 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Alternative Surrogate Loss for PGD-based Adversarial Testing
Oct 21, 2019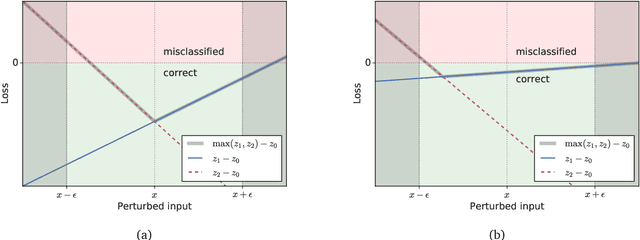

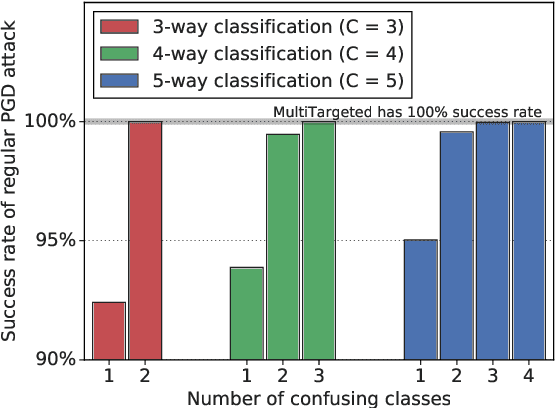

Adversarial testing methods based on Projected Gradient Descent (PGD) are widely used for searching norm-bounded perturbations that cause the inputs of neural networks to be misclassified. This paper takes a deeper look at these methods and explains the effect of different hyperparameters (i.e., optimizer, step size and surrogate loss). We introduce the concept of MultiTargeted testing, which makes clever use of alternative surrogate losses, and explain when and how MultiTargeted is guaranteed to find optimal perturbations. Finally, we demonstrate that MultiTargeted outperforms more sophisticated methods and often requires less iterative steps than other variants of PGD found in the literature. Notably, MultiTargeted ranks first on MadryLab's white-box MNIST and CIFAR-10 leaderboards, reducing the accuracy of their MNIST model to 88.36% (with $\ell_\infty$ perturbations of $\epsilon = 0.3$) and the accuracy of their CIFAR-10 model to 44.03% (at $\epsilon = 8/255$). MultiTargeted also ranks first on the TRADES leaderboard reducing the accuracy of their CIFAR-10 model to 53.07% (with $\ell_\infty$ perturbations of $\epsilon = 0.031$).
Adaptive Temporal-Difference Learning for Policy Evaluation with Per-State Uncertainty Estimates
Jun 19, 2019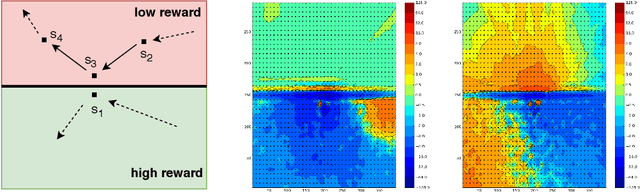
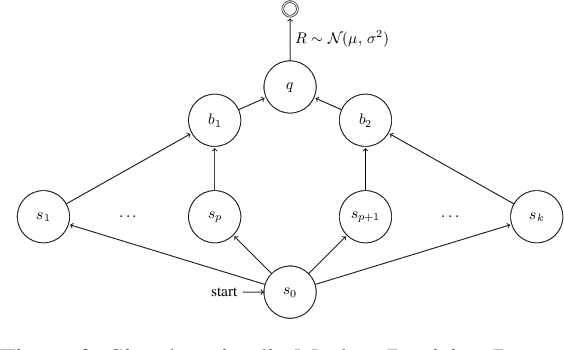
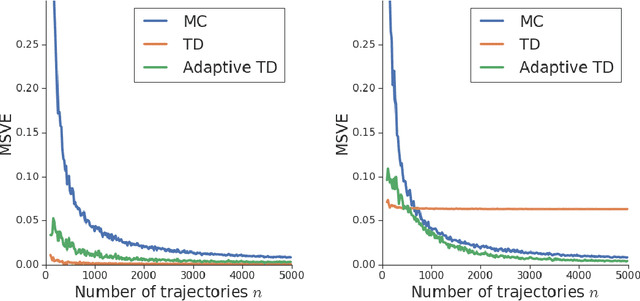
We consider the core reinforcement-learning problem of on-policy value function approximation from a batch of trajectory data, and focus on various issues of Temporal Difference (TD) learning and Monte Carlo (MC) policy evaluation. The two methods are known to achieve complementary bias-variance trade-off properties, with TD tending to achieve lower variance but potentially higher bias. In this paper, we argue that the larger bias of TD can be a result of the amplification of local approximation errors. We address this by proposing an algorithm that adaptively switches between TD and MC in each state, thus mitigating the propagation of errors. Our method is based on learned confidence intervals that detect biases of TD estimates. We demonstrate in a variety of policy evaluation tasks that this simple adaptive algorithm performs competitively with the best approach in hindsight, suggesting that learned confidence intervals are a powerful technique for adapting policy evaluation to use TD or MC returns in a data-driven way.
Robust Reinforcement Learning for Continuous Control with Model Misspecification
Jun 18, 2019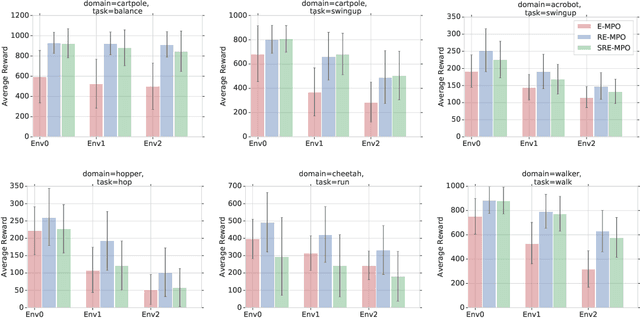

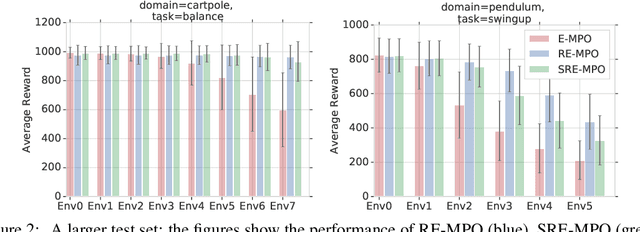
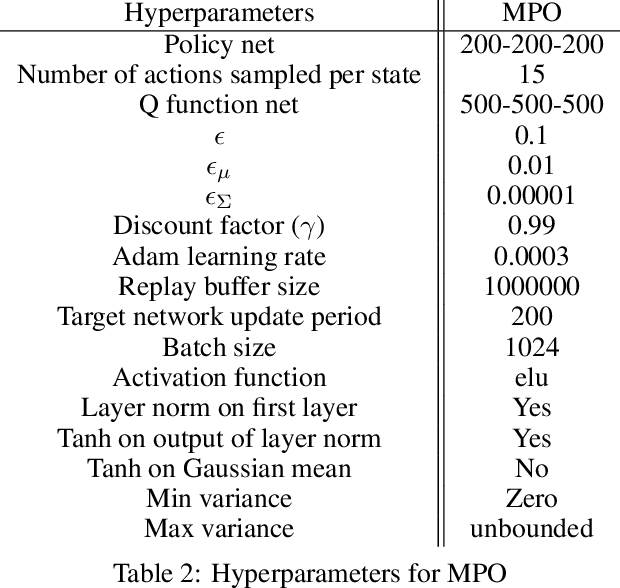
We provide a framework for incorporating robustness -- to perturbations in the transition dynamics which we refer to as model misspecification -- into continuous control Reinforcement Learning (RL) algorithms. We specifically focus on incorporating robustness into a state-of-the-art continuous control RL algorithm called Maximum a-posteriori Policy Optimization (MPO). We achieve this by learning a policy that optimizes for a worst case, entropy-regularized, expected return objective and derive a corresponding robust entropy-regularized Bellman contraction operator. In addition, we introduce a less conservative, soft-robust, entropy-regularized objective with a corresponding Bellman operator. We show that both, robust and soft-robust policies, outperform their non-robust counterparts in nine Mujoco domains with environment perturbations. Finally, we present multiple investigative experiments that provide a deeper insight into the robustness framework; including an adaptation to another continuous control RL algorithm as well as comparing this approach to domain randomization. Performance videos can be found online at https://sites.google.com/view/robust-rl.
A Bayesian Approach to Robust Reinforcement Learning
May 20, 2019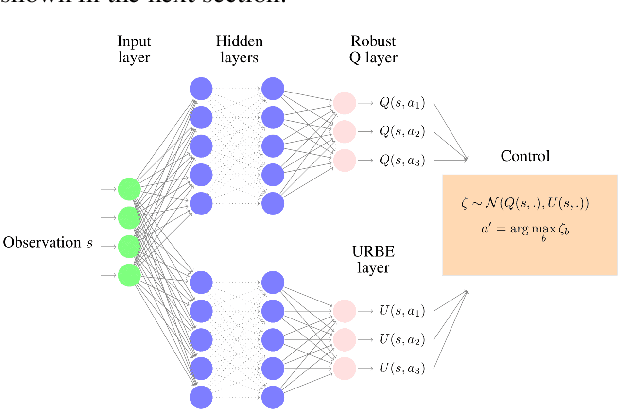

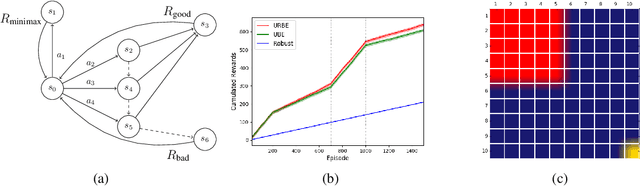
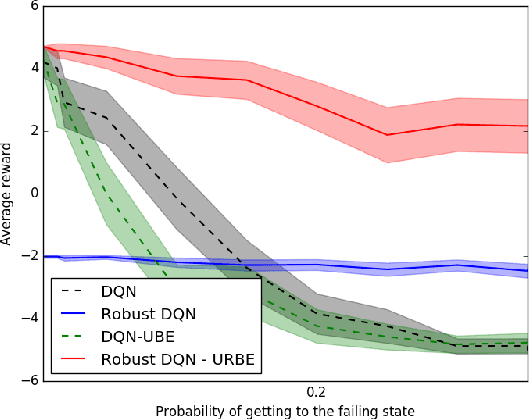
Robust Markov Decision Processes (RMDPs) intend to ensure robustness with respect to changing or adversarial system behavior. In this framework, transitions are modeled as arbitrary elements of a known and properly structured uncertainty set and a robust optimal policy can be derived under the worst-case scenario. In this study, we address the issue of learning in RMDPs using a Bayesian approach. We introduce the Uncertainty Robust Bellman Equation (URBE) which encourages safe exploration for adapting the uncertainty set to new observations while preserving robustness. We propose a URBE-based algorithm, DQN-URBE, that scales this method to higher dimensional domains. Our experiments show that the derived URBE-based strategy leads to a better trade-off between less conservative solutions and robustness in the presence of model misspecification. In addition, we show that the DQN-URBE algorithm can adapt significantly faster to changing dynamics online compared to existing robust techniques with fixed uncertainty sets.
On the Effectiveness of Interval Bound Propagation for Training Verifiably Robust Models
Nov 05, 2018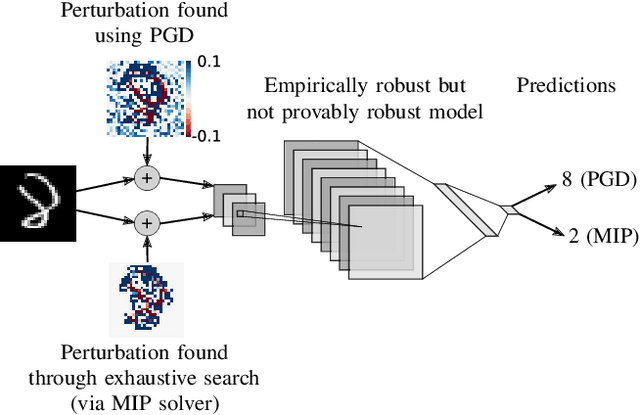

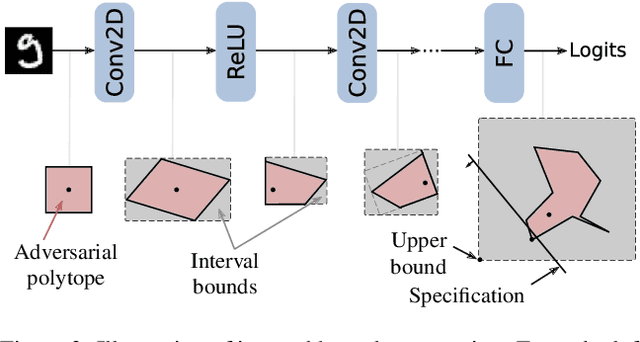

Recent works have shown that it is possible to train models that are verifiably robust to norm-bounded adversarial perturbations. While these recent methods show promise, they remain hard to scale and difficult to tune. This paper investigates how interval bound propagation (IBP) using simple interval arithmetic can be exploited to train verifiably robust neural networks that are surprisingly effective. While IBP itself has been studied in prior work, our contribution is in showing that, with an appropriate loss and careful tuning of hyper-parameters, verified training with IBP leads to a fast and stable learning algorithm. We compare our approach with recent techniques, and train classifiers that improve on the state-of-the-art in single-model adversarial robustness: we reduce the verified error rate from 3.67% to 2.23% on MNIST (with $\ell_\infty$ perturbations of $\epsilon = 0.1$), from 19.32% to 8.05% on MNIST (at $\epsilon = 0.3$), and from 78.22% to 72.91% on CIFAR-10 (at $\epsilon = 8/255$).
A Dual Approach to Scalable Verification of Deep Networks
Aug 03, 2018
This paper addresses the problem of formally verifying desirable properties of neural networks, i.e., obtaining provable guarantees that neural networks satisfy specifications relating their inputs and outputs (robustness to bounded norm adversarial perturbations, for example). Most previous work on this topic was limited in its applicability by the size of the network, network architecture and the complexity of properties to be verified. In contrast, our framework applies to a general class of activation functions and specifications on neural network inputs and outputs. We formulate verification as an optimization problem (seeking to find the largest violation of the specification) and solve a Lagrangian relaxation of the optimization problem to obtain an upper bound on the worst case violation of the specification being verified. Our approach is anytime i.e. it can be stopped at any time and a valid bound on the maximum violation can be obtained. We develop specialized verification algorithms with provable tightness guarantees under special assumptions and demonstrate the practical significance of our general verification approach on a variety of verification tasks.
Temporal Difference Learning with Neural Networks - Study of the Leakage Propagation Problem
Jul 09, 2018
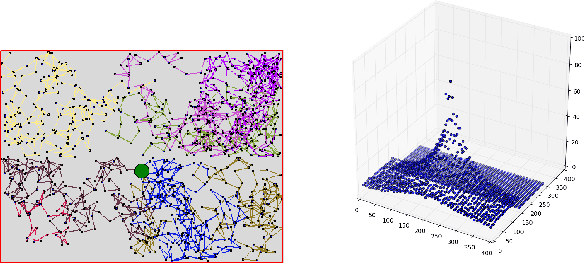
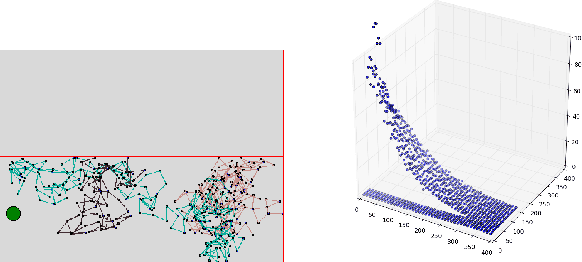
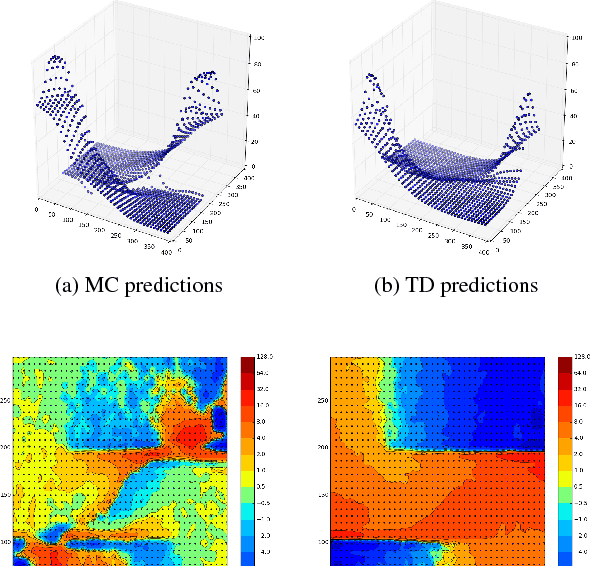
Temporal-Difference learning (TD) [Sutton, 1988] with function approximation can converge to solutions that are worse than those obtained by Monte-Carlo regression, even in the simple case of on-policy evaluation. To increase our understanding of the problem, we investigate the issue of approximation errors in areas of sharp discontinuities of the value function being further propagated by bootstrap updates. We show empirical evidence of this leakage propagation, and show analytically that it must occur, in a simple Markov chain, when function approximation errors are present. For reversible policies, the result can be interpreted as the tension between two terms of the loss function that TD minimises, as recently described by [Ollivier, 2018]. We show that the upper bounds from [Tsitsiklis and Van Roy, 1997] hold, but they do not imply that leakage propagation occurs and under what conditions. Finally, we test whether the problem could be mitigated with a better state representation, and whether it can be learned in an unsupervised manner, without rewards or privileged information.
Deep Reinforcement Learning in Large Discrete Action Spaces
Apr 04, 2016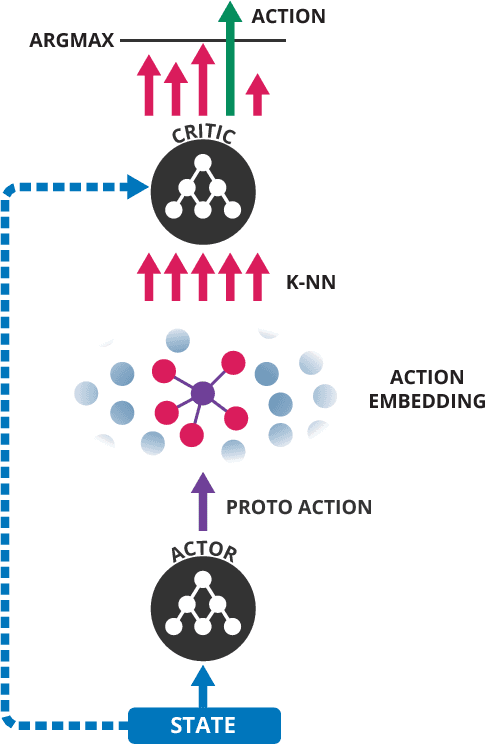

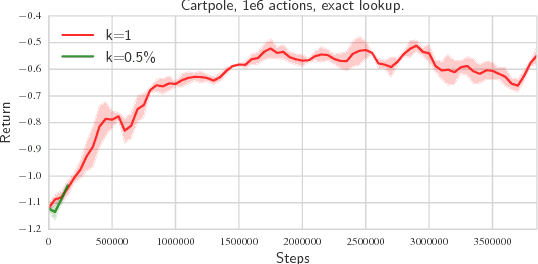
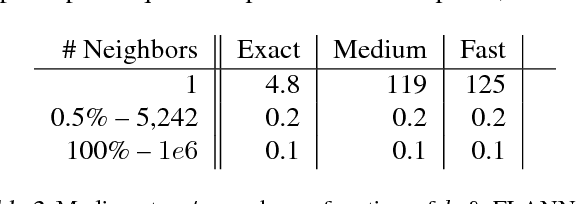
Being able to reason in an environment with a large number of discrete actions is essential to bringing reinforcement learning to a larger class of problems. Recommender systems, industrial plants and language models are only some of the many real-world tasks involving large numbers of discrete actions for which current methods are difficult or even often impossible to apply. An ability to generalize over the set of actions as well as sub-linear complexity relative to the size of the set are both necessary to handle such tasks. Current approaches are not able to provide both of these, which motivates the work in this paper. Our proposed approach leverages prior information about the actions to embed them in a continuous space upon which it can generalize. Additionally, approximate nearest-neighbor methods allow for logarithmic-time lookup complexity relative to the number of actions, which is necessary for time-wise tractable training. This combined approach allows reinforcement learning methods to be applied to large-scale learning problems previously intractable with current methods. We demonstrate our algorithm's abilities on a series of tasks having up to one million actions.
Off-policy evaluation for MDPs with unknown structure
Feb 11, 2015



Off-policy learning in dynamic decision problems is essential for providing strong evidence that a new policy is better than the one in use. But how can we prove superiority without testing the new policy? To answer this question, we introduce the G-SCOPE algorithm that evaluates a new policy based on data generated by the existing policy. Our algorithm is both computationally and sample efficient because it greedily learns to exploit factored structure in the dynamics of the environment. We present a finite sample analysis of our approach and show through experiments that the algorithm scales well on high-dimensional problems with few samples.