 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSITAR: Semi-supervised Image Transformer for Action Recognition
Sep 04, 2024



Recognizing actions from a limited set of labeled videos remains a challenge as annotating visual data is not only tedious but also can be expensive due to classified nature. Moreover, handling spatio-temporal data using deep $3$D transformers for this can introduce significant computational complexity. In this paper, our objective is to address video action recognition in a semi-supervised setting by leveraging only a handful of labeled videos along with a collection of unlabeled videos in a compute efficient manner. Specifically, we rearrange multiple frames from the input videos in row-column form to construct super images. Subsequently, we capitalize on the vast pool of unlabeled samples and employ contrastive learning on the encoded super images. Our proposed approach employs two pathways to generate representations for temporally augmented super images originating from the same video. Specifically, we utilize a 2D image-transformer to generate representations and apply a contrastive loss function to minimize the similarity between representations from different videos while maximizing the representations of identical videos. Our method demonstrates superior performance compared to existing state-of-the-art approaches for semi-supervised action recognition across various benchmark datasets, all while significantly reducing computational costs.
Unlearning Trojans in Large Language Models: A Comparison Between Natural Language and Source Code
Aug 22, 2024This work investigates the application of Machine Unlearning (MU) for mitigating the impact of trojans embedded in conventional large language models of natural language (Text-LLMs) and large language models of code (Code-LLMs) We propose a novel unlearning approach, LYA, that leverages both gradient ascent and elastic weight consolidation, a Fisher Information Matrix (FIM) based regularization technique, to unlearn trojans from poisoned models. We compare the effectiveness of LYA against conventional techniques like fine-tuning, retraining, and vanilla gradient ascent. The subject models we investigate are BERT and CodeBERT, for sentiment analysis and code defect detection tasks, respectively. Our findings demonstrate that the combination of gradient ascent and FIM-based regularization, as done in LYA, outperforms existing methods in removing the trojan's influence from the poisoned model, while preserving its original functionality. To the best of our knowledge, this is the first work that compares and contrasts MU of trojans in LLMs, in the NL and Coding domain.
Harnessing the Power of LLMs: Automating Unit Test Generation for High-Performance Computing
Jul 06, 2024



Unit testing is crucial in software engineering for ensuring quality. However, it's not widely used in parallel and high-performance computing software, particularly scientific applications, due to their smaller, diverse user base and complex logic. These factors make unit testing challenging and expensive, as it requires specialized knowledge and existing automated tools are often ineffective. To address this, we propose an automated method for generating unit tests for such software, considering their unique features like complex logic and parallel processing. Recently, large language models (LLMs) have shown promise in coding and testing. We explored the capabilities of Davinci (text-davinci-002) and ChatGPT (gpt-3.5-turbo) in creating unit tests for C++ parallel programs. Our results show that LLMs can generate mostly correct and comprehensive unit tests, although they have some limitations, such as repetitive assertions and blank test cases.
Trojans in Large Language Models of Code: A Critical Review through a Trigger-Based Taxonomy
May 05, 2024



Large language models (LLMs) have provided a lot of exciting new capabilities in software development. However, the opaque nature of these models makes them difficult to reason about and inspect. Their opacity gives rise to potential security risks, as adversaries can train and deploy compromised models to disrupt the software development process in the victims' organization. This work presents an overview of the current state-of-the-art trojan attacks on large language models of code, with a focus on triggers -- the main design point of trojans -- with the aid of a novel unifying trigger taxonomy framework. We also aim to provide a uniform definition of the fundamental concepts in the area of trojans in Code LLMs. Finally, we draw implications of findings on how code models learn on trigger design.
On Trojan Signatures in Large Language Models of Code
Mar 07, 2024Trojan signatures, as described by Fields et al. (2021), are noticeable differences in the distribution of the trojaned class parameters (weights) and the non-trojaned class parameters of the trojaned model, that can be used to detect the trojaned model. Fields et al. (2021) found trojan signatures in computer vision classification tasks with image models, such as, Resnet, WideResnet, Densenet, and VGG. In this paper, we investigate such signatures in the classifier layer parameters of large language models of source code. Our results suggest that trojan signatures could not generalize to LLMs of code. We found that trojaned code models are stubborn, even when the models were poisoned under more explicit settings (finetuned with pre-trained weights frozen). We analyzed nine trojaned models for two binary classification tasks: clone and defect detection. To the best of our knowledge, this is the first work to examine weight-based trojan signature revelation techniques for large-language models of code and furthermore to demonstrate that detecting trojans only from the weights in such models is a hard problem.
A Study of Variable-Role-based Feature Enrichment in Neural Models of Code
Mar 12, 2023Although deep neural models substantially reduce the overhead of feature engineering, the features readily available in the inputs might significantly impact training cost and the performance of the models. In this paper, we explore the impact of an unsuperivsed feature enrichment approach based on variable roles on the performance of neural models of code. The notion of variable roles (as introduced in the works of Sajaniemi et al. [Refs. 1,2]) has been found to help students' abilities in programming. In this paper, we investigate if this notion would improve the performance of neural models of code. To the best of our knowledge, this is the first work to investigate how Sajaniemi et al.'s concept of variable roles can affect neural models of code. In particular, we enrich a source code dataset by adding the role of individual variables in the dataset programs, and thereby conduct a study on the impact of variable role enrichment in training the Code2Seq model. In addition, we shed light on some challenges and opportunities in feature enrichment for neural code intelligence models.
Study of Distractors in Neural Models of Code
Mar 03, 2023



Finding important features that contribute to the prediction of neural models is an active area of research in explainable AI. Neural models are opaque and finding such features sheds light on a better understanding of their predictions. In contrast, in this work, we present an inverse perspective of distractor features: features that cast doubt about the prediction by affecting the model's confidence in its prediction. Understanding distractors provide a complementary view of the features' relevance in the predictions of neural models. In this paper, we apply a reduction-based technique to find distractors and provide our preliminary results of their impacts and types. Our experiments across various tasks, models, and datasets of code reveal that the removal of tokens can have a significant impact on the confidence of models in their predictions and the categories of tokens can also play a vital role in the model's confidence. Our study aims to enhance the transparency of models by emphasizing those tokens that significantly influence the confidence of the models.
Co-channel Interference Management for the Next-Generation Heterogeneous Networks using Deep Leaning
Jan 06, 2023



The connectivity of public-safety mobile users (MU) in the co-existence of a public-safety network (PSN), unmanned aerial vehicles (UAVs), and LTE-based railway networks (LRN) needs a thorough investigation. UAVs are deployed as mobile base stations (BSs) for cell-edge coverage enhancement for MU. The co-existence of heterogeneous networks gives rise to the issue of co-channel interference due to the utilization of the same frequency band. By considering both sharing and non-sharing of radio access channels (RAC), we analyze co-channel interference in the downlink system of PSN, UAV, and LRN. As the LRN control signal demands high reliability and low latency, we provide higher priority to LRN users when allocating resources from the LRN RAC shared with MUs. Moreover, UAVs are deployed at the cell edge to increase the performance of cell-edge users. Therefore, interference control techniques enable LRN, PSN, and UAVs to cohabit in a scenario of sharing RAC. By offloading more PSN UEs to the LRN or UAVs, the resource utilization of the LRN and UAVs BSs is enhanced. In this paper, we aim to adopt deep learning (DL) based on enhanced inter-cell-interference coordination (eICIC) and further enhanced ICIC (FeICIC) strategies to deal with the interference from the PSN to the LRN and UAVs. Among LRN, PSN BS, and UAVs, a DL-based coordinated multipoint (CoMP) link technique is utilized to enhance the performance of PSN MUs. Therefore, if radio access channels are shared, utilization of DL-based FeICIC and CoMP for coordinated scheduling gives the best performance.
Syntax-Guided Program Reduction for Understanding Neural Code Intelligence Models
May 28, 2022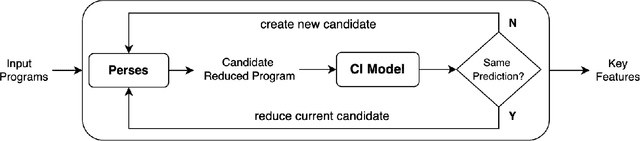
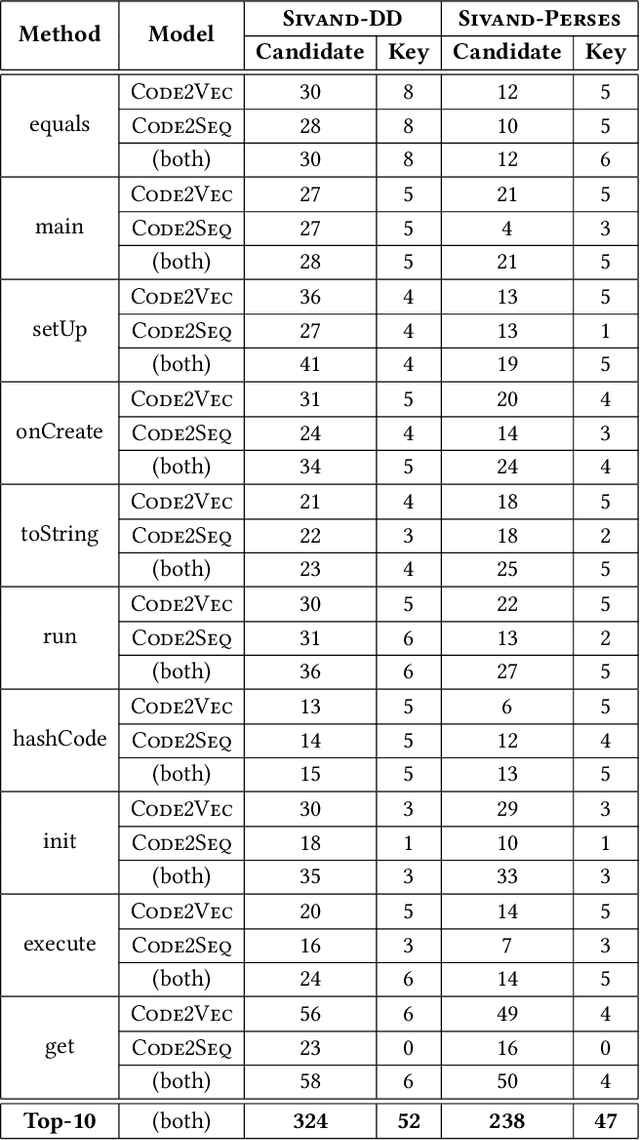
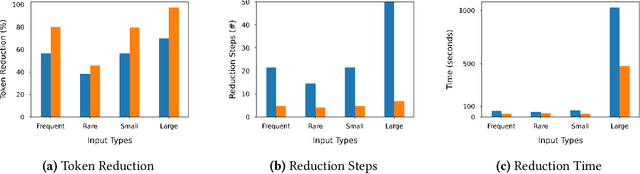
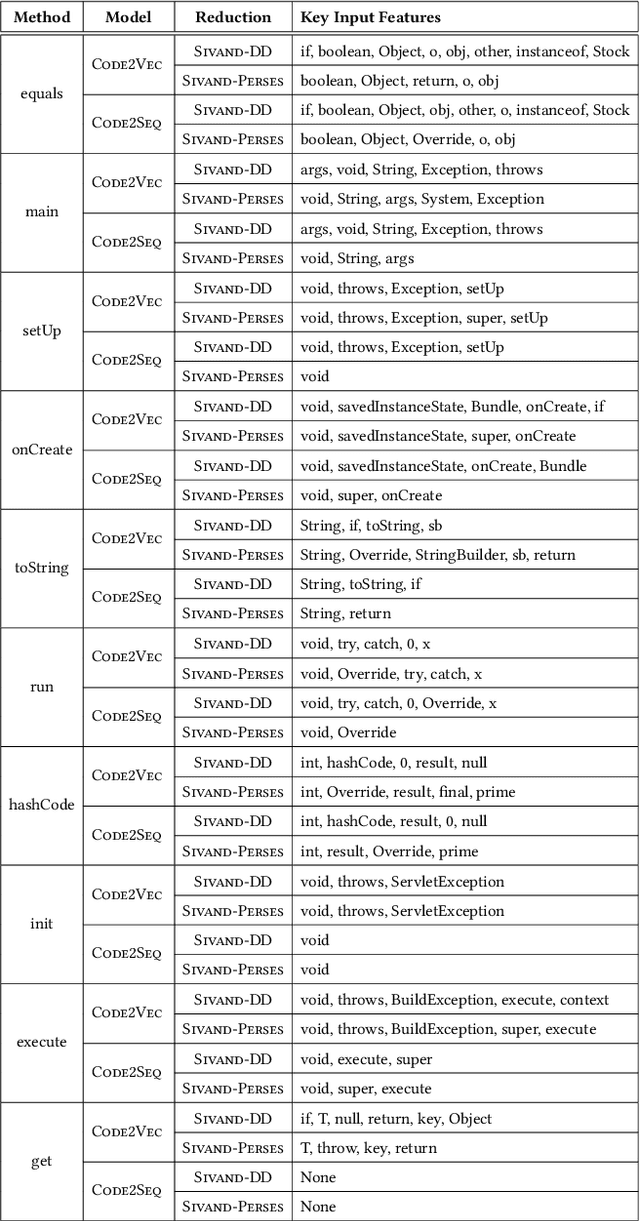
Neural code intelligence (CI) models are opaque black-boxes and offer little insight on the features they use in making predictions. This opacity may lead to distrust in their prediction and hamper their wider adoption in safety-critical applications. Recently, input program reduction techniques have been proposed to identify key features in the input programs to improve the transparency of CI models. However, this approach is syntax-unaware and does not consider the grammar of the programming language. In this paper, we apply a syntax-guided program reduction technique that considers the grammar of the input programs during reduction. Our experiments on multiple models across different types of input programs show that the syntax-guided program reduction technique is faster and provides smaller sets of key tokens in reduced programs. We also show that the key tokens could be used in generating adversarial examples for up to 65% of the input programs.
Testing the Robustness of a BiLSTM-based Structural Story Classifier
Jan 03, 2022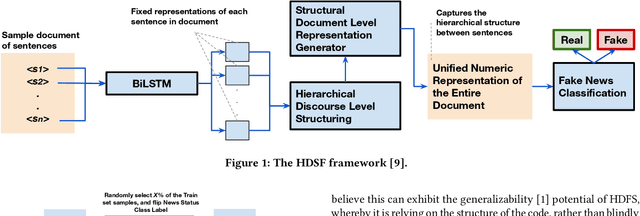
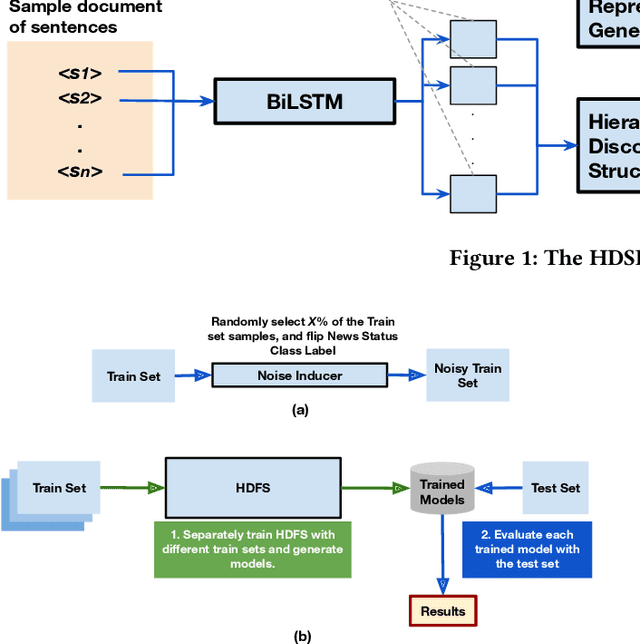
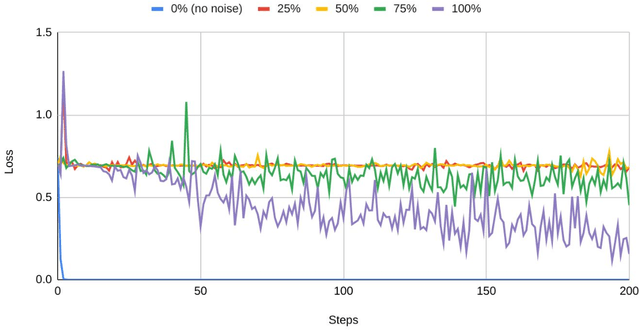
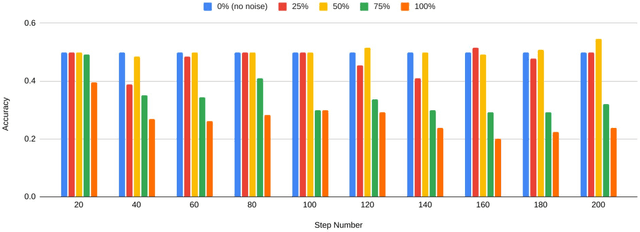
The growing prevalence of counterfeit stories on the internet has fostered significant interest towards fast and scalable detection of fake news in the machine learning community. While several machine learning techniques for this purpose have emerged, we observe that there is a need to evaluate the impact of noise on these techniques' performance, where noise constitutes news articles being mistakenly labeled as fake (or real). This work takes a step in that direction, where we examine the impact of noise on a state-of-the-art, structural model based on BiLSTM (Bidirectional Long-Short Term Model) for fake news detection, Hierarchical Discourse-level Structure for Fake News Detection by Karimi and Tang (Reference no. 9).