 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScene Coordinate Reconstruction Priors
Oct 14, 2025Scene coordinate regression (SCR) models have proven to be powerful implicit scene representations for 3D vision, enabling visual relocalization and structure-from-motion. SCR models are trained specifically for one scene. If training images imply insufficient multi-view constraints SCR models degenerate. We present a probabilistic reinterpretation of training SCR models, which allows us to infuse high-level reconstruction priors. We investigate multiple such priors, ranging from simple priors over the distribution of reconstructed depth values to learned priors over plausible scene coordinate configurations. For the latter, we train a 3D point cloud diffusion model on a large corpus of indoor scans. Our priors push predicted 3D scene points towards plausible geometry at each training step to increase their likelihood. On three indoor datasets our priors help learning better scene representations, resulting in more coherent scene point clouds, higher registration rates and better camera poses, with a positive effect on down-stream tasks such as novel view synthesis and camera relocalization.
Scene Coordinate Reconstruction: Posing of Image Collections via Incremental Learning of a Relocalizer
Apr 22, 2024We address the task of estimating camera parameters from a set of images depicting a scene. Popular feature-based structure-from-motion (SfM) tools solve this task by incremental reconstruction: they repeat triangulation of sparse 3D points and registration of more camera views to the sparse point cloud. We re-interpret incremental structure-from-motion as an iterated application and refinement of a visual relocalizer, that is, of a method that registers new views to the current state of the reconstruction. This perspective allows us to investigate alternative visual relocalizers that are not rooted in local feature matching. We show that scene coordinate regression, a learning-based relocalization approach, allows us to build implicit, neural scene representations from unposed images. Different from other learning-based reconstruction methods, we do not require pose priors nor sequential inputs, and we optimize efficiently over thousands of images. Our method, ACE0 (ACE Zero), estimates camera poses to an accuracy comparable to feature-based SfM, as demonstrated by novel view synthesis. Project page: https://nianticlabs.github.io/acezero/
Map-Relative Pose Regression for Visual Re-Localization
Apr 15, 2024Pose regression networks predict the camera pose of a query image relative to a known environment. Within this family of methods, absolute pose regression (APR) has recently shown promising accuracy in the range of a few centimeters in position error. APR networks encode the scene geometry implicitly in their weights. To achieve high accuracy, they require vast amounts of training data that, realistically, can only be created using novel view synthesis in a days-long process. This process has to be repeated for each new scene again and again. We present a new approach to pose regression, map-relative pose regression (marepo), that satisfies the data hunger of the pose regression network in a scene-agnostic fashion. We condition the pose regressor on a scene-specific map representation such that its pose predictions are relative to the scene map. This allows us to train the pose regressor across hundreds of scenes to learn the generic relation between a scene-specific map representation and the camera pose. Our map-relative pose regressor can be applied to new map representations immediately or after mere minutes of fine-tuning for the highest accuracy. Our approach outperforms previous pose regression methods by far on two public datasets, indoor and outdoor. Code is available: https://nianticlabs.github.io/marepo
Accelerated Coordinate Encoding: Learning to Relocalize in Minutes using RGB and Poses
May 23, 2023



Learning-based visual relocalizers exhibit leading pose accuracy, but require hours or days of training. Since training needs to happen on each new scene again, long training times make learning-based relocalization impractical for most applications, despite its promise of high accuracy. In this paper we show how such a system can actually achieve the same accuracy in less than 5 minutes. We start from the obvious: a relocalization network can be split in a scene-agnostic feature backbone, and a scene-specific prediction head. Less obvious: using an MLP prediction head allows us to optimize across thousands of view points simultaneously in each single training iteration. This leads to stable and extremely fast convergence. Furthermore, we substitute effective but slow end-to-end training using a robust pose solver with a curriculum over a reprojection loss. Our approach does not require privileged knowledge, such a depth maps or a 3D model, for speedy training. Overall, our approach is up to 300x faster in mapping than state-of-the-art scene coordinate regression, while keeping accuracy on par.
Recurrently Estimating Reflective Symmetry Planes from Partial Pointclouds
Jun 30, 2021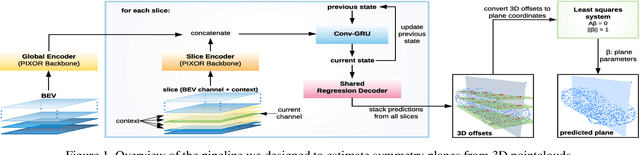



Many man-made objects are characterised by a shape that is symmetric along one or more planar directions. Estimating the location and orientation of such symmetry planes can aid many tasks such as estimating the overall orientation of an object of interest or performing shape completion, where a partial scan of an object is reflected across the estimated symmetry plane in order to obtain a more detailed shape. Many methods processing 3D data rely on expensive 3D convolutions. In this paper we present an alternative novel encoding that instead slices the data along the height dimension and passes it sequentially to a 2D convolutional recurrent regression scheme. The method also comprises a differentiable least squares step, allowing for end-to-end accurate and fast processing of both full and partial scans of symmetric objects. We use this approach to efficiently handle 3D inputs to design a method to estimate planar reflective symmetries. We show that our approach has an accuracy comparable to state-of-the-art techniques on the task of planar reflective symmetry estimation on full synthetic objects. Additionally, we show that it can be deployed on partial scans of objects in a real-world pipeline to improve the outputs of a 3D object detector.
Beyond Controlled Environments: 3D Camera Re-Localization in Changing Indoor Scenes
Aug 05, 2020
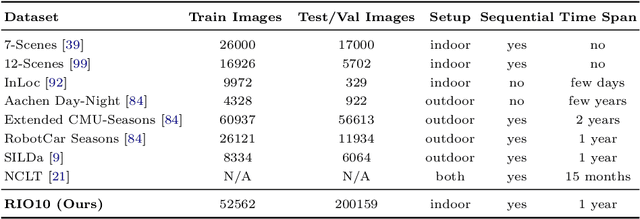
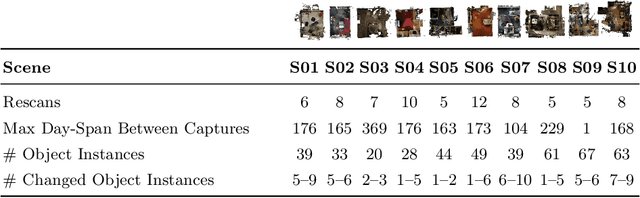

Long-term camera re-localization is an important task with numerous computer vision and robotics applications. Whilst various outdoor benchmarks exist that target lighting, weather and seasonal changes, far less attention has been paid to appearance changes that occur indoors. This has led to a mismatch between popular indoor benchmarks, which focus on static scenes, and indoor environments that are of interest for many real-world applications. In this paper, we adapt 3RScan - a recently introduced indoor RGB-D dataset designed for object instance re-localization - to create RIO10, a new long-term camera re-localization benchmark focused on indoor scenes. We propose new metrics for evaluating camera re-localization and explore how state-of-the-art camera re-localizers perform according to these metrics. We also examine in detail how different types of scene change affect the performance of different methods, based on novel ways of detecting such changes in a given RGB-D frame. Our results clearly show that long-term indoor re-localization is an unsolved problem. Our benchmark and tools are publicly available at waldjohannau.github.io/RIO10
Real-Time Highly Accurate Dense Depth on a Power Budget using an FPGA-CPU Hybrid SoC
Jul 17, 2019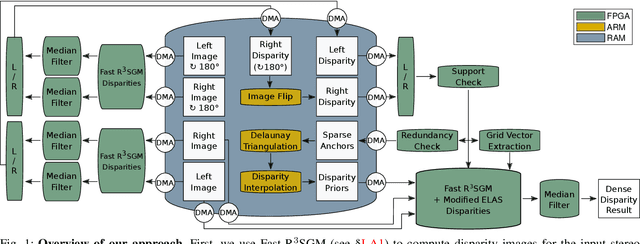
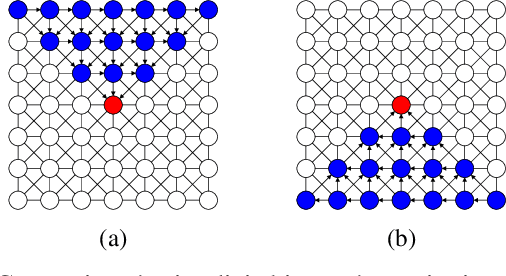
Obtaining highly accurate depth from stereo images in real time has many applications across computer vision and robotics, but in some contexts, upper bounds on power consumption constrain the feasible hardware to embedded platforms such as FPGAs. Whilst various stereo algorithms have been deployed on these platforms, usually cut down to better match the embedded architecture, certain key parts of the more advanced algorithms, e.g. those that rely on unpredictable access to memory or are highly iterative in nature, are difficult to deploy efficiently on FPGAs, and thus the depth quality that can be achieved is limited. In this paper, we leverage a FPGA-CPU chip to propose a novel, sophisticated, stereo approach that combines the best features of SGM and ELAS-based methods to compute highly accurate dense depth in real time. Our approach achieves an 8.7% error rate on the challenging KITTI 2015 dataset at over 50 FPS, with a power consumption of only 5W.
* 6 pages, 7 figures, 2 tables, journal
Let's Take This Online: Adapting Scene Coordinate Regression Network Predictions for Online RGB-D Camera Relocalisation
Jun 20, 2019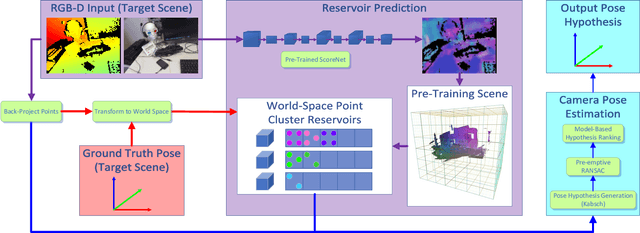
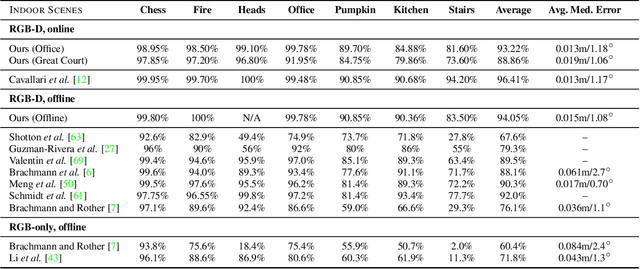
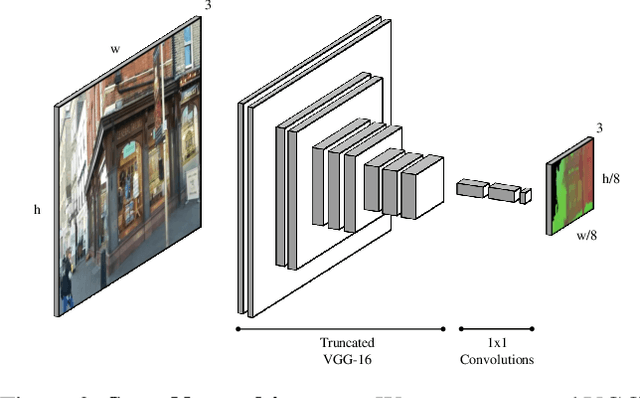
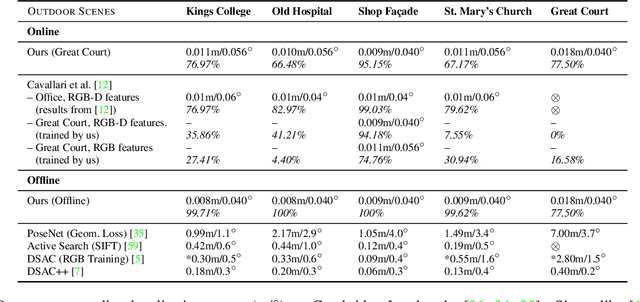
Many applications require a camera to be relocalised online, without expensive offline training on the target scene. Whilst both keyframe and sparse keypoint matching methods can be used online, the former often fail away from the training trajectory, and the latter can struggle in textureless regions. By contrast, scene coordinate regression (SCoRe) methods generalise to novel poses and can leverage dense correspondences to improve robustness, and recent work has shown how to adapt SCoRe forests between scenes, allowing their state-of-the-art performance to be leveraged online. However, because they use features hand-crafted for indoor use, they do not generalise well to harder outdoor scenes. Whilst replacing the forest with a neural network and learning suitable features for outdoor use is possible, the techniques used to adapt forests between scenes are unfortunately harder to transfer to a network context. In this paper, we address this by proposing a novel way of leveraging a network trained on one scene to predict points in another scene. Our approach replaces the appearance clustering performed by the branching structure of a regression forest with a two-step process that first uses the network to predict points in the original scene, and then uses these predicted points to look up clusters of points from the new scene. We show experimentally that our online approach achieves state-of-the-art performance on both the 7-Scenes and Cambridge Landmarks datasets, whilst running in under 300ms, making it highly effective in live scenarios.
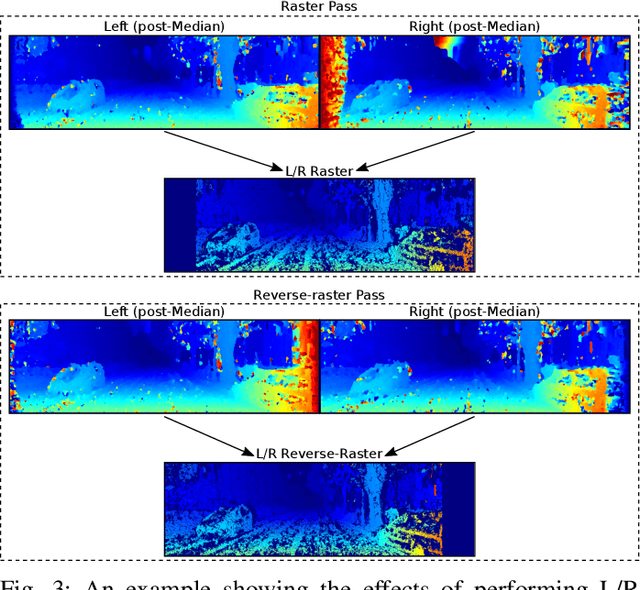
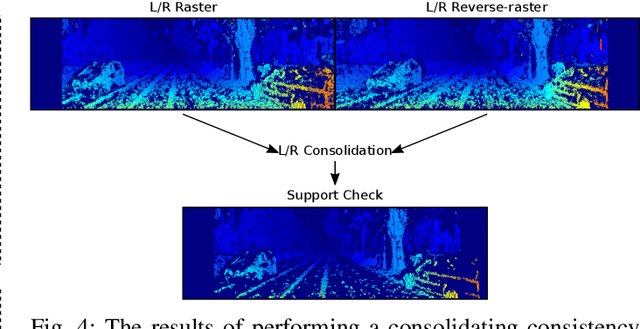
R$^3$SGM: Real-time Raster-Respecting Semi-Global Matching for Power-Constrained Systems
Oct 30, 2018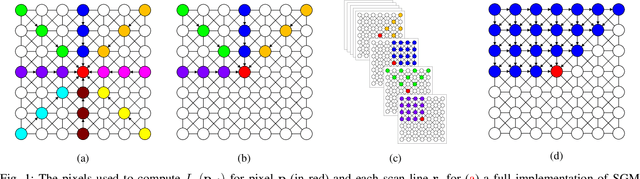
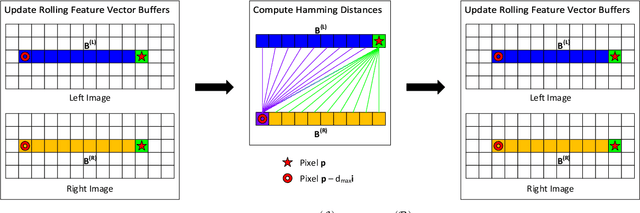
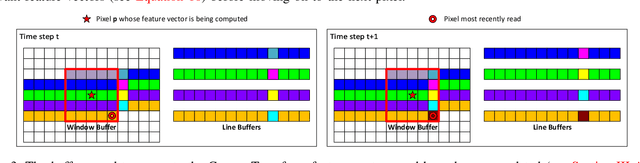
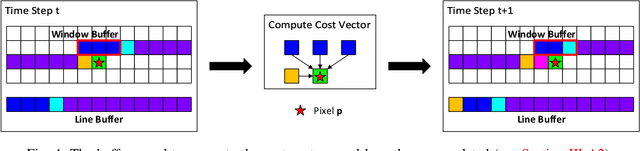
Stereo depth estimation is used for many computer vision applications. Though many popular methods strive solely for depth quality, for real-time mobile applications (e.g. prosthetic glasses or micro-UAVs), speed and power efficiency are equally, if not more, important. Many real-world systems rely on Semi-Global Matching (SGM) to achieve a good accuracy vs. speed balance, but power efficiency is hard to achieve with conventional hardware, making the use of embedded devices such as FPGAs attractive for low-power applications. However, the full SGM algorithm is ill-suited to deployment on FPGAs, and so most FPGA variants of it are partial, at the expense of accuracy. In a non-FPGA context, the accuracy of SGM has been improved by More Global Matching (MGM), which also helps tackle the streaking artifacts that afflict SGM. In this paper, we propose a novel, resource-efficient method that is inspired by MGM's techniques for improving depth quality, but which can be implemented to run in real time on a low-power FPGA. Through evaluation on multiple datasets (KITTI and Middlebury), we show that in comparison to other real-time capable stereo approaches, we can achieve a state-of-the-art balance between accuracy, power efficiency and speed, making our approach highly desirable for use in real-time systems with limited power.
Real-Time RGB-D Camera Pose Estimation in Novel Scenes using a Relocalisation Cascade
Oct 29, 2018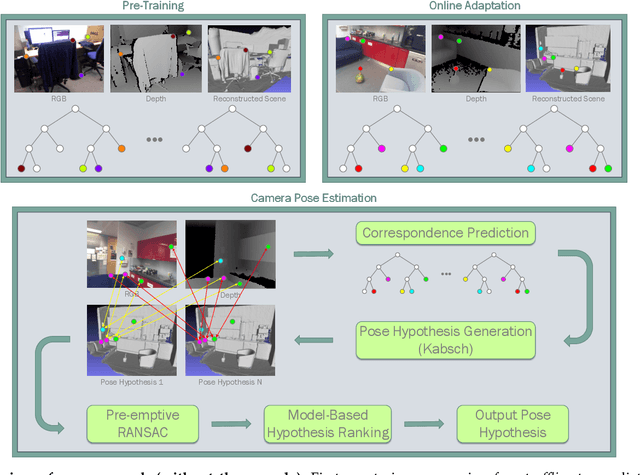
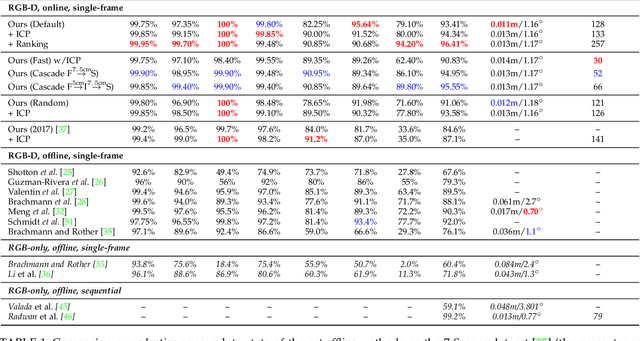

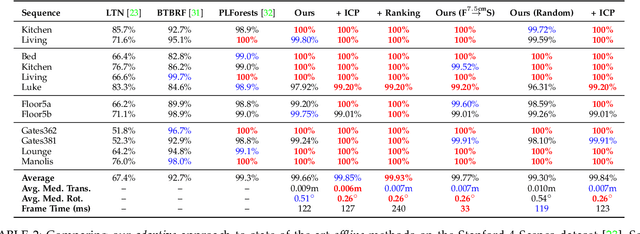
Camera pose estimation is an important problem in computer vision. Common techniques either match the current image against keyframes with known poses, directly regress the pose, or establish correspondences between keypoints in the image and points in the scene to estimate the pose. In recent years, regression forests have become a popular alternative to establish such correspondences. They achieve accurate results, but have traditionally needed to be trained offline on the target scene, preventing relocalisation in new environments. Recently, we showed how to circumvent this limitation by adapting a pre-trained forest to a new scene on the fly. The adapted forests achieved relocalisation performance that was on par with that of offline forests, and our approach was able to estimate the camera pose in close to real time. In this paper, we present an extension of this work that achieves significantly better relocalisation performance whilst running fully in real time. To achieve this, we make several changes to the original approach: (i) instead of accepting the camera pose hypothesis without question, we make it possible to score the final few hypotheses using a geometric approach and select the most promising; (ii) we chain several instantiations of our relocaliser together in a cascade, allowing us to try faster but less accurate relocalisation first, only falling back to slower, more accurate relocalisation as necessary; and (iii) we tune the parameters of our cascade to achieve effective overall performance. These changes allow us to significantly improve upon the performance our original state-of-the-art method was able to achieve on the well-known 7-Scenes and Stanford 4 Scenes benchmarks. As additional contributions, we present a way of visualising the internal behaviour of our forests and show how to entirely circumvent the need to pre-train a forest on a generic scene.