 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDrivable Volumetric Avatars using Texel-Aligned Features
Jul 20, 2022
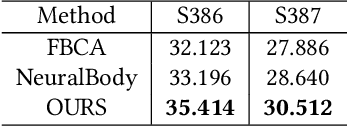
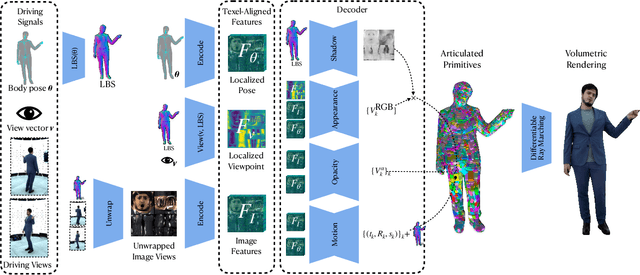
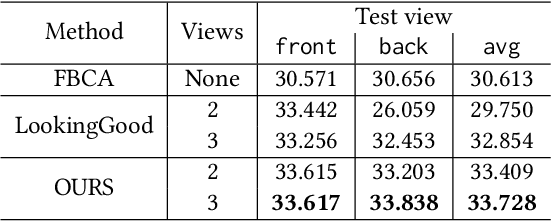
Photorealistic telepresence requires both high-fidelity body modeling and faithful driving to enable dynamically synthesized appearance that is indistinguishable from reality. In this work, we propose an end-to-end framework that addresses two core challenges in modeling and driving full-body avatars of real people. One challenge is driving an avatar while staying faithful to details and dynamics that cannot be captured by a global low-dimensional parameterization such as body pose. Our approach supports driving of clothed avatars with wrinkles and motion that a real driving performer exhibits beyond the training corpus. Unlike existing global state representations or non-parametric screen-space approaches, we introduce texel-aligned features -- a localised representation which can leverage both the structural prior of a skeleton-based parametric model and observed sparse image signals at the same time. Another challenge is modeling a temporally coherent clothed avatar, which typically requires precise surface tracking. To circumvent this, we propose a novel volumetric avatar representation by extending mixtures of volumetric primitives to articulated objects. By explicitly incorporating articulation, our approach naturally generalizes to unseen poses. We also introduce a localized viewpoint conditioning, which leads to a large improvement in generalization of view-dependent appearance. The proposed volumetric representation does not require high-quality mesh tracking as a prerequisite and brings significant quality improvements compared to mesh-based counterparts. In our experiments, we carefully examine our design choices and demonstrate the efficacy of our approach, outperforming the state-of-the-art methods on challenging driving scenarios.
Dressing Avatars: Deep Photorealistic Appearance for Physically Simulated Clothing
Jun 30, 2022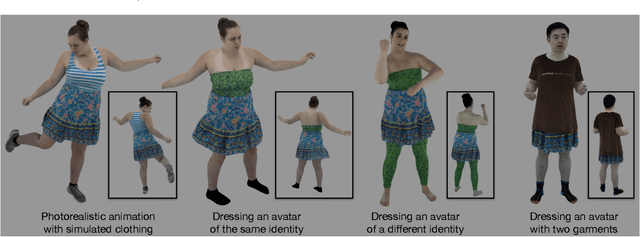
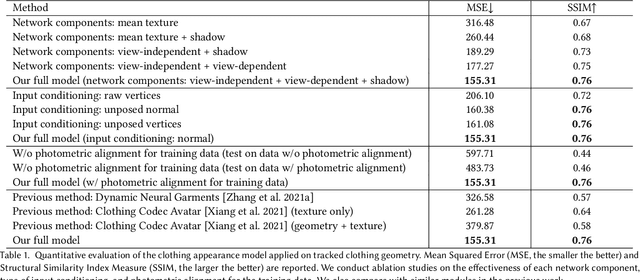
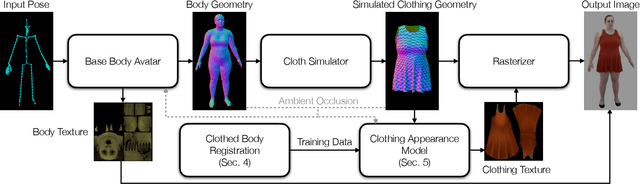
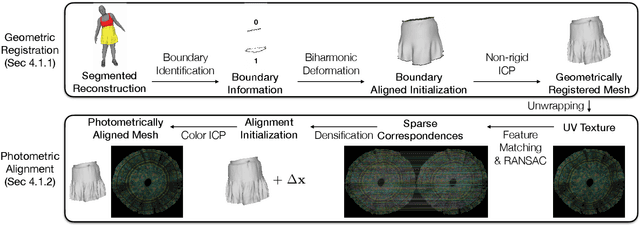
Despite recent progress in developing animatable full-body avatars, realistic modeling of clothing - one of the core aspects of human self-expression - remains an open challenge. State-of-the-art physical simulation methods can generate realistically behaving clothing geometry at interactive rate. Modeling photorealistic appearance, however, usually requires physically-based rendering which is too expensive for interactive applications. On the other hand, data-driven deep appearance models are capable of efficiently producing realistic appearance, but struggle at synthesizing geometry of highly dynamic clothing and handling challenging body-clothing configurations. To this end, we introduce pose-driven avatars with explicit modeling of clothing that exhibit both realistic clothing dynamics and photorealistic appearance learned from real-world data. The key idea is to introduce a neural clothing appearance model that operates on top of explicit geometry: at train time we use high-fidelity tracking, whereas at animation time we rely on physically simulated geometry. Our key contribution is a physically-inspired appearance network, capable of generating photorealistic appearance with view-dependent and dynamic shadowing effects even for unseen body-clothing configurations. We conduct a thorough evaluation of our model and demonstrate diverse animation results on several subjects and different types of clothing. Unlike previous work on photorealistic full-body avatars, our approach can produce much richer dynamics and more realistic deformations even for loose clothing. We also demonstrate that our formulation naturally allows clothing to be used with avatars of different people while staying fully animatable, thus enabling, for the first time, photorealistic avatars with novel clothing.
Garment Avatars: Realistic Cloth Driving using Pattern Registration
Jun 07, 2022

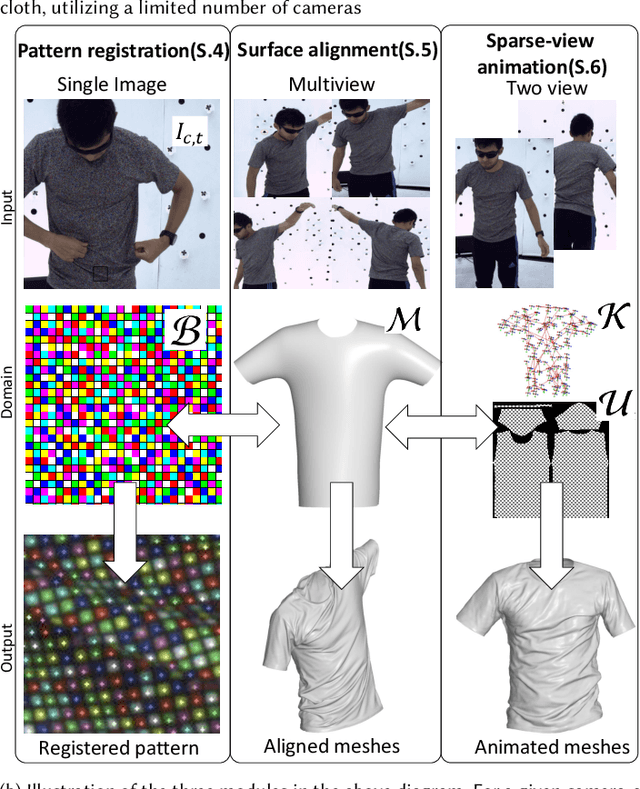

Virtual telepresence is the future of online communication. Clothing is an essential part of a person's identity and self-expression. Yet, ground truth data of registered clothes is currently unavailable in the required resolution and accuracy for training telepresence models for realistic cloth animation. Here, we propose an end-to-end pipeline for building drivable representations for clothing. The core of our approach is a multi-view patterned cloth tracking algorithm capable of capturing deformations with high accuracy. We further rely on the high-quality data produced by our tracking method to build a Garment Avatar: an expressive and fully-drivable geometry model for a piece of clothing. The resulting model can be animated using a sparse set of views and produces highly realistic reconstructions which are faithful to the driving signals. We demonstrate the efficacy of our pipeline on a realistic virtual telepresence application, where a garment is being reconstructed from two views, and a user can pick and swap garment design as they wish. In addition, we show a challenging scenario when driven exclusively with body pose, our drivable garment avatar is capable of producing realistic cloth geometry of significantly higher quality than the state-of-the-art.
DANBO: Disentangled Articulated Neural Body Representations via Graph Neural Networks
May 03, 2022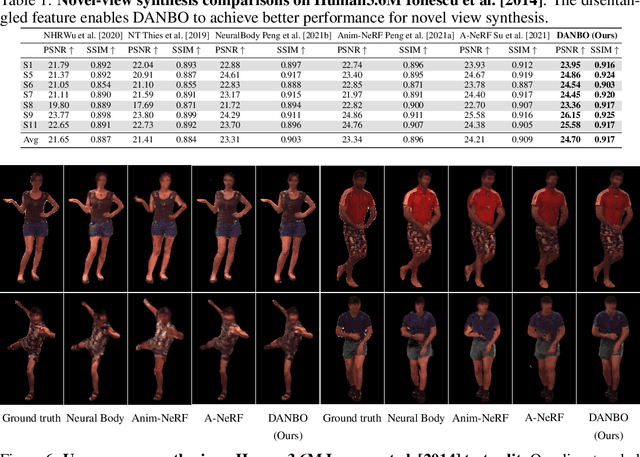
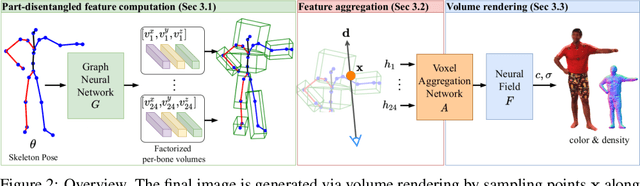
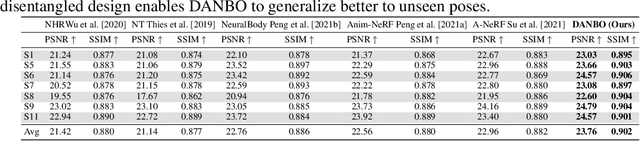
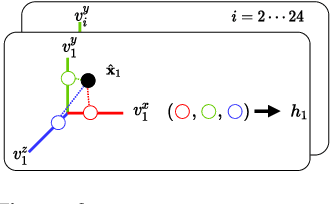
Deep learning greatly improved the realism of animatable human models by learning geometry and appearance from collections of 3D scans, template meshes, and multi-view imagery. High-resolution models enable photo-realistic avatars but at the cost of requiring studio settings not available to end users. Our goal is to create avatars directly from raw images without relying on expensive studio setups and surface tracking. While a few such approaches exist, those have limited generalization capabilities and are prone to learning spurious (chance) correlations between irrelevant body parts, resulting in implausible deformations and missing body parts on unseen poses. We introduce a three-stage method that induces two inductive biases to better disentangled pose-dependent deformation. First, we model correlations of body parts explicitly with a graph neural network. Second, to further reduce the effect of chance correlations, we introduce localized per-bone features that use a factorized volumetric representation and a new aggregation function. We demonstrate that our model produces realistic body shapes under challenging unseen poses and shows high-quality image synthesis. Our proposed representation strikes a better trade-off between model capacity, expressiveness, and robustness than competing methods. Project website: https://lemonatsu.github.io/danbo.
AutoAvatar: Autoregressive Neural Fields for Dynamic Avatar Modeling
Mar 25, 2022
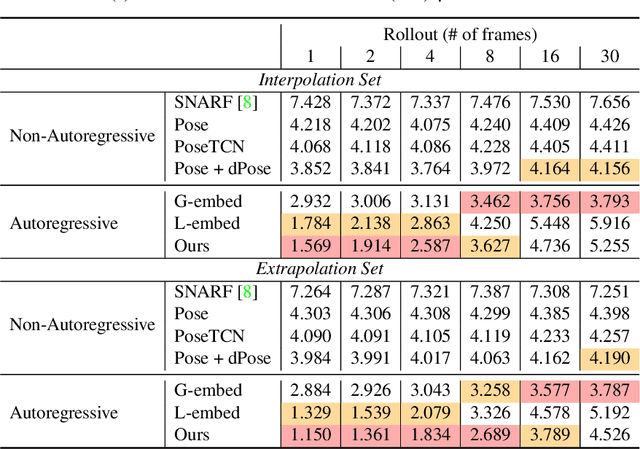
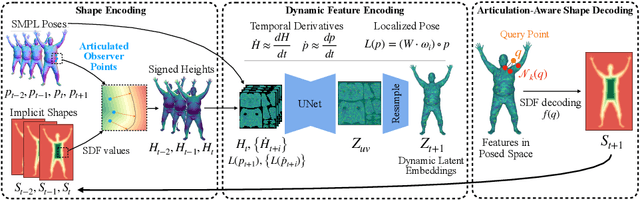
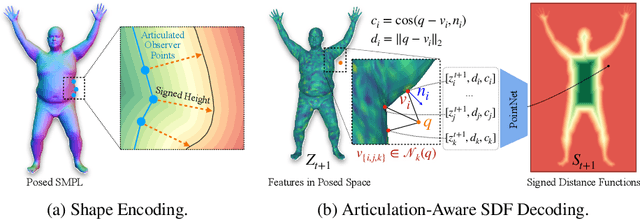
Neural fields such as implicit surfaces have recently enabled avatar modeling from raw scans without explicit temporal correspondences. In this work, we exploit autoregressive modeling to further extend this notion to capture dynamic effects, such as soft-tissue deformations. Although autoregressive models are naturally capable of handling dynamics, it is non-trivial to apply them to implicit representations, as explicit state decoding is infeasible due to prohibitive memory requirements. In this work, for the first time, we enable autoregressive modeling of implicit avatars. To reduce the memory bottleneck and efficiently model dynamic implicit surfaces, we introduce the notion of articulated observer points, which relate implicit states to the explicit surface of a parametric human body model. We demonstrate that encoding implicit surfaces as a set of height fields defined on articulated observer points leads to significantly better generalization compared to a latent representation. The experiments show that our approach outperforms the state of the art, achieving plausible dynamic deformations even for unseen motions. https://zqbai-jeremy.github.io/autoavatar
Explicit Clothing Modeling for an Animatable Full-Body Avatar
Jun 30, 2021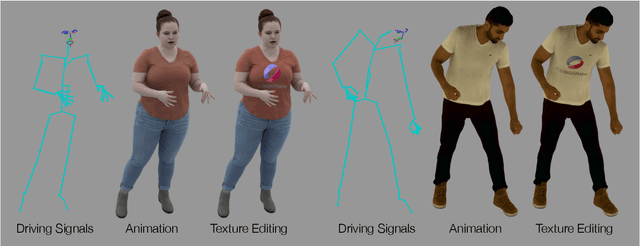
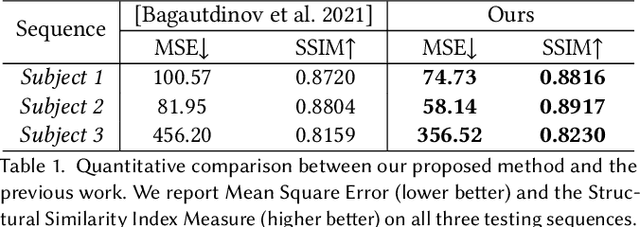

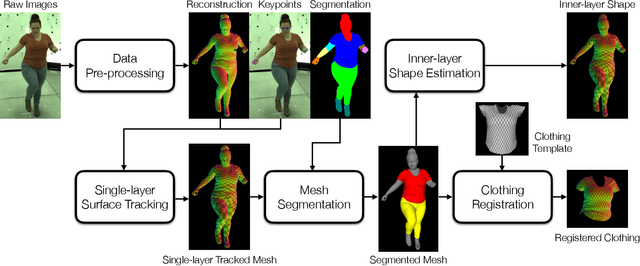
Recent work has shown great progress in building photorealistic animatable full-body codec avatars, but these avatars still face difficulties in generating high-fidelity animation of clothing. To address the difficulties, we propose a method to build an animatable clothed body avatar with an explicit representation of the clothing on the upper body from multi-view captured videos. We use a two-layer mesh representation to separately register the 3D scans with templates. In order to improve the photometric correspondence across different frames, texture alignment is then performed through inverse rendering of the clothing geometry and texture predicted by a variational autoencoder. We then train a new two-layer codec avatar with separate modeling of the upper clothing and the inner body layer. To learn the interaction between the body dynamics and clothing states, we use a temporal convolution network to predict the clothing latent code based on a sequence of input skeletal poses. We show photorealistic animation output for three different actors, and demonstrate the advantage of our clothed-body avatars over single-layer avatars in the previous work. We also show the benefit of an explicit clothing model which allows the clothing texture to be edited in the animation output.
DeepMesh: Differentiable Iso-Surface Extraction
Jun 20, 2021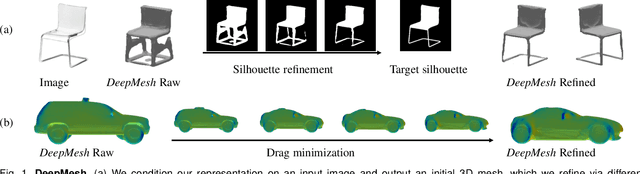
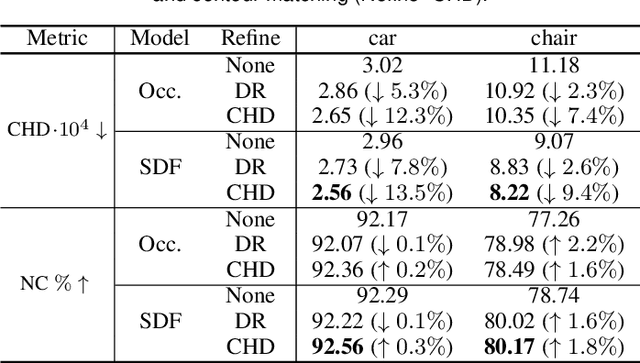
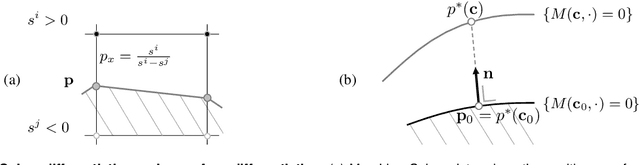
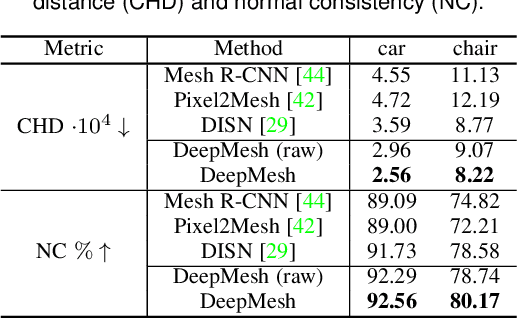
Geometric Deep Learning has recently made striking progress with the advent of continuous Deep Implicit Fields. They allow for detailed modeling of watertight surfaces of arbitrary topology while not relying on a 3D Euclidean grid, resulting in a learnable parameterization that is unlimited in resolution. Unfortunately, these methods are often unsuitable for applications that require an explicit mesh-based surface representation because converting an implicit field to such a representation relies on the Marching Cubes algorithm, which cannot be differentiated with respect to the underlying implicit field. In this work, we remove this limitation and introduce a differentiable way to produce explicit surface mesh representations from Deep Implicit Fields. Our key insight is that by reasoning on how implicit field perturbations impact local surface geometry, one can ultimately differentiate the 3D location of surface samples with respect to the underlying deep implicit field. We exploit this to define DeepMesh -- end-to-end differentiable mesh representation that can vary its topology. We use two different applications to validate our theoretical insight: Single view 3D Reconstruction via Differentiable Rendering and Physically-Driven Shape Optimization. In both cases our end-to-end differentiable parameterization gives us an edge over state-of-the-art algorithms.
Driving-Signal Aware Full-Body Avatars
May 21, 2021
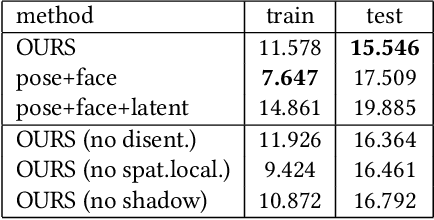
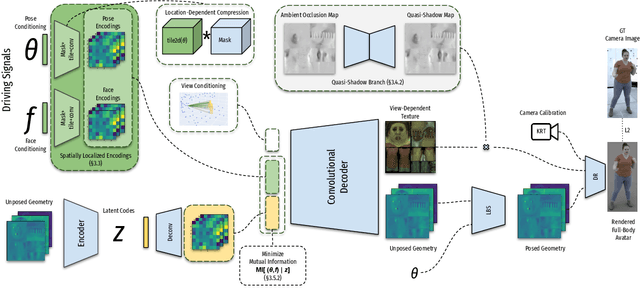
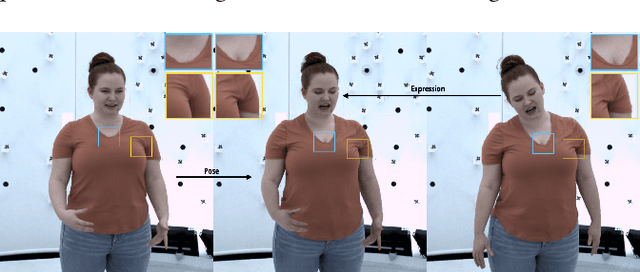
We present a learning-based method for building driving-signal aware full-body avatars. Our model is a conditional variational autoencoder that can be animated with incomplete driving signals, such as human pose and facial keypoints, and produces a high-quality representation of human geometry and view-dependent appearance. The core intuition behind our method is that better drivability and generalization can be achieved by disentangling the driving signals and remaining generative factors, which are not available during animation. To this end, we explicitly account for information deficiency in the driving signal by introducing a latent space that exclusively captures the remaining information, thus enabling the imputation of the missing factors required during full-body animation, while remaining faithful to the driving signal. We also propose a learnable localized compression for the driving signal which promotes better generalization, and helps minimize the influence of global chance-correlations often found in real datasets. For a given driving signal, the resulting variational model produces a compact space of uncertainty for missing factors that allows for an imputation strategy best suited to a particular application. We demonstrate the efficacy of our approach on the challenging problem of full-body animation for virtual telepresence with driving signals acquired from minimal sensors placed in the environment and mounted on a VR-headset.
Learning Compositional Radiance Fields of Dynamic Human Heads
Dec 17, 2020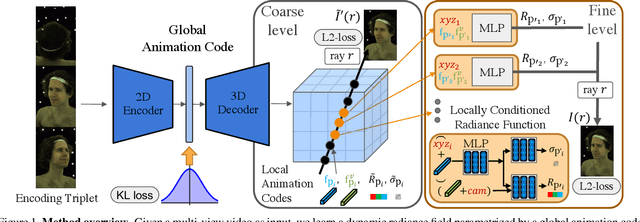



Photorealistic rendering of dynamic humans is an important ability for telepresence systems, virtual shopping, synthetic data generation, and more. Recently, neural rendering methods, which combine techniques from computer graphics and machine learning, have created high-fidelity models of humans and objects. Some of these methods do not produce results with high-enough fidelity for driveable human models (Neural Volumes) whereas others have extremely long rendering times (NeRF). We propose a novel compositional 3D representation that combines the best of previous methods to produce both higher-resolution and faster results. Our representation bridges the gap between discrete and continuous volumetric representations by combining a coarse 3D-structure-aware grid of animation codes with a continuous learned scene function that maps every position and its corresponding local animation code to its view-dependent emitted radiance and local volume density. Differentiable volume rendering is employed to compute photo-realistic novel views of the human head and upper body as well as to train our novel representation end-to-end using only 2D supervision. In addition, we show that the learned dynamic radiance field can be used to synthesize novel unseen expressions based on a global animation code. Our approach achieves state-of-the-art results for synthesizing novel views of dynamic human heads and the upper body.
Masksembles for Uncertainty Estimation
Dec 15, 2020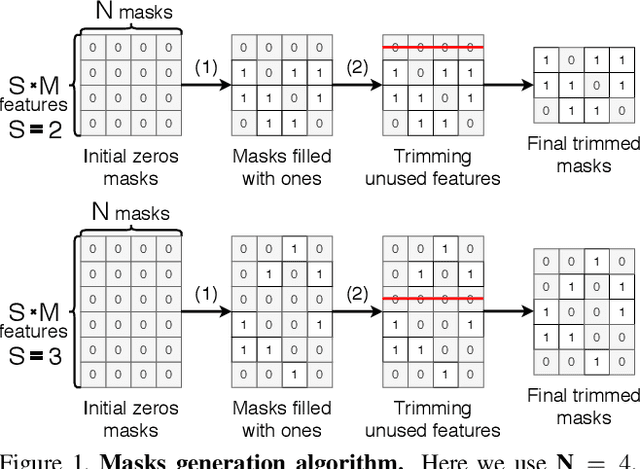
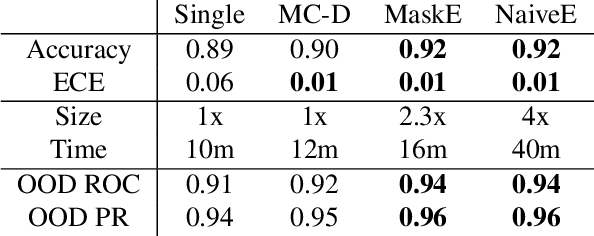
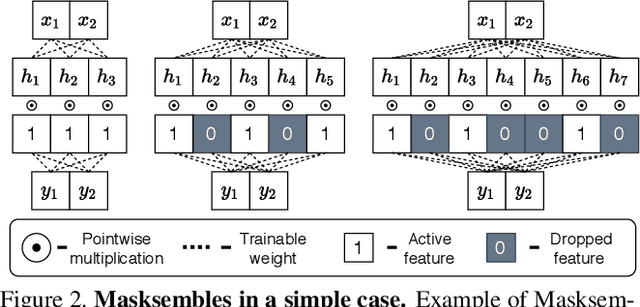
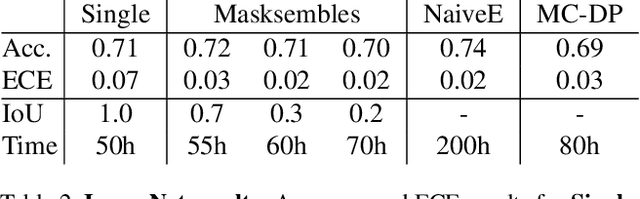
Deep neural networks have amply demonstrated their prowess but estimating the reliability of their predictions remains challenging. Deep Ensembles are widely considered as being one of the best methods for generating uncertainty estimates but are very expensive to train and evaluate. MC-Dropout is another popular alternative, which is less expensive, but also less reliable. Our central intuition is that there is a continuous spectrum of ensemble-like models of which MC-Dropout and Deep Ensembles are extreme examples. The first uses an effectively infinite number of highly correlated models while the second relies on a finite number of independent models. To combine the benefits of both, we introduce Masksembles. Instead of randomly dropping parts of the network as in MC-dropout, Masksemble relies on a fixed number of binary masks, which are parameterized in a way that allows to change correlations between individual models. Namely, by controlling the overlap between the masks and their density one can choose the optimal configuration for the task at hand. This leads to a simple and easy to implement method with performance on par with Ensembles at a fraction of the cost. We experimentally validate Masksembles on two widely used datasets, CIFAR10 and ImageNet.