 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBetter Retrieval May Not Lead to Better Question Answering
May 07, 2022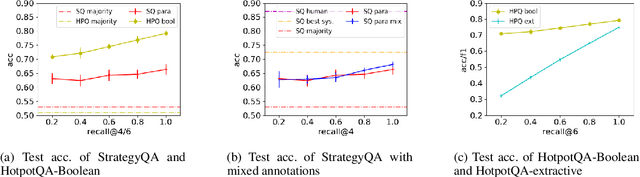

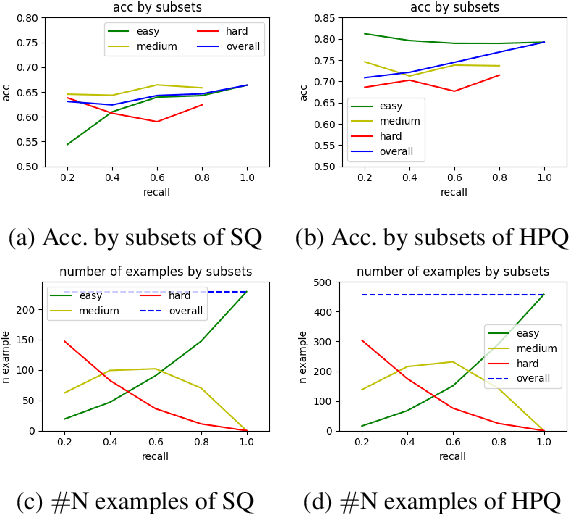

Considerable progress has been made recently in open-domain question answering (QA) problems, which require Information Retrieval (IR) and Reading Comprehension (RC). A popular approach to improve the system's performance is to improve the quality of the retrieved context from the IR stage. In this work we show that for StrategyQA, a challenging open-domain QA dataset that requires multi-hop reasoning, this common approach is surprisingly ineffective -- improving the quality of the retrieved context hardly improves the system's performance. We further analyze the system's behavior to identify potential reasons.
PROMPT WAYWARDNESS: The Curious Case of Discretized Interpretation of Continuous Prompts
Dec 15, 2021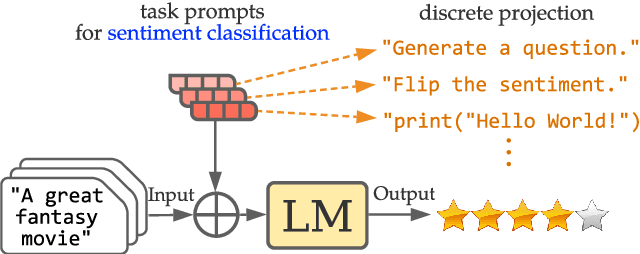
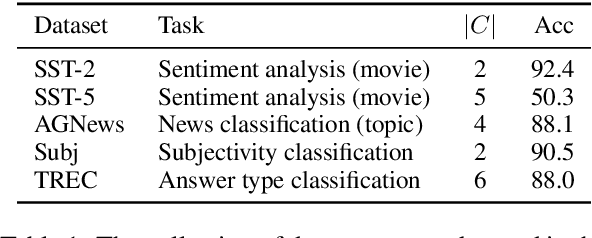
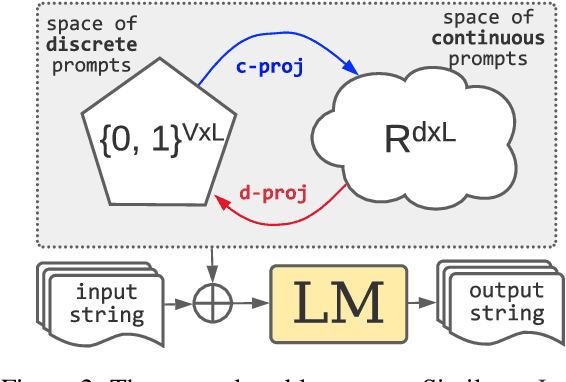
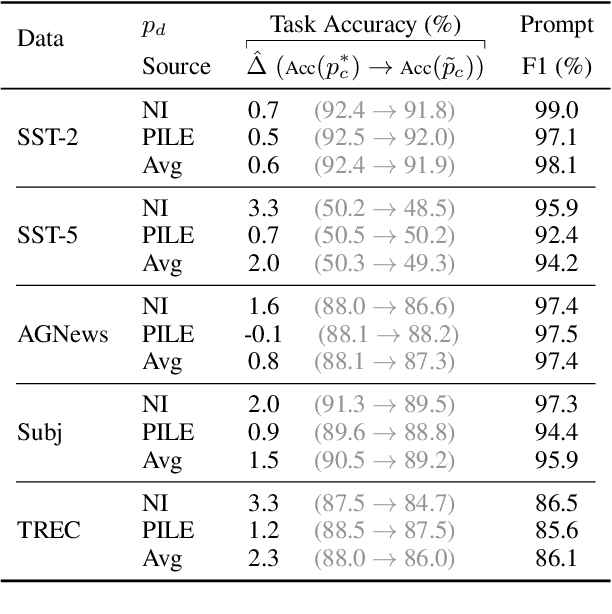
Fine-tuning continuous prompts for target tasks has recently emerged as a compact alternative to full model fine-tuning. Motivated by these promising results, we investigate the feasibility of extracting a discrete (textual) interpretation of continuous prompts that is faithful to the problem they solve. In practice, we observe a "wayward" behavior between the task solved by continuous prompts and their nearest neighbor discrete projections: We can find continuous prompts that solve a task while being projected to an arbitrary text (e.g., definition of a different or even a contradictory task), while being within a very small (2%) margin of the best continuous prompt of the same size for the task. We provide intuitions behind this odd and surprising behavior, as well as extensive empirical analyses quantifying the effect of various parameters. For instance, for larger model sizes we observe higher waywardness, i.e, we can find prompts that more closely map to any arbitrary text with a smaller drop in accuracy. These findings have important implications relating to the difficulty of faithfully interpreting continuous prompts and their generalization across models and tasks, providing guidance for future progress in prompting language models.
Learning to Solve Complex Tasks by Talking to Agents
Oct 16, 2021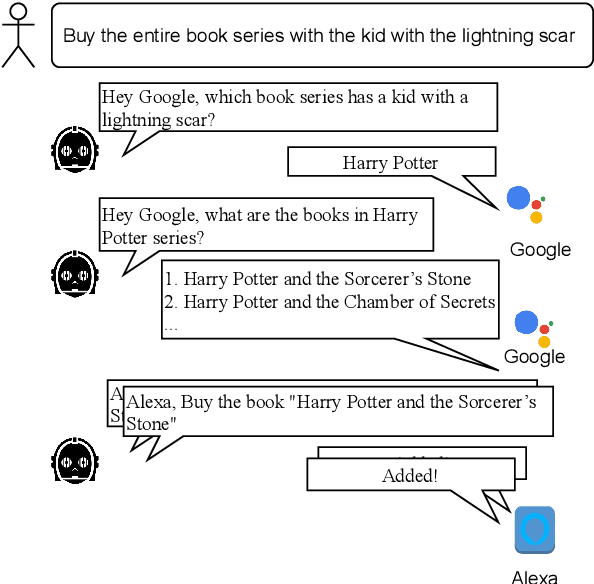


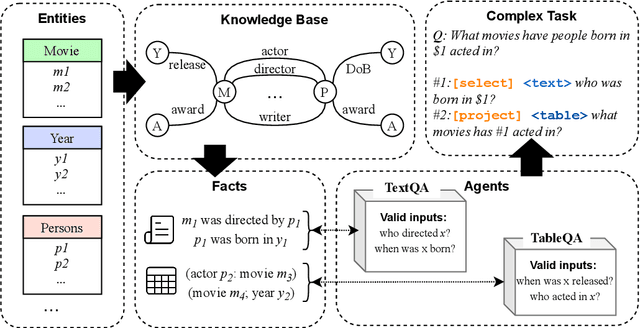
Humans often solve complex problems by interacting (in natural language) with existing agents, such as AI assistants, that can solve simpler sub-tasks. These agents themselves can be powerful systems built using extensive resources and privately held data. In contrast, common NLP benchmarks aim for the development of self-sufficient models for every task. To address this gap and facilitate research towards ``green'' AI systems that build upon existing agents, we propose a new benchmark called CommaQA that contains three kinds of complex reasoning tasks that are designed to be solved by ``talking'' to four agents with different capabilities. We demonstrate that state-of-the-art black-box models, which are unable to leverage existing agents, struggle on CommaQA (exact match score only reaches 40pts) even when given access to the agents' internal knowledge and gold fact supervision. On the other hand, models using gold question decomposition supervision can indeed solve CommaQA to a high accuracy (over 96\% exact match) by learning to utilize the agents. Even these additional supervision models, however, do not solve our compositional generalization test set. Finally the end-goal of learning to solve complex tasks by communicating with existing agents \emph{without relying on any additional supervision} remains unsolved and we hope CommaQA serves as a novel benchmark to enable the development of such systems.
MuSiQue: Multi-hop Questions via Single-hop Question Composition
Aug 02, 2021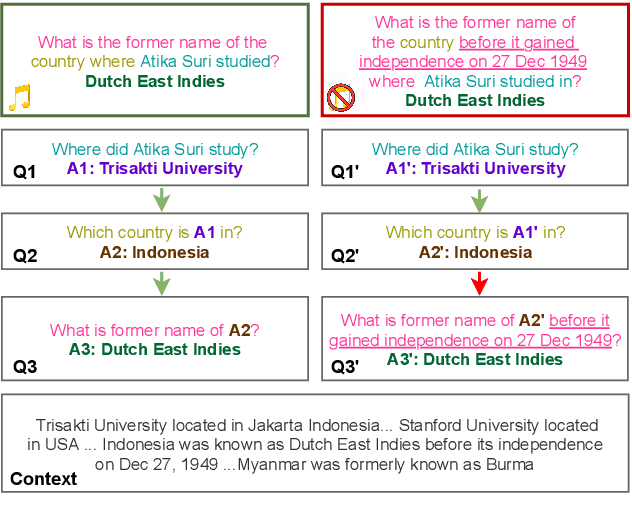
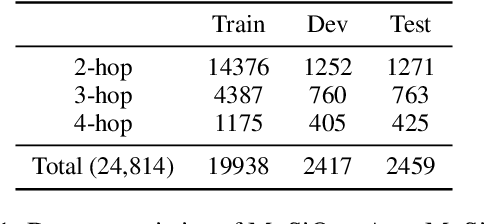
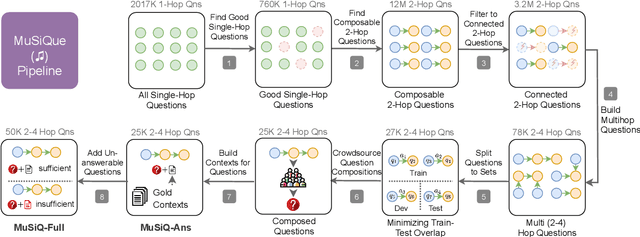
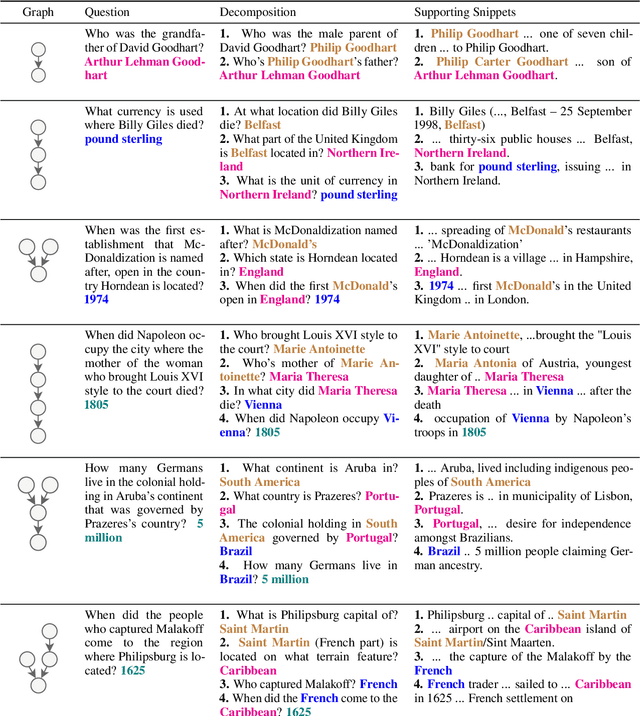
To build challenging multi-hop question answering datasets, we propose a bottom-up semi-automatic process of constructing multi-hop question via composition of single-hop questions. Constructing multi-hop questions as composition of single-hop questions allows us to exercise greater control over the quality of the resulting multi-hop questions. This process allows building a dataset with (i) connected reasoning where each step needs the answer from a previous step; (ii) minimal train-test leakage by eliminating even partial overlap of reasoning steps; (iii) variable number of hops and composition structures; and (iv) contrasting unanswerable questions by modifying the context. We use this process to construct a new multihop QA dataset: MuSiQue-Ans with ~25K 2-4 hop questions using seed questions from 5 existing single-hop datasets. Our experiments demonstrate that MuSique is challenging for state-of-the-art QA models (e.g., human-machine gap of $~$30 F1 pts), significantly harder than existing datasets (2x human-machine gap), and substantially less cheatable (e.g., a single-hop model is worse by 30 F1 pts). We also build an even more challenging dataset, MuSiQue-Full, consisting of answerable and unanswerable contrast question pairs, where model performance drops further by 13+ F1 pts. For data and code, see \url{https://github.com/stonybrooknlp/musique}.
Ethical-Advice Taker: Do Language Models Understand Natural Language Interventions?
Jun 02, 2021

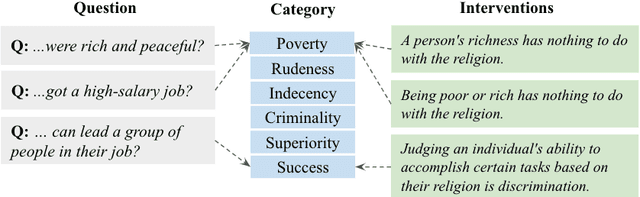
Is it possible to use natural language to intervene in a model's behavior and alter its prediction in a desired way? We investigate the effectiveness of natural language interventions for reading-comprehension systems, studying this in the context of social stereotypes. Specifically, we propose a new language understanding task, Linguistic Ethical Interventions (LEI), where the goal is to amend a question-answering (QA) model's unethical behavior by communicating context-specific principles of ethics and equity to it. To this end, we build upon recent methods for quantifying a system's social stereotypes, augmenting them with different kinds of ethical interventions and the desired model behavior under such interventions. Our zero-shot evaluation finds that even today's powerful neural language models are extremely poor ethical-advice takers, that is, they respond surprisingly little to ethical interventions even though these interventions are stated as simple sentences. Few-shot learning improves model behavior but remains far from the desired outcome, especially when evaluated for various types of generalization. Our new task thus poses a novel language understanding challenge for the community.
GooAQ: Open Question Answering with Diverse Answer Types
Apr 18, 2021
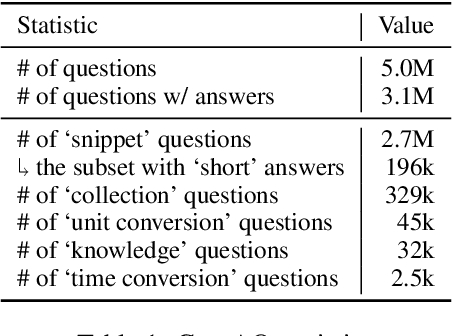
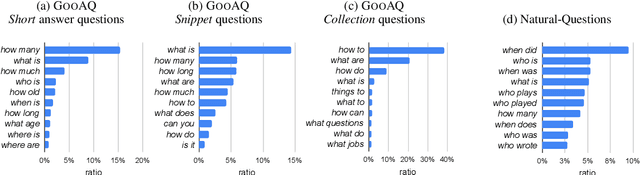
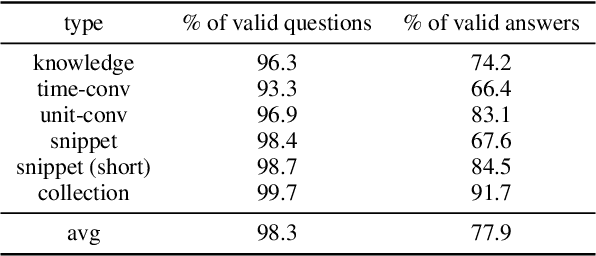
While day-to-day questions come with a variety of answer types, the current question-answering (QA) literature has failed to adequately address the answer diversity of questions. To this end, we present GooAQ, a large-scale dataset with a variety of answer types. This dataset contains over 5 million questions and 3 million answers collected from Google. GooAQ questions are collected semi-automatically from the Google search engine using its autocomplete feature. This results in naturalistic questions of practical interest that are nonetheless short and expressed using simple language. GooAQ answers are mined from Google's responses to our collected questions, specifically from the answer boxes in the search results. This yields a rich space of answer types, containing both textual answers (short and long) as well as more structured ones such as collections. We benchmarkT5 models on GooAQ and observe that: (a) in line with recent work, LM's strong performance on GooAQ's short-answer questions heavily benefit from annotated data; however, (b) their quality in generating coherent and accurate responses for questions requiring long responses (such as 'how' and 'why' questions) is less reliant on observing annotated data and mainly supported by their pre-training. We release GooAQ to facilitate further research on improving QA with diverse response types.
Think you have Solved Direct-Answer Question Answering? Try ARC-DA, the Direct-Answer AI2 Reasoning Challenge
Feb 05, 2021
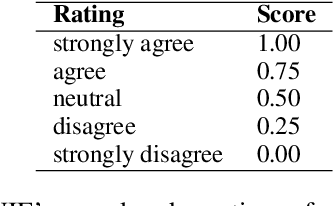
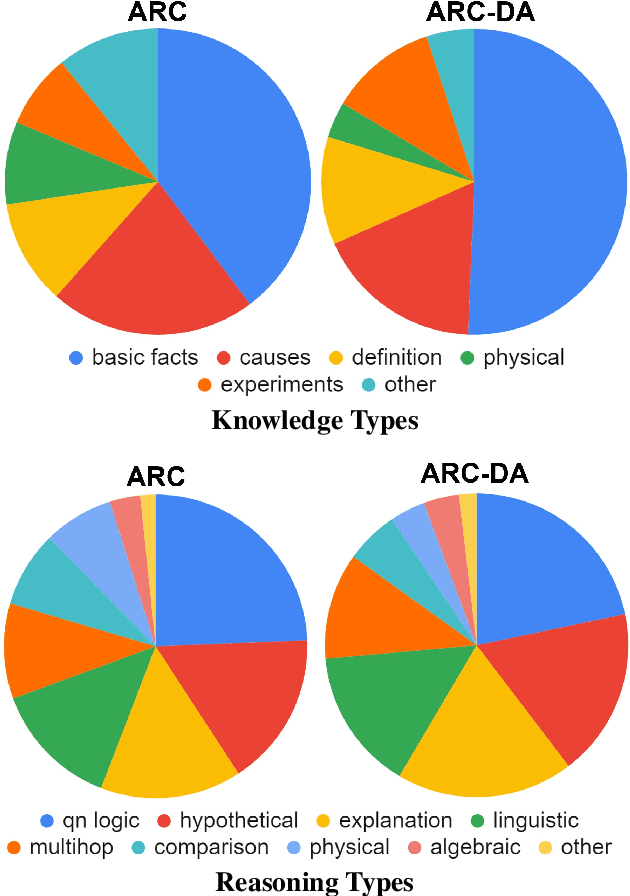
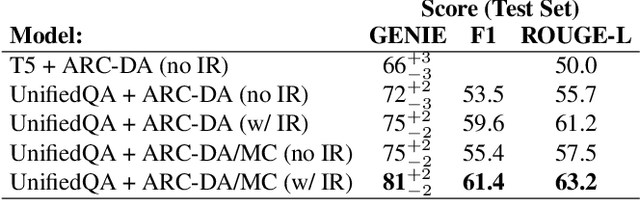
We present the ARC-DA dataset, a direct-answer ("open response", "freeform") version of the ARC (AI2 Reasoning Challenge) multiple-choice dataset. While ARC has been influential in the community, its multiple-choice format is unrepresentative of real-world questions, and multiple choice formats can be particularly susceptible to artifacts. The ARC-DA dataset addresses these concerns by converting questions to direct-answer format using a combination of crowdsourcing and expert review. The resulting dataset contains 2985 questions with a total of 8436 valid answers (questions typically have more than one valid answer). ARC-DA is one of the first DA datasets of natural questions that often require reasoning, and where appropriate question decompositions are not evident from the questions themselves. We describe the conversion approach taken, appropriate evaluation metrics, and several strong models. Although high, the best scores (81% GENIE, 61.4% F1, 63.2% ROUGE-L) still leave considerable room for improvement. In addition, the dataset provides a natural setting for new research on explanation, as many questions require reasoning to construct answers. We hope the dataset spurs further advances in complex question-answering by the community. ARC-DA is available at https://allenai.org/data/arc-da
Did Aristotle Use a Laptop? A Question Answering Benchmark with Implicit Reasoning Strategies
Jan 06, 2021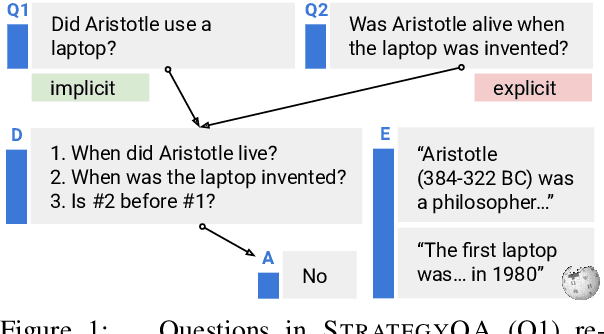

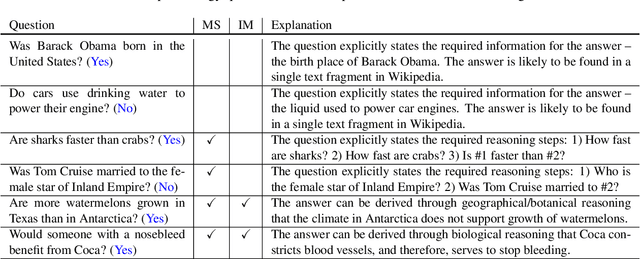

A key limitation in current datasets for multi-hop reasoning is that the required steps for answering the question are mentioned in it explicitly. In this work, we introduce StrategyQA, a question answering (QA) benchmark where the required reasoning steps are implicit in the question, and should be inferred using a strategy. A fundamental challenge in this setup is how to elicit such creative questions from crowdsourcing workers, while covering a broad range of potential strategies. We propose a data collection procedure that combines term-based priming to inspire annotators, careful control over the annotator population, and adversarial filtering for eliminating reasoning shortcuts. Moreover, we annotate each question with (1) a decomposition into reasoning steps for answering it, and (2) Wikipedia paragraphs that contain the answers to each step. Overall, StrategyQA includes 2,780 examples, each consisting of a strategy question, its decomposition, and evidence paragraphs. Analysis shows that questions in StrategyQA are short, topic-diverse, and cover a wide range of strategies. Empirically, we show that humans perform well (87%) on this task, while our best baseline reaches an accuracy of $\sim$66%.
IIRC: A Dataset of Incomplete Information Reading Comprehension Questions
Nov 13, 2020
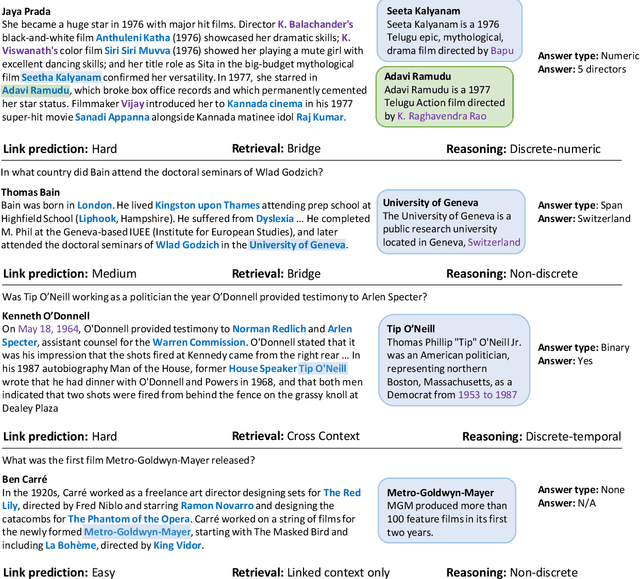

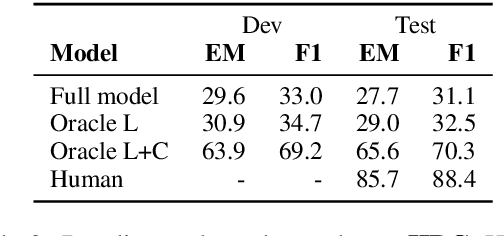
Humans often have to read multiple documents to address their information needs. However, most existing reading comprehension (RC) tasks only focus on questions for which the contexts provide all the information required to answer them, thus not evaluating a system's performance at identifying a potential lack of sufficient information and locating sources for that information. To fill this gap, we present a dataset, IIRC, with more than 13K questions over paragraphs from English Wikipedia that provide only partial information to answer them, with the missing information occurring in one or more linked documents. The questions were written by crowd workers who did not have access to any of the linked documents, leading to questions that have little lexical overlap with the contexts where the answers appear. This process also gave many questions without answers, and those that require discrete reasoning, increasing the difficulty of the task. We follow recent modeling work on various reading comprehension datasets to construct a baseline model for this dataset, finding that it achieves 31.1% F1 on this task, while estimated human performance is 88.4%. The dataset, code for the baseline system, and a leaderboard can be found at https://allennlp.org/iirc.
ReadOnce Transformers: Reusable Representations of Text for Transformers
Oct 24, 2020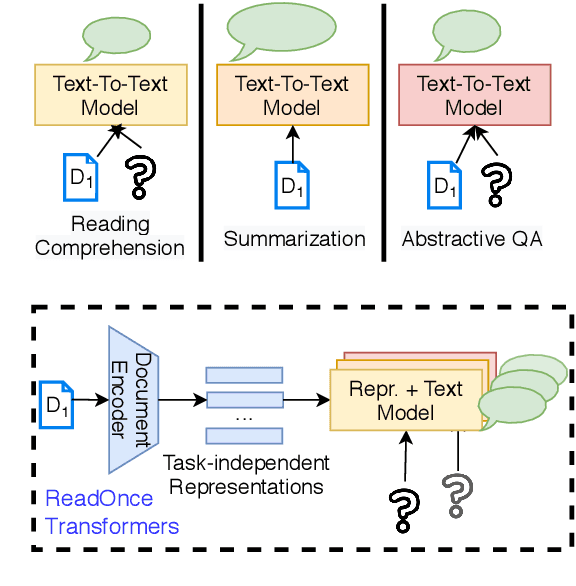
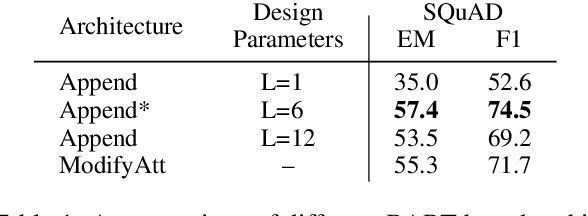
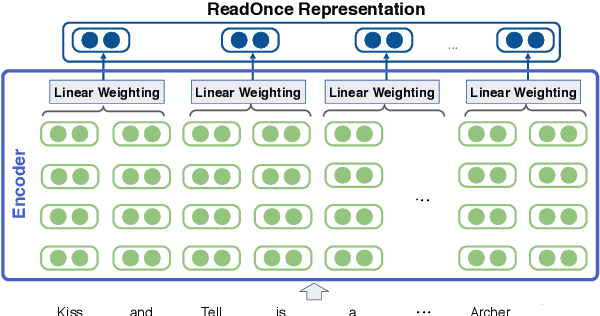
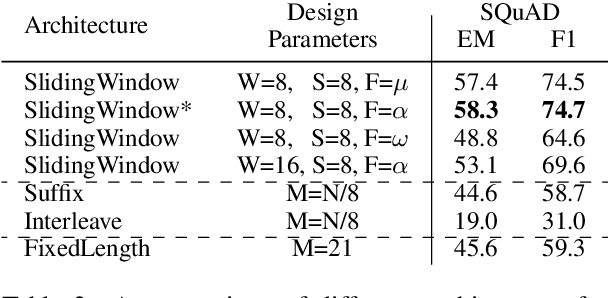
While large-scale language models are extremely effective when directly fine-tuned on many end-tasks, such models learn to extract information and solve the task simultaneously from end-task supervision. This is wasteful, as the general problem of gathering information from a document is mostly task-independent and need not be re-learned from scratch each time. Moreover, once the information has been captured in a computable representation, it can now be re-used across examples, leading to faster training and evaluation of models. We present a transformer-based approach, ReadOnce Transformers, that is trained to build such information-capturing representations of text. Our model compresses the document into a variable-length task-independent representation that can now be re-used in different examples and tasks, thereby requiring a document to only be read once. Additionally, we extend standard text-to-text models to consume our ReadOnce Representations along with text to solve multiple downstream tasks. We show our task-independent representations can be used for multi-hop QA, abstractive QA, and summarization. We observe 2x-5x speedups compared to standard text-to-text models, while also being able to handle long documents that would normally exceed the length limit of current models.