 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlind and neural network-guided convolutional beamformer for joint denoising, dereverberation, and source separation
Aug 04, 2021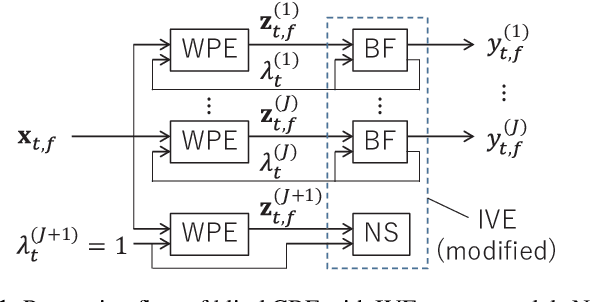
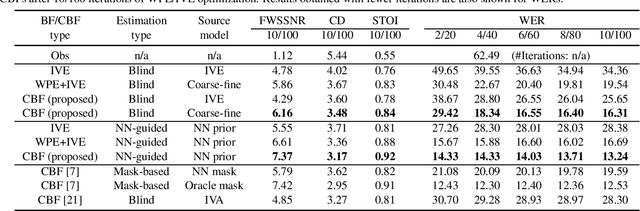
This paper proposes an approach for optimizing a Convolutional BeamFormer (CBF) that can jointly perform denoising (DN), dereverberation (DR), and source separation (SS). First, we develop a blind CBF optimization algorithm that requires no prior information on the sources or the room acoustics, by extending a conventional joint DR and SS method. For making the optimization computationally tractable, we incorporate two techniques into the approach: the Source-Wise Factorization (SW-Fact) of a CBF and the Independent Vector Extraction (IVE). To further improve the performance, we develop a method that integrates a neural network(NN) based source power spectra estimation with CBF optimization by an inverse-Gamma prior. Experiments using noisy reverberant mixtures reveal that our proposed method with both blind and NN-guided scenarios greatly outperforms the conventional state-of-the-art NN-supported mask-based CBF in terms of the improvement in automatic speech recognition and signal distortion reduction performance.
Independent Deeply Learned Tensor Analysis for Determined Audio Source Separation
Jun 10, 2021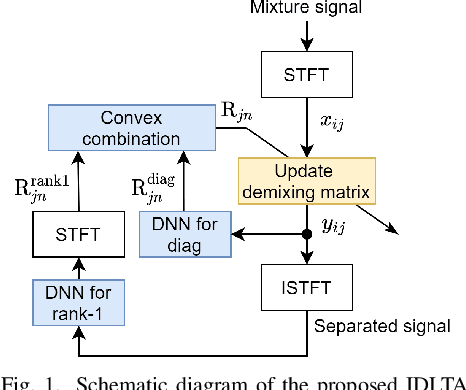

We address the determined audio source separation problem in the time-frequency domain. In independent deeply learned matrix analysis (IDLMA), it is assumed that the inter-frequency correlation of each source spectrum is zero, which is inappropriate for modeling nonstationary signals such as music signals. To account for the correlation between frequencies, independent positive semidefinite tensor analysis has been proposed. This unsupervised (blind) method, however, severely restrict the structure of frequency covariance matrices (FCMs) to reduce the number of model parameters. As an extension of these conventional approaches, we here propose a supervised method that models FCMs using deep neural networks (DNNs). It is difficult to directly infer FCMs using DNNs. Therefore, we also propose a new FCM model represented as a convex combination of a diagonal FCM and a rank-1 FCM. Our FCM model is flexible enough to not only consider inter-frequency correlation, but also capture the dynamics of time-varying FCMs of nonstationary signals. We infer the proposed FCMs using two DNNs: DNN for power spectrum estimation and DNN for time-domain signal estimation. An experimental result of separating music signals shows that the proposed method provides higher separation performance than IDLMA.
PILOT: Introducing Transformers for Probabilistic Sound Event Localization
Jun 07, 2021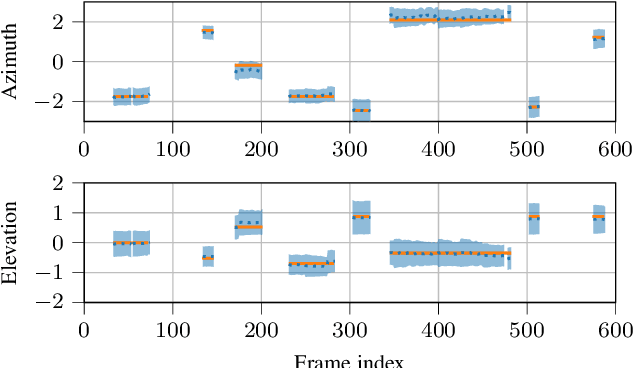
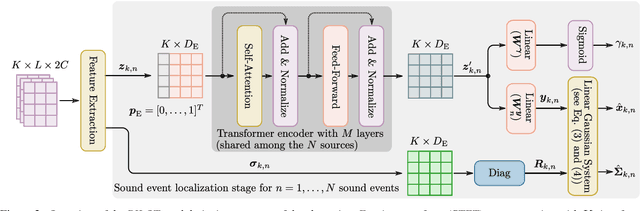
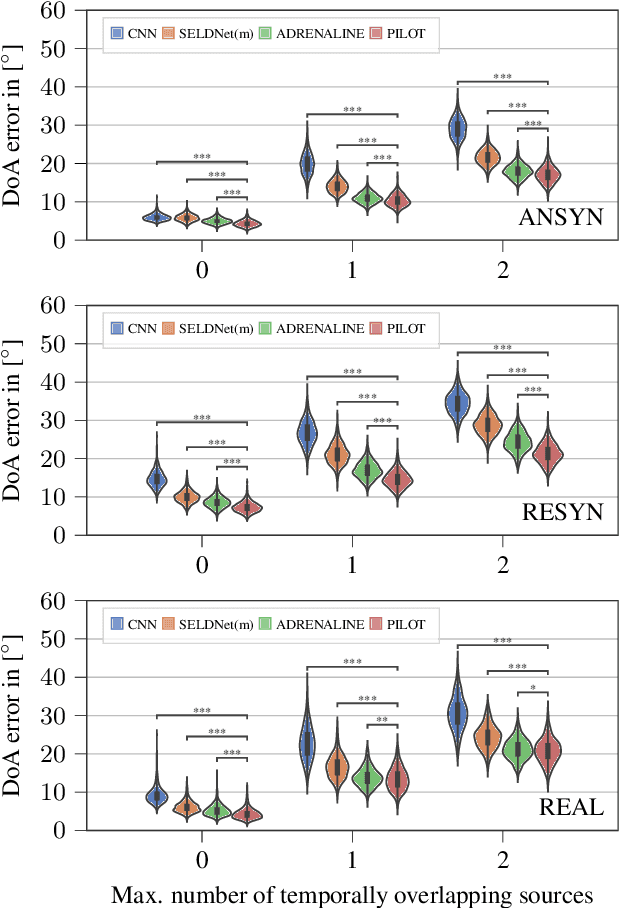
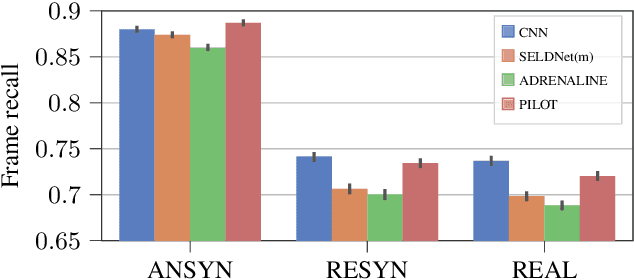
Sound event localization aims at estimating the positions of sound sources in the environment with respect to an acoustic receiver (e.g. a microphone array). Recent advances in this domain most prominently focused on utilizing deep recurrent neural networks. Inspired by the success of transformer architectures as a suitable alternative to classical recurrent neural networks, this paper introduces a novel transformer-based sound event localization framework, where temporal dependencies in the received multi-channel audio signals are captured via self-attention mechanisms. Additionally, the estimated sound event positions are represented as multivariate Gaussian variables, yielding an additional notion of uncertainty, which many previously proposed deep learning-based systems designed for this application do not provide. The framework is evaluated on three publicly available multi-source sound event localization datasets and compared against state-of-the-art methods in terms of localization error and event detection accuracy. It outperforms all competing systems on all datasets with statistical significant differences in performance.
Comparison of remote experiments using crowdsourcing and laboratory experiments on speech intelligibility
Apr 17, 2021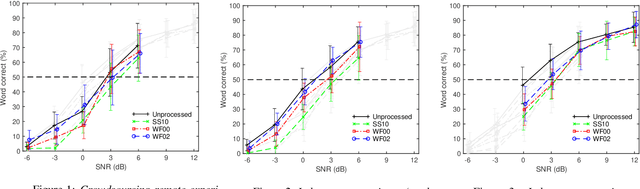
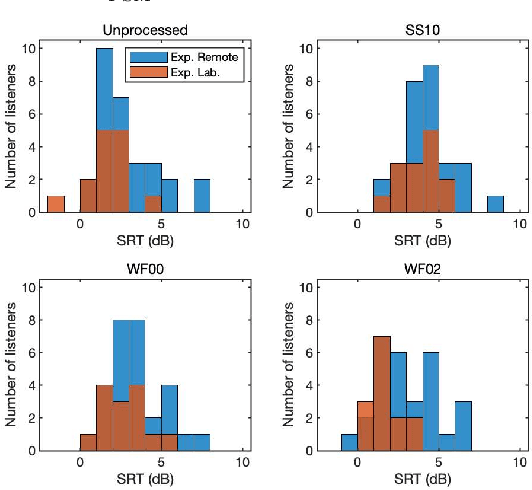
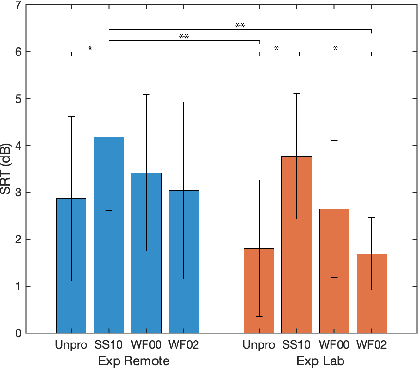
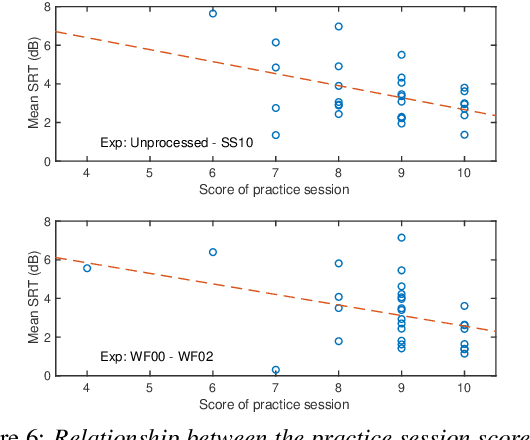
Many subjective experiments have been performed to develop objective speech intelligibility measures, but the novel coronavirus outbreak has made it very difficult to conduct experiments in a laboratory. One solution is to perform remote testing using crowdsourcing; however, because we cannot control the listening conditions, it is unclear whether the results are entirely reliable. In this study, we compared speech intelligibility scores obtained in remote and laboratory experiments. The results showed that the mean and standard deviation (SD) of the remote experiments' speech reception threshold (SRT) were higher than those of the laboratory experiments. However, the variance in the SRTs across the speech-enhancement conditions revealed similarities, implying that remote testing results may be as useful as laboratory experiments to develop an objective measure. We also show that the practice session scores correlate with the SRT values. This is a priori information before performing the main tests and would be useful for data screening to reduce the variability of the SRT distribution.
Exploiting Attention-based Sequence-to-Sequence Architectures for Sound Event Localization
Feb 28, 2021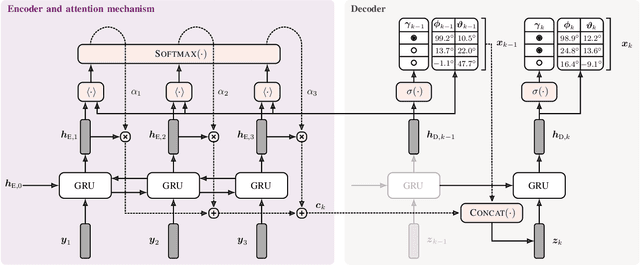
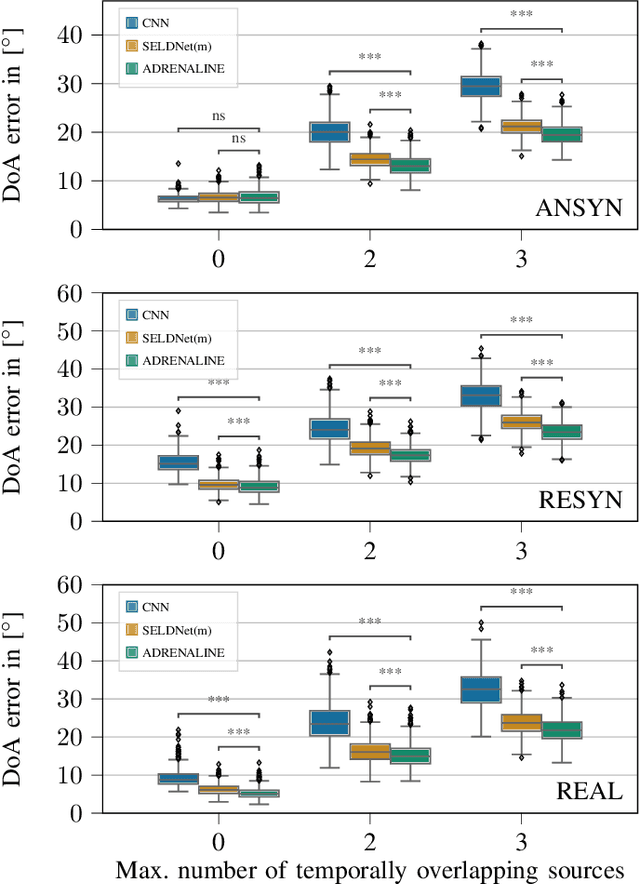
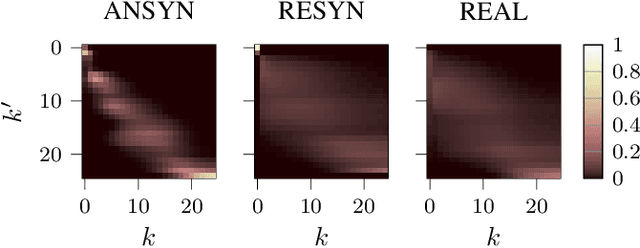
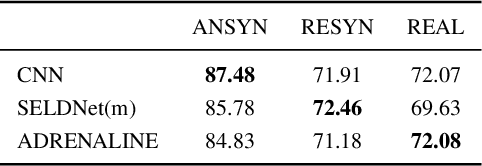
Sound event localization frameworks based on deep neural networks have shown increased robustness with respect to reverberation and noise in comparison to classical parametric approaches. In particular, recurrent architectures that incorporate temporal context into the estimation process seem to be well-suited for this task. This paper proposes a novel approach to sound event localization by utilizing an attention-based sequence-to-sequence model. These types of models have been successfully applied to problems in natural language processing and automatic speech recognition. In this work, a multi-channel audio signal is encoded to a latent representation, which is subsequently decoded to a sequence of estimated directions-of-arrival. Herein, attentions allow for capturing temporal dependencies in the audio signal by focusing on specific frames that are relevant for estimating the activity and direction-of-arrival of sound events at the current time-step. The framework is evaluated on three publicly available datasets for sound event localization. It yields superior localization performance compared to state-of-the-art methods in both anechoic and reverberant conditions.
Data Fusion for Audiovisual Speaker Localization: Extending Dynamic Stream Weights to the Spatial Domain
Feb 24, 2021
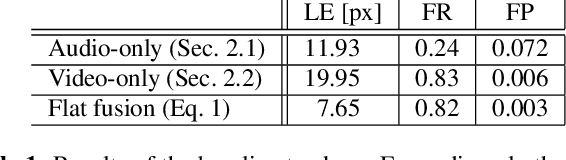
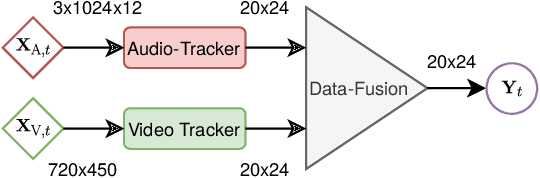
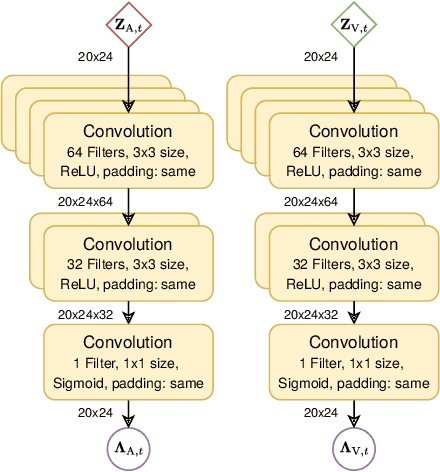
Estimating the positions of multiple speakers can be helpful for tasks like automatic speech recognition or speaker diarization. Both applications benefit from a known speaker position when, for instance, applying beamforming or assigning unique speaker identities. Recently, several approaches utilizing acoustic signals augmented with visual data have been proposed for this task. However, both the acoustic and the visual modality may be corrupted in specific spatial regions, for instance due to poor lighting conditions or to the presence of background noise. This paper proposes a novel audiovisual data fusion framework for speaker localization by assigning individual dynamic stream weights to specific regions in the localization space. This fusion is achieved via a neural network, which combines the predictions of individual audio and video trackers based on their time- and location-dependent reliability. A performance evaluation using audiovisual recordings yields promising results, with the proposed fusion approach outperforming all baseline models.
End-to-End Dereverberation, Beamforming, and Speech Recognition with Improved Numerical Stability and Advanced Frontend
Feb 23, 2021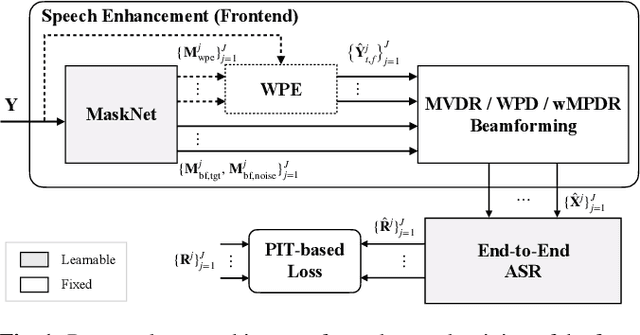
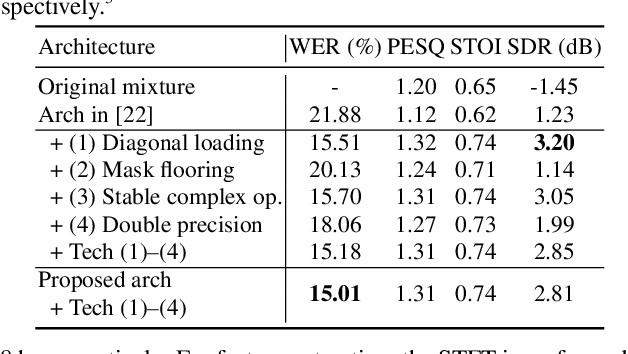
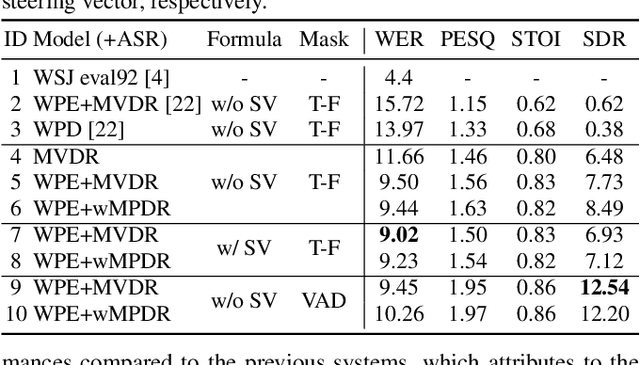
Recently, the end-to-end approach has been successfully applied to multi-speaker speech separation and recognition in both single-channel and multichannel conditions. However, severe performance degradation is still observed in the reverberant and noisy scenarios, and there is still a large performance gap between anechoic and reverberant conditions. In this work, we focus on the multichannel multi-speaker reverberant condition, and propose to extend our previous framework for end-to-end dereverberation, beamforming, and speech recognition with improved numerical stability and advanced frontend subnetworks including voice activity detection like masks. The techniques significantly stabilize the end-to-end training process. The experiments on the spatialized wsj1-2mix corpus show that the proposed system achieves about 35% WER relative reduction compared to our conventional multi-channel E2E ASR system, and also obtains decent speech dereverberation and separation performance (SDR=12.5 dB) in the reverberant multi-speaker condition while trained only with the ASR criterion.
Speaker activity driven neural speech extraction
Feb 09, 2021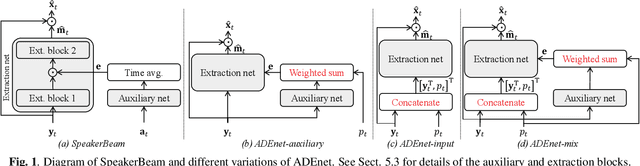

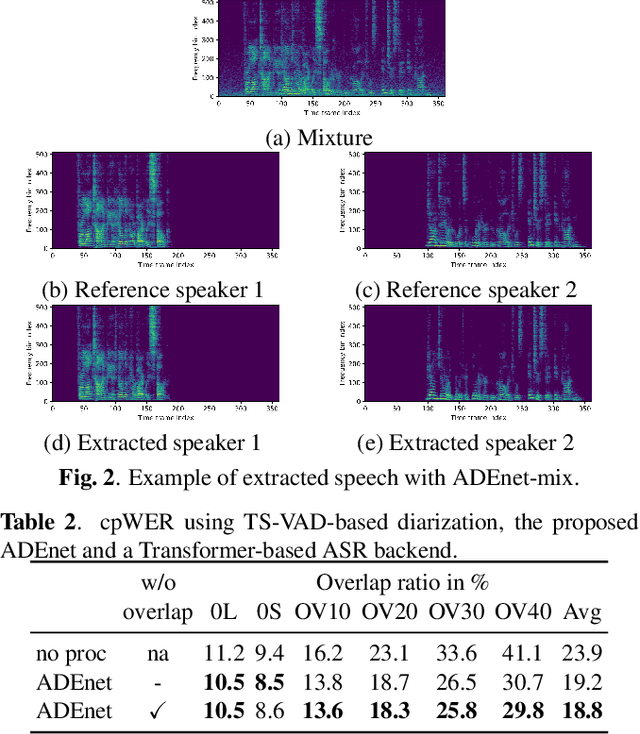
Target speech extraction, which extracts the speech of a target speaker in a mixture given auxiliary speaker clues, has recently received increased interest. Various clues have been investigated such as pre-recorded enrollment utterances, direction information, or video of the target speaker. In this paper, we explore the use of speaker activity information as an auxiliary clue for single-channel neural network-based speech extraction. We propose a speaker activity driven speech extraction neural network (ADEnet) and show that it can achieve performance levels competitive with enrollment-based approaches, without the need for pre-recordings. We further demonstrate the potential of the proposed approach for processing meeting-like recordings, where the speaker activity is obtained from a diarization system. We show that this simple yet practical approach can successfully extract speakers after diarization, which results in improved ASR performance, especially in high overlapping conditions, with a relative word error rate reduction of up to 25%.
Independent Vector Extraction for Joint Blind Source Separation and Dereverberation
Feb 09, 2021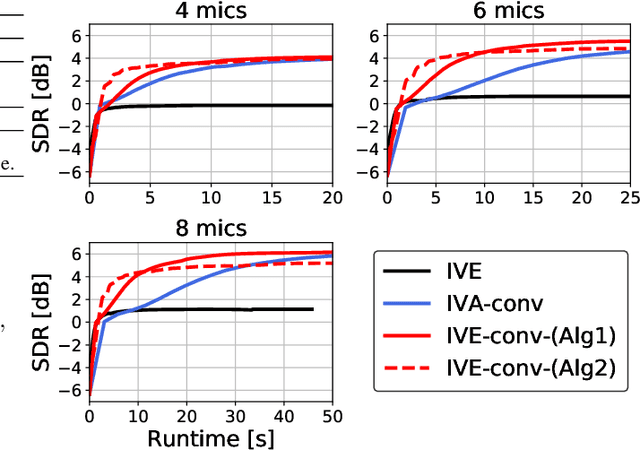


We address a blind source separation (BSS) problem in a noisy reverberant environment in which the number of microphones $M$ is greater than the number of sources of interest, and the other noise components can be approximated as stationary and Gaussian distributed. Conventional BSS algorithms for the optimization of a multi-input multi-output convolutional beamformer have suffered from a huge computational cost when $M$ is large. We here propose a computationally efficient method that integrates a weighted prediction error (WPE) dereverberation method and a fast BSS method called independent vector extraction (IVE), which has been developed for less reverberant environments. We show that the optimization problem of the new method can be reduced to that of IVE by exploiting the stationary condition, which makes the optimization easy to handle and computationally efficient. An experiment of speech signal separation shows that, compared to a conventional method that integrates WPE and independent vector analysis, our proposed algorithm has significantly faster convergence speeds while maintaining its separation performance.
Multimodal Attention Fusion for Target Speaker Extraction
Feb 02, 2021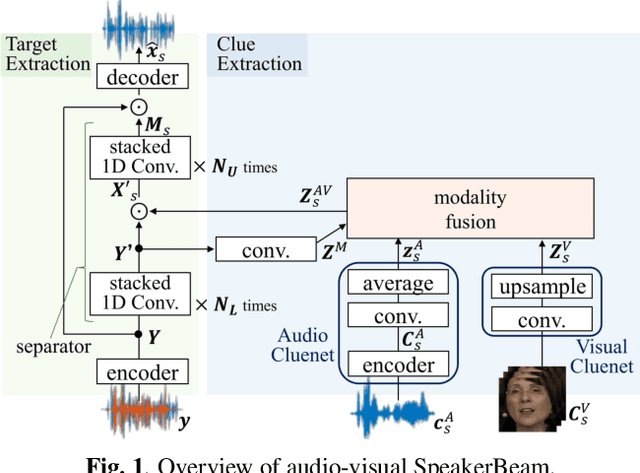
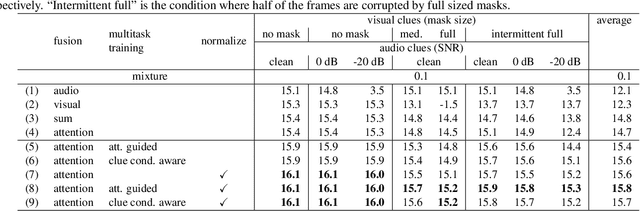
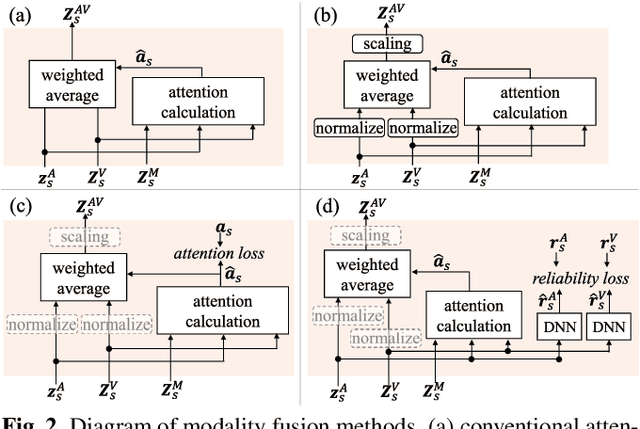
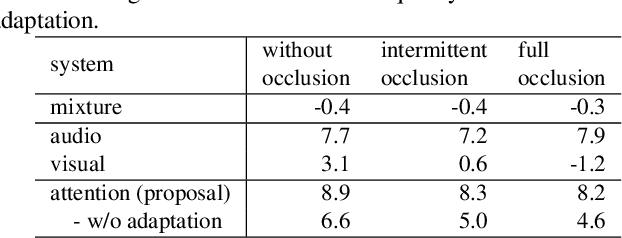
Target speaker extraction, which aims at extracting a target speaker's voice from a mixture of voices using audio, visual or locational clues, has received much interest. Recently an audio-visual target speaker extraction has been proposed that extracts target speech by using complementary audio and visual clues. Although audio-visual target speaker extraction offers a more stable performance than single modality methods for simulated data, its adaptation towards realistic situations has not been fully explored as well as evaluations on real recorded mixtures. One of the major issues to handle realistic situations is how to make the system robust to clue corruption because in real recordings both clues may not be equally reliable, e.g. visual clues may be affected by occlusions. In this work, we propose a novel attention mechanism for multi-modal fusion and its training methods that enable to effectively capture the reliability of the clues and weight the more reliable ones. Our proposals improve signal to distortion ratio (SDR) by 1.0 dB over conventional fusion mechanisms on simulated data. Moreover, we also record an audio-visual dataset of simultaneous speech with realistic visual clue corruption and show that audio-visual target speaker extraction with our proposals successfully work on real data.
* 7 pages, 5 figures