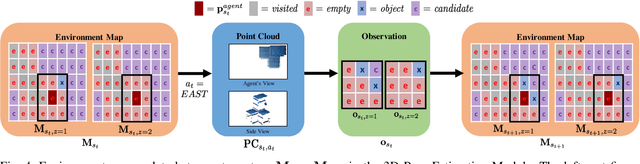
Creating mobile robots which are able to find and manipulate objects in large environments is an active topic of research. These robots not only need to be capable of searching for specific objects but also to estimate their poses often relying on environment observations, which is even more difficult in the presence of occlusions. Therefore, to tackle this problem we propose a simple hierarchical approach to estimate the pose of a desired object. An Active Visual Search module operating with RGB images first obtains a rough estimation of the object 2D pose, followed by a more computationally expensive Active Pose Estimation module using point cloud data. We empirically show that processing image features to obtain a richer observation speeds up the search and pose estimation computations, in comparison to a binary decision that indicates whether the object is or not in the current image.
Residual Robot Learning for Object-Centric Probabilistic Movement Primitives
Mar 08, 2022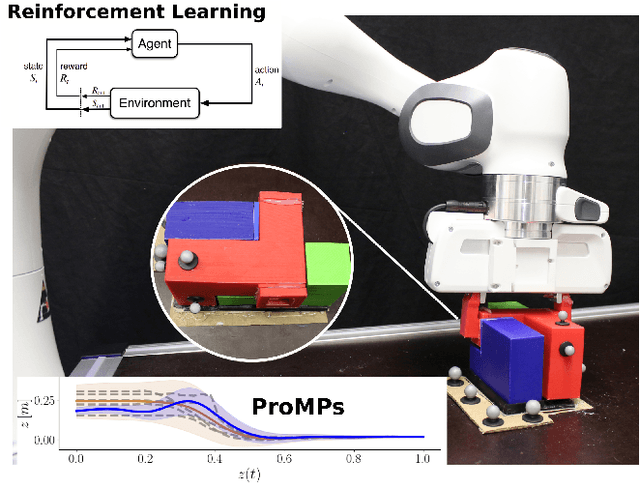
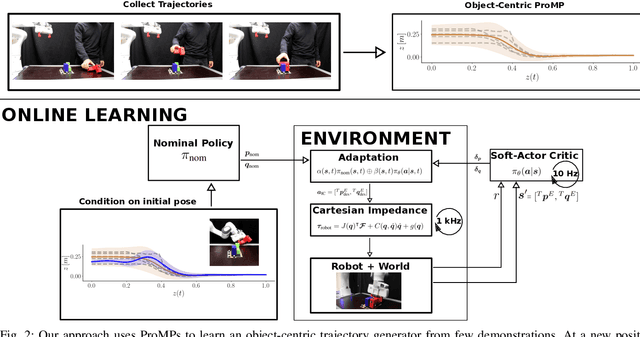
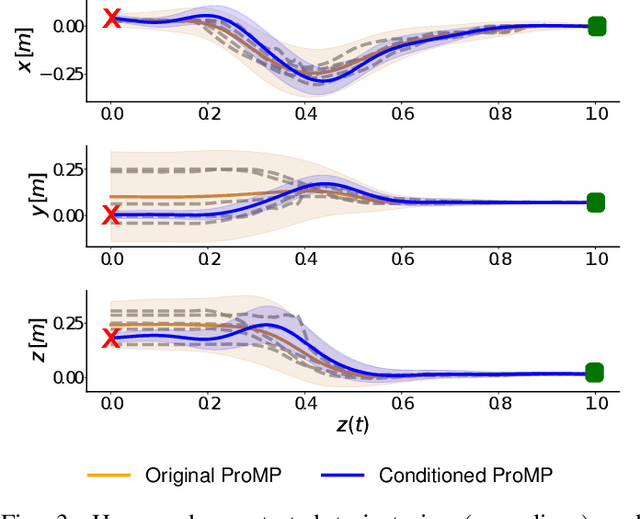

It is desirable for future robots to quickly learn new tasks and adapt learned skills to constantly changing environments. To this end, Probabilistic Movement Primitives (ProMPs) have shown to be a promising framework to learn generalizable trajectory generators from distributions over demonstrated trajectories. However, in practical applications that require high precision in the manipulation of objects, the accuracy of ProMPs is often insufficient, in particular when they are learned in cartesian space from external observations and executed with limited controller gains. Therefore, we propose to combine ProMPs with recently introduced Residual Reinforcement Learning (RRL), to account for both, corrections in position and orientation during task execution. In particular, we learn a residual on top of a nominal ProMP trajectory with Soft-Actor Critic and incorporate the variability in the demonstrations as a decision variable to reduce the search space for RRL. As a proof of concept, we evaluate our proposed method on a 3D block insertion task with a 7-DoF Franka Emika Panda robot. Experimental results show that the robot successfully learns to complete the insertion which was not possible before with using basic ProMPs.
An Analysis of Measure-Valued Derivatives for Policy Gradients
Mar 08, 2022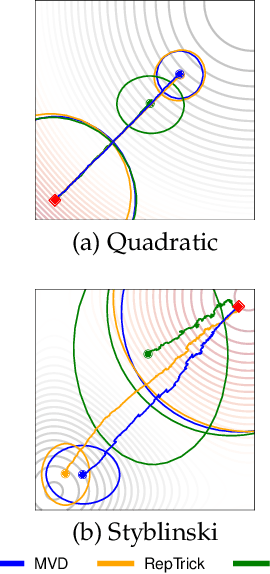
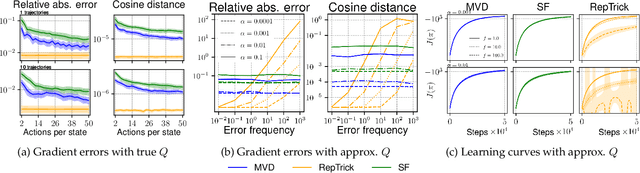
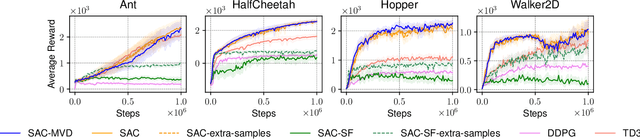
Reinforcement learning methods for robotics are increasingly successful due to the constant development of better policy gradient techniques. A precise (low variance) and accurate (low bias) gradient estimator is crucial to face increasingly complex tasks. Traditional policy gradient algorithms use the likelihood-ratio trick, which is known to produce unbiased but high variance estimates. More modern approaches exploit the reparametrization trick, which gives lower variance gradient estimates but requires differentiable value function approximators. In this work, we study a different type of stochastic gradient estimator - the Measure-Valued Derivative. This estimator is unbiased, has low variance, and can be used with differentiable and non-differentiable function approximators. We empirically evaluate this estimator in the actor-critic policy gradient setting and show that it can reach comparable performance with methods based on the likelihood-ratio or reparametrization tricks, both in low and high-dimensional action spaces. With this work, we want to show that the Measure-Valued Derivative estimator can be a useful alternative to other policy gradient estimators.
A Nonparametric Off-Policy Policy Gradient
Feb 11, 2020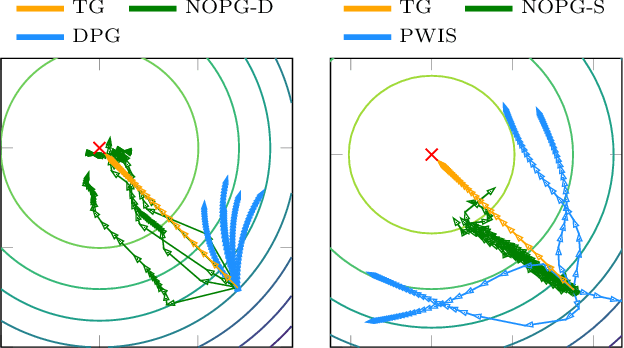

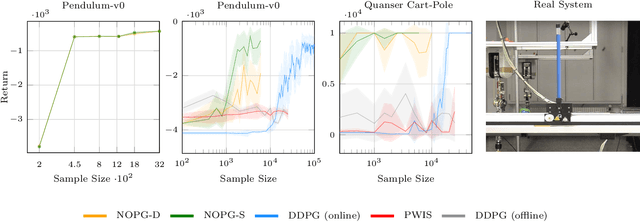
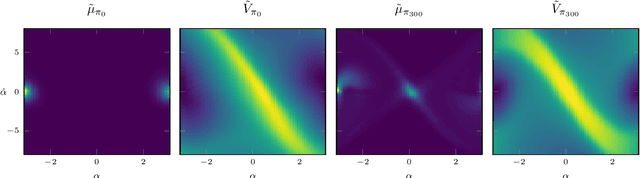
Reinforcement learning (RL) algorithms still suffer from high sample complexity despite outstanding recent successes. The need for intensive interactions with the environment is especially observed in many widely popular policy gradient algorithms that perform updates using on-policy samples. The price of such inefficiency becomes evident in real-world scenarios such as interaction-driven robot learning, where the success of RL has been rather limited. We address this issue by building on the general sample efficiency of off-policy algorithms. With nonparametric regression and density estimation methods we construct a nonparametric Bellman equation in a principled manner, which allows us to obtain closed-form estimates of the value function, and to analytically express the full policy gradient. We provide a theoretical analysis of our estimate to show that it is consistent under mild smoothness assumptions and empirically show that our approach has better sample efficiency than state-of-the-art policy gradient methods.