 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimultaneous Perception-Action Design via Invariant Finite Belief Sets
Sep 10, 2021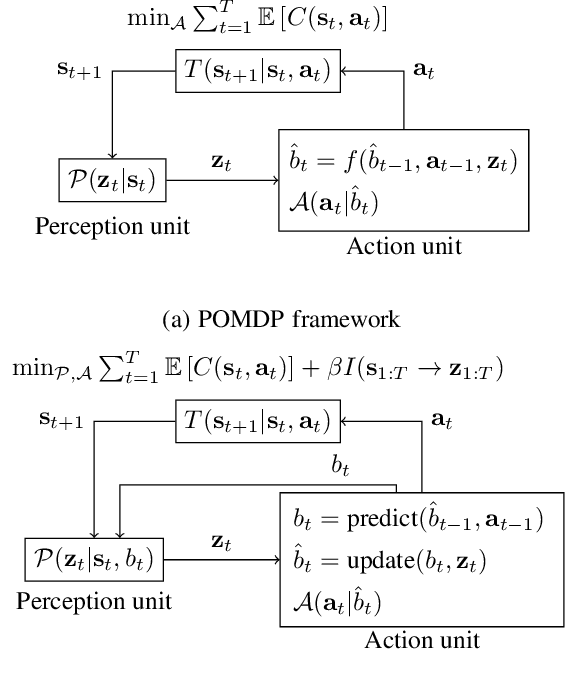
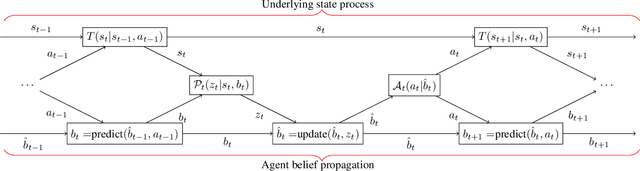
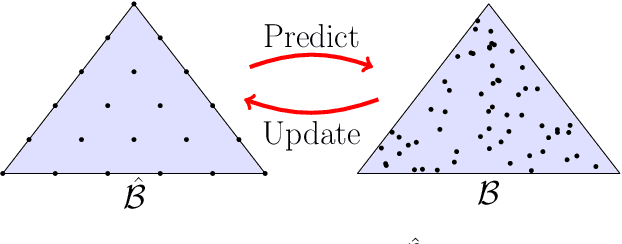
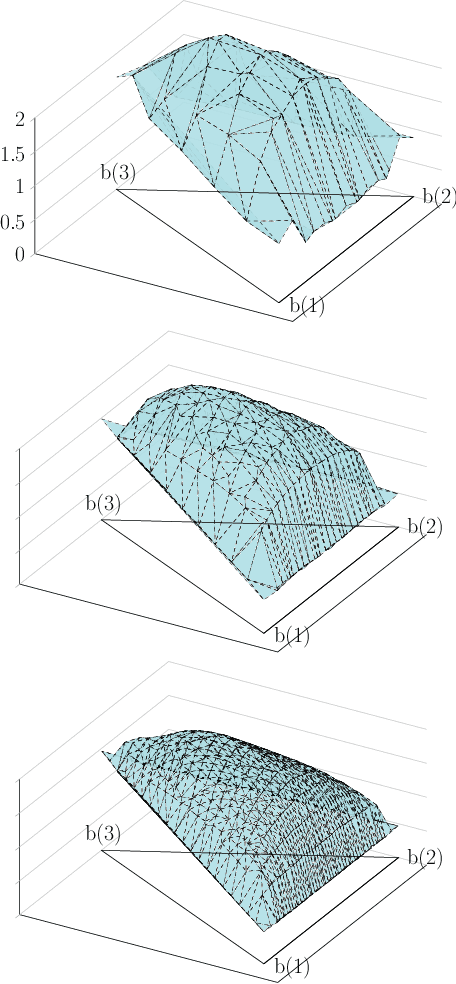
Although perception is an increasingly dominant portion of the overall computational cost for autonomous systems, only a fraction of the information perceived is likely to be relevant to the current task. To alleviate these perception costs, we develop a novel simultaneous perception-action design framework wherein an agent senses only the task-relevant information. This formulation differs from that of a partially observable Markov decision process, since the agent is free to synthesize not only its policy for action selection but also its belief-dependent observation function. The method enables the agent to balance its perception costs with those incurred by operating in its environment. To obtain a computationally tractable solution, we approximate the value function using a novel method of invariant finite belief sets, wherein the agent acts exclusively on a finite subset of the continuous belief space. We solve the approximate problem through value iteration in which a linear program is solved individually for each belief state in the set, in each iteration. Finally, we prove that the value functions, under an assumption on their structure, converge to their continuous state-space values as the sample density increases.
From Agile Ground to Aerial Navigation: Learning from Learned Hallucination
Aug 22, 2021

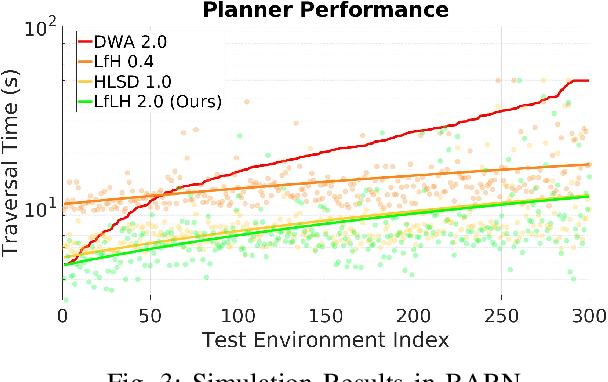

This paper presents a self-supervised Learning from Learned Hallucination (LfLH) method to learn fast and reactive motion planners for ground and aerial robots to navigate through highly constrained environments. The recent Learning from Hallucination (LfH) paradigm for autonomous navigation executes motion plans by random exploration in completely safe obstacle-free spaces, uses hand-crafted hallucination techniques to add imaginary obstacles to the robot's perception, and then learns motion planners to navigate in realistic, highly-constrained, dangerous spaces. However, current hand-crafted hallucination techniques need to be tailored for specific robot types (e.g., a differential drive ground vehicle), and use approximations heavily dependent on certain assumptions (e.g., a short planning horizon). In this work, instead of manually designing hallucination functions, LfLH learns to hallucinate obstacle configurations, where the motion plans from random exploration in open space are optimal, in a self-supervised manner. LfLH is robust to different robot types and does not make assumptions about the planning horizon. Evaluated in both simulated and physical environments with a ground and an aerial robot, LfLH outperforms or performs comparably to previous hallucination approaches, along with sampling- and optimization-based classical methods.
Robust Generative Adversarial Imitation Learning via Local Lipschitzness
Jun 30, 2021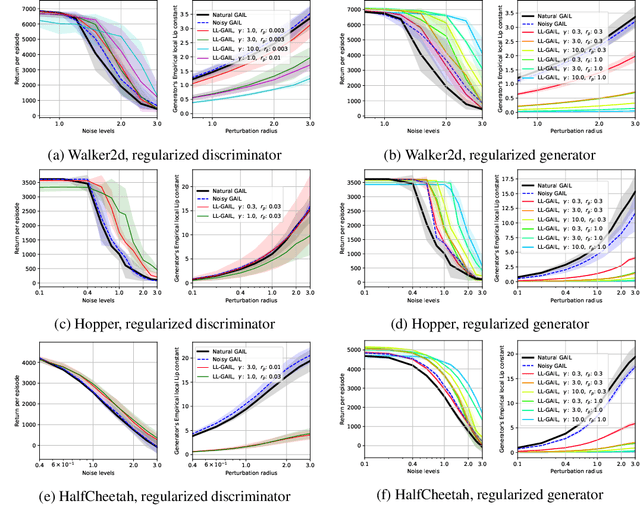
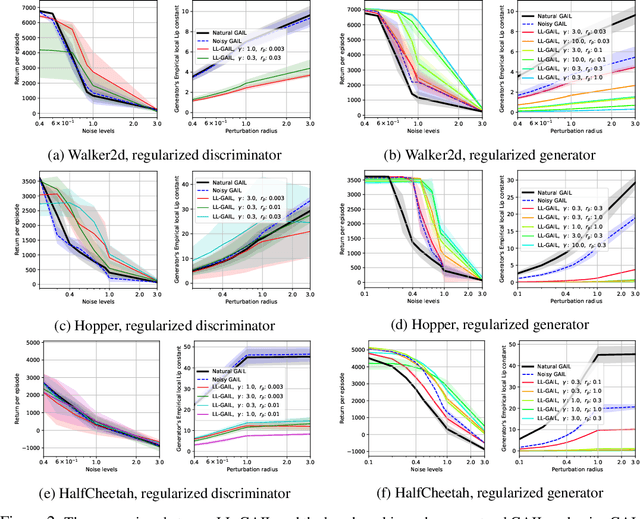
We explore methodologies to improve the robustness of generative adversarial imitation learning (GAIL) algorithms to observation noise. Towards this objective, we study the effect of local Lipschitzness of the discriminator and the generator on the robustness of policies learned by GAIL. In many robotics applications, the learned policies by GAIL typically suffer from a degraded performance at test time since the observations from the environment might be corrupted by noise. Hence, robustifying the learned policies against the observation noise is of critical importance. To this end, we propose a regularization method to induce local Lipschitzness in the generator and the discriminator of adversarial imitation learning methods. We show that the modified objective leads to learning significantly more robust policies. Moreover, we demonstrate -- both theoretically and experimentally -- that training a locally Lipschitz discriminator leads to a locally Lipschitz generator, thereby improving the robustness of the resultant policy. We perform extensive experiments on simulated robot locomotion environments from the MuJoCo suite that demonstrate the proposed method learns policies that significantly outperform the state-of-the-art generative adversarial imitation learning algorithm when applied to test scenarios with noise-corrupted observations.
Convex Optimization for Parameter Synthesis in MDPs
Jun 30, 2021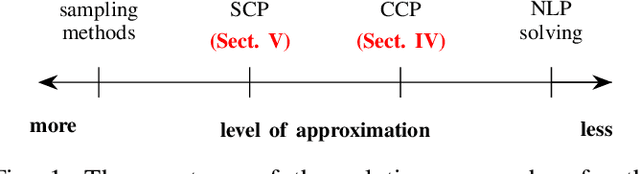
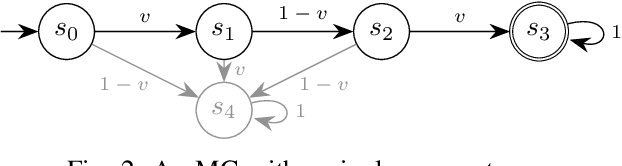
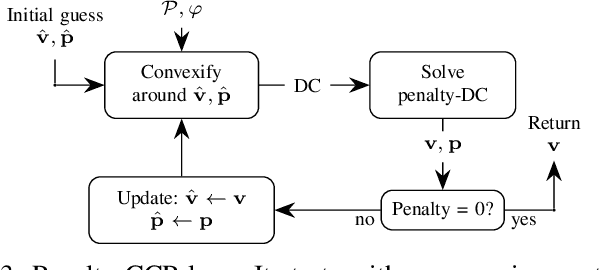
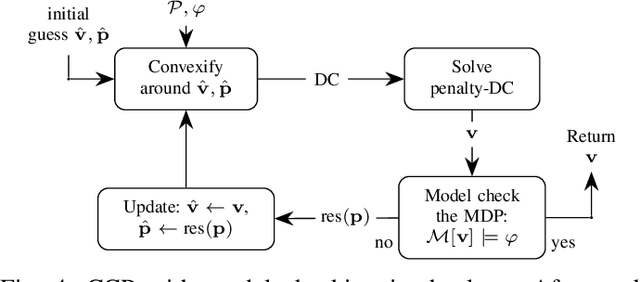
Probabilistic model checking aims to prove whether a Markov decision process (MDP) satisfies a temporal logic specification. The underlying methods rely on an often unrealistic assumption that the MDP is precisely known. Consequently, parametric MDPs (pMDPs) extend MDPs with transition probabilities that are functions over unspecified parameters. The parameter synthesis problem is to compute an instantiation of these unspecified parameters such that the resulting MDP satisfies the temporal logic specification. We formulate the parameter synthesis problem as a quadratically constrained quadratic program (QCQP), which is nonconvex and is NP-hard to solve in general. We develop two approaches that iteratively obtain locally optimal solutions. The first approach exploits the so-called convex-concave procedure (CCP), and the second approach utilizes a sequential convex programming (SCP) method. The techniques improve the runtime and scalability by multiple orders of magnitude compared to black-box CCP and SCP by merging ideas from convex optimization and probabilistic model checking. We demonstrate the approaches on a satellite collision avoidance problem with hundreds of thousands of states and tens of thousands of parameters and their scalability on a wide range of commonly used benchmarks.
Non-Parametric Neuro-Adaptive Control Subject to Task Specifications
Jun 25, 2021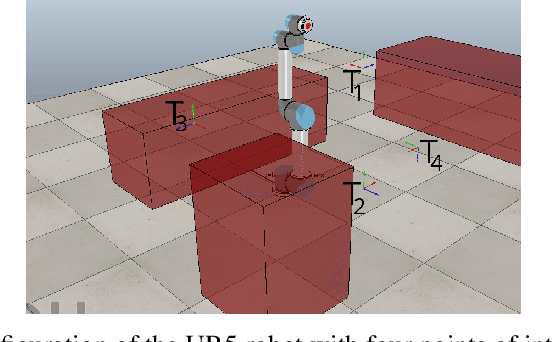

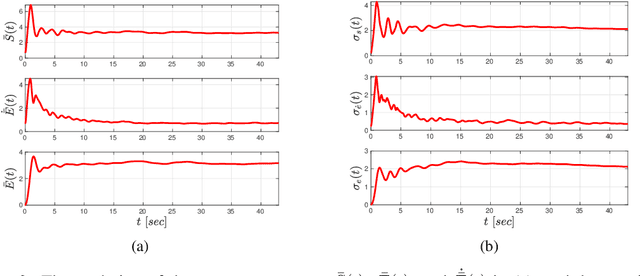
We develop a learning-based algorithm for the control of robotic systems governed by unknown, nonlinear dynamics to satisfy tasks expressed as signal temporal logic specifications. Most existing algorithms either assume certain parametric forms for the dynamic terms or resort to unnecessarily large control inputs (e.g., using reciprocal functions) in order to provide theoretical guarantees. The proposed algorithm avoids the aforementioned drawbacks by innovatively integrating neural network-based learning with adaptive control. More specifically, the algorithm learns a controller, represented as a neural network, using training data that correspond to a collection of different tasks and robot parameters. It then incorporates this neural network into an online closed-loop adaptive control mechanism in such a way that the resulting behavior satisfies a user-defined task. The proposed algorithm does not use any information on the unknown dynamic terms or any approximation schemes. We provide formal theoretical guarantees on the satisfaction of the task and we demonstrate the effectiveness of the algorithm in a virtual simulator using a 6-DOF robotic manipulator.
Learning to Reach, Swim, Walk and Fly in One Trial: Data-Driven Control with Scarce Data and Side Information
Jun 19, 2021
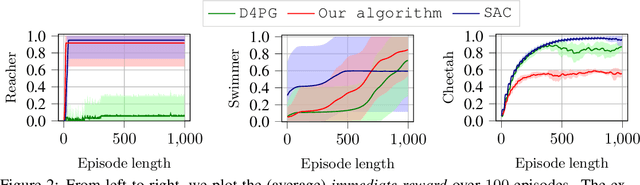
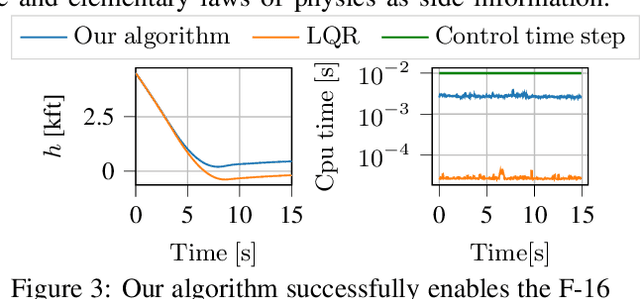
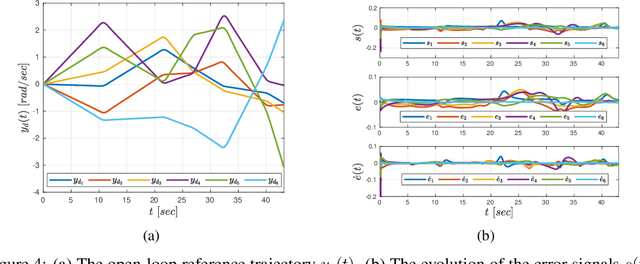
We develop a learning-based control algorithm for unknown dynamical systems under very severe data limitations. Specifically, the algorithm has access to streaming data only from a single and ongoing trial. Despite the scarcity of data, we show -- through a series of examples -- that the algorithm can provide performance comparable to reinforcement learning algorithms trained over millions of environment interactions. It accomplishes such performance by effectively leveraging various forms of side information on the dynamics to reduce the sample complexity. Such side information typically comes from elementary laws of physics and qualitative properties of the system. More precisely, the algorithm approximately solves an optimal control problem encoding the system's desired behavior. To this end, it constructs and refines a differential inclusion that contains the unknown vector field of the dynamics. The differential inclusion, used in an interval Taylor-based method, enables to over-approximate the set of states the system may reach. Theoretically, we establish a bound on the suboptimality of the approximate solution with respect to the case of known dynamics. We show that the longer the trial or the more side information is available, the tighter the bound. Empirically, experiments in a high-fidelity F-16 aircraft simulator and MuJoCo's environments such as the Reacher, Swimmer, and Cheetah illustrate the algorithm's effectiveness.
Robust Training in High Dimensions via Block Coordinate Geometric Median Descent
Jun 16, 2021
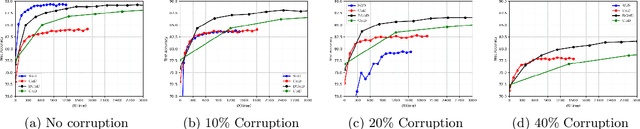
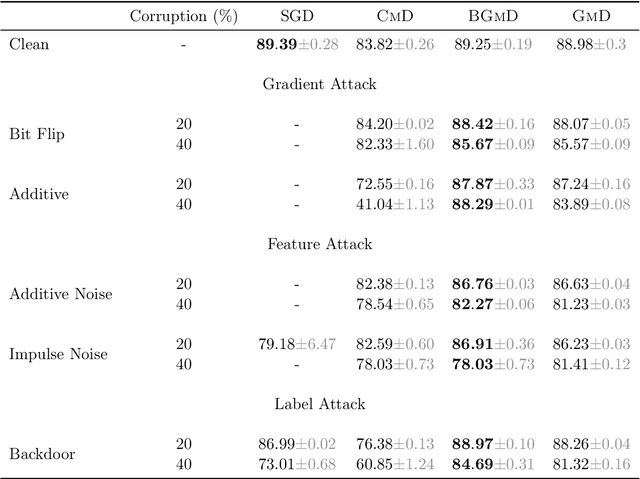
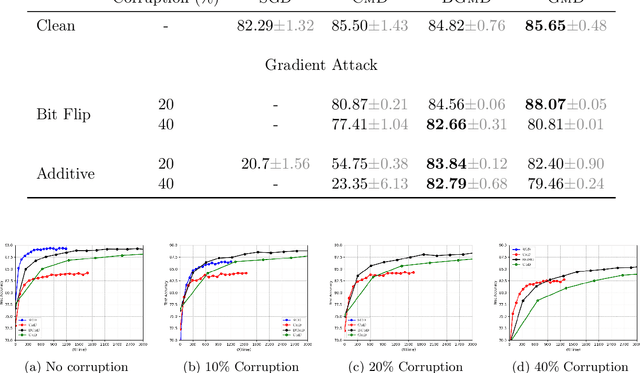
Geometric median (\textsc{Gm}) is a classical method in statistics for achieving a robust estimation of the uncorrupted data; under gross corruption, it achieves the optimal breakdown point of 0.5. However, its computational complexity makes it infeasible for robustifying stochastic gradient descent (SGD) for high-dimensional optimization problems. In this paper, we show that by applying \textsc{Gm} to only a judiciously chosen block of coordinates at a time and using a memory mechanism, one can retain the breakdown point of 0.5 for smooth non-convex problems, with non-asymptotic convergence rates comparable to the SGD with \textsc{Gm}.
Verifiable and Compositional Reinforcement Learning Systems
Jun 07, 2021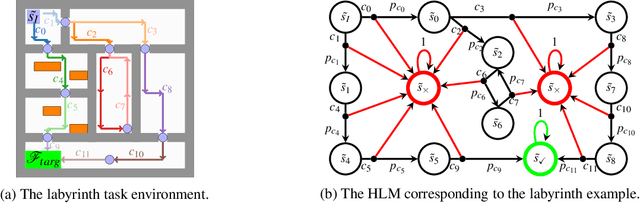

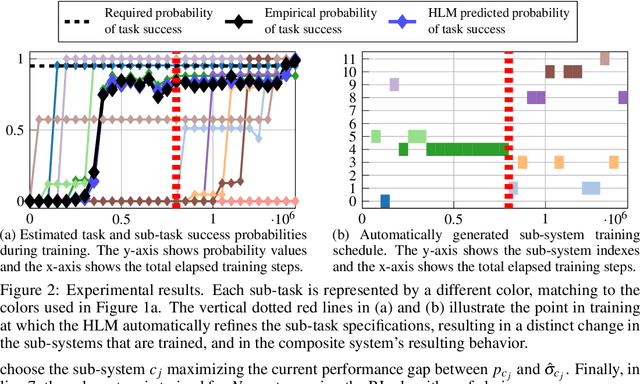

We propose a novel framework for verifiable and compositional reinforcement learning (RL) in which a collection of RL sub-systems, each of which learns to accomplish a separate sub-task, are composed to achieve an overall task. The framework consists of a high-level model, represented as a parametric Markov decision process (pMDP) which is used to plan and to analyze compositions of sub-systems, and of the collection of low-level sub-systems themselves. By defining interfaces between the sub-systems, the framework enables automatic decompositons of task specifications, e.g., reach a target set of states with a probability of at least 0.95, into individual sub-task specifications, i.e. achieve the sub-system's exit conditions with at least some minimum probability, given that its entry conditions are met. This in turn allows for the independent training and testing of the sub-systems; if they each learn a policy satisfying the appropriate sub-task specification, then their composition is guaranteed to satisfy the overall task specification. Conversely, if the sub-task specifications cannot all be satisfied by the learned policies, we present a method, formulated as the problem of finding an optimal set of parameters in the pMDP, to automatically update the sub-task specifications to account for the observed shortcomings. The result is an iterative procedure for defining sub-task specifications, and for training the sub-systems to meet them. As an additional benefit, this procedure allows for particularly challenging or important components of an overall task to be determined automatically, and focused on, during training. Experimental results demonstrate the presented framework's novel capabilities.
Uncertainty-Aware Signal Temporal Logic Inference
May 30, 2021



Temporal logic inference is the process of extracting formal descriptions of system behaviors from data in the form of temporal logic formulas. The existing temporal logic inference methods mostly neglect uncertainties in the data, which results in limited applicability of such methods in real-world deployments. In this paper, we first investigate the uncertainties associated with trajectories of a system and represent such uncertainties in the form of interval trajectories. We then propose two uncertainty-aware signal temporal logic (STL) inference approaches to classify the undesired behaviors and desired behaviors of a system. Instead of classifying finitely many trajectories, we classify infinitely many trajectories within the interval trajectories. In the first approach, we incorporate robust semantics of STL formulas with respect to an interval trajectory to quantify the margin at which an STL formula is satisfied or violated by the interval trajectory. The second approach relies on the first learning algorithm and exploits the decision tree to infer STL formulas to classify behaviors of a given system. The proposed approaches also work for non-separable data by optimizing the worst-case robustness in inferring an STL formula. Finally, we evaluate the performance of the proposed algorithms in two case studies, where the proposed algorithms show reductions in the computation time by up to four orders of magnitude in comparison with the sampling-based baseline algorithms (for a dataset with 800 sampled trajectories in total).
Task-Guided Inverse Reinforcement Learning Under Partial Information
May 28, 2021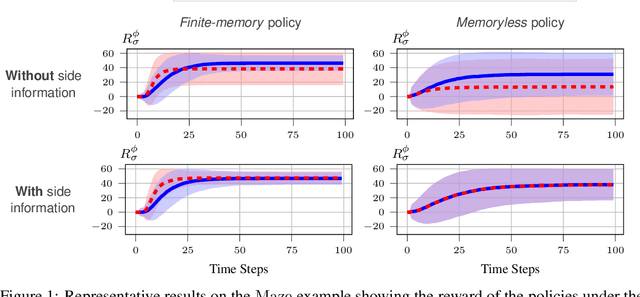
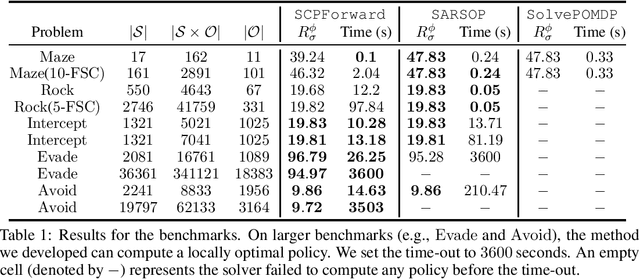
We study the problem of inverse reinforcement learning (IRL), where the learning agent recovers a reward function using expert demonstrations. Most of the existing IRL techniques make the often unrealistic assumption that the agent has access to full information about the environment. We remove this assumption by developing an algorithm for IRL in partially observable Markov decision processes (POMDPs), where an agent cannot directly observe the current state of the POMDP. The algorithm addresses several limitations of existing techniques that do not take the \emph{information asymmetry} between the expert and the agent into account. First, it adopts causal entropy as the measure of the likelihood of the expert demonstrations as opposed to entropy in most existing IRL techniques and avoids a common source of algorithmic complexity. Second, it incorporates task specifications expressed in temporal logic into IRL. Such specifications may be interpreted as side information available to the learner a priori in addition to the demonstrations, and may reduce the information asymmetry between the expert and the agent. Nevertheless, the resulting formulation is still nonconvex due to the intrinsic nonconvexity of the so-called \emph{forward problem}, i.e., computing an optimal policy given a reward function, in POMDPs. We address this nonconvexity through sequential convex programming and introduce several extensions to solve the forward problem in a scalable manner. This scalability allows computing policies that incorporate memory at the expense of added computational cost yet also achieves higher performance compared to memoryless policies. We demonstrate that, even with severely limited data, the algorithm learns reward functions and policies that satisfy the task and induce a similar behavior to the expert by leveraging the side information and incorporating memory into the policy.