 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage Augmentations for GAN Training
Jun 04, 2020
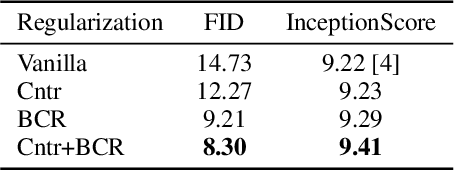
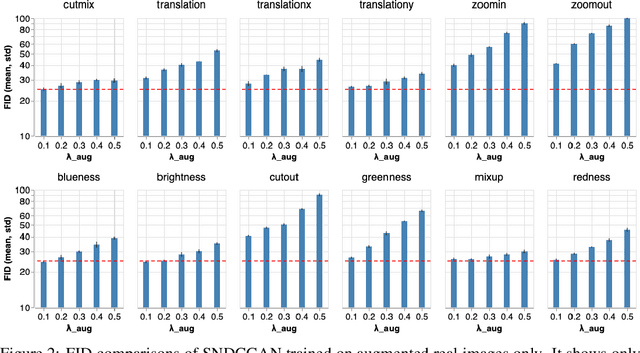
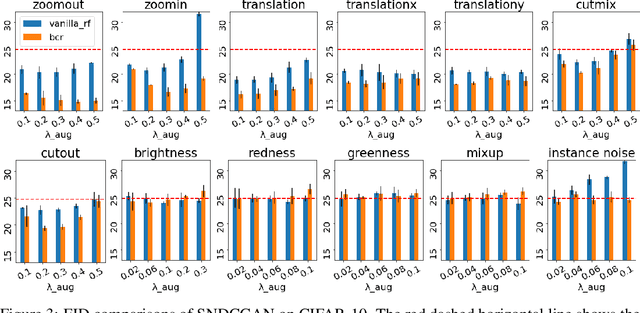
Data augmentations have been widely studied to improve the accuracy and robustness of classifiers. However, the potential of image augmentation in improving GAN models for image synthesis has not been thoroughly investigated in previous studies. In this work, we systematically study the effectiveness of various existing augmentation techniques for GAN training in a variety of settings. We provide insights and guidelines on how to augment images for both vanilla GANs and GANs with regularizations, improving the fidelity of the generated images substantially. Surprisingly, we find that vanilla GANs attain generation quality on par with recent state-of-the-art results if we use augmentations on both real and generated images. When this GAN training is combined with other augmentation-based regularization techniques, such as contrastive loss and consistency regularization, the augmentations further improve the quality of generated images. We provide new state-of-the-art results for conditional generation on CIFAR-10 with both consistency loss and contrastive loss as additional regularizations.
Understanding Why Neural Networks Generalize Well Through GSNR of Parameters
Feb 24, 2020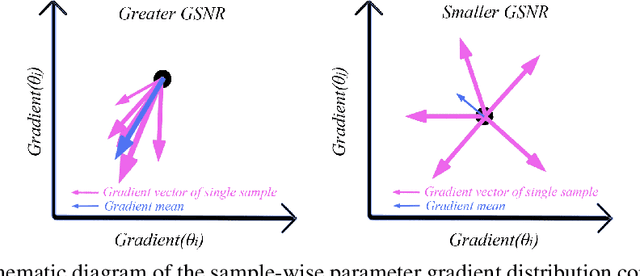
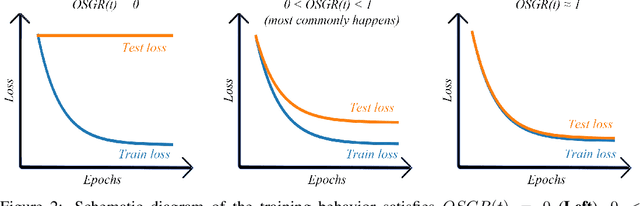

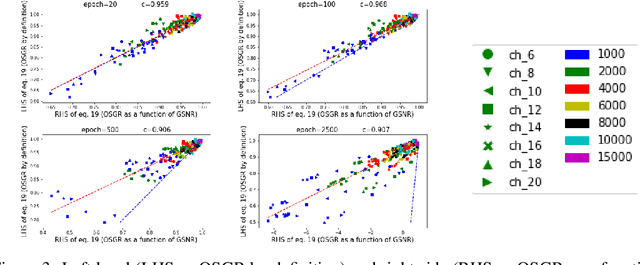
As deep neural networks (DNNs) achieve tremendous success across many application domains, researchers tried to explore in many aspects on why they generalize well. In this paper, we provide a novel perspective on these issues using the gradient signal to noise ratio (GSNR) of parameters during training process of DNNs. The GSNR of a parameter is defined as the ratio between its gradient's squared mean and variance, over the data distribution. Based on several approximations, we establish a quantitative relationship between model parameters' GSNR and the generalization gap. This relationship indicates that larger GSNR during training process leads to better generalization performance. Moreover, we show that, different from that of shallow models (e.g. logistic regression, support vector machines), the gradient descent optimization dynamics of DNNs naturally produces large GSNR during training, which is probably the key to DNNs' remarkable generalization ability.
A Simple Framework for Contrastive Learning of Visual Representations
Feb 13, 2020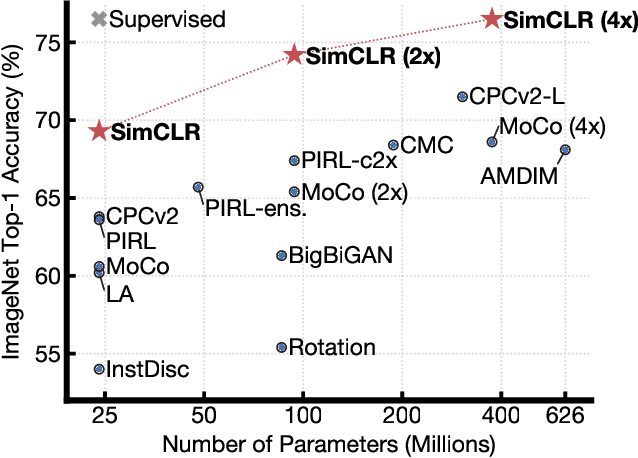

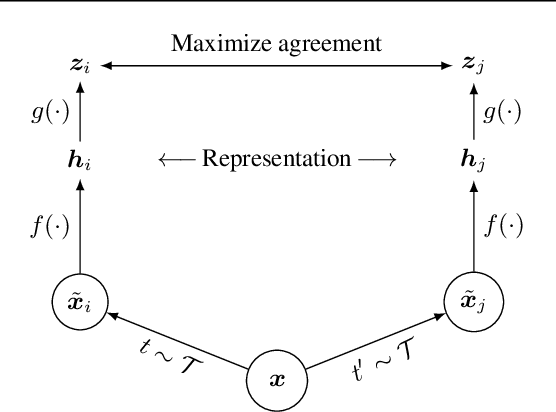

This paper presents SimCLR: a simple framework for contrastive learning of visual representations. We simplify recently proposed contrastive self-supervised learning algorithms without requiring specialized architectures or a memory bank. In order to understand what enables the contrastive prediction tasks to learn useful representations, we systematically study the major components of our framework. We show that (1) composition of data augmentations plays a critical role in defining effective predictive tasks, (2) introducing a learnable nonlinear transformation between the representation and the contrastive loss substantially improves the quality of the learned representations, and (3) contrastive learning benefits from larger batch sizes and more training steps compared to supervised learning. By combining these findings, we are able to considerably outperform previous methods for self-supervised and semi-supervised learning on ImageNet. A linear classifier trained on self-supervised representations learned by SimCLR achieves 76.5% top-1 accuracy, which is a 7% relative improvement over previous state-of-the-art, matching the performance of a supervised ResNet-50. When fine-tuned on only 1% of the labels, we achieve 85.8% top-5 accuracy, outperforming AlexNet with 100X fewer labels.
Differentiable Product Quantization for End-to-End Embedding Compression
Aug 26, 2019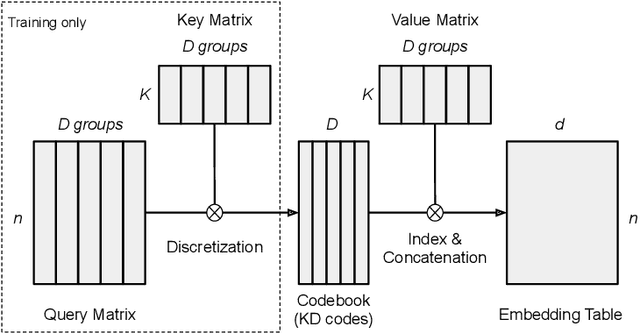
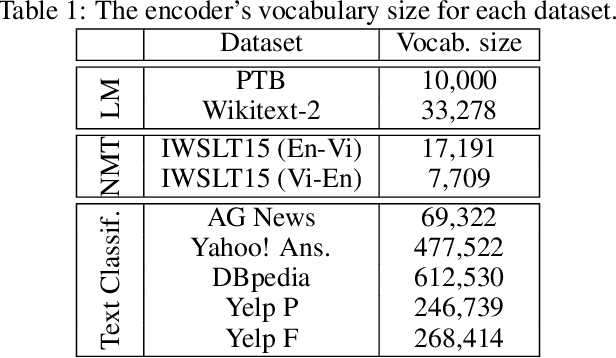
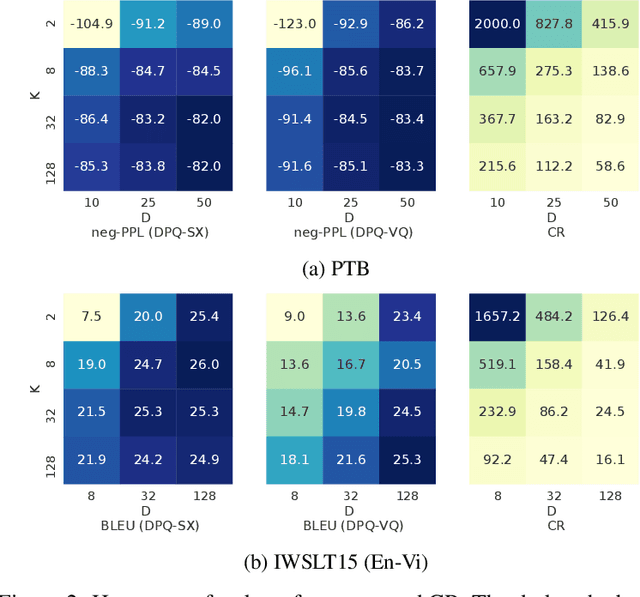
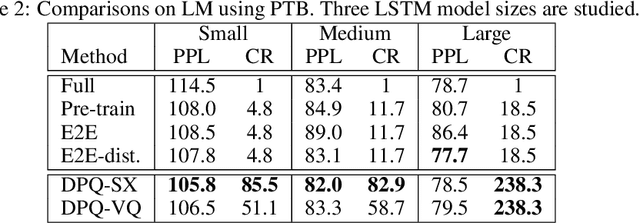
Embedding layer is commonly used to map discrete symbols into continuous embedding vectors that reflect their semantic meanings. As the number of symbols increase, the number of embedding parameter, as well as their size, increase linearly and become problematically large. In this work, we aim to reduce the size of embedding layer via learning discrete codes and composing embedding vectors from the codes. More specifically, we propose a differentiable product quantization framework with two instantiations, which can serve as an efficient drop-in replacement for existing embedding layer. Empirically, we evaluate the proposed method on three different language tasks, and show that the proposed method enables end-to-end training of embedding compression that achieves significant compression ratios (14-238$\times$) at almost no performance cost (sometimes even better).
Few-Shot Representation Learning for Out-Of-Vocabulary Words
Jul 01, 2019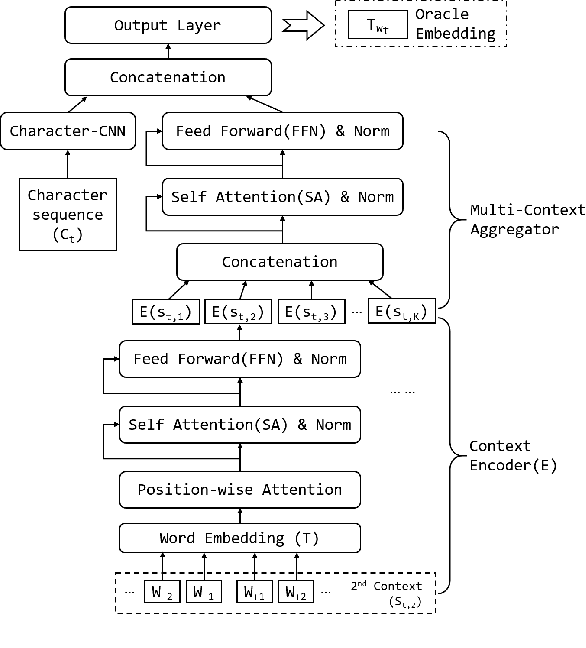
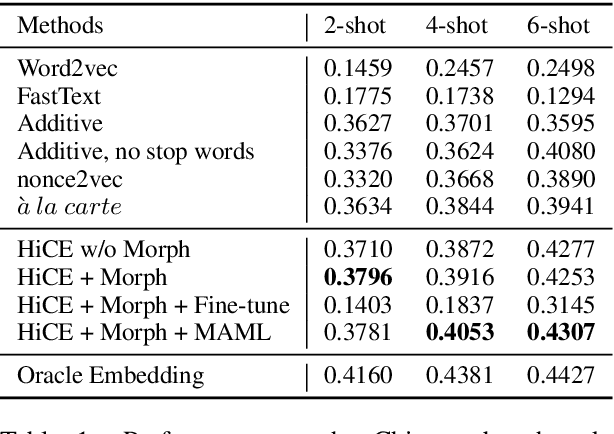
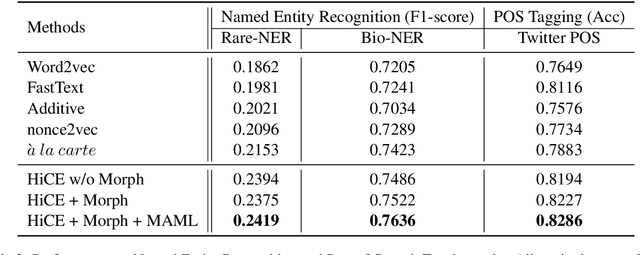

Existing approaches for learning word embeddings often assume there are sufficient occurrences for each word in the corpus, such that the representation of words can be accurately estimated from their contexts. However, in real-world scenarios, out-of-vocabulary (a.k.a. OOV) words that do not appear in training corpus emerge frequently. It is challenging to learn accurate representations of these words with only a few observations. In this paper, we formulate the learning of OOV embeddings as a few-shot regression problem, and address it by training a representation function to predict the oracle embedding vector (defined as embedding trained with abundant observations) based on limited observations. Specifically, we propose a novel hierarchical attention-based architecture to serve as the neural regression function, with which the context information of a word is encoded and aggregated from K observations. Furthermore, our approach can leverage Model-Agnostic Meta-Learning (MAML) for adapting the learned model to the new corpus fast and robustly. Experiments show that the proposed approach significantly outperforms existing methods in constructing accurate embeddings for OOV words, and improves downstream tasks where these embeddings are utilized.
Pre-Training Graph Neural Networks for Generic Structural Feature Extraction
May 31, 2019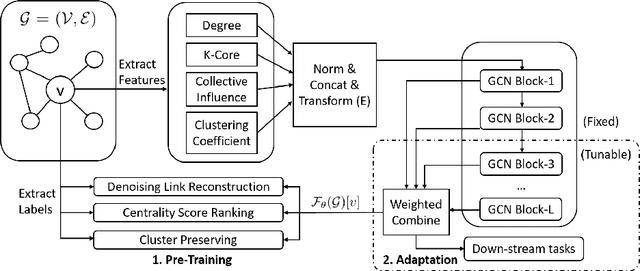
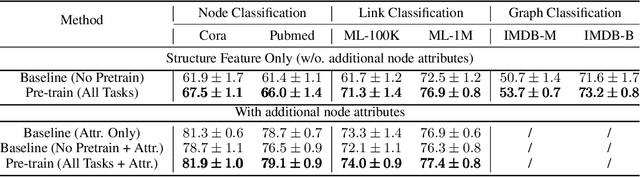

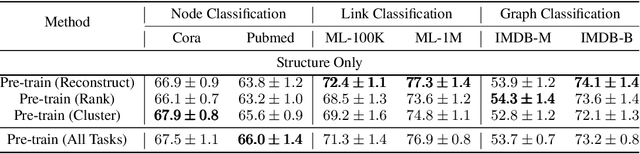
Graph neural networks (GNNs) are shown to be successful in modeling applications with graph structures. However, training an accurate GNN model requires a large collection of labeled data and expressive features, which might be inaccessible for some applications. To tackle this problem, we propose a pre-training framework that captures generic graph structural information that is transferable across tasks. Our framework can leverage the following three tasks: 1) denoising link reconstruction, 2) centrality score ranking, and 3) cluster preserving. The pre-training procedure can be conducted purely on the synthetic graphs, and the pre-trained GNN is then adapted for downstream applications. With the proposed pre-training procedure, the generic structural information is learned and preserved, thus the pre-trained GNN requires less amount of labeled data and fewer domain-specific features to achieve high performance on different downstream tasks. Comprehensive experiments demonstrate that our proposed framework can significantly enhance the performance of various tasks at the level of node, link, and graph.
Are Powerful Graph Neural Nets Necessary? A Dissection on Graph Classification
May 24, 2019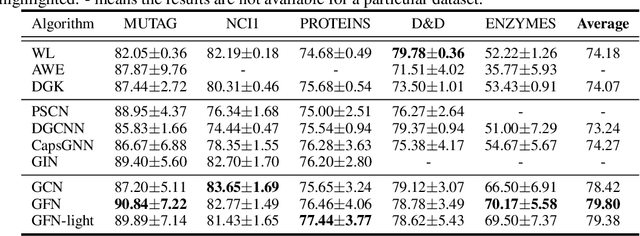
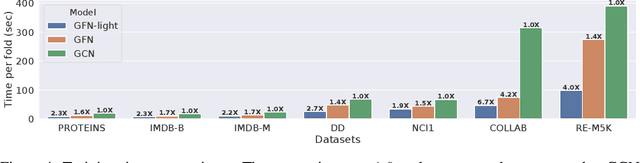
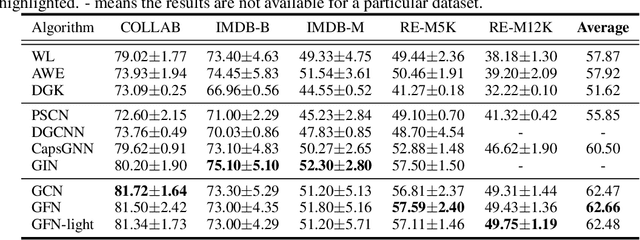
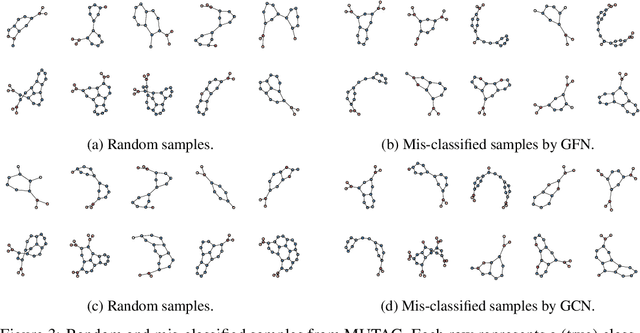
Graph Neural Nets (GNNs) have received increasing attentions, partially due to their superior performance in many node and graph classification tasks. However, there is a lack of understanding on what they are learning and how sophisticated the learned graph functions are. In this work, we first propose Graph Feature Network (GFN), a simple lightweight neural net defined on a set of graph augmented features. We then propose a dissection of GNNs on graph classification into two parts: 1) the graph filtering, where graph-based neighbor aggregations are performed, and 2) the set function, where a set of hidden node features are composed for prediction. We prove that GFN can be derived by linearizing graph filtering part of GNNs, and leverage it to test the importance of the two parts separately. Empirically we perform evaluations on common graph classification benchmarks. To our surprise, we find that, despite the simplification, GFN could match or exceed the best accuracies produced by recently proposed GNNs, with a fraction of computation cost. Our results suggest that linear graph filtering with non-linear set function is powerful enough, and common graph classification benchmarks seem inadequate for testing advanced GNN variants.
Unsupervised Inductive Whole-Graph Embedding by Preserving Graph Proximity
Apr 01, 2019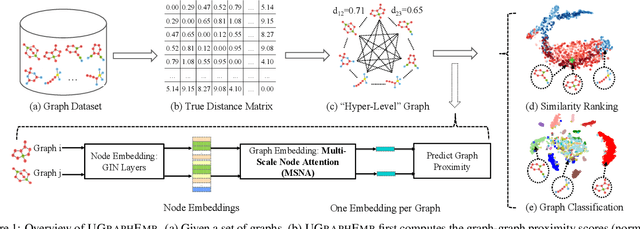
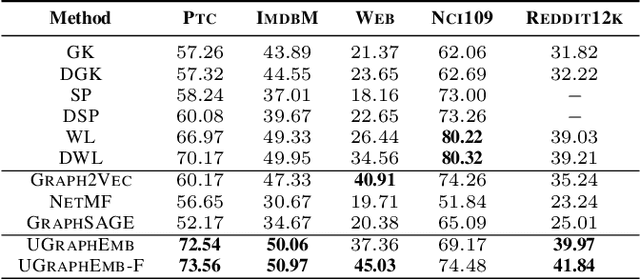
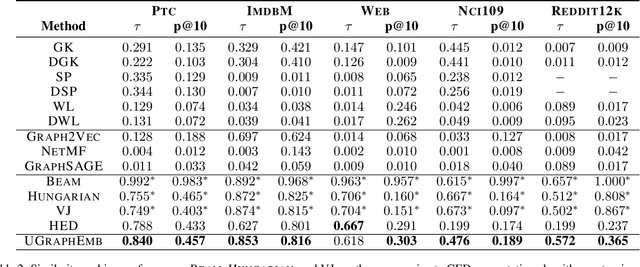

We introduce a novel approach to graph-level representation learning, which is to embed an entire graph into a vector space where the embeddings of two graphs preserve their graph-graph proximity. Our approach, UGRAPHEMB, is a general framework that provides a novel means to performing graph-level embedding in a completely unsupervised and inductive manner. The learned neural network can be considered as a function that receives any graph as input, either seen or unseen in the training set, and transforms it into an embedding. A novel graph-level embedding generation mechanism called Multi-Scale Node Attention (MSNA), is proposed. Experiments on five real graph datasets show that UGRAPHEMB achieves competitive accuracy in the tasks of graph classification, similarity ranking, and graph visualization.
Doubly Sparse: Sparse Mixture of Sparse Experts for Efficient Softmax Inference
Jan 30, 2019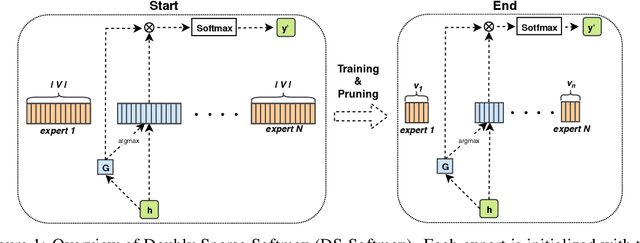
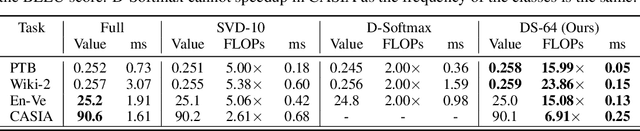
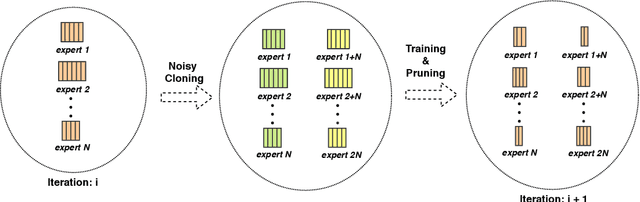
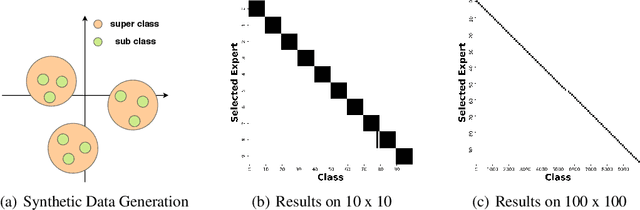
Computations for the softmax function are significantly expensive when the number of output classes is large. In this paper, we present a novel softmax inference speedup method, Doubly Sparse Softmax (DS-Softmax), that leverages sparse mixture of sparse experts to efficiently retrieve top-k classes. Different from most existing methods that require and approximate a fixed softmax, our method is learning-based and can adapt softmax weights for a better approximation. In particular, our method learns a two-level hierarchy which divides entire output class space into several partially overlapping experts. Each expert is sparse and only contains a subset of output classes. To find top-k classes, a sparse mixture enables us to find the most probable expert quickly, and the sparse expert enables us to search within a small-scale softmax. We empirically conduct evaluation on several real-world tasks (including neural machine translation, language modeling and image classification) and demonstrate that significant computation reductions can be achieved without loss of performance.
Self-Supervised Generative Adversarial Networks
Nov 27, 2018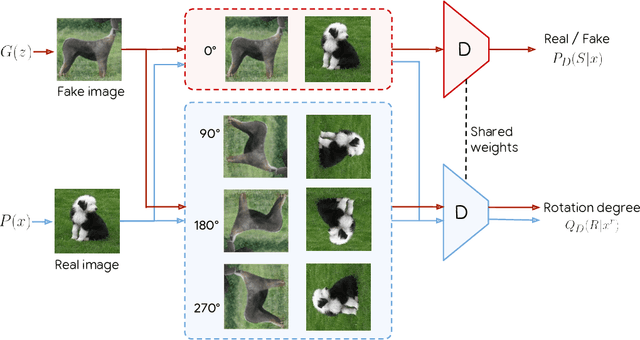
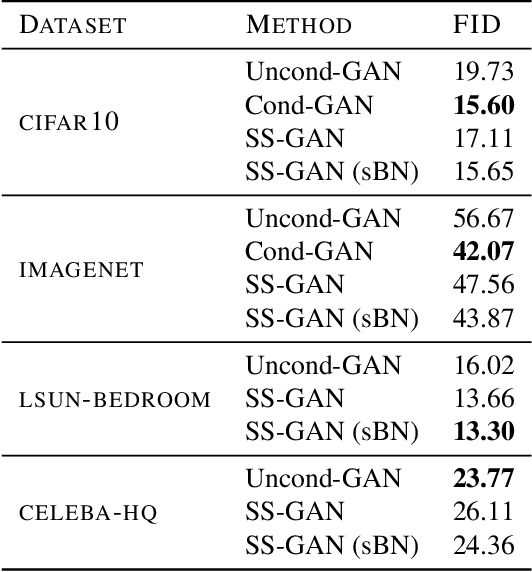
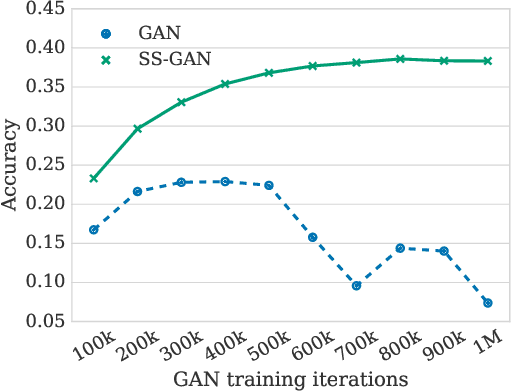
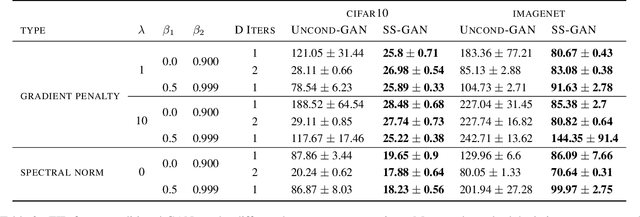
Conditional GANs are at the forefront of natural image synthesis. The main drawback of such models is the necessity for labelled data. In this work we exploit two popular unsupervised learning techniques, adversarial training and self-supervision, to close the gap between conditional and unconditional GANs. In particular, we allow the networks to collaborate on the task of representation learning, while being adversarial with respect to the classic GAN game. The role of self-supervision is to encourage the discriminator to learn meaningful feature representations which are not forgotten during training. We test empirically both the quality of the learned image representations, and the quality of the synthesized images. Under the same conditions, the self-supervised GAN attains a similar performance to state-of-the-art conditional counterparts. Finally, we show that this approach to fully unsupervised learning can be scaled to attain an FID of 33 on unconditional ImageNet generation.