 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion Action Segmentation
Mar 31, 2023Temporal action segmentation is crucial for understanding long-form videos. Previous works on this task commonly adopt an iterative refinement paradigm by using multi-stage models. Our paper proposes an essentially different framework via denoising diffusion models, which nonetheless shares the same inherent spirit of such iterative refinement. In this framework, action predictions are progressively generated from random noise with input video features as conditions. To enhance the modeling of three striking characteristics of human actions, including the position prior, the boundary ambiguity, and the relational dependency, we devise a unified masking strategy for the conditioning inputs in our framework. Extensive experiments on three benchmark datasets, i.e., GTEA, 50Salads, and Breakfast, are performed and the proposed method achieves superior or comparable results to state-of-the-art methods, showing the effectiveness of a generative approach for action segmentation. Our codes will be made available.
Real-world Deep Local Motion Deblurring
Apr 18, 2022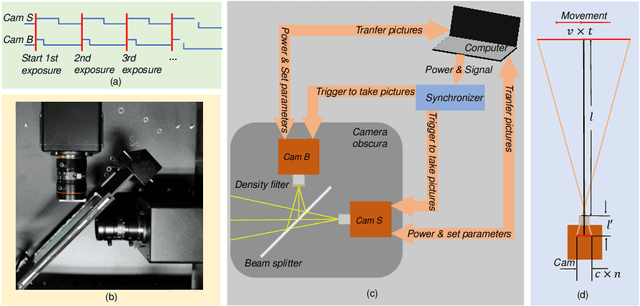



Most existing deblurring methods focus on removing global blur caused by camera shake, while they cannot well handle local blur caused by object movements. To fill the vacancy of local deblurring in real scenes, we establish the first real local motion blur dataset (ReLoBlur), which is captured by a synchronized beam-splitting photographing system and corrected by a post-progressing pipeline. Based on ReLoBlur, we propose a Local Blur-Aware Gated network (LBAG) and several local blur-aware techniques to bridge the gap between global and local deblurring: 1) a blur detection approach based on background subtraction to localize blurred regions; 2) a gate mechanism to guide our network to focus on blurred regions; and 3) a blur-aware patch cropping strategy to address data imbalance problem. Extensive experiments prove the reliability of ReLoBlur dataset, and demonstrate that LBAG achieves better performance than state-of-the-art global deblurring methods without our proposed local blur-aware techniques.
Contrastive and Selective Hidden Embeddings for Medical Image Segmentation
Jan 21, 2022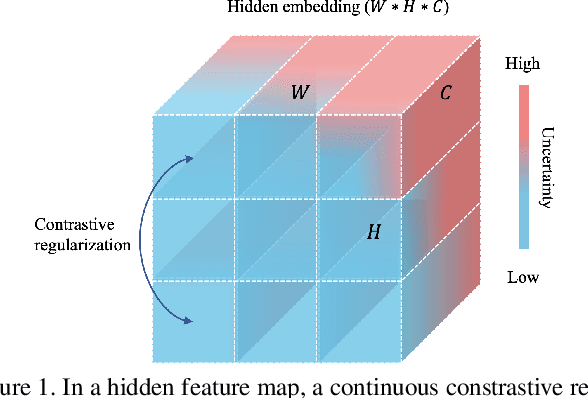
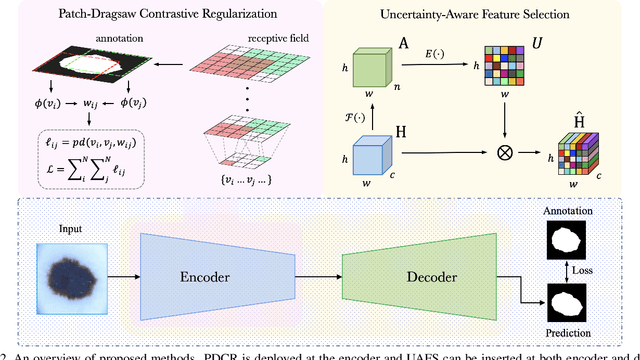
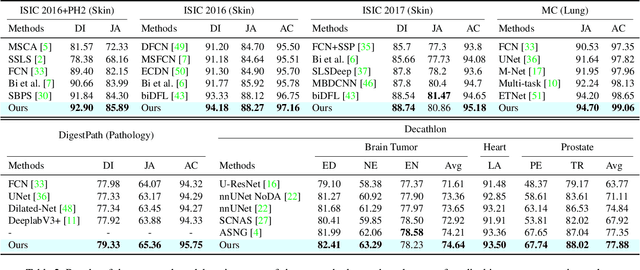
Medical image segmentation has been widely recognized as a pivot procedure for clinical diagnosis, analysis, and treatment planning. However, the laborious and expensive annotation process lags down the speed of further advances. Contrastive learning-based weight pre-training provides an alternative by leveraging unlabeled data to learn a good representation. In this paper, we investigate how contrastive learning benefits the general supervised medical segmentation tasks. To this end, patch-dragsaw contrastive regularization (PDCR) is proposed to perform patch-level tugging and repulsing with the extent controlled by a continuous affinity score. And a new structure dubbed uncertainty-aware feature selection block (UAFS) is designed to perform the feature selection process, which can handle the learning target shift caused by minority features with high uncertainty. By plugging the proposed 2 modules into the existing segmentation architecture, we achieve state-of-the-art results across 8 public datasets from 6 domains. Newly designed modules further decrease the amount of training data to a quarter while achieving comparable, if not better, performances. From this perspective, we take the opposite direction of the original self/un-supervised contrastive learning by further excavating information contained within the label.
ASFormer: Transformer for Action Segmentation
Oct 16, 2021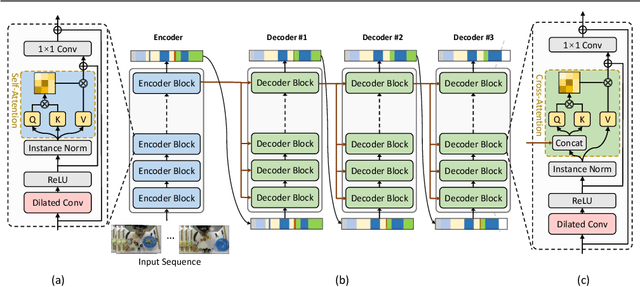


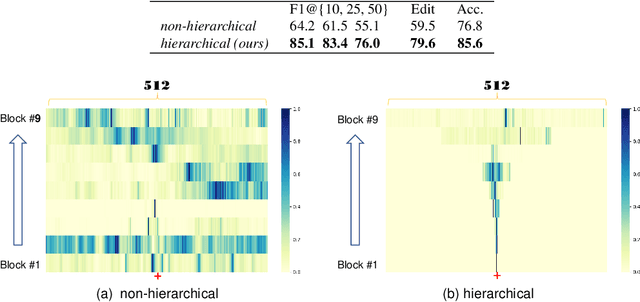
Algorithms for the action segmentation task typically use temporal models to predict what action is occurring at each frame for a minute-long daily activity. Recent studies have shown the potential of Transformer in modeling the relations among elements in sequential data. However, there are several major concerns when directly applying the Transformer to the action segmentation task, such as the lack of inductive biases with small training sets, the deficit in processing long input sequence, and the limitation of the decoder architecture to utilize temporal relations among multiple action segments to refine the initial predictions. To address these concerns, we design an efficient Transformer-based model for action segmentation task, named ASFormer, with three distinctive characteristics: (i) We explicitly bring in the local connectivity inductive priors because of the high locality of features. It constrains the hypothesis space within a reliable scope, and is beneficial for the action segmentation task to learn a proper target function with small training sets. (ii) We apply a pre-defined hierarchical representation pattern that efficiently handles long input sequences. (iii) We carefully design the decoder to refine the initial predictions from the encoder. Extensive experiments on three public datasets demonstrate that effectiveness of our methods. Code is available at \url{https://github.com/ChinaYi/ASFormer}.
Not End-to-End: Explore Multi-Stage Architecture for Online Surgical Phase Recognition
Jul 10, 2021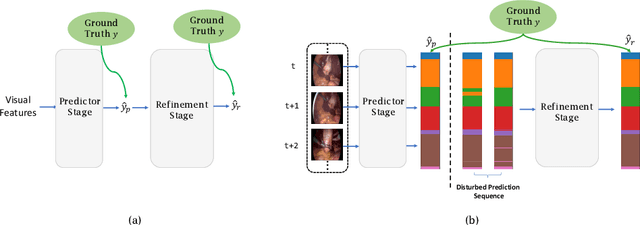

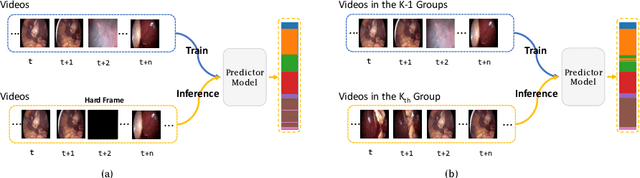

Surgical phase recognition is of particular interest to computer assisted surgery systems, in which the goal is to predict what phase is occurring at each frame for a surgery video. Networks with multi-stage architecture have been widely applied in many computer vision tasks with rich patterns, where a predictor stage first outputs initial predictions and an additional refinement stage operates on the initial predictions to perform further refinement. Existing works show that surgical video contents are well ordered and contain rich temporal patterns, making the multi-stage architecture well suited for the surgical phase recognition task. However, we observe that when simply applying the multi-stage architecture to the surgical phase recognition task, the end-to-end training manner will make the refinement ability fall short of its wishes. To address the problem, we propose a new non end-to-end training strategy and explore different designs of multi-stage architecture for surgical phase recognition task. For the non end-to-end training strategy, the refinement stage is trained separately with proposed two types of disturbed sequences. Meanwhile, we evaluate three different choices of refinement models to show that our analysis and solution are robust to the choices of specific multi-stage models. We conduct experiments on two public benchmarks, the M2CAI16 Workflow Challenge, and the Cholec80 dataset. Results show that multi-stage architecture trained with our strategy largely boosts the performance of the current state-of-the-art single-stage model. Code is available at \url{https://github.com/ChinaYi/casual_tcn}.
Towards Unified Surgical Skill Assessment
Jun 02, 2021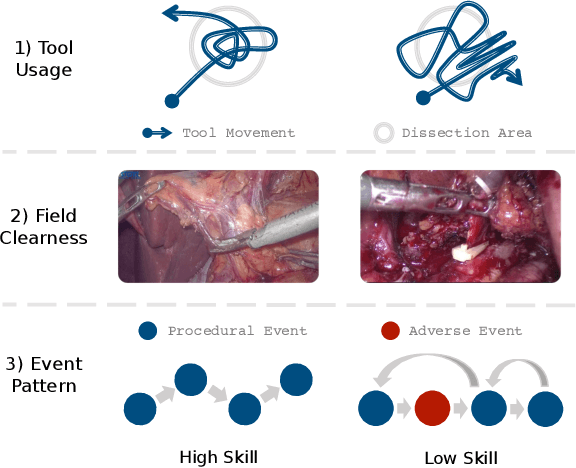

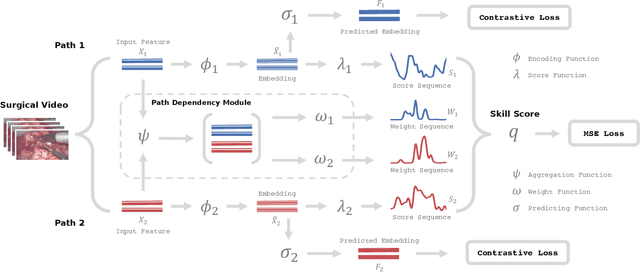

Surgical skills have a great influence on surgical safety and patients' well-being. Traditional assessment of surgical skills involves strenuous manual efforts, which lacks efficiency and repeatability. Therefore, we attempt to automatically predict how well the surgery is performed using the surgical video. In this paper, a unified multi-path framework for automatic surgical skill assessment is proposed, which takes care of multiple composing aspects of surgical skills, including surgical tool usage, intraoperative event pattern, and other skill proxies. The dependency relationships among these different aspects are specially modeled by a path dependency module in the framework. We conduct extensive experiments on the JIGSAWS dataset of simulated surgical tasks, and a new clinical dataset of real laparoscopic surgeries. The proposed framework achieves promising results on both datasets, with the state-of-the-art on the simulated dataset advanced from 0.71 Spearman's correlation to 0.80. It is also shown that combining multiple skill aspects yields better performance than relying on a single aspect.
Unified Quality Assessment of In-the-Wild Videos with Mixed Datasets Training
Nov 15, 2020
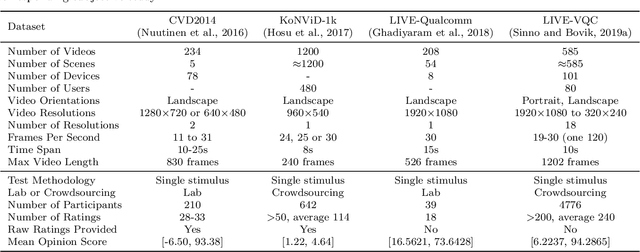
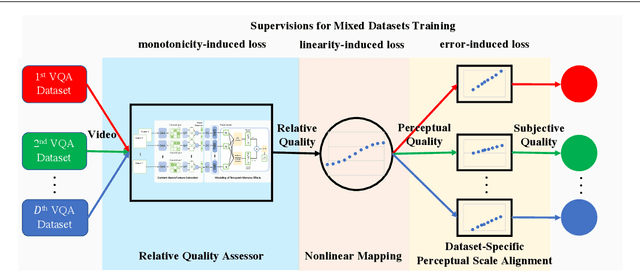
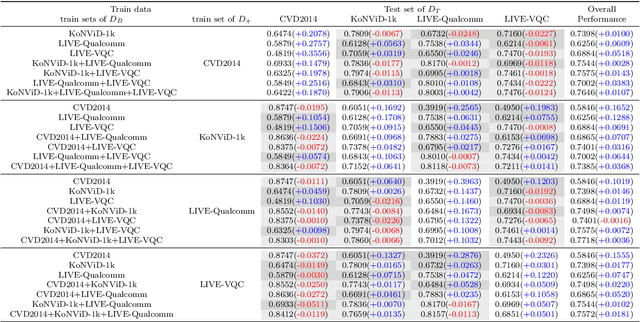
Video quality assessment (VQA) is an important problem in computer vision. The videos in computer vision applications are usually captured in the wild. We focus on automatically assessing the quality of in-the-wild videos, which is a challenging problem due to the absence of reference videos, the complexity of distortions, and the diversity of video contents. Moreover, the video contents and distortions among existing datasets are quite different, which leads to poor performance of data-driven methods in the cross-dataset evaluation setting. To improve the performance of quality assessment models, we borrow intuitions from human perception, specifically, content dependency and temporal-memory effects of human visual system. To face the cross-dataset evaluation challenge, we explore a mixed datasets training strategy for training a single VQA model with multiple datasets. The proposed unified framework explicitly includes three stages: relative quality assessor, nonlinear mapping, and dataset-specific perceptual scale alignment, to jointly predict relative quality, perceptual quality, and subjective quality. Experiments are conducted on four publicly available datasets for VQA in the wild, i.e., LIVE-VQC, LIVE-Qualcomm, KoNViD-1k, and CVD2014. The experimental results verify the effectiveness of the mixed datasets training strategy and prove the superior performance of the unified model in comparison with the state-of-the-art models. For reproducible research, we make the PyTorch implementation of our method available at https://github.com/lidq92/MDTVSFA.
Human Perception-based Evaluation Criterion for Ultra-high Resolution Cell Membrane Segmentation
Oct 16, 2020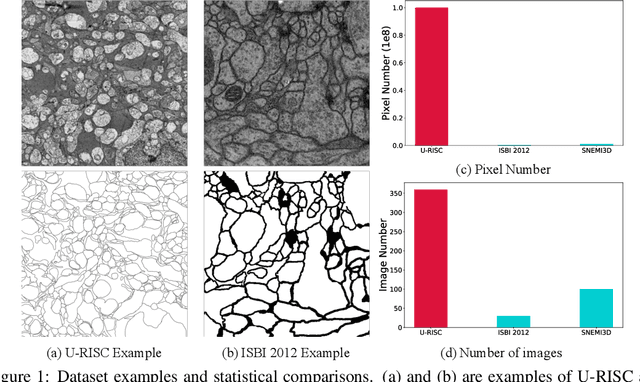
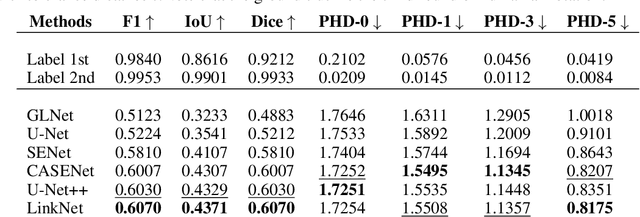
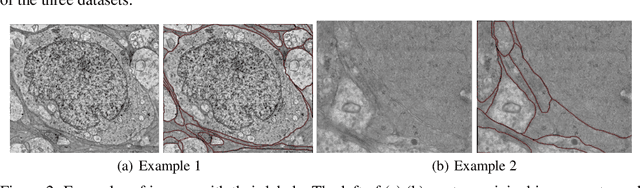

Computer vision technology is widely used in biological and medical data analysis and understanding. However, there are still two major bottlenecks in the field of cell membrane segmentation, which seriously hinder further research: lack of sufficient high-quality data and lack of suitable evaluation criteria. In order to solve these two problems, this paper first proposes an Ultra-high Resolution Image Segmentation dataset for the Cell membrane, called U-RISC, the largest annotated Electron Microscopy (EM) dataset for the Cell membrane with multiple iterative annotations and uncompressed high-resolution raw data. During the analysis process of the U-RISC, we found that the current popular segmentation evaluation criteria are inconsistent with human perception. This interesting phenomenon is confirmed by a subjective experiment involving twenty people. Furthermore, to resolve this inconsistency, we propose a new evaluation criterion called Perceptual Hausdorff Distance (PHD) to measure the quality of cell membrane segmentation results. Detailed performance comparison and discussion of classic segmentation methods along with two iterative manual annotation results under existing evaluation criteria and PHD is given.
Surgical Skill Assessment on In-Vivo Clinical Data via the Clearness of Operating Field
Aug 27, 2020
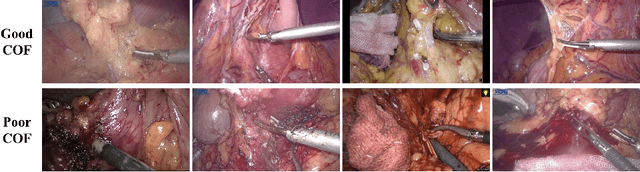

Surgical skill assessment is important for surgery training and quality control. Prior works on this task largely focus on basic surgical tasks such as suturing and knot tying performed in simulation settings. In contrast, surgical skill assessment is studied in this paper on a real clinical dataset, which consists of fifty-seven in-vivo laparoscopic surgeries and corresponding skill scores annotated by six surgeons. From analyses on this dataset, the clearness of operating field (COF) is identified as a good proxy for overall surgical skills, given its strong correlation with overall skills and high inter-annotator consistency. Then an objective and automated framework based on neural network is proposed to predict surgical skills through the proxy of COF. The neural network is jointly trained with a supervised regression loss and an unsupervised rank loss. In experiments, the proposed method achieves 0.55 Spearman's correlation with the ground truth of overall technical skill, which is even comparable with the human performance of junior surgeons.
Unsupervised Surgical Instrument Segmentation via Anchor Generation and Semantic Diffusion
Aug 27, 2020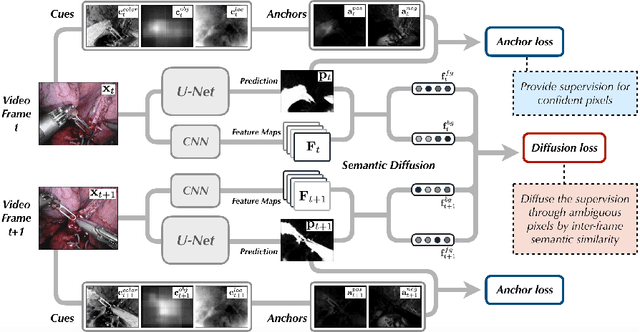
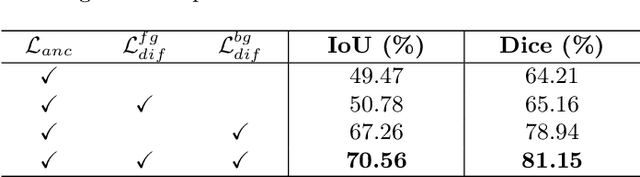
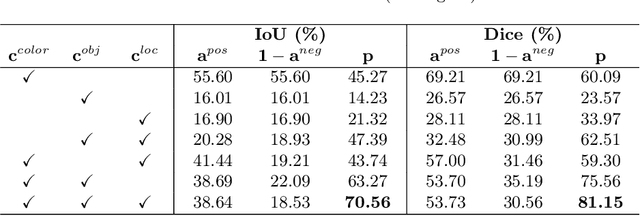
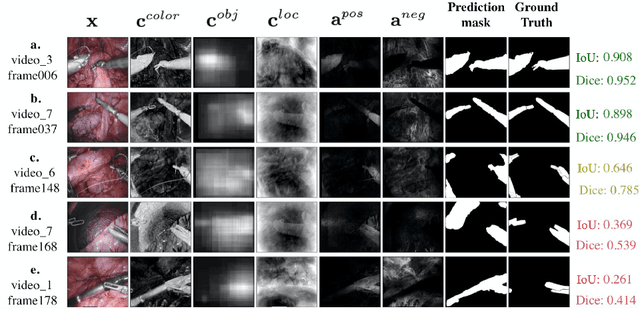
Surgical instrument segmentation is a key component in developing context-aware operating rooms. Existing works on this task heavily rely on the supervision of a large amount of labeled data, which involve laborious and expensive human efforts. In contrast, a more affordable unsupervised approach is developed in this paper. To train our model, we first generate anchors as pseudo labels for instruments and background tissues respectively by fusing coarse handcrafted cues. Then a semantic diffusion loss is proposed to resolve the ambiguity in the generated anchors via the feature correlation between adjacent video frames. In the experiments on the binary instrument segmentation task of the 2017 MICCAI EndoVis Robotic Instrument Segmentation Challenge dataset, the proposed method achieves 0.71 IoU and 0.81 Dice score without using a single manual annotation, which is promising to show the potential of unsupervised learning for surgical tool segmentation.