 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent Convolutional Models
Nov 02, 2018

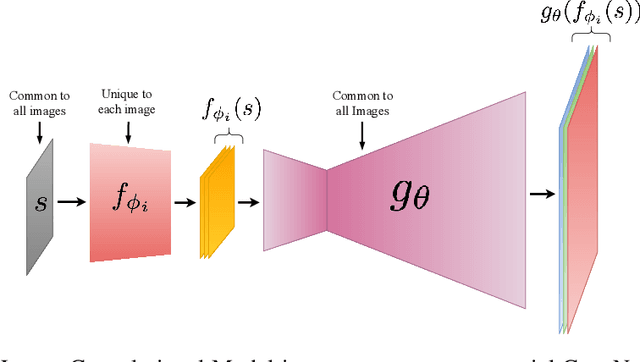
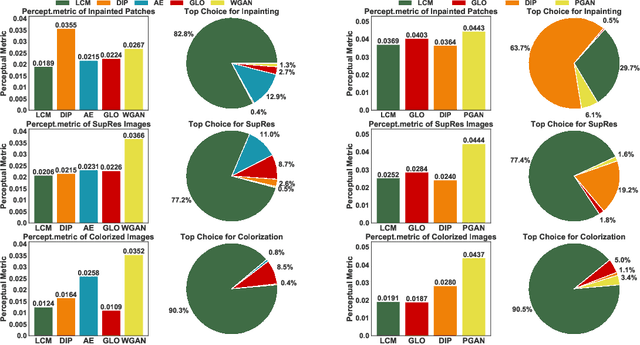
We present a new latent model of natural images that can be learned on large-scale datasets. The learning process provides a latent embedding for every image in the training dataset, as well as a deep convolutional network that maps the latent space to the image space. After training, the new model provides a strong and universal image prior for a variety of image restoration tasks such as large-hole inpainting, superresolution, and colorization. To model high-resolution natural images, our approach uses latent spaces of very high dimensionality (one to two orders of magnitude higher than previous latent image models). To tackle this high dimensionality, we use latent spaces with a special manifold structure (convolutional manifolds) parameterized by a ConvNet of a certain architecture. In the experiments, we compare the learned latent models with latent models learned by autoencoders, advanced variants of generative adversarial networks, and a strong baseline system using simpler parameterization of the latent space. Our model outperforms the competing approaches over a range of restoration tasks.
Image Manipulation with Perceptual Discriminators
Sep 05, 2018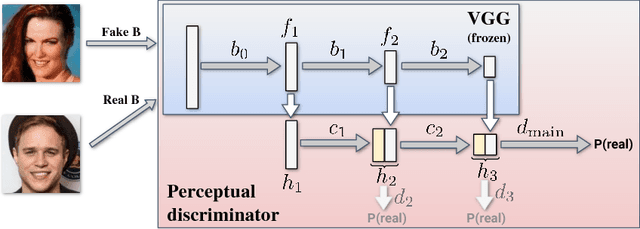
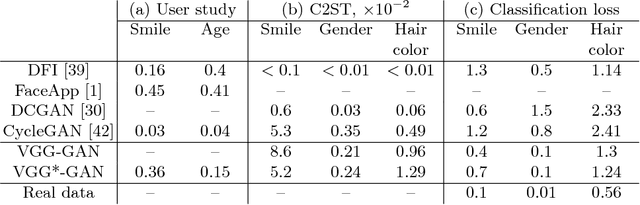


Systems that perform image manipulation using deep convolutional networks have achieved remarkable realism. Perceptual losses and losses based on adversarial discriminators are the two main classes of learning objectives behind these advances. In this work, we show how these two ideas can be combined in a principled and non-additive manner for unaligned image translation tasks. This is accomplished through a special architecture of the discriminator network inside generative adversarial learning framework. The new architecture, that we call a perceptual discriminator, embeds the convolutional parts of a pre-trained deep classification network inside the discriminator network. The resulting architecture can be trained on unaligned image datasets while benefiting from the robustness and efficiency of perceptual losses. We demonstrate the merits of the new architecture in a series of qualitative and quantitative comparisons with baseline approaches and state-of-the-art frameworks for unaligned image translation.
Instance Segmentation by Deep Coloring
Jul 26, 2018
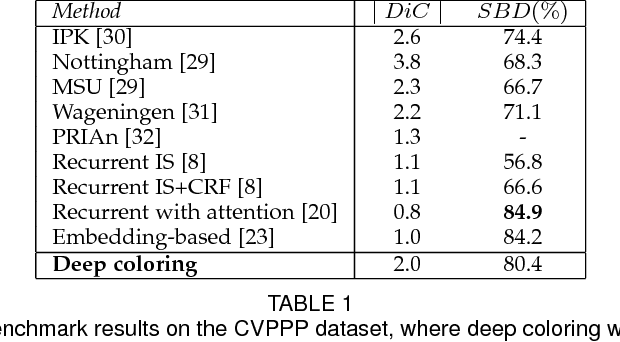


We propose a new and, arguably, a very simple reduction of instance segmentation to semantic segmentation. This reduction allows to train feed-forward non-recurrent deep instance segmentation systems in an end-to-end fashion using architectures that have been proposed for semantic segmentation. Our approach proceeds by introducing a fixed number of labels (colors) and then dynamically assigning object instances to those labels during training (coloring). A standard semantic segmentation objective is then used to train a network that can color previously unseen images. At test time, individual object instances can be recovered from the output of the trained convolutional network using simple connected component analysis. In the experimental validation, the coloring approach is shown to be capable of solving diverse instance segmentation tasks arising in autonomous driving (the Cityscapes benchmark), plant phenotyping (the CVPPP leaf segmentation challenge), and high-throughput microscopy image analysis. The source code is publicly available: https://github.com/kulikovv/DeepColoring.
Impostor Networks for Fast Fine-Grained Recognition
Jun 13, 2018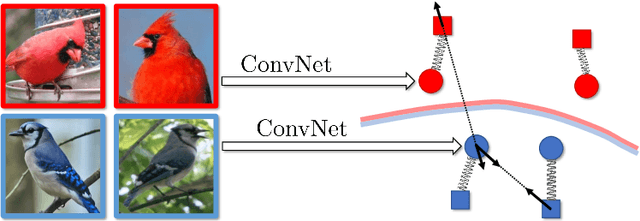
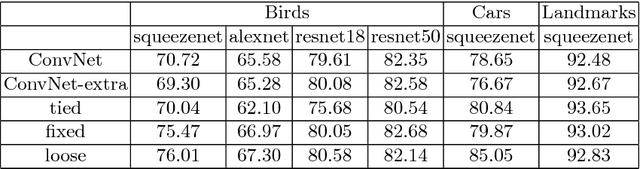
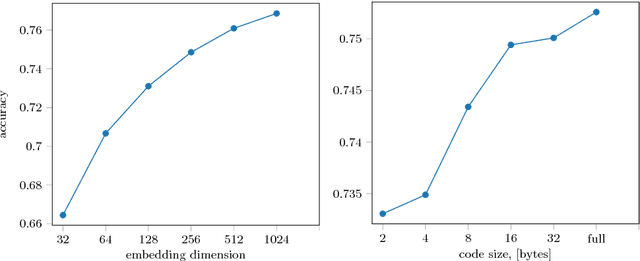
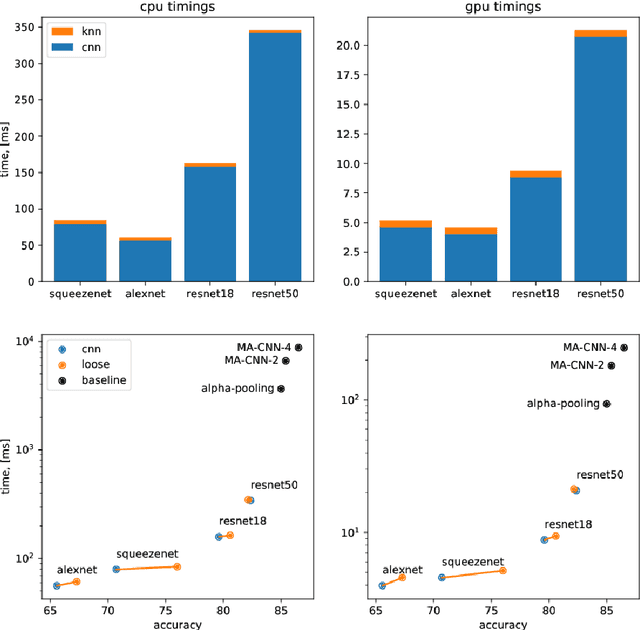
In this work we introduce impostor networks, an architecture that allows to perform fine-grained recognition with high accuracy and using a light-weight convolutional network, making it particularly suitable for fine-grained applications on low-power and non-GPU enabled platforms. Impostor networks compensate for the lightness of its `backend' network by combining it with a lightweight non-parametric classifier. The combination of a convolutional network and such non-parametric classifier is trained in an end-to-end fashion. Similarly to convolutional neural networks, impostor networks can fit large-scale training datasets very well, while also being able to generalize to new data points. At the same time, the bulk of computations within impostor networks happen through nearest neighbor search in high-dimensions. Such search can be performed efficiently on a variety of architectures including standard CPUs, where deep convolutional networks are inefficient. In a series of experiments with three fine-grained datasets, we show that impostor networks are able to boost the classification accuracy of a moderate-sized convolutional network considerably at a very small computational cost.
Deep Image Prior
Apr 05, 2018

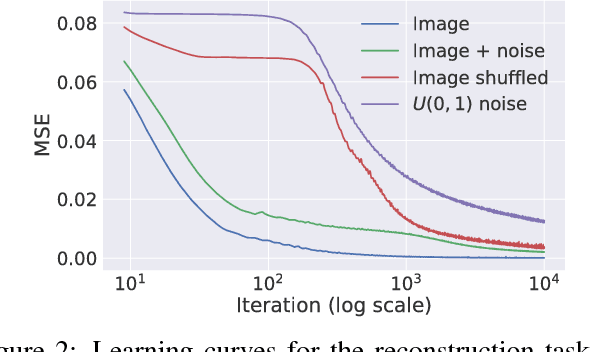
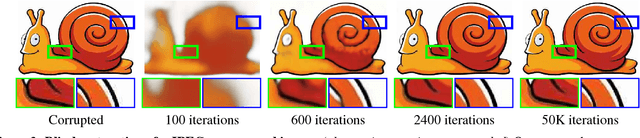
Deep convolutional networks have become a popular tool for image generation and restoration. Generally, their excellent performance is imputed to their ability to learn realistic image priors from a large number of example images. In this paper, we show that, on the contrary, the structure of a generator network is sufficient to capture a great deal of low-level image statistics prior to any learning. In order to do so, we show that a randomly-initialized neural network can be used as a handcrafted prior with excellent results in standard inverse problems such as denoising, super-resolution, and inpainting. Furthermore, the same prior can be used to invert deep neural representations to diagnose them, and to restore images based on flash-no flash input pairs. Apart from its diverse applications, our approach highlights the inductive bias captured by standard generator network architectures. It also bridges the gap between two very popular families of image restoration methods: learning-based methods using deep convolutional networks and learning-free methods based on handcrafted image priors such as self-similarity. Code and supplementary material are available at https://dmitryulyanov.github.io/deep_image_prior .
It Takes (Only) Two: Adversarial Generator-Encoder Networks
Nov 06, 2017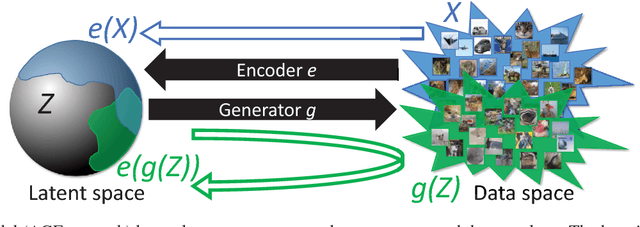



We present a new autoencoder-type architecture that is trainable in an unsupervised mode, sustains both generation and inference, and has the quality of conditional and unconditional samples boosted by adversarial learning. Unlike previous hybrids of autoencoders and adversarial networks, the adversarial game in our approach is set up directly between the encoder and the generator, and no external mappings are trained in the process of learning. The game objective compares the divergences of each of the real and the generated data distributions with the prior distribution in the latent space. We show that direct generator-vs-encoder game leads to a tight coupling of the two components, resulting in samples and reconstructions of a comparable quality to some recently-proposed more complex architectures.
Improved Texture Networks: Maximizing Quality and Diversity in Feed-forward Stylization and Texture Synthesis
Nov 06, 2017

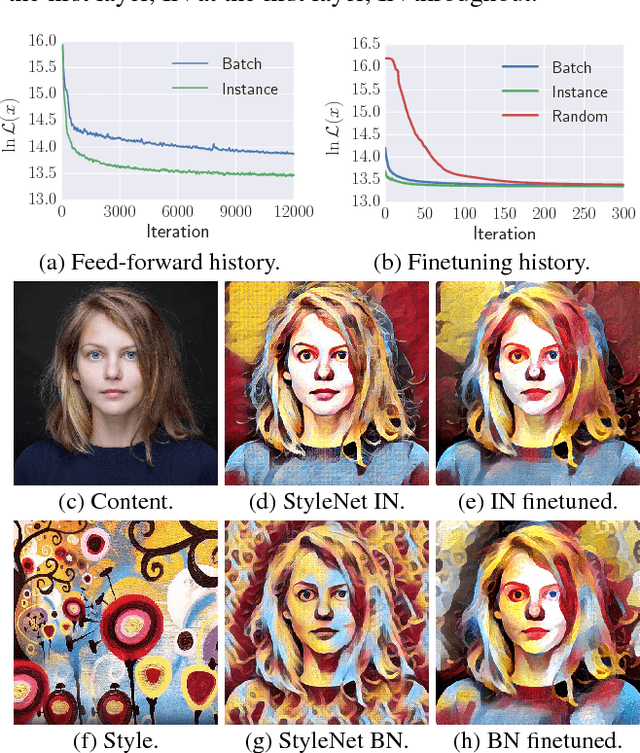

The recent work of Gatys et al., who characterized the style of an image by the statistics of convolutional neural network filters, ignited a renewed interest in the texture generation and image stylization problems. While their image generation technique uses a slow optimization process, recently several authors have proposed to learn generator neural networks that can produce similar outputs in one quick forward pass. While generator networks are promising, they are still inferior in visual quality and diversity compared to generation-by-optimization. In this work, we advance them in two significant ways. First, we introduce an instance normalization module to replace batch normalization with significant improvements to the quality of image stylization. Second, we improve diversity by introducing a new learning formulation that encourages generators to sample unbiasedly from the Julesz texture ensemble, which is the equivalence class of all images characterized by certain filter responses. Together, these two improvements take feed forward texture synthesis and image stylization much closer to the quality of generation-via-optimization, while retaining the speed advantage.
Instance Normalization: The Missing Ingredient for Fast Stylization
Nov 06, 2017



It this paper we revisit the fast stylization method introduced in Ulyanov et. al. (2016). We show how a small change in the stylization architecture results in a significant qualitative improvement in the generated images. The change is limited to swapping batch normalization with instance normalization, and to apply the latter both at training and testing times. The resulting method can be used to train high-performance architectures for real-time image generation. The code will is made available on github at https://github.com/DmitryUlyanov/texture_nets. Full paper can be found at arXiv:1701.02096.
Large-Scale 3D Shape Reconstruction and Segmentation from ShapeNet Core55
Oct 27, 2017
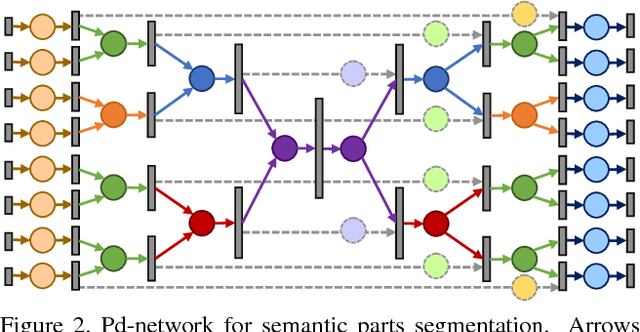
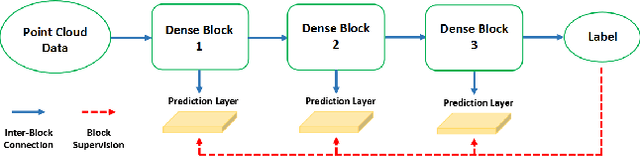
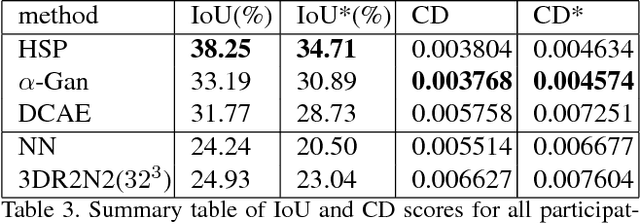
We introduce a large-scale 3D shape understanding benchmark using data and annotation from ShapeNet 3D object database. The benchmark consists of two tasks: part-level segmentation of 3D shapes and 3D reconstruction from single view images. Ten teams have participated in the challenge and the best performing teams have outperformed state-of-the-art approaches on both tasks. A few novel deep learning architectures have been proposed on various 3D representations on both tasks. We report the techniques used by each team and the corresponding performances. In addition, we summarize the major discoveries from the reported results and possible trends for the future work in the field.
Escape from Cells: Deep Kd-Networks for the Recognition of 3D Point Cloud Models
Oct 26, 2017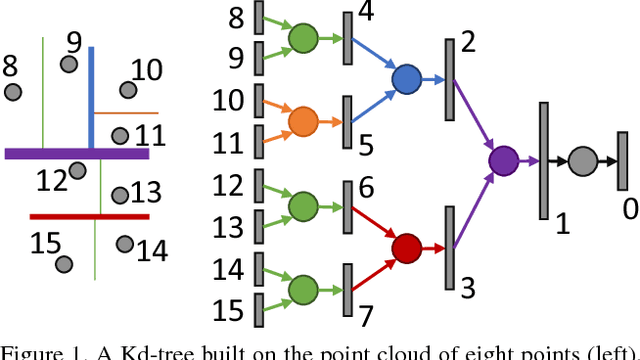
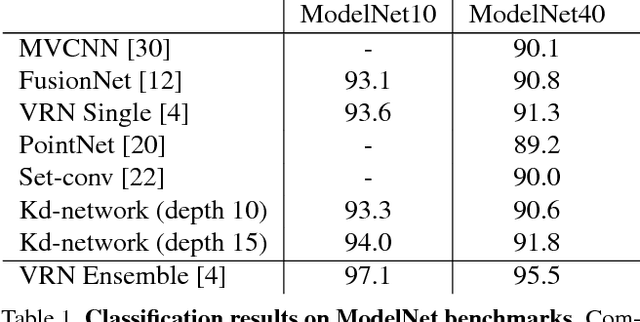
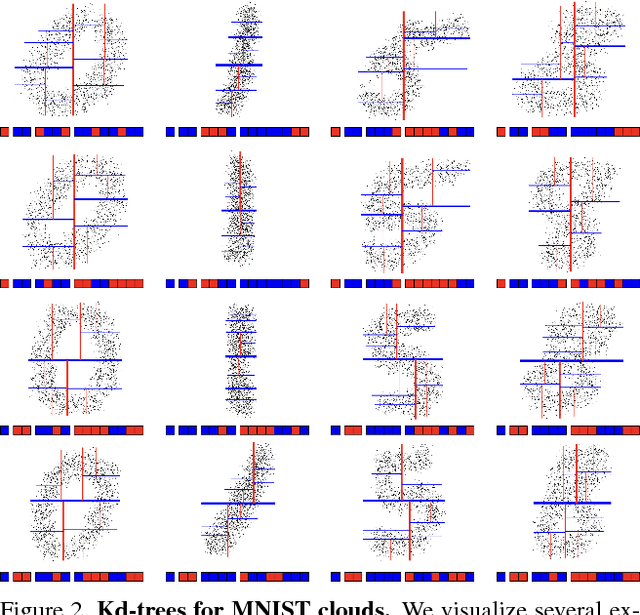
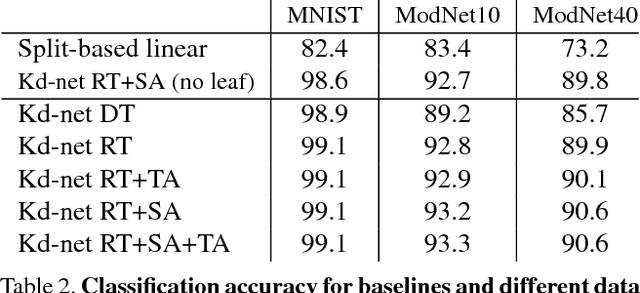
We present a new deep learning architecture (called Kd-network) that is designed for 3D model recognition tasks and works with unstructured point clouds. The new architecture performs multiplicative transformations and share parameters of these transformations according to the subdivisions of the point clouds imposed onto them by Kd-trees. Unlike the currently dominant convolutional architectures that usually require rasterization on uniform two-dimensional or three-dimensional grids, Kd-networks do not rely on such grids in any way and therefore avoid poor scaling behaviour. In a series of experiments with popular shape recognition benchmarks, Kd-networks demonstrate competitive performance in a number of shape recognition tasks such as shape classification, shape retrieval and shape part segmentation.