 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaussCtrl: Multi-View Consistent Text-Driven 3D Gaussian Splatting Editing
Mar 14, 2024



We propose GaussCtrl, a text-driven method to edit a 3D scene reconstructed by the 3D Gaussian Splatting (3DGS). Our method first renders a collection of images by using the 3DGS and edits them by using a pre-trained 2D diffusion model (ControlNet) based on the input prompt, which is then used to optimise the 3D model. Our key contribution is multi-view consistent editing, which enables editing all images together instead of iteratively editing one image while updating the 3D model as in previous works. It leads to faster editing as well as higher visual quality. This is achieved by the two terms: (a) depth-conditioned editing that enforces geometric consistency across multi-view images by leveraging naturally consistent depth maps. (b) attention-based latent code alignment that unifies the appearance of edited images by conditioning their editing to several reference views through self and cross-view attention between images' latent representations. Experiments demonstrate that our method achieves faster editing and better visual results than previous state-of-the-art methods.
PoRF: Pose Residual Field for Accurate Neural Surface Reconstruction
Oct 12, 2023Neural surface reconstruction is sensitive to the camera pose noise, even if state-of-the-art pose estimators like COLMAP or ARKit are used. More importantly, existing Pose-NeRF joint optimisation methods have struggled to improve pose accuracy in challenging real-world scenarios. To overcome the challenges, we introduce the pose residual field (\textbf{PoRF}), a novel implicit representation that uses an MLP for regressing pose updates. This is more robust than the conventional pose parameter optimisation due to parameter sharing that leverages global information over the entire sequence. Furthermore, we propose an epipolar geometry loss to enhance the supervision that leverages the correspondences exported from COLMAP results without the extra computational overhead. Our method yields promising results. On the DTU dataset, we reduce the rotation error by 78\% for COLMAP poses, leading to the decreased reconstruction Chamfer distance from 3.48mm to 0.85mm. On the MobileBrick dataset that contains casually captured unbounded 360-degree videos, our method refines ARKit poses and improves the reconstruction F1 score from 69.18 to 75.67, outperforming that with the dataset provided ground-truth pose (75.14). These achievements demonstrate the efficacy of our approach in refining camera poses and improving the accuracy of neural surface reconstruction in real-world scenarios.
Two-View Geometry Scoring Without Correspondences
Jun 02, 2023Camera pose estimation for two-view geometry traditionally relies on RANSAC. Normally, a multitude of image correspondences leads to a pool of proposed hypotheses, which are then scored to find a winning model. The inlier count is generally regarded as a reliable indicator of "consensus". We examine this scoring heuristic, and find that it favors disappointing models under certain circumstances. As a remedy, we propose the Fundamental Scoring Network (FSNet), which infers a score for a pair of overlapping images and any proposed fundamental matrix. It does not rely on sparse correspondences, but rather embodies a two-view geometry model through an epipolar attention mechanism that predicts the pose error of the two images. FSNet can be incorporated into traditional RANSAC loops. We evaluate FSNet on fundamental and essential matrix estimation on indoor and outdoor datasets, and establish that FSNet can successfully identify good poses for pairs of images with few or unreliable correspondences. Besides, we show that naively combining FSNet with MAGSAC++ scoring approach achieves state of the art results.
Accelerated Coordinate Encoding: Learning to Relocalize in Minutes using RGB and Poses
May 23, 2023



Learning-based visual relocalizers exhibit leading pose accuracy, but require hours or days of training. Since training needs to happen on each new scene again, long training times make learning-based relocalization impractical for most applications, despite its promise of high accuracy. In this paper we show how such a system can actually achieve the same accuracy in less than 5 minutes. We start from the obvious: a relocalization network can be split in a scene-agnostic feature backbone, and a scene-specific prediction head. Less obvious: using an MLP prediction head allows us to optimize across thousands of view points simultaneously in each single training iteration. This leads to stable and extremely fast convergence. Furthermore, we substitute effective but slow end-to-end training using a robust pose solver with a curriculum over a reprojection loss. Our approach does not require privileged knowledge, such a depth maps or a 3D model, for speedy training. Overall, our approach is up to 300x faster in mapping than state-of-the-art scene coordinate regression, while keeping accuracy on par.
SimSC: A Simple Framework for Semantic Correspondence with Temperature Learning
May 03, 2023We propose SimSC, a remarkably simple framework, to address the problem of semantic matching only based on the feature backbone. We discover that when fine-tuning ImageNet pre-trained backbone on the semantic matching task, L2 normalization of the feature map, a standard procedure in feature matching, produces an overly smooth matching distribution and significantly hinders the fine-tuning process. By setting an appropriate temperature to the softmax, this over-smoothness can be alleviated and the quality of features can be substantially improved. We employ a learning module to predict the optimal temperature for fine-tuning feature backbones. This module is trained together with the backbone and the temperature is updated online. We evaluate our method on three public datasets and demonstrate that we can achieve accuracy on par with state-of-the-art methods under the same backbone without using a learned matching head. Our method is versatile and works on various types of backbones. We show that the accuracy of our framework can be easily improved by coupling it with more powerful backbones.
Refinement for Absolute Pose Regression with Neural Feature Synthesis
Mar 17, 2023Absolute Pose Regression (APR) methods use deep neural networks to directly regress camera poses from RGB images. Despite their advantages in inference speed and simplicity, these methods still fall short of the accuracy achieved by geometry-based techniques. To address this issue, we propose a new model called the Neural Feature Synthesizer (NeFeS). Our approach encodes 3D geometric features during training and renders dense novel view features at test time to refine estimated camera poses from arbitrary APR methods. Unlike previous APR works that require additional unlabeled training data, our method leverages implicit geometric constraints during test time using a robust feature field. To enhance the robustness of our NeFeS network, we introduce a feature fusion module and a progressive training strategy. Our proposed method improves the state-of-the-art single-image APR accuracy by as much as 54.9% on indoor and outdoor benchmark datasets without additional time-consuming unlabeled data training.
MobileBrick: Building LEGO for 3D Reconstruction on Mobile Devices
Mar 09, 2023High-quality 3D ground-truth shapes are critical for 3D object reconstruction evaluation. However, it is difficult to create a replica of an object in reality, and even 3D reconstructions generated by 3D scanners have artefacts that cause biases in evaluation. To address this issue, we introduce a novel multi-view RGBD dataset captured using a mobile device, which includes highly precise 3D ground-truth annotations for 153 object models featuring a diverse set of 3D structures. We obtain precise 3D ground-truth shape without relying on high-end 3D scanners by utilising LEGO models with known geometry as the 3D structures for image capture. The distinct data modality offered by high-resolution RGB images and low-resolution depth maps captured on a mobile device, when combined with precise 3D geometry annotations, presents a unique opportunity for future research on high-fidelity 3D reconstruction. Furthermore, we evaluate a range of 3D reconstruction algorithms on the proposed dataset. Project page: http://code.active.vision/MobileBrick/
NoPe-NeRF: Optimising Neural Radiance Field with No Pose Prior
Dec 14, 2022



Training a Neural Radiance Field (NeRF) without pre-computed camera poses is challenging. Recent advances in this direction demonstrate the possibility of jointly optimising a NeRF and camera poses in forward-facing scenes. However, these methods still face difficulties during dramatic camera movement. We tackle this challenging problem by incorporating undistorted monocular depth priors. These priors are generated by correcting scale and shift parameters during training, with which we are then able to constrain the relative poses between consecutive frames. This constraint is achieved using our proposed novel loss functions. Experiments on real-world indoor and outdoor scenes show that our method can handle challenging camera trajectories and outperforms existing methods in terms of novel view rendering quality and pose estimation accuracy.
Approximating Continuous Convolutions for Deep Network Compression
Oct 17, 2022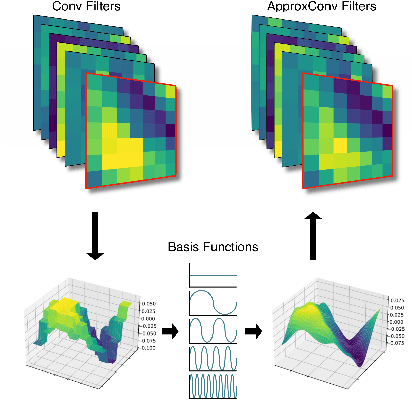
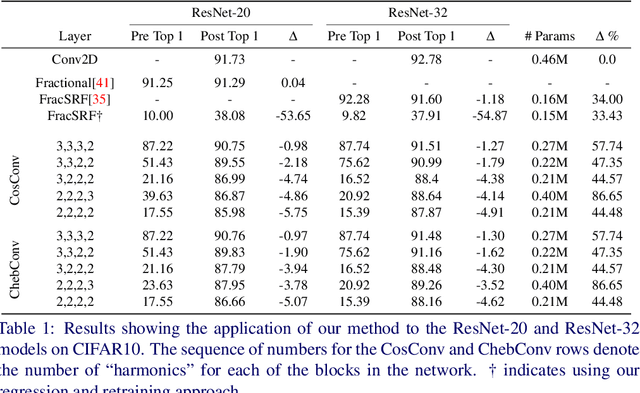
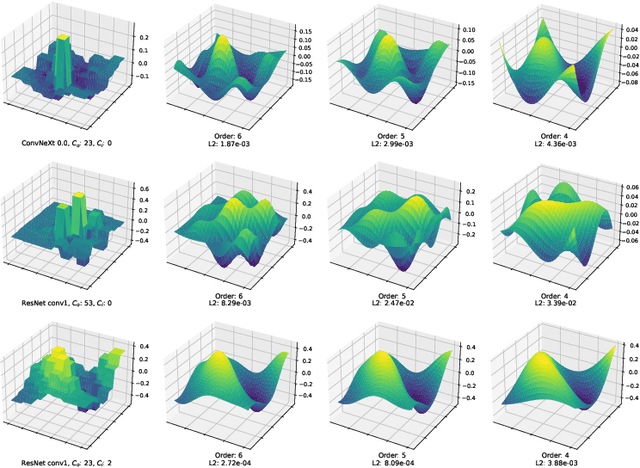
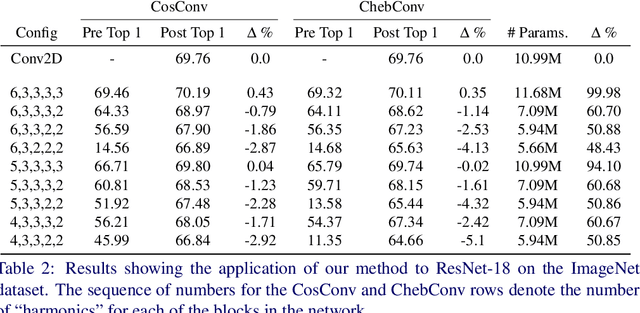
We present ApproxConv, a novel method for compressing the layers of a convolutional neural network. Reframing conventional discrete convolution as continuous convolution of parametrised functions over space, we use functional approximations to capture the essential structures of CNN filters with fewer parameters than conventional operations. Our method is able to reduce the size of trained CNN layers requiring only a small amount of fine-tuning. We show that our method is able to compress existing deep network models by half whilst losing only 1.86% accuracy. Further, we demonstrate that our method is compatible with other compression methods like quantisation allowing for further reductions in model size.
Map-free Visual Relocalization: Metric Pose Relative to a Single Image
Oct 11, 2022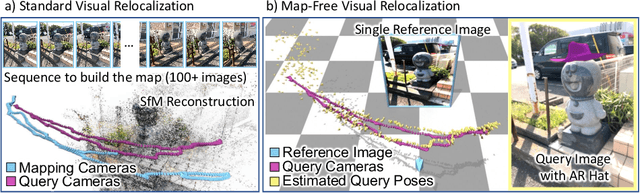

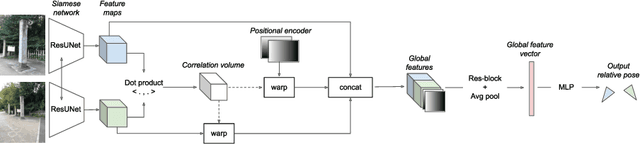

Can we relocalize in a scene represented by a single reference image? Standard visual relocalization requires hundreds of images and scale calibration to build a scene-specific 3D map. In contrast, we propose Map-free Relocalization, i.e., using only one photo of a scene to enable instant, metric scaled relocalization. Existing datasets are not suitable to benchmark map-free relocalization, due to their focus on large scenes or their limited variability. Thus, we have constructed a new dataset of 655 small places of interest, such as sculptures, murals and fountains, collected worldwide. Each place comes with a reference image to serve as a relocalization anchor, and dozens of query images with known, metric camera poses. The dataset features changing conditions, stark viewpoint changes, high variability across places, and queries with low to no visual overlap with the reference image. We identify two viable families of existing methods to provide baseline results: relative pose regression, and feature matching combined with single-image depth prediction. While these methods show reasonable performance on some favorable scenes in our dataset, map-free relocalization proves to be a challenge that requires new, innovative solutions.