 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAPS: A Multilingual Benchmark for Global Agent Performance and Security
May 21, 2025Agentic AI systems, which build on Large Language Models (LLMs) and interact with tools and memory, have rapidly advanced in capability and scope. Yet, since LLMs have been shown to struggle in multilingual settings, typically resulting in lower performance and reduced safety, agentic systems risk inheriting these limitations. This raises concerns about the global accessibility of such systems, as users interacting in languages other than English may encounter unreliable or security-critical agent behavior. Despite growing interest in evaluating agentic AI, existing benchmarks focus exclusively on English, leaving multilingual settings unexplored. To address this gap, we propose MAPS, a multilingual benchmark suite designed to evaluate agentic AI systems across diverse languages and tasks. MAPS builds on four widely used agentic benchmarks - GAIA (real-world tasks), SWE-bench (code generation), MATH (mathematical reasoning), and the Agent Security Benchmark (security). We translate each dataset into ten diverse languages, resulting in 805 unique tasks and 8,855 total language-specific instances. Our benchmark suite enables a systematic analysis of how multilingual contexts affect agent performance and robustness. Empirically, we observe consistent degradation in both performance and security when transitioning from English to other languages, with severity varying by task and correlating with the amount of translated input. Building on these findings, we provide actionable recommendations to guide agentic AI systems development and assessment under multilingual settings. This work establishes a standardized evaluation framework, encouraging future research towards equitable, reliable, and globally accessible agentic AI. MAPS benchmark suite is publicly available at https://huggingface.co/datasets/Fujitsu-FRE/MAPS
X-Detect: Explainable Adversarial Patch Detection for Object Detectors in Retail
Jul 02, 2023



Object detection models, which are widely used in various domains (such as retail), have been shown to be vulnerable to adversarial attacks. Existing methods for detecting adversarial attacks on object detectors have had difficulty detecting new real-life attacks. We present X-Detect, a novel adversarial patch detector that can: i) detect adversarial samples in real time, allowing the defender to take preventive action; ii) provide explanations for the alerts raised to support the defender's decision-making process, and iii) handle unfamiliar threats in the form of new attacks. Given a new scene, X-Detect uses an ensemble of explainable-by-design detectors that utilize object extraction, scene manipulation, and feature transformation techniques to determine whether an alert needs to be raised. X-Detect was evaluated in both the physical and digital space using five different attack scenarios (including adaptive attacks) and the COCO dataset and our new Superstore dataset. The physical evaluation was performed using a smart shopping cart setup in real-world settings and included 17 adversarial patch attacks recorded in 1,700 adversarial videos. The results showed that X-Detect outperforms the state-of-the-art methods in distinguishing between benign and adversarial scenes for all attack scenarios while maintaining a 0% FPR (no false alarms) and providing actionable explanations for the alerts raised. A demo is available.
Seeds Don't Lie: An Adaptive Watermarking Framework for Computer Vision Models
Nov 24, 2022



In recent years, various watermarking methods were suggested to detect computer vision models obtained illegitimately from their owners, however they fail to demonstrate satisfactory robustness against model extraction attacks. In this paper, we present an adaptive framework to watermark a protected model, leveraging the unique behavior present in the model due to a unique random seed initialized during the model training. This watermark is used to detect extracted models, which have the same unique behavior, indicating an unauthorized usage of the protected model's intellectual property (IP). First, we show how an initial seed for random number generation as part of model training produces distinct characteristics in the model's decision boundaries, which are inherited by extracted models and present in their decision boundaries, but aren't present in non-extracted models trained on the same data-set with a different seed. Based on our findings, we suggest the Robust Adaptive Watermarking (RAW) Framework, which utilizes the unique behavior present in the protected and extracted models to generate a watermark key-set and verification model. We show that the framework is robust to (1) unseen model extraction attacks, and (2) extracted models which undergo a blurring method (e.g., weight pruning). We evaluate the framework's robustness against a naive attacker (unaware that the model is watermarked), and an informed attacker (who employs blurring strategies to remove watermarked behavior from an extracted model), and achieve outstanding (i.e., >0.9) AUC values. Finally, we show that the framework is robust to model extraction attacks with different structure and/or architecture than the protected model.
First to Possess His Statistics: Data-Free Model Extraction Attack on Tabular Data
Sep 30, 2021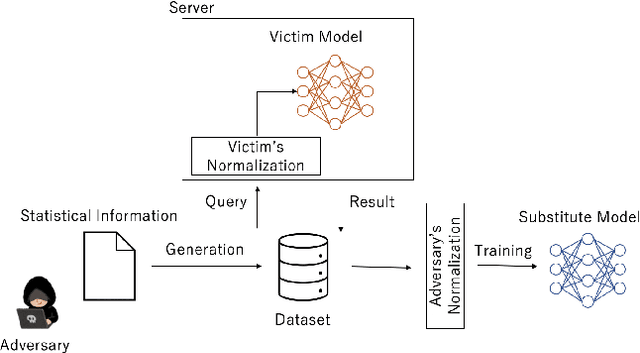
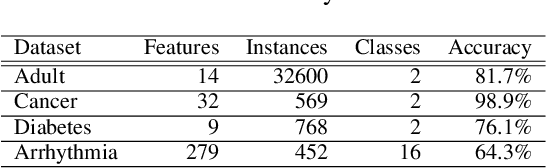
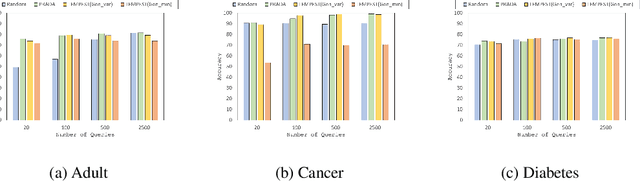

Model extraction attacks are a kind of attacks where an adversary obtains a machine learning model whose performance is comparable with one of the victim model through queries and their results. This paper presents a novel model extraction attack, named TEMPEST, applicable on tabular data under a practical data-free setting. Whereas model extraction is more challenging on tabular data due to normalization, TEMPEST no longer needs initial samples that previous attacks require; instead, it makes use of publicly available statistics to generate query samples. Experiments show that our attack can achieve the same level of performance as the previous attacks. Moreover, we identify that the use of mean and variance as statistics for query generation and the use of the same normalization process as the victim model can improve the performance of our attack. We also discuss a possibility whereby TEMPEST is executed in the real world through an experiment with a medical diagnosis dataset. We plan to release the source code for reproducibility and a reference to subsequent works.