 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGame-Theoretic Robust Reinforcement Learning Handles Temporally-Coupled Perturbations
Jul 22, 2023Robust reinforcement learning (RL) seeks to train policies that can perform well under environment perturbations or adversarial attacks. Existing approaches typically assume that the space of possible perturbations remains the same across timesteps. However, in many settings, the space of possible perturbations at a given timestep depends on past perturbations. We formally introduce temporally-coupled perturbations, presenting a novel challenge for existing robust RL methods. To tackle this challenge, we propose GRAD, a novel game-theoretic approach that treats the temporally-coupled robust RL problem as a partially-observable two-player zero-sum game. By finding an approximate equilibrium in this game, GRAD ensures the agent's robustness against temporally-coupled perturbations. Empirical experiments on a variety of continuous control tasks demonstrate that our proposed approach exhibits significant robustness advantages compared to baselines against both standard and temporally-coupled attacks, in both state and action spaces.
On the Convergence of No-Regret Learning Dynamics in Time-Varying Games
Jan 26, 2023



Most of the literature on learning in games has focused on the restrictive setting where the underlying repeated game does not change over time. Much less is known about the convergence of no-regret learning algorithms in dynamic multiagent settings. In this paper, we characterize the convergence of \emph{optimistic gradient descent (OGD)} in time-varying games by drawing a strong connection with \emph{dynamic regret}. Our framework yields sharp convergence bounds for the equilibrium gap of OGD in zero-sum games parameterized on the \emph{minimal} first-order variation of the Nash equilibria and the second-order variation of the payoff matrices, subsuming known results for static games. Furthermore, we establish improved \emph{second-order} variation bounds under strong convexity-concavity, as long as each game is repeated multiple times. Our results also apply to time-varying \emph{general-sum} multi-player games via a bilinear formulation of correlated equilibria, which has novel implications for meta-learning and for obtaining refined variation-dependent regret bounds, addressing questions left open in prior papers. Finally, we leverage our framework to also provide new insights on dynamic regret guarantees in static games.
Computing equilibria by minimizing exploitability with best-response ensembles
Jan 20, 2023In this paper, we study the problem of computing an approximate Nash equilibrium of a continuous game. Such games naturally model many situations involving space, time, money, and other fine-grained resources or quantities. The standard measure of the closeness of a strategy profile to Nash equilibrium is exploitability, which measures how much utility players can gain from changing their strategy unilaterally. We introduce a new equilibrium-finding method that minimizes an approximation of the exploitability. This approximation employs a best-response ensemble for each player that maintains multiple candidate best responses for that player. In each iteration, the best-performing element of each ensemble is used in a gradient-based scheme to update the current strategy profile. The strategy profile and best-response ensembles are simultaneously trained to minimize and maximize the approximate exploitability, respectively. Experiments on a suite of benchmark games show that it outperforms previous methods.
Finding mixed-strategy equilibria of continuous-action games without gradients using randomized policy networks
Nov 29, 2022We study the problem of computing an approximate Nash equilibrium of continuous-action game without access to gradients. Such game access is common in reinforcement learning settings, where the environment is typically treated as a black box. To tackle this problem, we apply zeroth-order optimization techniques that combine smoothed gradient estimators with equilibrium-finding dynamics. We model players' strategies using artificial neural networks. In particular, we use randomized policy networks to model mixed strategies. These take noise in addition to an observation as input and can flexibly represent arbitrary observation-dependent, continuous-action distributions. Being able to model such mixed strategies is crucial for tackling continuous-action games that lack pure-strategy equilibria. We evaluate the performance of our method using an approximation of the Nash convergence metric from game theory, which measures how much players can benefit from unilaterally changing their strategy. We apply our method to continuous Colonel Blotto games, single-item and multi-item auctions, and a visibility game. The experiments show that our method can quickly find high-quality approximate equilibria. Furthermore, they show that the dimensionality of the input noise is crucial for performance. To our knowledge, this paper is the first to solve general continuous-action games with unrestricted mixed strategies and without any gradient information.
Near-Optimal $Φ$-Regret Learning in Extensive-Form Games
Aug 20, 2022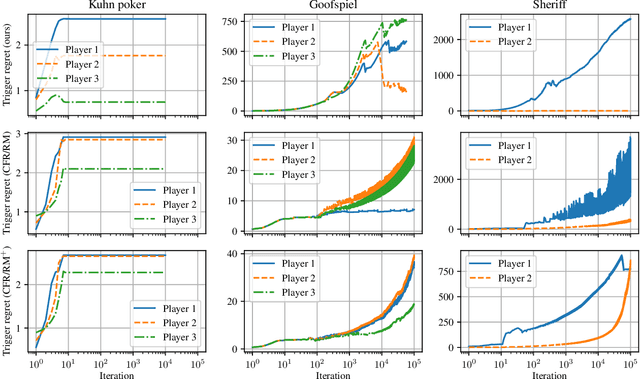
In this paper, we establish efficient and uncoupled learning dynamics so that, when employed by all players in multiplayer perfect-recall imperfect-information extensive-form games, the \emph{trigger regret} of each player grows as $O(\log T)$ after $T$ repetitions of play. This improves exponentially over the prior best known trigger-regret bound of $O(T^{1/4})$, and settles a recent open question by Bai et al. (2022). As an immediate consequence, we guarantee convergence to the set of \emph{extensive-form correlated equilibria} and \emph{coarse correlated equilibria} at a near-optimal rate of $\frac{\log T}{T}$. Building on prior work, at the heart of our construction lies a more general result regarding fixed points deriving from rational functions with \emph{polynomial degree}, a property that we establish for the fixed points of \emph{(coarse) trigger deviation functions}. Moreover, our construction leverages a refined \textit{regret circuit} for the convex hull, which -- unlike prior guarantees -- preserves the \emph{RVU property} introduced by Syrgkanis et al. (NIPS, 2015); this observation has an independent interest in establishing near-optimal regret under learning dynamics based on a CFR-type decomposition of the regret.
Self-Play PSRO: Toward Optimal Populations in Two-Player Zero-Sum Games
Jul 13, 2022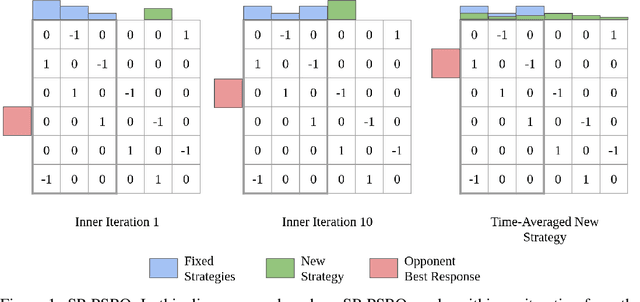
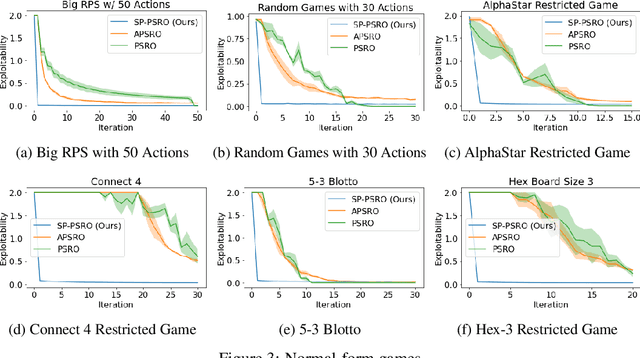

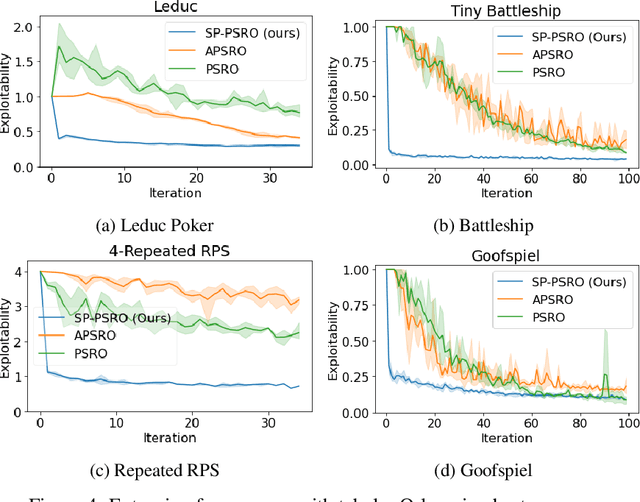
In competitive two-agent environments, deep reinforcement learning (RL) methods based on the \emph{Double Oracle (DO)} algorithm, such as \emph{Policy Space Response Oracles (PSRO)} and \emph{Anytime PSRO (APSRO)}, iteratively add RL best response policies to a population. Eventually, an optimal mixture of these population policies will approximate a Nash equilibrium. However, these methods might need to add all deterministic policies before converging. In this work, we introduce \emph{Self-Play PSRO (SP-PSRO)}, a method that adds an approximately optimal stochastic policy to the population in each iteration. Instead of adding only deterministic best responses to the opponent's least exploitable population mixture, SP-PSRO also learns an approximately optimal stochastic policy and adds it to the population as well. As a result, SP-PSRO empirically tends to converge much faster than APSRO and in many games converges in just a few iterations.
Near-Optimal No-Regret Learning for General Convex Games
Jun 20, 2022
A recent line of work has established uncoupled learning dynamics such that, when employed by all players in a game, each player's \emph{regret} after $T$ repetitions grows polylogarithmically in $T$, an exponential improvement over the traditional guarantees within the no-regret framework. However, so far these results have only been limited to certain classes of games with structured strategy spaces -- such as normal-form and extensive-form games. The question as to whether $O(\text{polylog} T)$ regret bounds can be obtained for general convex and compact strategy sets -- which occur in many fundamental models in economics and multiagent systems -- while retaining efficient strategy updates is an important question. In this paper, we answer this in the positive by establishing the first uncoupled learning algorithm with $O(\log T)$ per-player regret in general \emph{convex games}, that is, games with concave utility functions supported on arbitrary convex and compact strategy sets. Our learning dynamics are based on an instantiation of optimistic follow-the-regularized-leader over an appropriately \emph{lifted} space using a \emph{self-concordant regularizer} that is, peculiarly, not a barrier for the feasible region. Further, our learning dynamics are efficiently implementable given access to a proximal oracle for the convex strategy set, leading to $O(\log\log T)$ per-iteration complexity; we also give extensions when access to only a \emph{linear} optimization oracle is assumed. Finally, we adapt our dynamics to guarantee $O(\sqrt{T})$ regret in the adversarial regime. Even in those special cases where prior results apply, our algorithm improves over the state-of-the-art regret bounds either in terms of the dependence on the number of iterations or on the dimension of the strategy sets.
ESCHER: Eschewing Importance Sampling in Games by Computing a History Value Function to Estimate Regret
Jun 08, 2022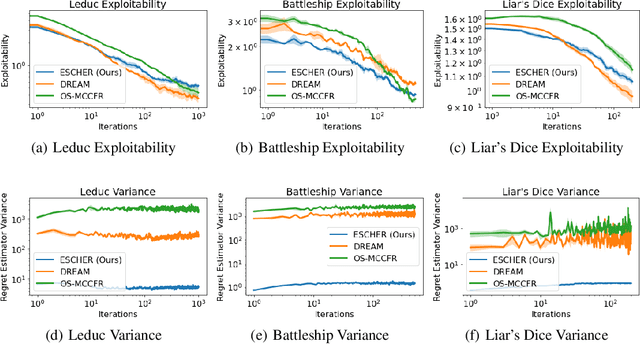

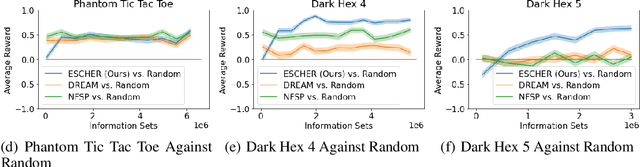

Recent techniques for approximating Nash equilibria in very large games leverage neural networks to learn approximately optimal policies (strategies). One promising line of research uses neural networks to approximate counterfactual regret minimization (CFR) or its modern variants. DREAM, the only current CFR-based neural method that is model free and therefore scalable to very large games, trains a neural network on an estimated regret target that can have extremely high variance due to an importance sampling term inherited from Monte Carlo CFR (MCCFR). In this paper we propose an unbiased model-free method that does not require any importance sampling. Our method, ESCHER, is principled and is guaranteed to converge to an approximate Nash equilibrium with high probability in the tabular case. We show that the variance of the estimated regret of a tabular version of ESCHER with an oracle value function is significantly lower than that of outcome sampling MCCFR and tabular DREAM with an oracle value function. We then show that a deep learning version of ESCHER outperforms the prior state of the art -- DREAM and neural fictitious self play (NFSP) -- and the difference becomes dramatic as game size increases.
Uncoupled Learning Dynamics with $O(\log T)$ Swap Regret in Multiplayer Games
Apr 25, 2022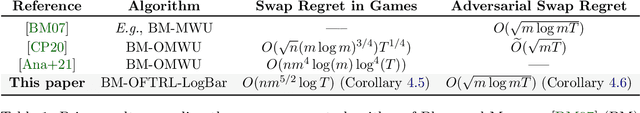
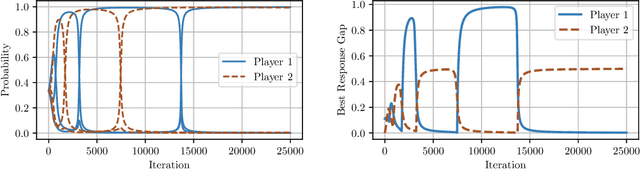
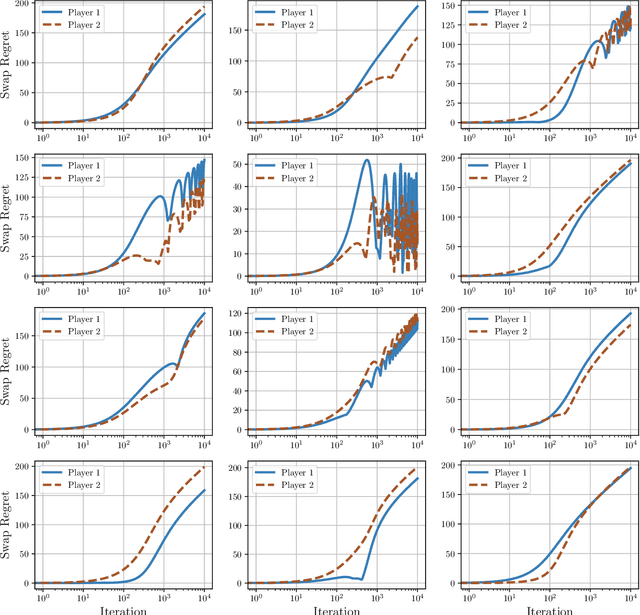
In this paper we establish efficient and \emph{uncoupled} learning dynamics so that, when employed by all players in a general-sum multiplayer game, the \emph{swap regret} of each player after $T$ repetitions of the game is bounded by $O(\log T)$, improving over the prior best bounds of $O(\log^4 (T))$. At the same time, we guarantee optimal $O(\sqrt{T})$ swap regret in the adversarial regime as well. To obtain these results, our primary contribution is to show that when all players follow our dynamics with a \emph{time-invariant} learning rate, the \emph{second-order path lengths} of the dynamics up to time $T$ are bounded by $O(\log T)$, a fundamental property which could have further implications beyond near-optimally bounding the (swap) regret. Our proposed learning dynamics combine in a novel way \emph{optimistic} regularized learning with the use of \emph{self-concordant barriers}. Further, our analysis is remarkably simple, bypassing the cumbersome framework of higher-order smoothness recently developed by Daskalakis, Fishelson, and Golowich (NeurIPS'21).
Structural Analysis of Branch-and-Cut and the Learnability of Gomory Mixed Integer Cuts
Apr 15, 2022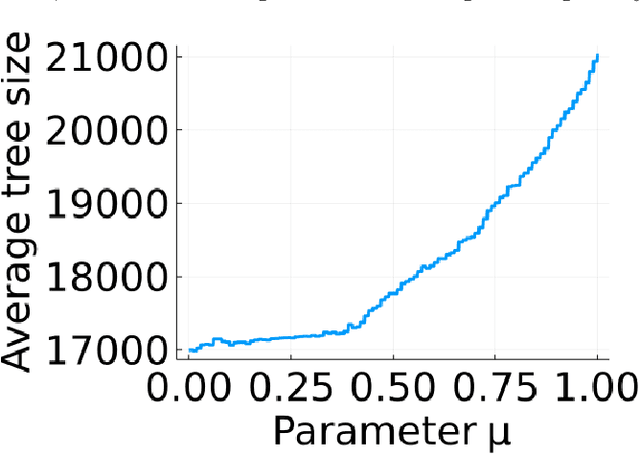
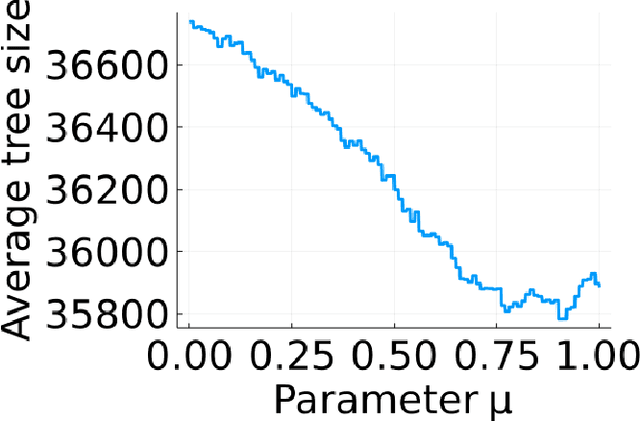
The incorporation of cutting planes within the branch-and-bound algorithm, known as branch-and-cut, forms the backbone of modern integer programming solvers. These solvers are the foremost method for solving discrete optimization problems and thus have a vast array of applications in machine learning, operations research, and many other fields. Choosing cutting planes effectively is a major research topic in the theory and practice of integer programming. We conduct a novel structural analysis of branch-and-cut that pins down how every step of the algorithm is affected by changes in the parameters defining the cutting planes added to the input integer program. Our main application of this analysis is to derive sample complexity guarantees for using machine learning to determine which cutting planes to apply during branch-and-cut. These guarantees apply to infinite families of cutting planes, such as the family of Gomory mixed integer cuts, which are responsible for the main breakthrough speedups of integer programming solvers. We exploit geometric and combinatorial structure of branch-and-cut in our analysis, which provides a key missing piece for the recent generalization theory of branch-and-cut.