 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Intent is a Latent Variable: Stateful Trust Inference for Securing Multimodal Agentic RAG
Feb 24, 2026Current stateless defences for multimodal agentic RAG fail to detect adversarial strategies that distribute malicious semantics across retrieval, planning, and generation components. We formulate this security challenge as a Partially Observable Markov Decision Process (POMDP), where adversarial intent is a latent variable inferred from noisy multi-stage observations. We introduce MMA-RAG^T, an inference-time control framework governed by a Modular Trust Agent (MTA) that maintains an approximate belief state via structured LLM reasoning. Operating as a model-agnostic overlay, MMA-RAGT mediates a configurable set of internal checkpoints to enforce stateful defence-in-depth. Extensive evaluation on 43,774 instances demonstrates a 6.50x average reduction factor in Attack Success Rate relative to undefended baselines, with negligible utility cost. Crucially, a factorial ablation validates our theoretical bounds: while statefulness and spatial coverage are individually necessary (26.4 pp and 13.6 pp gains respectively), stateless multi-point intervention can yield zero marginal benefit under homogeneous stateless filtering when checkpoint detections are perfectly correlated.
Inference-Time Backdoors via Hidden Instructions in LLM Chat Templates
Feb 05, 2026Open-weight language models are increasingly used in production settings, raising new security challenges. One prominent threat in this context is backdoor attacks, in which adversaries embed hidden behaviors in language models that activate under specific conditions. Previous work has assumed that adversaries have access to training pipelines or deployment infrastructure. We propose a novel attack surface requiring neither, which utilizes the chat template. Chat templates are executable Jinja2 programs invoked at every inference call, occupying a privileged position between user input and model processing. We show that an adversary who distributes a model with a maliciously modified template can implant an inference-time backdoor without modifying model weights, poisoning training data, or controlling runtime infrastructure. We evaluated this attack vector by constructing template backdoors targeting two objectives: degrading factual accuracy and inducing emission of attacker-controlled URLs, and applied them across eighteen models spanning seven families and four inference engines. Under triggered conditions, factual accuracy drops from 90% to 15% on average while attacker-controlled URLs are emitted with success rates exceeding 80%; benign inputs show no measurable degradation. Backdoors generalize across inference runtimes and evade all automated security scans applied by the largest open-weight distribution platform. These results establish chat templates as a reliable and currently undefended attack surface in the LLM supply chain.
AgenTRIM: Tool Risk Mitigation for Agentic AI
Jan 18, 2026AI agents are autonomous systems that combine LLMs with external tools to solve complex tasks. While such tools extend capability, improper tool permissions introduce security risks such as indirect prompt injection and tool misuse. We characterize these failures as unbalanced tool-driven agency. Agents may retain unnecessary permissions (excessive agency) or fail to invoke required tools (insufficient agency), amplifying the attack surface and reducing performance. We introduce AgenTRIM, a framework for detecting and mitigating tool-driven agency risks without altering an agent's internal reasoning. AgenTRIM addresses these risks through complementary offline and online phases. Offline, AgenTRIM reconstructs and verifies the agent's tool interface from code and execution traces. At runtime, it enforces per-step least-privilege tool access through adaptive filtering and status-aware validation of tool calls. Evaluating on the AgentDojo benchmark, AgenTRIM substantially reduces attack success while maintaining high task performance. Additional experiments show robustness to description-based attacks and effective enforcement of explicit safety policies. Together, these results demonstrate that AgenTRIM provides a practical, capability-preserving approach to safer tool use in LLM-based agents.
MAPS: A Multilingual Benchmark for Global Agent Performance and Security
May 21, 2025Agentic AI systems, which build on Large Language Models (LLMs) and interact with tools and memory, have rapidly advanced in capability and scope. Yet, since LLMs have been shown to struggle in multilingual settings, typically resulting in lower performance and reduced safety, agentic systems risk inheriting these limitations. This raises concerns about the global accessibility of such systems, as users interacting in languages other than English may encounter unreliable or security-critical agent behavior. Despite growing interest in evaluating agentic AI, existing benchmarks focus exclusively on English, leaving multilingual settings unexplored. To address this gap, we propose MAPS, a multilingual benchmark suite designed to evaluate agentic AI systems across diverse languages and tasks. MAPS builds on four widely used agentic benchmarks - GAIA (real-world tasks), SWE-bench (code generation), MATH (mathematical reasoning), and the Agent Security Benchmark (security). We translate each dataset into ten diverse languages, resulting in 805 unique tasks and 8,855 total language-specific instances. Our benchmark suite enables a systematic analysis of how multilingual contexts affect agent performance and robustness. Empirically, we observe consistent degradation in both performance and security when transitioning from English to other languages, with severity varying by task and correlating with the amount of translated input. Building on these findings, we provide actionable recommendations to guide agentic AI systems development and assessment under multilingual settings. This work establishes a standardized evaluation framework, encouraging future research towards equitable, reliable, and globally accessible agentic AI. MAPS benchmark suite is publicly available at https://huggingface.co/datasets/Fujitsu-FRE/MAPS
Identifying Memorization of Diffusion Models through p-Laplace Analysis
May 13, 2025Diffusion models, today's leading image generative models, estimate the score function, i.e. the gradient of the log probability of (perturbed) data samples, without direct access to the underlying probability distribution. This work investigates whether the estimated score function can be leveraged to compute higher-order differentials, namely p-Laplace operators. We show here these operators can be employed to identify memorized training data. We propose a numerical p-Laplace approximation based on the learned score functions, showing its effectiveness in identifying key features of the probability landscape. We analyze the structured case of Gaussian mixture models, and demonstrate the results carry-over to image generative models, where memorization identification based on the p-Laplace operator is performed for the first time.
Manifold Induced Biases for Zero-shot and Few-shot Detection of Generated Images
Apr 21, 2025



Distinguishing between real and AI-generated images, commonly referred to as 'image detection', presents a timely and significant challenge. Despite extensive research in the (semi-)supervised regime, zero-shot and few-shot solutions have only recently emerged as promising alternatives. Their main advantage is in alleviating the ongoing data maintenance, which quickly becomes outdated due to advances in generative technologies. We identify two main gaps: (1) a lack of theoretical grounding for the methods, and (2) significant room for performance improvements in zero-shot and few-shot regimes. Our approach is founded on understanding and quantifying the biases inherent in generated content, where we use these quantities as criteria for characterizing generated images. Specifically, we explore the biases of the implicit probability manifold, captured by a pre-trained diffusion model. Through score-function analysis, we approximate the curvature, gradient, and bias towards points on the probability manifold, establishing criteria for detection in the zero-shot regime. We further extend our contribution to the few-shot setting by employing a mixture-of-experts methodology. Empirical results across 20 generative models demonstrate that our method outperforms current approaches in both zero-shot and few-shot settings. This work advances the theoretical understanding and practical usage of generated content biases through the lens of manifold analysis.
Insights and Current Gaps in Open-Source LLM Vulnerability Scanners: A Comparative Analysis
Oct 21, 2024



This report presents a comparative analysis of open-source vulnerability scanners for conversational large language models (LLMs). As LLMs become integral to various applications, they also present potential attack surfaces, exposed to security risks such as information leakage and jailbreak attacks. Our study evaluates prominent scanners - Garak, Giskard, PyRIT, and CyberSecEval - that adapt red-teaming practices to expose these vulnerabilities. We detail the distinctive features and practical use of these scanners, outline unifying principles of their design and perform quantitative evaluations to compare them. These evaluations uncover significant reliability issues in detecting successful attacks, highlighting a fundamental gap for future development. Additionally, we contribute a preliminary labelled dataset, which serves as an initial step to bridge this gap. Based on the above, we provide strategic recommendations to assist organizations choose the most suitable scanner for their red-teaming needs, accounting for customizability, test suite comprehensiveness, and industry-specific use cases.
The Branch Not Taken: Predicting Branching in Online Conversations
Apr 21, 2024



Multi-participant discussions tend to unfold in a tree structure rather than a chain structure. Branching may occur for multiple reasons -- from the asynchronous nature of online platforms to a conscious decision by an interlocutor to disengage with part of the conversation. Predicting branching and understanding the reasons for creating new branches is important for many downstream tasks such as summarization and thread disentanglement and may help develop online spaces that encourage users to engage in online discussions in more meaningful ways. In this work, we define the novel task of branch prediction and propose GLOBS (Global Branching Score) -- a deep neural network model for predicting branching. GLOBS is evaluated on three large discussion forums from Reddit, achieving significant improvements over an array of competitive baselines and demonstrating better transferability. We affirm that structural, temporal, and linguistic features contribute to GLOBS success and find that branching is associated with a greater number of conversation participants and tends to occur in earlier levels of the conversation tree. We publicly release GLOBS and our implementation of all baseline models to allow reproducibility and promote further research on this important task.
Automatic Machine Learning Derived from Scholarly Big Data
Mar 06, 2020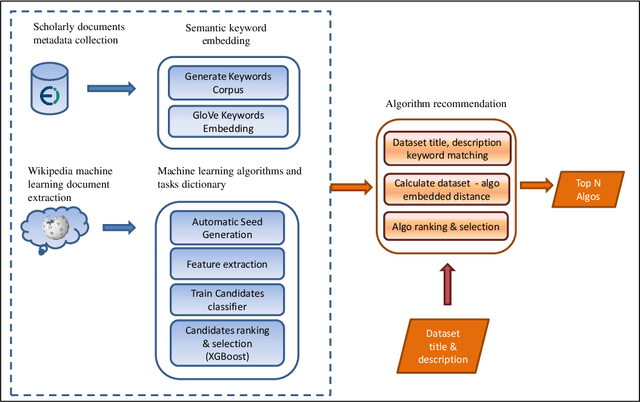
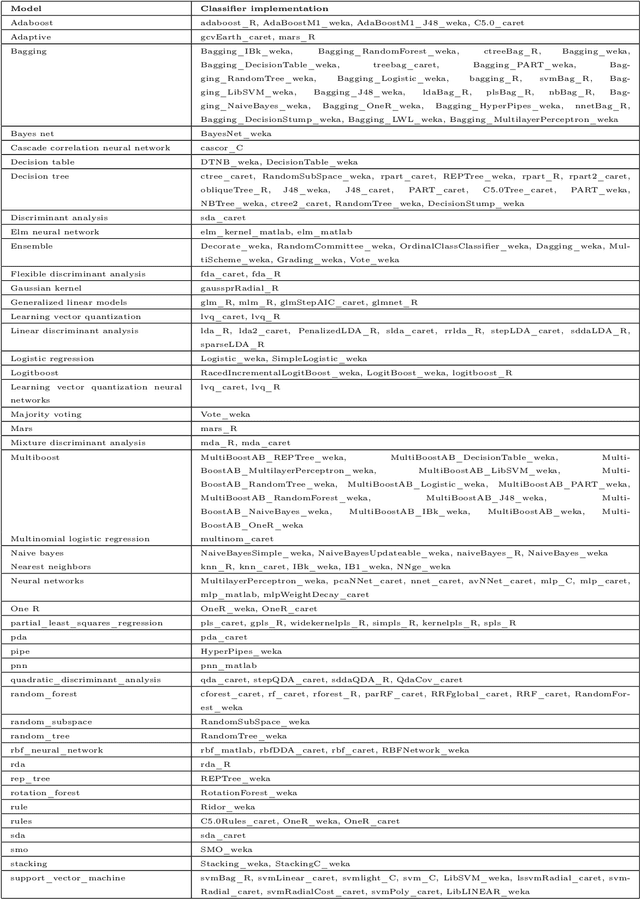
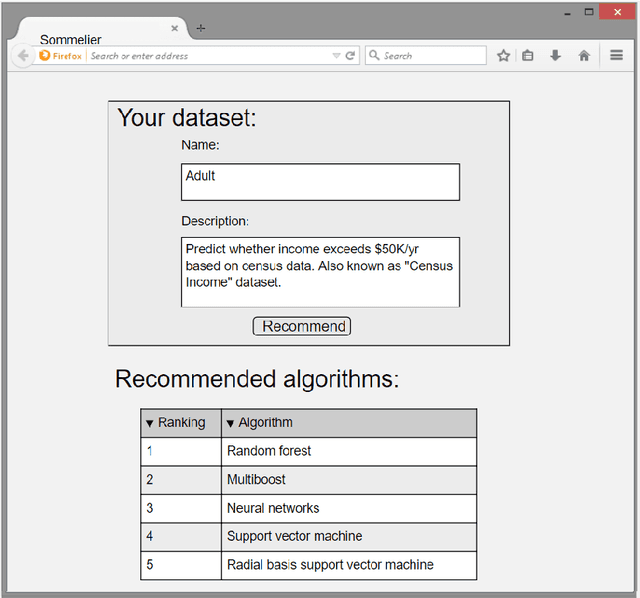

One of the challenging aspects of applying machine learning is the need to identify the algorithms that will perform best for a given dataset. This process can be difficult, time consuming and often requires a great deal of domain knowledge. We present Sommelier, an expert system for recommending the machine learning algorithms that should be applied on a previously unseen dataset. Sommelier is based on word embedding representations of the domain knowledge extracted from a large corpus of academic publications. When presented with a new dataset and its problem description, Sommelier leverages a recommendation model trained on the word embedding representation to provide a ranked list of the most relevant algorithms to be used on the dataset. We demonstrate Sommelier's effectiveness by conducting an extensive evaluation on 121 publicly available datasets and 53 classification algorithms. The top algorithms recommended for each dataset by Sommelier were able to achieve on average 97.7% of the optimal accuracy of all surveyed algorithms.
Sequence Preserving Network Traffic Generation
Feb 23, 2020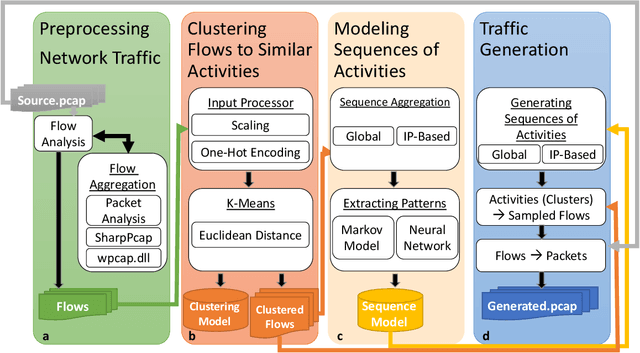


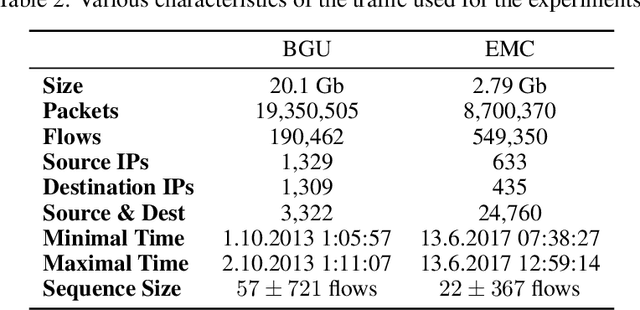
We present the Network Traffic Generator (NTG), a framework for perturbing recorded network traffic with the purpose of generating diverse but realistic background traffic for network simulation and what-if analysis in enterprise environments. The framework preserves many characteristics of the original traffic recorded in an enterprise, as well as sequences of network activities. Using the proposed framework, the original traffic flows are profiled using 200 cross-protocol features. The traffic is aggregated into flows of packets between IP pairs and clustered into groups of similar network activities. Sequences of network activities are then extracted. We examined two methods for extracting sequences of activities: a Markov model and a neural language model. Finally, new traffic is generated using the extracted model. We developed a prototype of the framework and conducted extensive experiments based on two real network traffic collections. Hypothesis testing was used to examine the difference between the distribution of original and generated features, showing that 30-100\% of the extracted features were preserved. Small differences between n-gram perplexities in sequences of network activities in the original and generated traffic, indicate that sequences of network activities were well preserved.