 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDummy Backdoor as a Defense: Removing Unknown Backdoors via Shared Internal Mechanisms for Generative LLMs
Jun 10, 2026Backdoor attacks pose a serious threat to the safety and reliability of Large Language Models (LLMs), as they cause models to behave normally on clean inputs while producing attacker-specified responses when hidden triggers are present. Removing such unknown backdoors is particularly challenging when the defender does not know the backdoor attack types or the internal mechanisms formed through backdoor training. In this work, we propose a simple but effective backdoor removal method based on shared internal mechanisms across different backdoors. First, we show that different backdoors with the same task (attack objective) induce similar trigger-activated changes in the internal activations. Motivated by this observation, our method intentionally embeds a backdoor with a known trigger (\emph{dummy backdoor}) and then removes it through further fine-tuning on dummy-triggered inputs paired with clean responses. Since the dummy backdoor and the unknown backdoor can rely on shared internal mechanisms, removing the dummy backdoor also reduces the effect of the unknown backdoor. We evaluate our method on three backdoor attack types across multiple model families. Experimental results show that our method substantially reduces the attack success rate of the unknown backdoor while preserving model utility, outperforming representative existing defense methods in both backdoor removal effectiveness and utility preservation. These findings suggest that a defender-controllable backdoor can serve as a helpful proxy for mitigating unknown backdoors in generative LLMs.
Robust Backdoor Removal by Reconstructing Trigger-Activated Changes in Latent Representation
Nov 12, 2025



Backdoor attacks pose a critical threat to machine learning models, causing them to behave normally on clean data but misclassify poisoned data into a poisoned class. Existing defenses often attempt to identify and remove backdoor neurons based on Trigger-Activated Changes (TAC) which is the activation differences between clean and poisoned data. These methods suffer from low precision in identifying true backdoor neurons due to inaccurate estimation of TAC values. In this work, we propose a novel backdoor removal method by accurately reconstructing TAC values in the latent representation. Specifically, we formulate the minimal perturbation that forces clean data to be classified into a specific class as a convex quadratic optimization problem, whose optimal solution serves as a surrogate for TAC. We then identify the poisoned class by detecting statistically small $L^2$ norms of perturbations and leverage the perturbation of the poisoned class in fine-tuning to remove backdoors. Experiments on CIFAR-10, GTSRB, and TinyImageNet demonstrated that our approach consistently achieves superior backdoor suppression with high clean accuracy across different attack types, datasets, and architectures, outperforming existing defense methods.
First to Possess His Statistics: Data-Free Model Extraction Attack on Tabular Data
Sep 30, 2021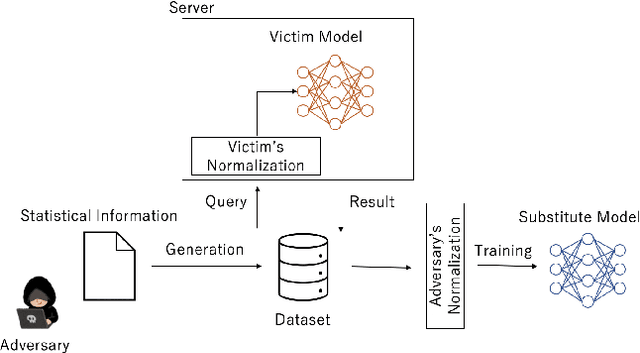
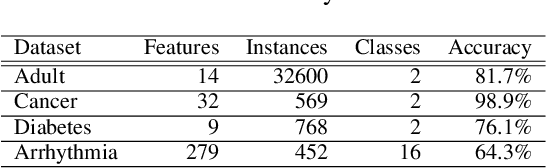
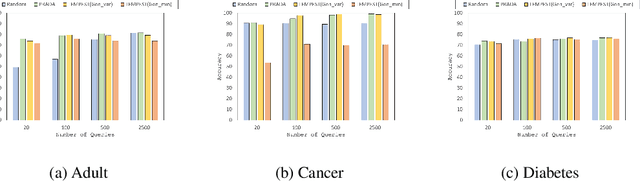

Model extraction attacks are a kind of attacks where an adversary obtains a machine learning model whose performance is comparable with one of the victim model through queries and their results. This paper presents a novel model extraction attack, named TEMPEST, applicable on tabular data under a practical data-free setting. Whereas model extraction is more challenging on tabular data due to normalization, TEMPEST no longer needs initial samples that previous attacks require; instead, it makes use of publicly available statistics to generate query samples. Experiments show that our attack can achieve the same level of performance as the previous attacks. Moreover, we identify that the use of mean and variance as statistics for query generation and the use of the same normalization process as the victim model can improve the performance of our attack. We also discuss a possibility whereby TEMPEST is executed in the real world through an experiment with a medical diagnosis dataset. We plan to release the source code for reproducibility and a reference to subsequent works.