 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNew Insights on Reducing Abrupt Representation Change in Online Continual Learning
Mar 08, 2022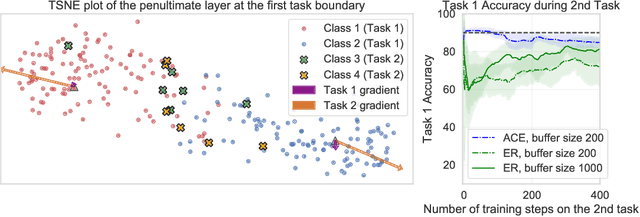
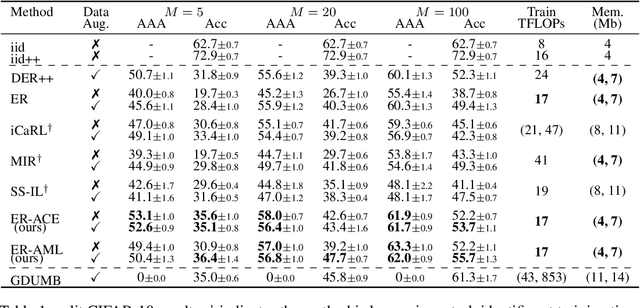
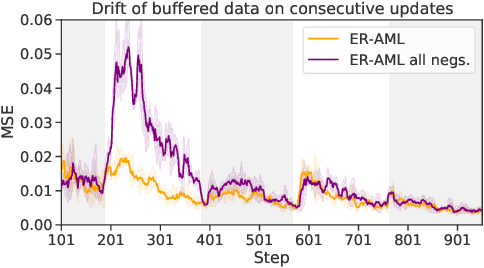
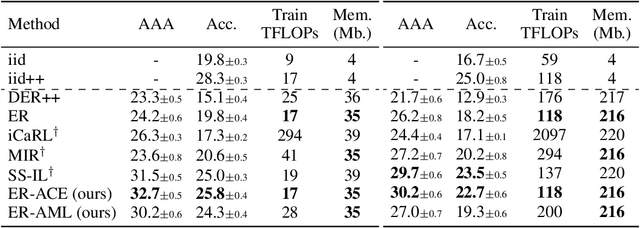
In the online continual learning paradigm, agents must learn from a changing distribution while respecting memory and compute constraints. Experience Replay (ER), where a small subset of past data is stored and replayed alongside new data, has emerged as a simple and effective learning strategy. In this work, we focus on the change in representations of observed data that arises when previously unobserved classes appear in the incoming data stream, and new classes must be distinguished from previous ones. We shed new light on this question by showing that applying ER causes the newly added classes' representations to overlap significantly with the previous classes, leading to highly disruptive parameter updates. Based on this empirical analysis, we propose a new method which mitigates this issue by shielding the learned representations from drastic adaptation to accommodate new classes. We show that using an asymmetric update rule pushes new classes to adapt to the older ones (rather than the reverse), which is more effective especially at task boundaries, where much of the forgetting typically occurs. Empirical results show significant gains over strong baselines on standard continual learning benchmarks
Barlow constrained optimization for Visual Question Answering
Mar 07, 2022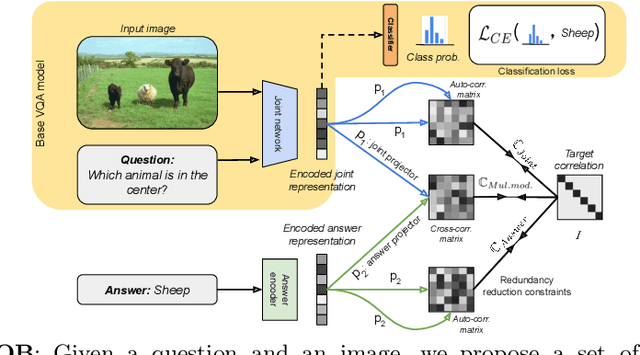
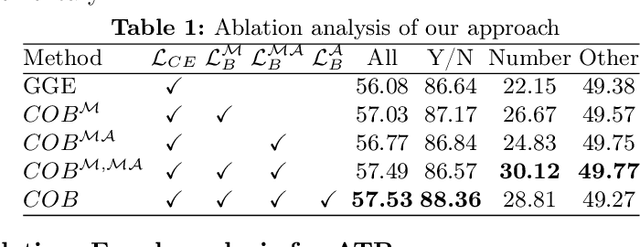
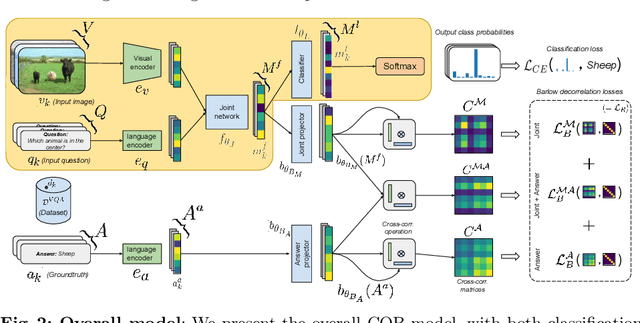
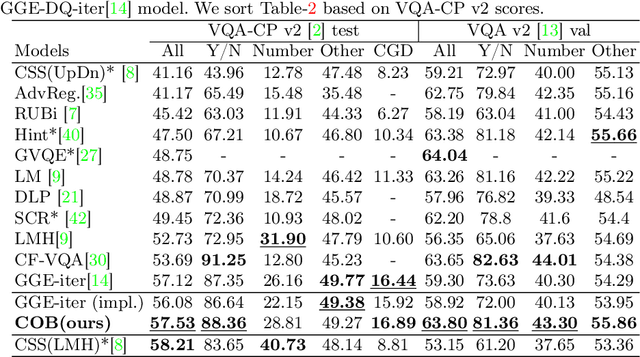
Visual question answering is a vision-and-language multimodal task, that aims at predicting answers given samples from the question and image modalities. Most recent methods focus on learning a good joint embedding space of images and questions, either by improving the interaction between these two modalities, or by making it a more discriminant space. However, how informative this joint space is, has not been well explored. In this paper, we propose a novel regularization for VQA models, Constrained Optimization using Barlow's theory (COB), that improves the information content of the joint space by minimizing the redundancy. It reduces the correlation between the learned feature components and thereby disentangles semantic concepts. Our model also aligns the joint space with the answer embedding space, where we consider the answer and image+question as two different `views' of what in essence is the same semantic information. We propose a constrained optimization policy to balance the categorical and redundancy minimization forces. When built on the state-of-the-art GGE model, the resulting model improves VQA accuracy by 1.4% and 4% on the VQA-CP v2 and VQA v2 datasets respectively. The model also exhibits better interpretability.
Find a Way Forward: a Language-Guided Semantic Map Navigator
Mar 07, 2022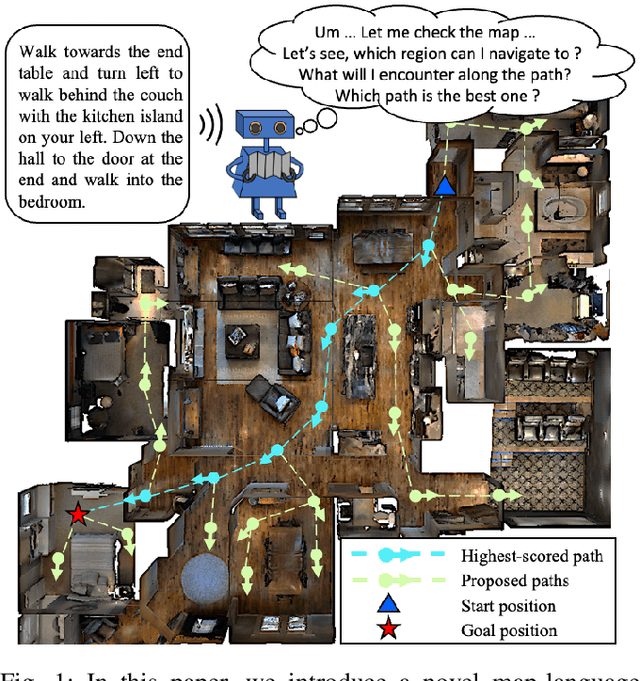
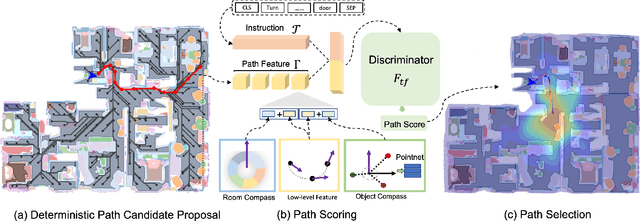
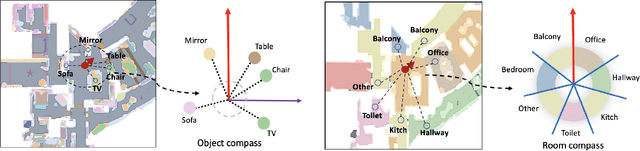
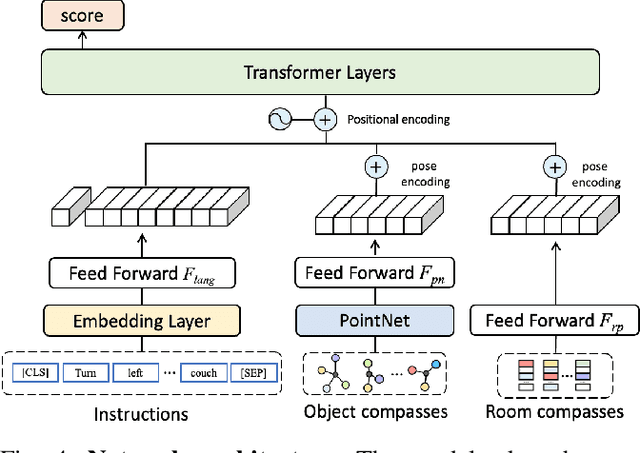
This paper attacks the problem of language-guided navigation in a new perspective by using novel semantic navigation maps, which enables robots to carry out natural language instructions and move to a target position based on the map observations. We break down this problem into parts and introduce three different modules to solve the corresponding subproblems. Our approach leverages map information to provide Deterministic Path Candidate Proposals to reduce the solution space. Different from traditional methods that predict robots' movements toward the target step-by-step, we design an attention-based Language Driven Discriminator to evaluate path candidates and determine the best path as the final result. To represent the map observations along a path for a better modality alignment, a novel Path Feature Encoding scheme tailored for semantic navigation maps is proposed. Unlike traditional methods that tend to produce cumulative errors or be stuck in local decisions, our method which plans paths based on global information can greatly alleviate these problems. The proposed approach has noticeable performance gains, especially in long-distance navigation cases. Also, its training efficiency is significantly higher than of other methods.
RARA: Zero-shot Sim2Real Visual Navigation with Following Foreground Cues
Jan 08, 2022
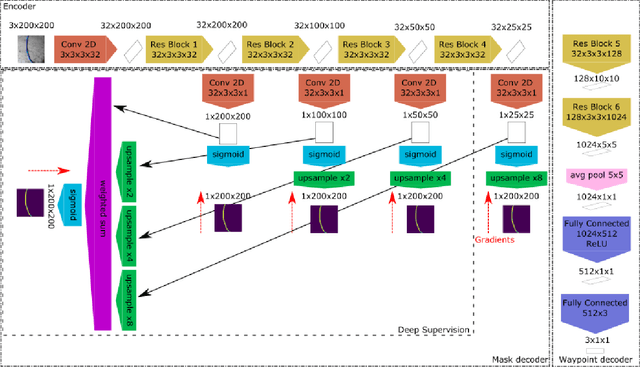


The gap between simulation and the real-world restrains many machine learning breakthroughs in computer vision and reinforcement learning from being applicable in the real world. In this work, we tackle this gap for the specific case of camera-based navigation, formulating it as following a visual cue in the foreground with arbitrary backgrounds. The visual cue in the foreground can often be simulated realistically, such as a line, gate or cone. The challenge then lies in coping with the unknown backgrounds and integrating both. As such, the goal is to train a visual agent on data captured in an empty simulated environment except for this foreground cue and test this model directly in a visually diverse real world. In order to bridge this big gap, we show it's crucial to combine following techniques namely: Randomized augmentation of the fore- and background, regularization with both deep supervision and triplet loss and finally abstraction of the dynamics by using waypoints rather than direct velocity commands. The various techniques are ablated in our experimental results both qualitatively and quantitatively finally demonstrating a successful transfer from simulation to the real world.
Revisiting spatio-temporal layouts for compositional action recognition
Nov 02, 2021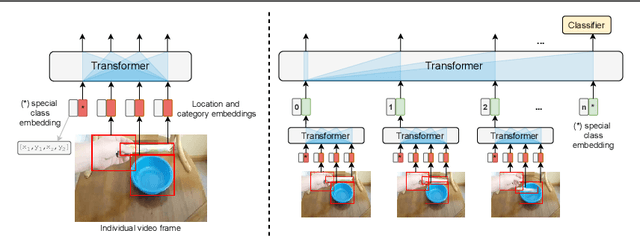
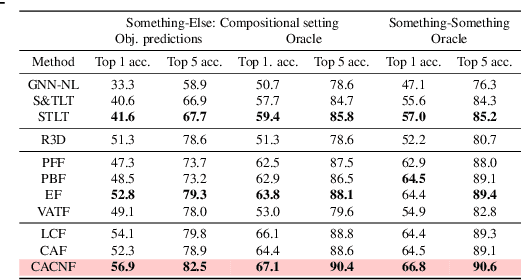
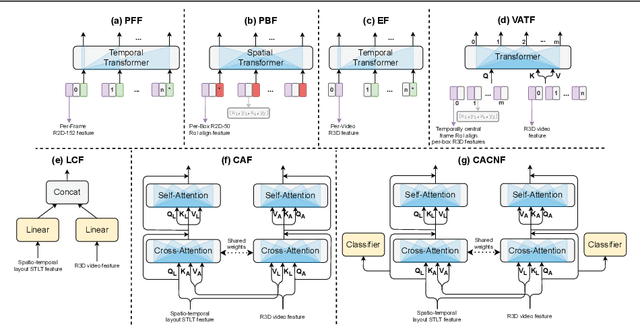
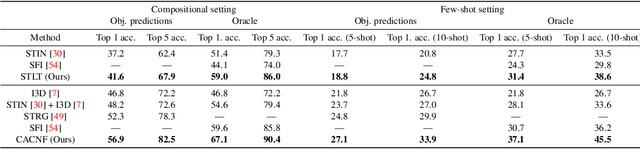
Recognizing human actions is fundamentally a spatio-temporal reasoning problem, and should be, at least to some extent, invariant to the appearance of the human and the objects involved. Motivated by this hypothesis, in this work, we take an object-centric approach to action recognition. Multiple works have studied this setting before, yet it remains unclear (i) how well a carefully crafted, spatio-temporal layout-based method can recognize human actions, and (ii) how, and when, to fuse the information from layout and appearance-based models. The main focus of this paper is compositional/few-shot action recognition, where we advocate the usage of multi-head attention (proven to be effective for spatial reasoning) over spatio-temporal layouts, i.e., configurations of object bounding boxes. We evaluate different schemes to inject video appearance information to the system, and benchmark our approach on background cluttered action recognition. On the Something-Else and Action Genome datasets, we demonstrate (i) how to extend multi-head attention for spatio-temporal layout-based action recognition, (ii) how to improve the performance of appearance-based models by fusion with layout-based models, (iii) that even on non-compositional background-cluttered video datasets, a fusion between layout- and appearance-based models improves the performance.
Trident Pyramid Networks: The importance of processing at the feature pyramid level for better object detection
Oct 08, 2021
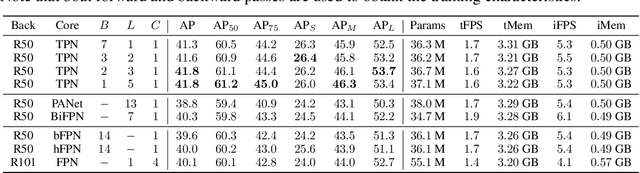

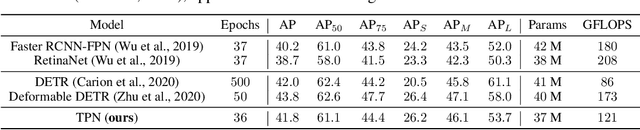
Feature pyramids have become ubiquitous in multi-scale computer vision tasks such as object detection. Based on their importance, we divide a computer vision network into three parts: a backbone (generating a feature pyramid), a core (refining the feature pyramid) and a head (generating the final output). Most existing networks operating on feature pyramids, named cores, are shallow and mostly focus on communication-based processing in the form of top-down and bottom-up operations. We present a new core architecture called Trident Pyramid Network (TPN), that allows for a deeper design and for a better balance between communication-based processing and self-processing. We show consistent improvements when using our TPN core on the COCO object detection benchmark, outperforming the popular BiFPN baseline by 1.5 AP. Additionally, we empirically show that it is more beneficial to put additional computation into the TPN core, rather than into the backbone, by outperforming a ResNet-101+FPN baseline with our ResNet-50+TPN network by 1.7 AP, while operating under similar computation budgets. This emphasizes the importance of performing computation at the feature pyramid level in modern-day object detection systems. Code will be released.
Glimpse-Attend-and-Explore: Self-Attention for Active Visual Exploration
Aug 26, 2021
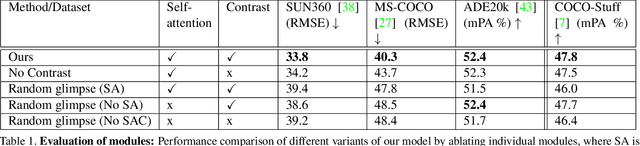
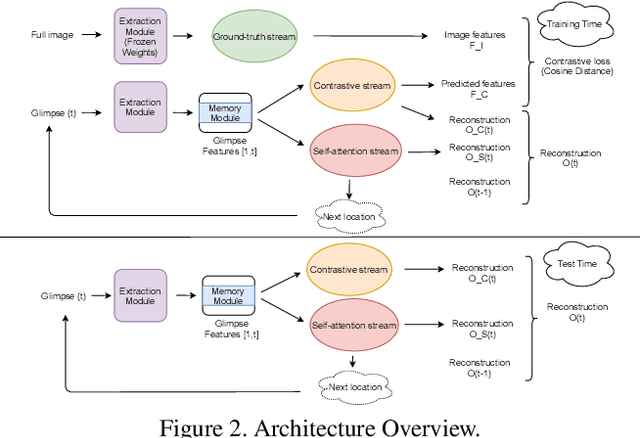
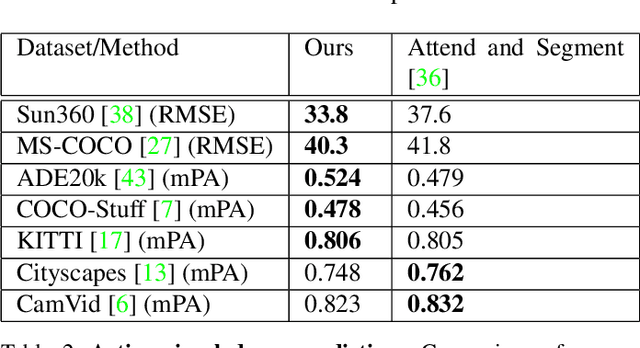
Active visual exploration aims to assist an agent with a limited field of view to understand its environment based on partial observations made by choosing the best viewing directions in the scene. Recent methods have tried to address this problem either by using reinforcement learning, which is difficult to train, or by uncertainty maps, which are task-specific and can only be implemented for dense prediction tasks. In this paper, we propose the Glimpse-Attend-and-Explore model which: (a) employs self-attention to guide the visual exploration instead of task-specific uncertainty maps; (b) can be used for both dense and sparse prediction tasks; and (c) uses a contrastive stream to further improve the representations learned. Unlike previous works, we show the application of our model on multiple tasks like reconstruction, segmentation and classification. Our model provides encouraging results while being less dependent on dataset bias in driving the exploration. We further perform an ablation study to investigate the features and attention learned by our model. Finally, we show that our self-attention module learns to attend different regions of the scene by minimizing the loss on the downstream task. Code: https://github.com/soroushseifi/glimpse-attend-explore.
BlockCopy: High-Resolution Video Processing with Block-Sparse Feature Propagation and Online Policies
Aug 20, 2021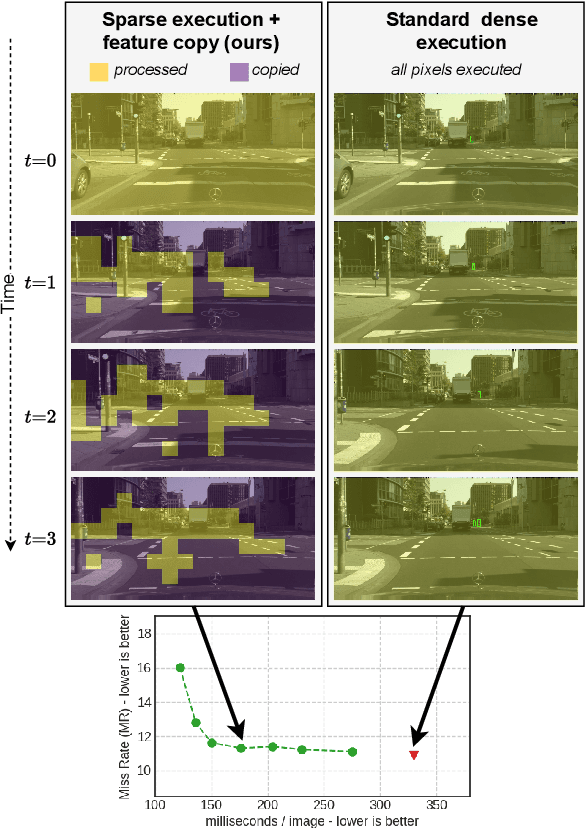
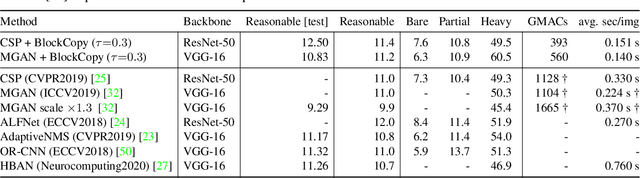
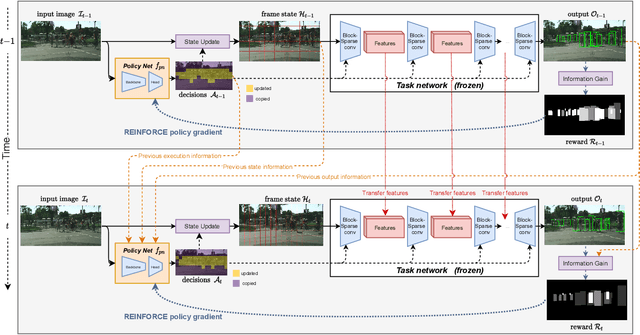
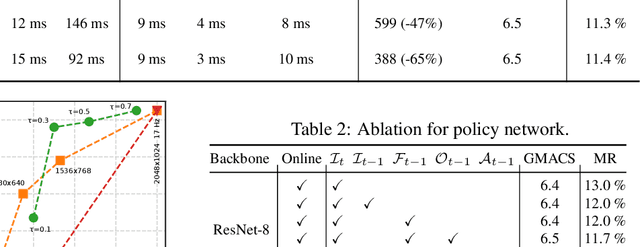
In this paper we propose BlockCopy, a scheme that accelerates pretrained frame-based CNNs to process video more efficiently, compared to standard frame-by-frame processing. To this end, a lightweight policy network determines important regions in an image, and operations are applied on selected regions only, using custom block-sparse convolutions. Features of non-selected regions are simply copied from the preceding frame, reducing the number of computations and latency. The execution policy is trained using reinforcement learning in an online fashion without requiring ground truth annotations. Our universal framework is demonstrated on dense prediction tasks such as pedestrian detection, instance segmentation and semantic segmentation, using both state of the art (Center and Scale Predictor, MGAN, SwiftNet) and standard baseline networks (Mask-RCNN, DeepLabV3+). BlockCopy achieves significant FLOPS savings and inference speedup with minimal impact on accuracy.
MinMaxCAM: Improving object coverage for CAM-basedWeakly Supervised Object Localization
Apr 29, 2021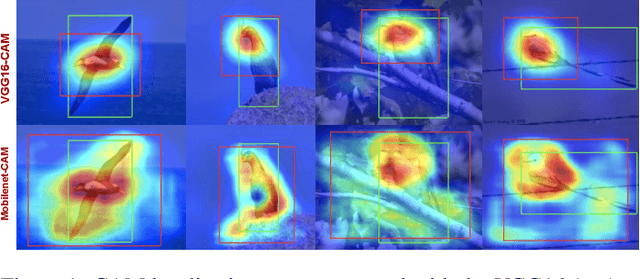

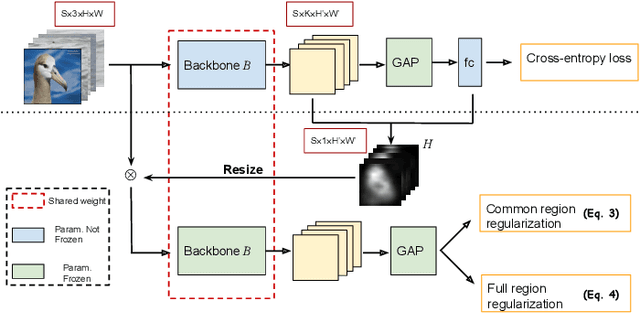

One of the most common problems of weakly supervised object localization is that of inaccurate object coverage. In the context of state-of-the-art methods based on Class Activation Mapping, this is caused either by localization maps which focus, exclusively, on the most discriminative region of the objects of interest or by activations occurring in background regions. To address these two problems, we propose two representation regularization mechanisms: Full Region Regularizationwhich tries to maximize the coverage of the localization map inside the object region, and Common Region Regularization which minimizes the activations occurring in background regions. We evaluate the two regularizations on the ImageNet, CUB-200-2011 and OpenImages-segmentation datasets, and show that the proposed regularizations tackle both problems, outperforming the state-of-the-art by a significant margin.
Towards Human-Understandable Visual Explanations:Imperceptible High-frequency Cues Can Better Be Removed
Apr 16, 2021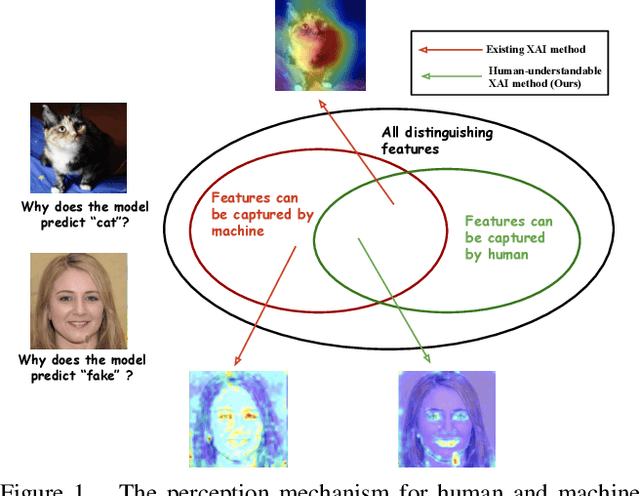


Explainable AI (XAI) methods focus on explaining what a neural network has learned - in other words, identifying the features that are the most influential to the prediction. In this paper, we call them "distinguishing features". However, whether a human can make sense of the generated explanation also depends on the perceptibility of these features to humans. To make sure an explanation is human-understandable, we argue that the capabilities of humans, constrained by the Human Visual System (HVS) and psychophysics, need to be taken into account. We propose the {\em human perceptibility principle for XAI}, stating that, to generate human-understandable explanations, neural networks should be steered towards focusing on human-understandable cues during training. We conduct a case study regarding the classification of real vs. fake face images, where many of the distinguishing features picked up by standard neural networks turn out not to be perceptible to humans. By applying the proposed principle, a neural network with human-understandable explanations is trained which, in a user study, is shown to better align with human intuition. This is likely to make the AI more trustworthy and opens the door to humans learning from machines. In the case study, we specifically investigate and analyze the behaviour of the human-imperceptible high spatial frequency features in neural networks and XAI methods.