 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTom Funkhouser
Scene Representation Transformer: Geometry-Free Novel View Synthesis Through Set-Latent Scene Representations
Nov 25, 2021
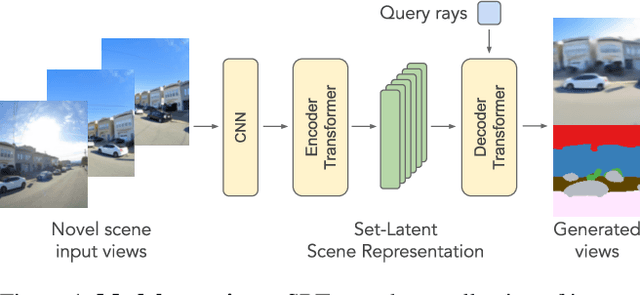

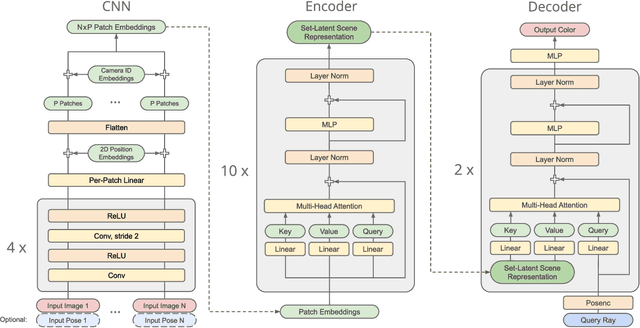
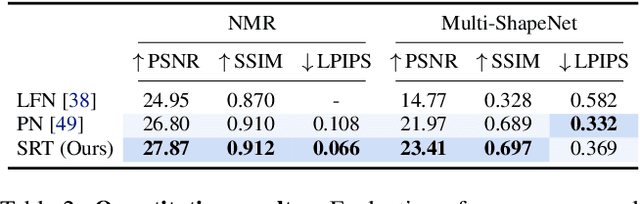
A classical problem in computer vision is to infer a 3D scene representation from few images that can be used to render novel views at interactive rates. Previous work focuses on reconstructing pre-defined 3D representations, e.g. textured meshes, or implicit representations, e.g. radiance fields, and often requires input images with precise camera poses and long processing times for each novel scene. In this work, we propose the Scene Representation Transformer (SRT), a method which processes posed or unposed RGB images of a new area, infers a "set-latent scene representation", and synthesises novel views, all in a single feed-forward pass. To calculate the scene representation, we propose a generalization of the Vision Transformer to sets of images, enabling global information integration, and hence 3D reasoning. An efficient decoder transformer parameterizes the light field by attending into the scene representation to render novel views. Learning is supervised end-to-end by minimizing a novel-view reconstruction error. We show that this method outperforms recent baselines in terms of PSNR and speed on synthetic datasets, including a new dataset created for the paper. Further, we demonstrate that SRT scales to support interactive visualization and semantic segmentation of real-world outdoor environments using Street View imagery.
Pillar-based Object Detection for Autonomous Driving
Jul 20, 2020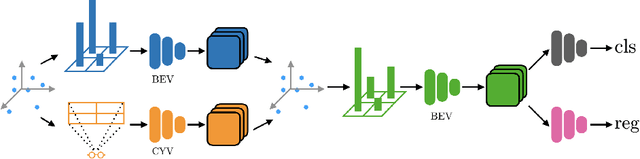
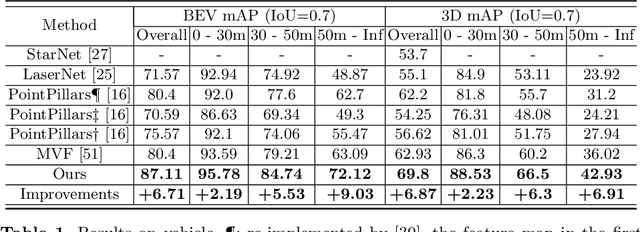
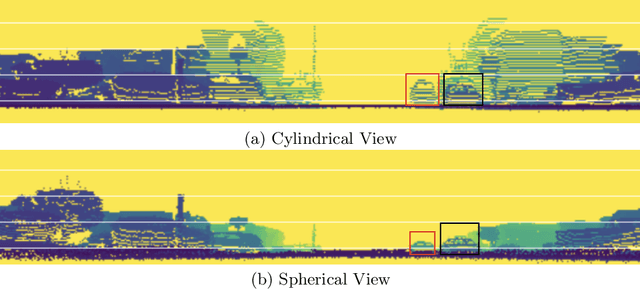

We present a simple and flexible object detection framework optimized for autonomous driving. Building on the observation that point clouds in this application are extremely sparse, we propose a practical pillar-based approach to fix the imbalance issue caused by anchors. In particular, our algorithm incorporates a cylindrical projection into multi-view feature learning, predicts bounding box parameters per pillar rather than per point or per anchor, and includes an aligned pillar-to-point projection module to improve the final prediction. Our anchor-free approach avoids hyperparameter search associated with past methods, simplifying 3D object detection while significantly improving upon state-of-the-art.
DOPS: Learning to Detect 3D Objects and Predict their 3D Shapes
Apr 02, 2020
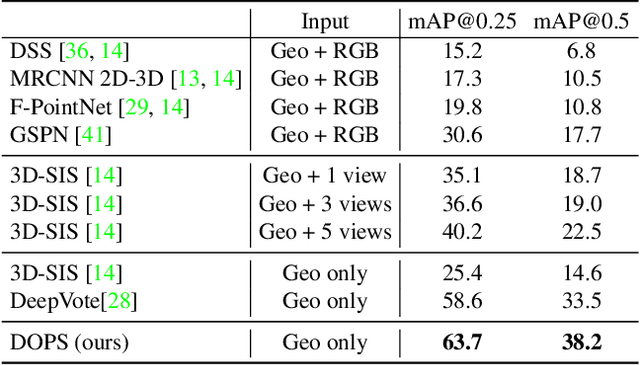
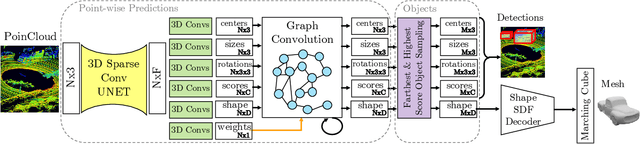
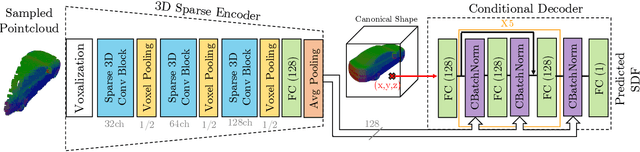
We propose DOPS, a fast single-stage 3D object detection method for LIDAR data. Previous methods often make domain-specific design decisions, for example projecting points into a bird-eye view image in autonomous driving scenarios. In contrast, we propose a general-purpose method that works on both indoor and outdoor scenes. The core novelty of our method is a fast, single-pass architecture that both detects objects in 3D and estimates their shapes. 3D bounding box parameters are estimated in one pass for every point, aggregated through graph convolutions, and fed into a branch of the network that predicts latent codes representing the shape of each detected object. The latent shape space and shape decoder are learned on a synthetic dataset and then used as supervision for the end-to-end training of the 3D object detection pipeline. Thus our model is able to extract shapes without access to ground-truth shape information in the target dataset. During experiments, we find that our proposed method achieves state-of-the-art results by ~5% on object detection in ScanNet scenes, and it gets top results by 3.4% in the Waymo Open Dataset, while reproducing the shapes of detected cars.