 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDIVINE: Diverse Influential Training Points for Data Visualization and Model Refinement
Paper and Code

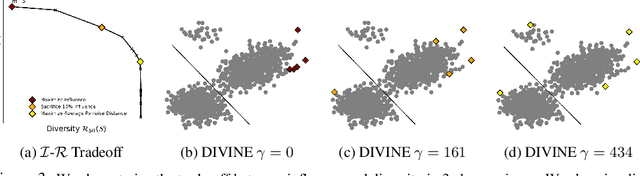
As the complexity of machine learning (ML) models increases, resulting in a lack of prediction explainability, several methods have been developed to explain a model's behavior in terms of the training data points that most influence the model. However, these methods tend to mark outliers as highly influential points, limiting the insights that practitioners can draw from points that are not representative of the training data. In this work, we take a step towards finding influential training points that also represent the training data well. We first review methods for assigning importance scores to training points. Given importance scores, we propose a method to select a set of DIVerse INfluEntial (DIVINE) training points as a useful explanation of model behavior. As practitioners might not only be interested in finding data points influential with respect to model accuracy, but also with respect to other important metrics, we show how to evaluate training data points on the basis of group fairness. Our method can identify unfairness-inducing training points, which can be removed to improve fairness outcomes. Our quantitative experiments and user studies show that visualizing DIVINE points helps practitioners understand and explain model behavior better than earlier approaches.