 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinear Partial Monitoring for Sequential Decision-Making: Algorithms, Regret Bounds and Applications
Feb 07, 2023Partial monitoring is an expressive framework for sequential decision-making with an abundance of applications, including graph-structured and dueling bandits, dynamic pricing and transductive feedback models. We survey and extend recent results on the linear formulation of partial monitoring that naturally generalizes the standard linear bandit setting. The main result is that a single algorithm, information-directed sampling (IDS), is (nearly) worst-case rate optimal in all finite-action games. We present a simple and unified analysis of stochastic partial monitoring, and further extend the model to the contextual and kernelized setting.
Regret Bounds for Information-Directed Reinforcement Learning
Jun 09, 2022Information-directed sampling (IDS) has revealed its potential as a data-efficient algorithm for reinforcement learning (RL). However, theoretical understanding of IDS for Markov Decision Processes (MDPs) is still limited. We develop novel information-theoretic tools to bound the information ratio and cumulative information gain about the learning target. Our theoretical results shed light on the importance of choosing the learning target such that the practitioners can balance the computation and regret bounds. As a consequence, we derive prior-free Bayesian regret bounds for vanilla-IDS which learns the whole environment under tabular finite-horizon MDPs. In addition, we propose a computationally-efficient regularized-IDS that maximizes an additive form rather than the ratio form and show that it enjoys the same regret bound as vanilla-IDS. With the aid of rate-distortion theory, we improve the regret bound by learning a surrogate, less informative environment. Furthermore, we extend our analysis to linear MDPs and prove similar regret bounds for Thompson sampling as a by-product.
Distributed Contextual Linear Bandits with Minimax Optimal Communication Cost
May 26, 2022

We study distributed contextual linear bandits with stochastic contexts, where $N$ agents act cooperatively to solve a linear bandit-optimization problem with $d$-dimensional features. For this problem, we propose a distributed batch elimination version of the LinUCB algorithm, DisBE-LUCB, where the agents share information among each other through a central server. We prove that over $T$ rounds ($NT$ actions in total) the communication cost of DisBE-LUCB is only $\tilde{\mathcal{O}}(dN)$ and its regret is at most $\tilde{\mathcal{O}}(\sqrt{dNT})$, which is of the same order as that incurred by an optimal single-agent algorithm for $NT$ rounds. Remarkably, we derive an information-theoretic lower bound on the communication cost of the distributed contextual linear bandit problem with stochastic contexts, and prove that our proposed algorithm is nearly minimax optimal in terms of \emph{both regret and communication cost}. Finally, we propose DecBE-LUCB, a fully decentralized version of DisBE-LUCB, which operates without a central server, where agents share information with their \emph{immediate neighbors} through a carefully designed consensus procedure.
Contextual Information-Directed Sampling
May 22, 2022
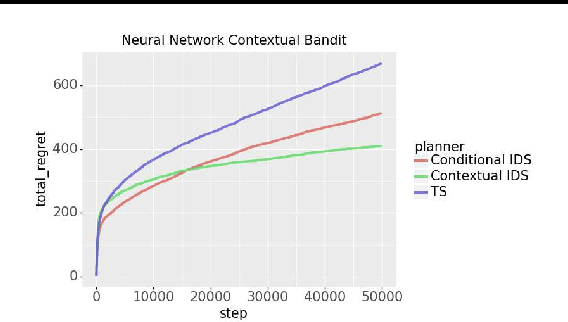

Information-directed sampling (IDS) has recently demonstrated its potential as a data-efficient reinforcement learning algorithm. However, it is still unclear what is the right form of information ratio to optimize when contextual information is available. We investigate the IDS design through two contextual bandit problems: contextual bandits with graph feedback and sparse linear contextual bandits. We provably demonstrate the advantage of contextual IDS over conditional IDS and emphasize the importance of considering the context distribution. The main message is that an intelligent agent should invest more on the actions that are beneficial for the future unseen contexts while the conditional IDS can be myopic. We further propose a computationally-efficient version of contextual IDS based on Actor-Critic and evaluate it empirically on a neural network contextual bandit.
Minimax Regret for Partial Monitoring: Infinite Outcomes and Rustichini's Regret
Feb 22, 2022We show that a version of the generalised information ratio of Lattimore and Gyorgy (2020) determines the asymptotic minimax regret for all finite-action partial monitoring games provided that (a) the standard definition of regret is used but the latent space where the adversary plays is potentially infinite; or (b) the regret introduced by Rustichini (1999) is used and the latent space is finite. Our results are complemented by a number of examples. For any $p \in [1/2,1]$ there exists an infinite partial monitoring game for which the minimax regret over $n$ rounds is $n^p$ up to subpolynomial factors and there exist finite games for which the minimax Rustichini regret is $n^{4/7}$ up to subpolynomial factors.
Variational Bayesian Optimistic Sampling
Oct 29, 2021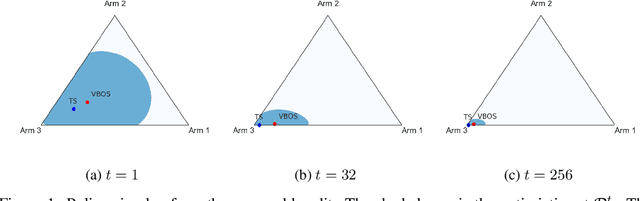
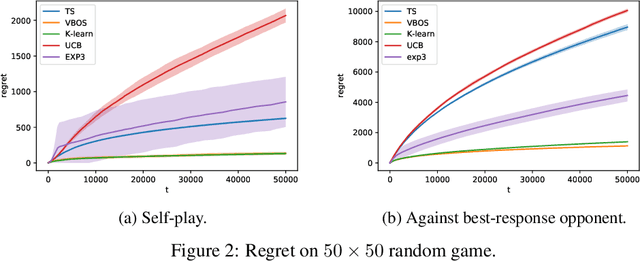
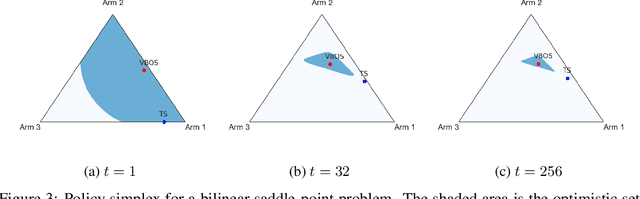
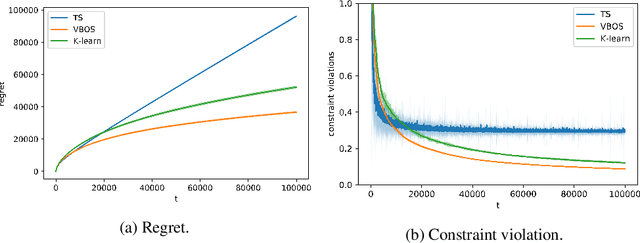
We consider online sequential decision problems where an agent must balance exploration and exploitation. We derive a set of Bayesian `optimistic' policies which, in the stochastic multi-armed bandit case, includes the Thompson sampling policy. We provide a new analysis showing that any algorithm producing policies in the optimistic set enjoys $\tilde O(\sqrt{AT})$ Bayesian regret for a problem with $A$ actions after $T$ rounds. We extend the regret analysis for optimistic policies to bilinear saddle-point problems which include zero-sum matrix games and constrained bandits as special cases. In this case we show that Thompson sampling can produce policies outside of the optimistic set and suffer linear regret in some instances. Finding a policy inside the optimistic set amounts to solving a convex optimization problem and we call the resulting algorithm `variational Bayesian optimistic sampling' (VBOS). The procedure works for any posteriors, \ie, it does not require the posterior to have any special properties, such as log-concavity, unimodality, or smoothness. The variational view of the problem has many useful properties, including the ability to tune the exploration-exploitation tradeoff, add regularization, incorporate constraints, and linearly parameterize the policy.
Minimax Regret for Bandit Convex Optimisation of Ridge Functions
Jun 06, 2021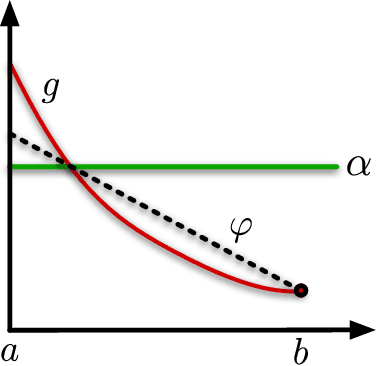
We analyse adversarial bandit convex optimisation with an adversary that is restricted to playing functions of the form $f_t(x) = g_t(\langle x, \theta\rangle)$ for convex $g_t : \mathbb R \to \mathbb R$ and unknown $\theta \in \mathbb R^d$ that is homogeneous over time. We provide a short information-theoretic proof that the minimax regret is at most $O(d \sqrt{n} \log(n \operatorname{diam}(\mathcal K)))$ where $n$ is the number of interactions, $d$ the dimension and $\operatorname{diam}(\mathcal K)$ is the diameter of the constraint set.
Bandit Phase Retrieval
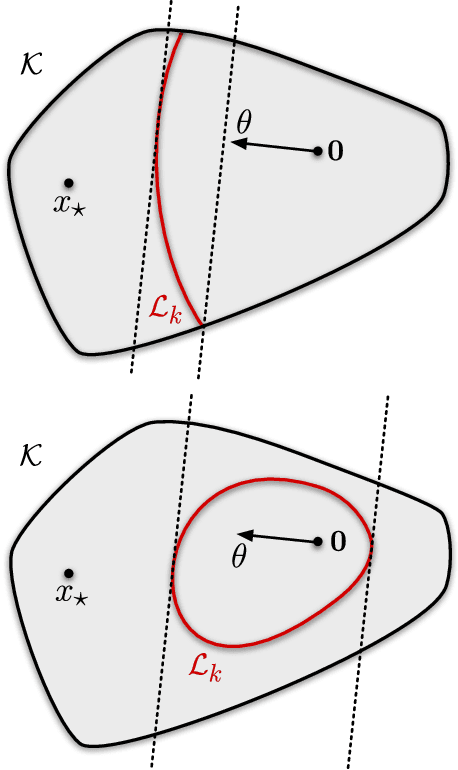
Jun 04, 2021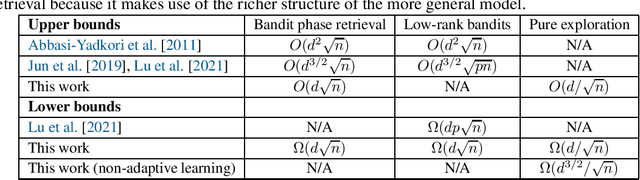
We study a bandit version of phase retrieval where the learner chooses actions $(A_t)_{t=1}^n$ in the $d$-dimensional unit ball and the expected reward is $\langle A_t, \theta_\star\rangle^2$ where $\theta_\star \in \mathbb R^d$ is an unknown parameter vector. We prove that the minimax cumulative regret in this problem is $\smash{\tilde \Theta(d \sqrt{n})}$, which improves on the best known bounds by a factor of $\smash{\sqrt{d}}$. We also show that the minimax simple regret is $\smash{\tilde \Theta(d / \sqrt{n})}$ and that this is only achievable by an adaptive algorithm. Our analysis shows that an apparently convincing heuristic for guessing lower bounds can be misleading and that uniform bounds on the information ratio for information-directed sampling are not sufficient for optimal regret.
Information Directed Sampling for Sparse Linear Bandits
May 29, 2021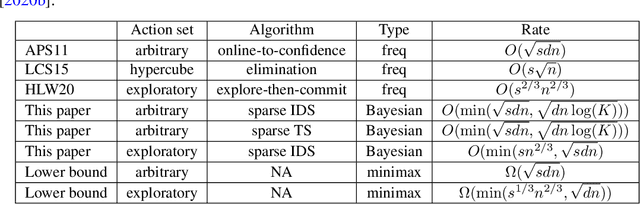
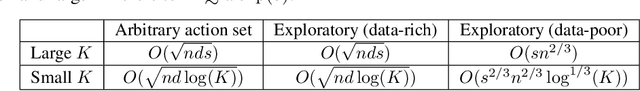
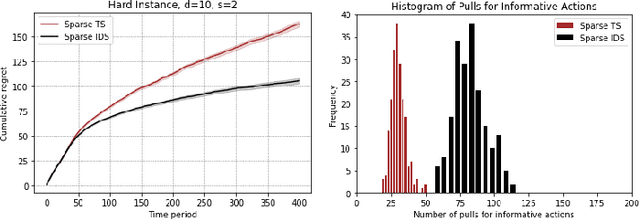
Stochastic sparse linear bandits offer a practical model for high-dimensional online decision-making problems and have a rich information-regret structure. In this work we explore the use of information-directed sampling (IDS), which naturally balances the information-regret trade-off. We develop a class of information-theoretic Bayesian regret bounds that nearly match existing lower bounds on a variety of problem instances, demonstrating the adaptivity of IDS. To efficiently implement sparse IDS, we propose an empirical Bayesian approach for sparse posterior sampling using a spike-and-slab Gaussian-Laplace prior. Numerical results demonstrate significant regret reductions by sparse IDS relative to several baselines.
On the Optimality of Batch Policy Optimization Algorithms
Apr 06, 2021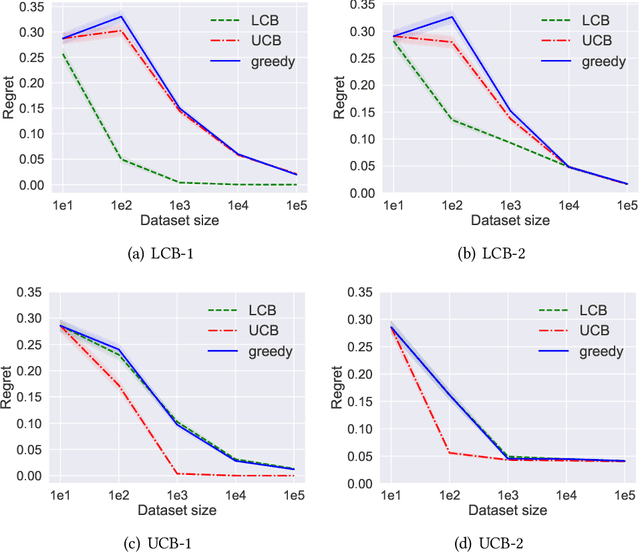
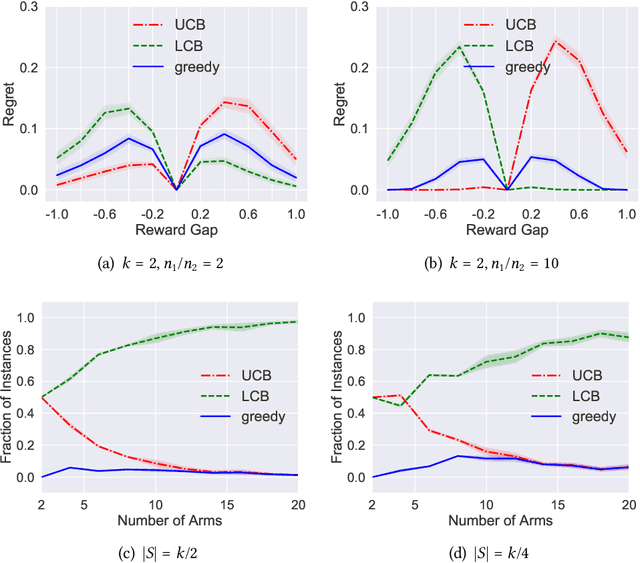
Batch policy optimization considers leveraging existing data for policy construction before interacting with an environment. Although interest in this problem has grown significantly in recent years, its theoretical foundations remain under-developed. To advance the understanding of this problem, we provide three results that characterize the limits and possibilities of batch policy optimization in the finite-armed stochastic bandit setting. First, we introduce a class of confidence-adjusted index algorithms that unifies optimistic and pessimistic principles in a common framework, which enables a general analysis. For this family, we show that any confidence-adjusted index algorithm is minimax optimal, whether it be optimistic, pessimistic or neutral. Our analysis reveals that instance-dependent optimality, commonly used to establish optimality of on-line stochastic bandit algorithms, cannot be achieved by any algorithm in the batch setting. In particular, for any algorithm that performs optimally in some environment, there exists another environment where the same algorithm suffers arbitrarily larger regret. Therefore, to establish a framework for distinguishing algorithms, we introduce a new weighted-minimax criterion that considers the inherent difficulty of optimal value prediction. We demonstrate how this criterion can be used to justify commonly used pessimistic principles for batch policy optimization.