 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerspectives on Incorporating Expert Feedback into Model Updates
May 13, 2022
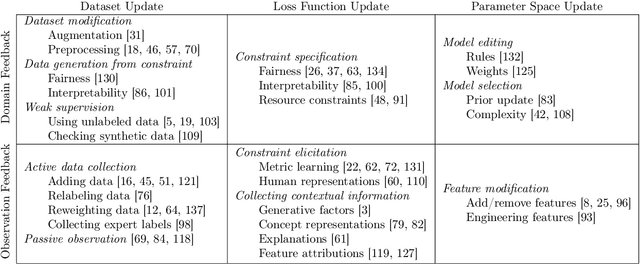
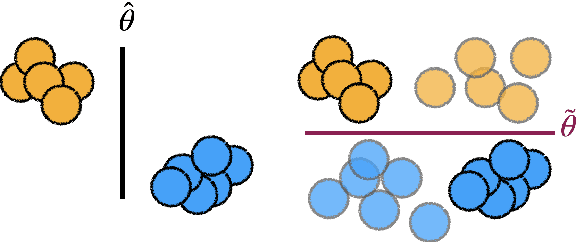
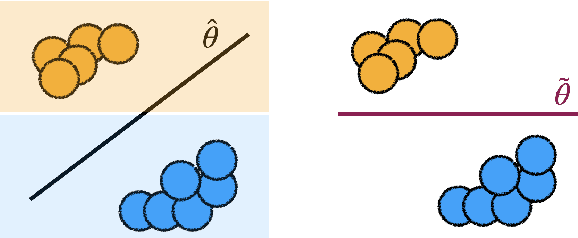
Machine learning (ML) practitioners are increasingly tasked with developing models that are aligned with non-technical experts' values and goals. However, there has been insufficient consideration on how practitioners should translate domain expertise into ML updates. In this paper, we consider how to capture interactions between practitioners and experts systematically. We devise a taxonomy to match expert feedback types with practitioner updates. A practitioner may receive feedback from an expert at the observation- or domain-level, and convert this feedback into updates to the dataset, loss function, or parameter space. We review existing work from ML and human-computer interaction to describe this feedback-update taxonomy, and highlight the insufficient consideration given to incorporating feedback from non-technical experts. We end with a set of open questions that naturally arise from our proposed taxonomy and subsequent survey.
On the Utility of Prediction Sets in Human-AI Teams
May 03, 2022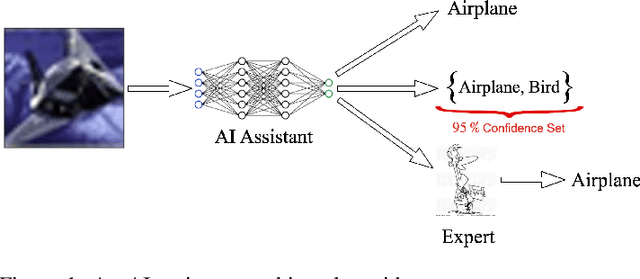
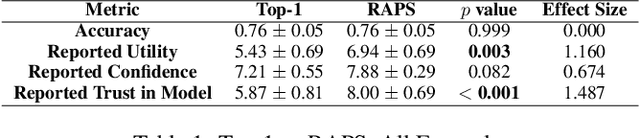
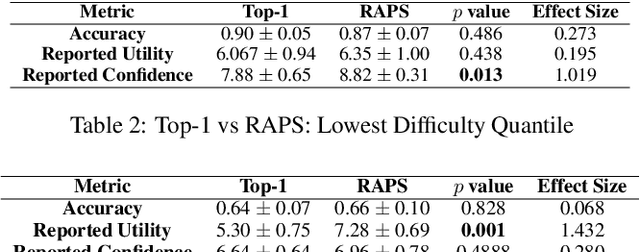
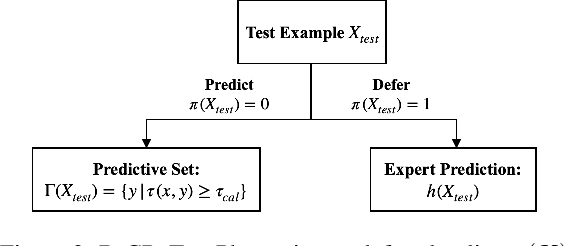
Research on human-AI teams usually provides experts with a single label, which ignores the uncertainty in a model's recommendation. Conformal prediction (CP) is a well established line of research that focuses on building a theoretically grounded, calibrated prediction set, which may contain multiple labels. We explore how such prediction sets impact expert decision-making in human-AI teams. Our evaluation on human subjects finds that set valued predictions positively impact experts. However, we notice that the predictive sets provided by CP can be very large, which leads to unhelpful AI assistants. To mitigate this, we introduce D-CP, a method to perform CP on some examples and defer to experts. We prove that D-CP can reduce the prediction set size of non-deferred examples. We show how D-CP performs in quantitative and in human subject experiments ($n=120$). Our results suggest that CP prediction sets improve human-AI team performance over showing the top-1 prediction alone, and that experts find D-CP prediction sets are more useful than CP prediction sets.
Approximating Full Conformal Prediction at Scale via Influence Functions
Feb 02, 2022Conformal prediction (CP) is a wrapper around traditional machine learning models, giving coverage guarantees under the sole assumption of exchangeability; in classification problems, for a chosen significance level $\varepsilon$, CP guarantees that the number of errors is at most $\varepsilon$, irrespective of whether the underlying model is misspecified. However, the prohibitive computational costs of full CP led researchers to design scalable alternatives, which alas do not attain the same guarantees or statistical power of full CP. In this paper, we use influence functions to efficiently approximate full CP. We prove that our method is a consistent approximation of full CP, and empirically show that the approximation error becomes smaller as the training set increases; e.g., for $10^{3}$ training points the two methods output p-values that are $<10^{-3}$ apart: a negligible error for any practical application. Our methods enable scaling full CP to large real-world datasets. We compare our full CP approximation ACP to mainstream CP alternatives, and observe that our method is computationally competitive whilst enjoying the statistical predictive power of full CP.
Diverse, Global and Amortised Counterfactual Explanations for Uncertainty Estimates
Dec 09, 2021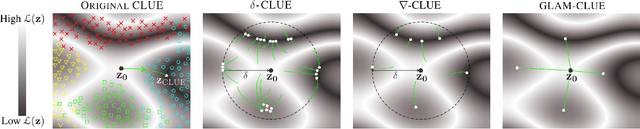

To interpret uncertainty estimates from differentiable probabilistic models, recent work has proposed generating a single Counterfactual Latent Uncertainty Explanation (CLUE) for a given data point where the model is uncertain, identifying a single, on-manifold change to the input such that the model becomes more certain in its prediction. We broaden the exploration to examine $\delta$-CLUE, the set of potential CLUEs within a $\delta$ ball of the original input in latent space. We study the diversity of such sets and find that many CLUEs are redundant; as such, we propose DIVerse CLUE ($\nabla$-CLUE), a set of CLUEs which each propose a distinct explanation as to how one can decrease the uncertainty associated with an input. We then further propose GLobal AMortised CLUE (GLAM-CLUE), a distinct and novel method which learns amortised mappings on specific groups of uncertain inputs, taking them and efficiently transforming them in a single function call into inputs for which a model will be certain. Our experiments show that $\delta$-CLUE, $\nabla$-CLUE, and GLAM-CLUE all address shortcomings of CLUE and provide beneficial explanations of uncertainty estimates to practitioners.
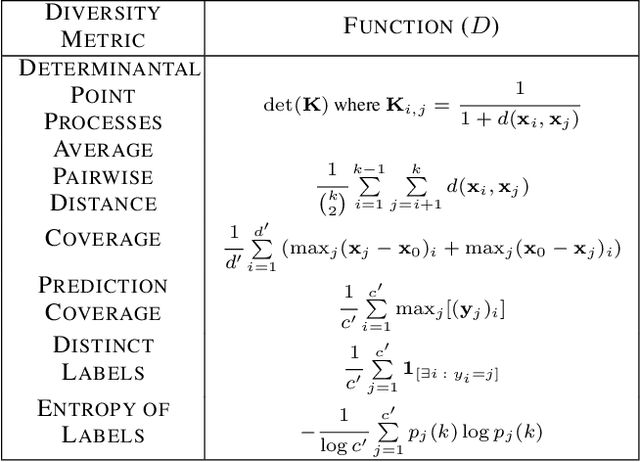
DIVINE: Diverse Influential Training Points for Data Visualization and Model Refinement
Jul 13, 2021
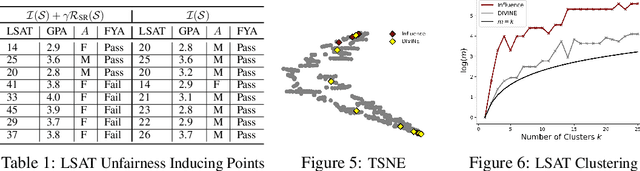
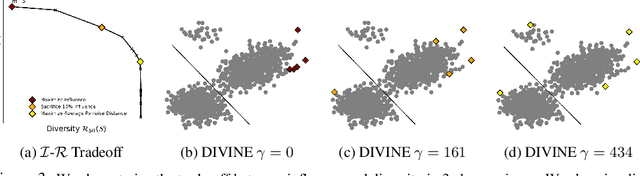
As the complexity of machine learning (ML) models increases, resulting in a lack of prediction explainability, several methods have been developed to explain a model's behavior in terms of the training data points that most influence the model. However, these methods tend to mark outliers as highly influential points, limiting the insights that practitioners can draw from points that are not representative of the training data. In this work, we take a step towards finding influential training points that also represent the training data well. We first review methods for assigning importance scores to training points. Given importance scores, we propose a method to select a set of DIVerse INfluEntial (DIVINE) training points as a useful explanation of model behavior. As practitioners might not only be interested in finding data points influential with respect to model accuracy, but also with respect to other important metrics, we show how to evaluate training data points on the basis of group fairness. Our method can identify unfairness-inducing training points, which can be removed to improve fairness outcomes. Our quantitative experiments and user studies show that visualizing DIVINE points helps practitioners understand and explain model behavior better than earlier approaches.
Do Concept Bottleneck Models Learn as Intended?
May 10, 2021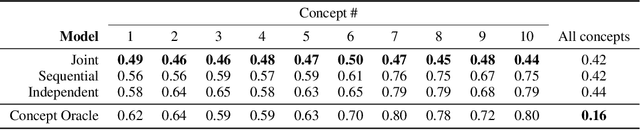
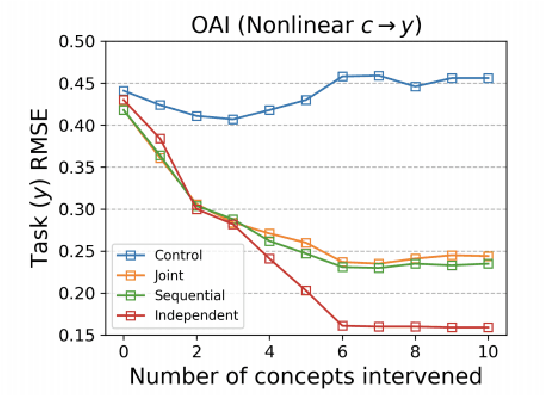
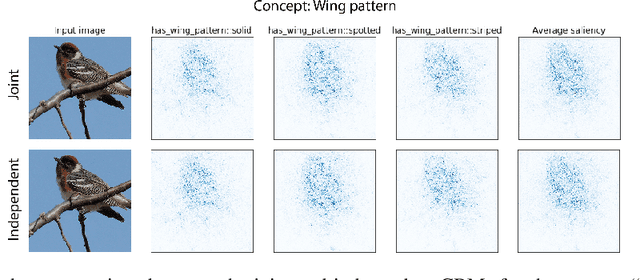
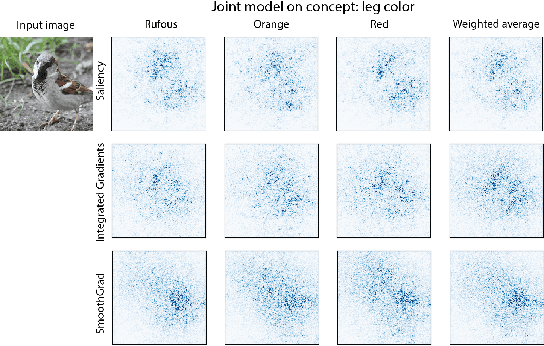
Concept bottleneck models map from raw inputs to concepts, and then from concepts to targets. Such models aim to incorporate pre-specified, high-level concepts into the learning procedure, and have been motivated to meet three desiderata: interpretability, predictability, and intervenability. However, we find that concept bottleneck models struggle to meet these goals. Using post hoc interpretability methods, we demonstrate that concepts do not correspond to anything semantically meaningful in input space, thus calling into question the usefulness of concept bottleneck models in their current form.
δ-CLUE: Diverse Sets of Explanations for Uncertainty Estimates
May 08, 2021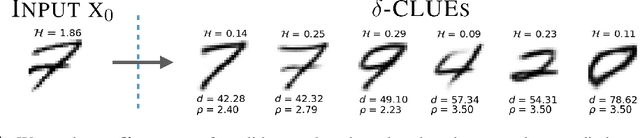
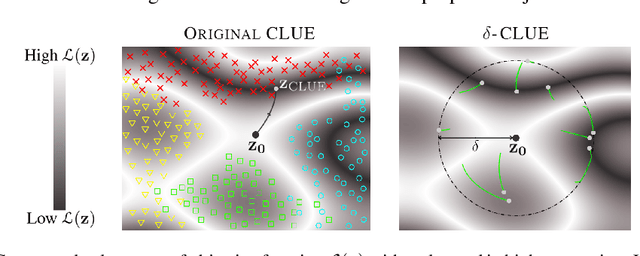
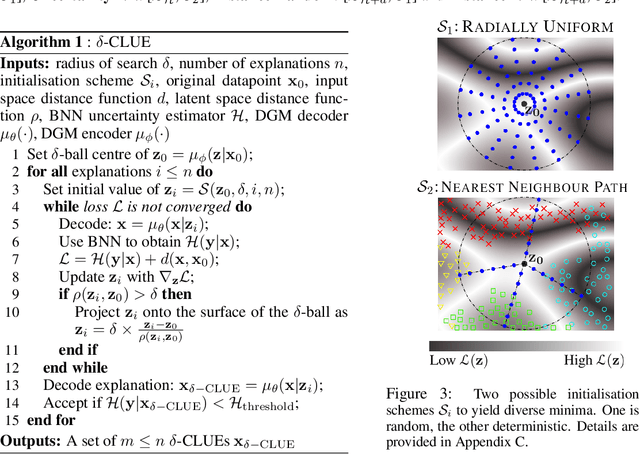
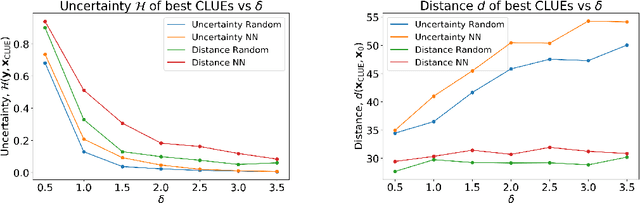
To interpret uncertainty estimates from differentiable probabilistic models, recent work has proposed generating Counterfactual Latent Uncertainty Explanations (CLUEs). However, for a single input, such approaches could output a variety of explanations due to the lack of constraints placed on the explanation. Here we augment the original CLUE approach, to provide what we call $\delta$-CLUE. CLUE indicates $\it{one}$ way to change an input, while remaining on the data manifold, such that the model becomes more confident about its prediction. We instead return a $\it{set}$ of plausible CLUEs: multiple, diverse inputs that are within a $\delta$ ball of the original input in latent space, all yielding confident predictions.
Uncertainty as a Form of Transparency: Measuring, Communicating, and Using Uncertainty
Nov 15, 2020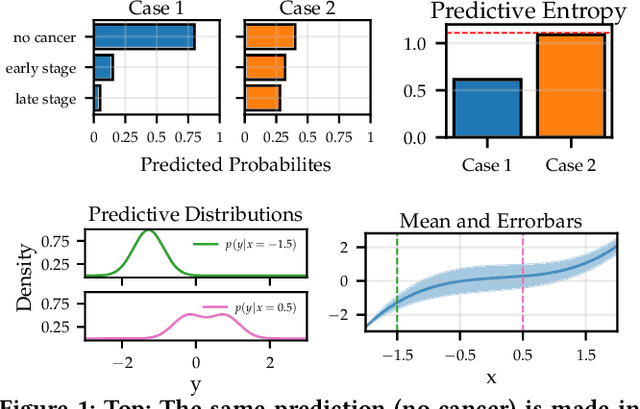

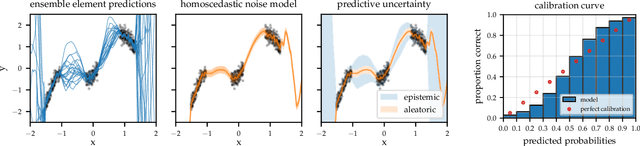
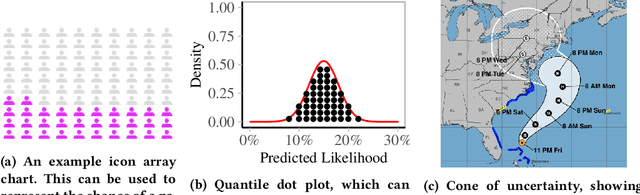
Transparency of algorithmic systems entails exposing system properties to various stakeholders for purposes that include understanding, improving, and/or contesting predictions. The machine learning (ML) community has mostly considered explainability as a proxy for transparency. With this work, we seek to encourage researchers to study uncertainty as a form of transparency and practitioners to communicate uncertainty estimates to stakeholders. First, we discuss methods for assessing uncertainty. Then, we describe the utility of uncertainty for mitigating model unfairness, augmenting decision-making, and building trustworthy systems. We also review methods for displaying uncertainty to stakeholders and discuss how to collect information required for incorporating uncertainty into existing ML pipelines. Our contribution is an interdisciplinary review to inform how to measure, communicate, and use uncertainty as a form of transparency.
On the Fairness of Causal Algorithmic Recourse
Oct 14, 2020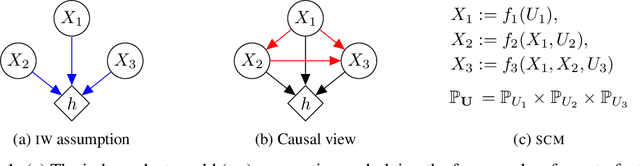
While many recent works have studied the problem of algorithmic fairness from the perspective of predictions, here we investigate the fairness of recourse actions recommended to individuals to recover from an unfavourable classification. To this end, we propose two new fairness criteria at the group and individual level which---unlike prior work on equalising the average distance from the decision boundary across protected groups---are based on a causal framework that explicitly models relationships between input features, thereby allowing to capture downstream effects of recourse actions performed in the physical world. We explore how our criteria relate to others, such as counterfactual fairness, and show that fairness of recourse is complementary to fairness of prediction. We then investigate how to enforce fair recourse in the training of the classifier. Finally, we discuss whether fairness violations in the data generating process revealed by our criteria may be better addressed by societal interventions and structural changes to the system, as opposed to constraints on the classifier.
Machine Learning Explainability for External Stakeholders
Jul 10, 2020As machine learning is increasingly deployed in high-stakes contexts affecting people's livelihoods, there have been growing calls to open the black box and to make machine learning algorithms more explainable. Providing useful explanations requires careful consideration of the needs of stakeholders, including end-users, regulators, and domain experts. Despite this need, little work has been done to facilitate inter-stakeholder conversation around explainable machine learning. To help address this gap, we conducted a closed-door, day-long workshop between academics, industry experts, legal scholars, and policymakers to develop a shared language around explainability and to understand the current shortcomings of and potential solutions for deploying explainable machine learning in service of transparency goals. We also asked participants to share case studies in deploying explainable machine learning at scale. In this paper, we provide a short summary of various case studies of explainable machine learning, lessons from those studies, and discuss open challenges.