 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-Grained Instance-Level Sketch-Based Video Retrieval
Feb 21, 2020
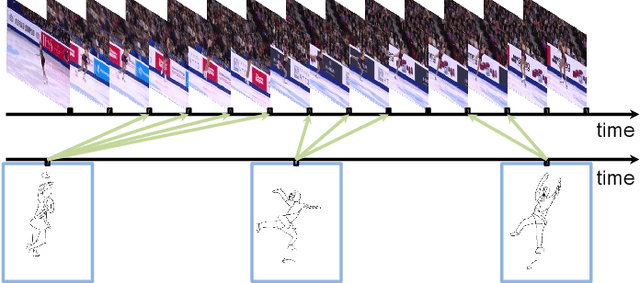

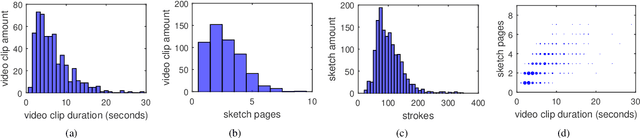
Existing sketch-analysis work studies sketches depicting static objects or scenes. In this work, we propose a novel cross-modal retrieval problem of fine-grained instance-level sketch-based video retrieval (FG-SBVR), where a sketch sequence is used as a query to retrieve a specific target video instance. Compared with sketch-based still image retrieval, and coarse-grained category-level video retrieval, this is more challenging as both visual appearance and motion need to be simultaneously matched at a fine-grained level. We contribute the first FG-SBVR dataset with rich annotations. We then introduce a novel multi-stream multi-modality deep network to perform FG-SBVR under both strong and weakly supervised settings. The key component of the network is a relation module, designed to prevent model over-fitting given scarce training data. We show that this model significantly outperforms a number of existing state-of-the-art models designed for video analysis.
Distance-Based Regularisation of Deep Networks for Fine-Tuning
Feb 19, 2020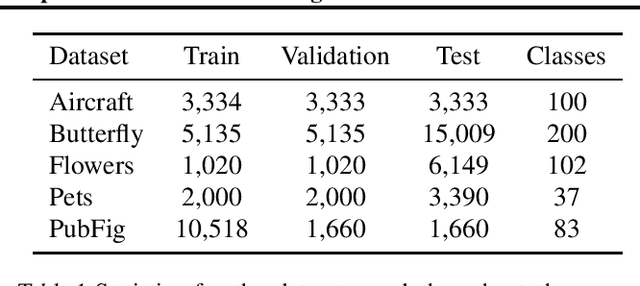
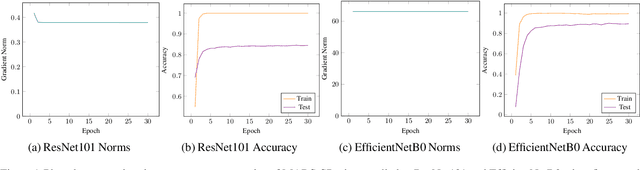
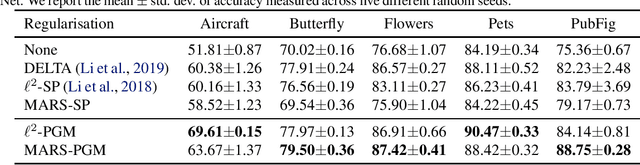
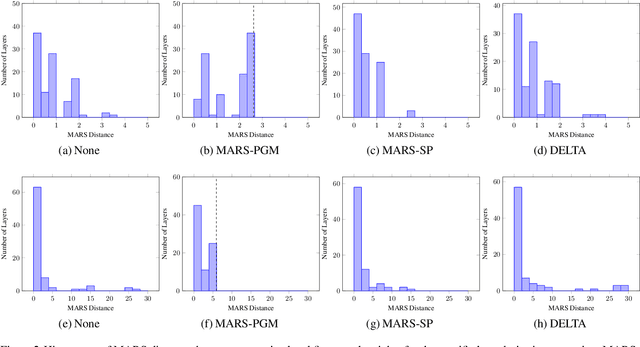
We investigate approaches to regularisation during fine-tuning of deep neural networks. First we provide a neural network generalisation bound based on Rademacher complexity that uses the distance the weights have moved from their initial values. This bound has no direct dependence on the number of weights and compares favourably to other bounds when applied to convolutional networks. Our bound is highly relevant for fine-tuning, because providing a network with a good initialisation based on transfer learning means that learning can modify the weights less, and hence achieve tighter generalisation. Inspired by this, we develop a simple yet effective fine-tuning algorithm that constrains the hypothesis class to a small sphere centred on the initial pre-trained weights, thus obtaining provably better generalisation performance than conventional transfer learning. Empirical evaluation shows that our algorithm works well, corroborating our theoretical results. It outperforms both state of the art fine-tuning competitors, and penalty-based alternatives that we show do not directly constrain the radius of the search space.
Deep clustering with concrete k-means
Oct 17, 2019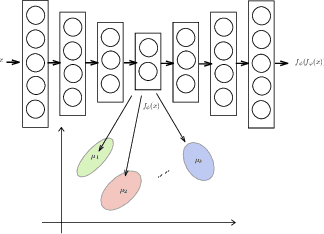
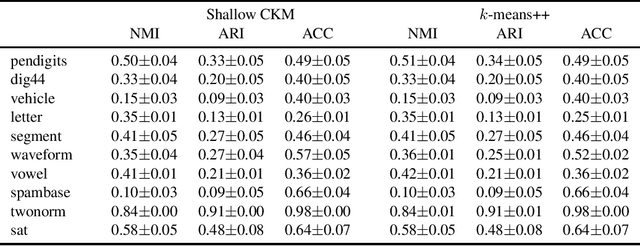
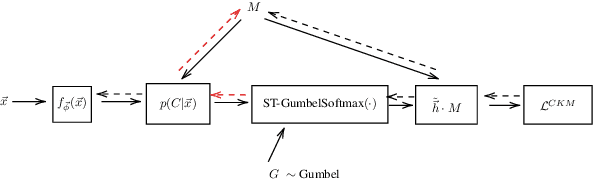

We address the problem of simultaneously learning a k-means clustering and deep feature representation from unlabelled data, which is of interest due to the potential of deep k-means to outperform traditional two-step feature extraction and shallow-clustering strategies. We achieve this by developing a gradient-estimator for the non-differentiable k-means objective via the Gumbel-Softmax reparameterisation trick. In contrast to previous attempts at deep clustering, our concrete k-means model can be optimised with respect to the canonical k-means objective and is easily trained end-to-end without resorting to alternating optimisation. We demonstrate the efficacy of our method on standard clustering benchmarks.
On Understanding Knowledge Graph Representation
Sep 25, 2019

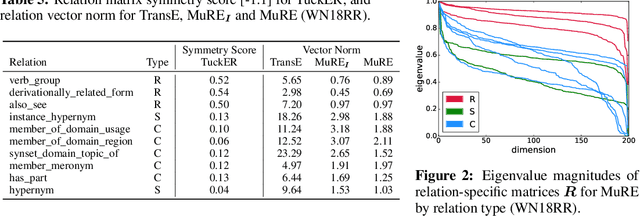
Many methods have been developed to represent knowledge graph data, which implicitly exploit low-rank latent structure in the data to encode known information and enable unknown facts to be inferred. To predict whether a relationship holds between entities, their embeddings are typically compared in the latent space following a relation-specific mapping. Whilst link prediction has steadily improved, the latent structure, and hence why such models capture semantic information, remains unexplained. We build on recent theoretical interpretation of word embeddings as a basis to consider an explicit structure for representations of relations between entities. For identifiable relation types, we are able to predict properties and justify the relative performance of leading knowledge graph representation methods, including their often overlooked ability to make independent predictions.
Goal-Driven Sequential Data Abstraction
Aug 08, 2019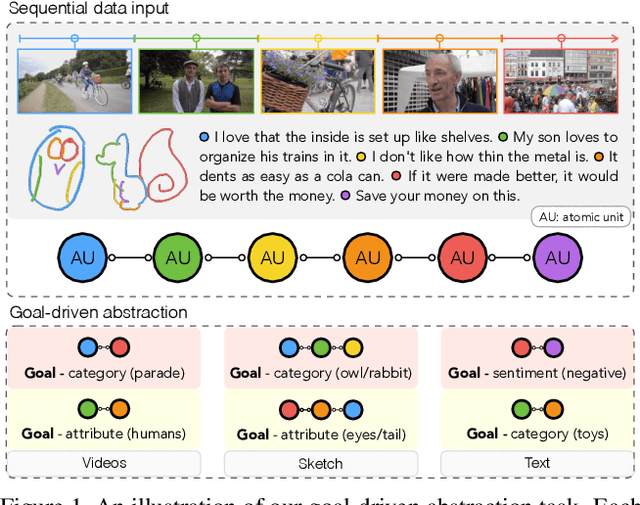
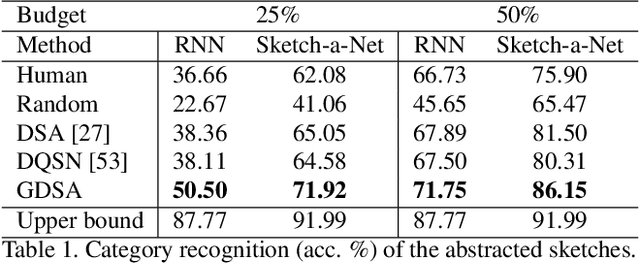
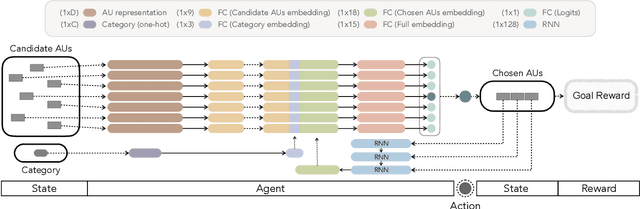
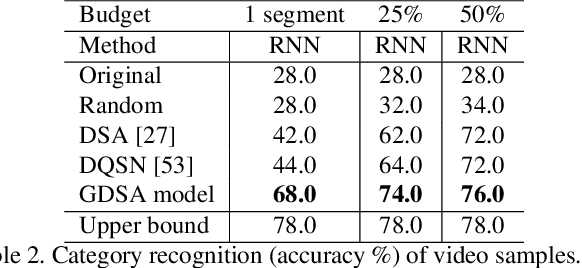
Automatic data abstraction is an important capability for both benchmarking machine intelligence and supporting summarization applications. In the former one asks whether a machine can `understand' enough about the meaning of input data to produce a meaningful but more compact abstraction. In the latter this capability is exploited for saving space or human time by summarizing the essence of input data. In this paper we study a general reinforcement learning based framework for learning to abstract sequential data in a goal-driven way. The ability to define different abstraction goals uniquely allows different aspects of the input data to be preserved according to the ultimate purpose of the abstraction. Our reinforcement learning objective does not require human-defined examples of ideal abstraction. Importantly our model processes the input sequence holistically without being constrained by the original input order. Our framework is also domain agnostic -- we demonstrate applications to sketch, video and text data and achieve promising results in all domains.
Measuring the Transferability of Adversarial Examples
Jul 14, 2019
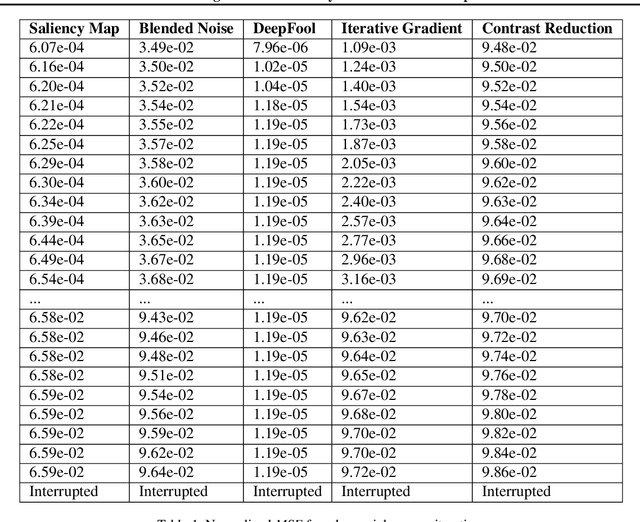
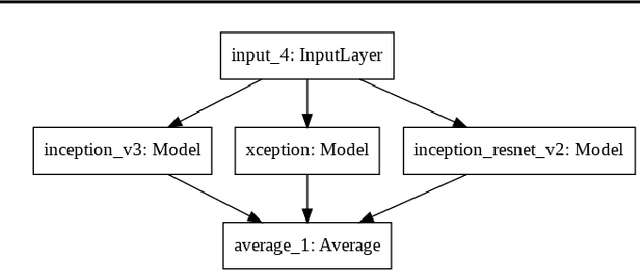
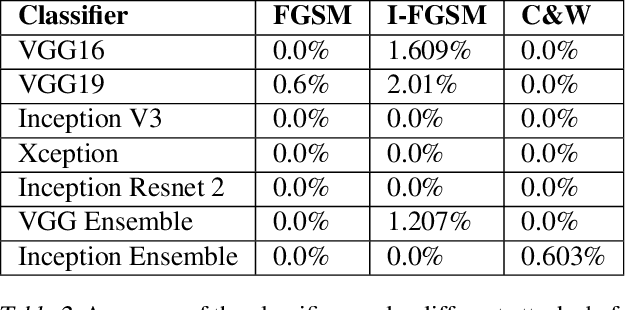
Adversarial examples are of wide concern due to their impact on the reliability of contemporary machine learning systems. Effective adversarial examples are mostly found via white-box attacks. However, in some cases they can be transferred across models, thus enabling them to attack black-box models. In this work we evaluate the transferability of three adversarial attacks - the Fast Gradient Sign Method, the Basic Iterative Method, and the Carlini & Wagner method, across two classes of models - the VGG class(using VGG16, VGG19 and an ensemble of VGG16 and VGG19), and the Inception class(Inception V3, Xception, Inception Resnet V2, and an ensemble of the three). We also outline the problems with the assessment of transferability in the current body of research and attempt to amend them by picking specific "strong" parameters for the attacks, and by using a L-Infinity clipping technique and the SSIM metric for the final evaluation of the attack transferability.
Frustratingly Easy Person Re-Identification: Generalizing Person Re-ID in Practice
May 09, 2019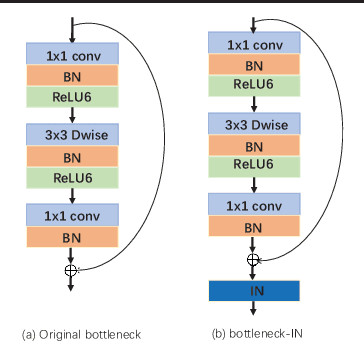
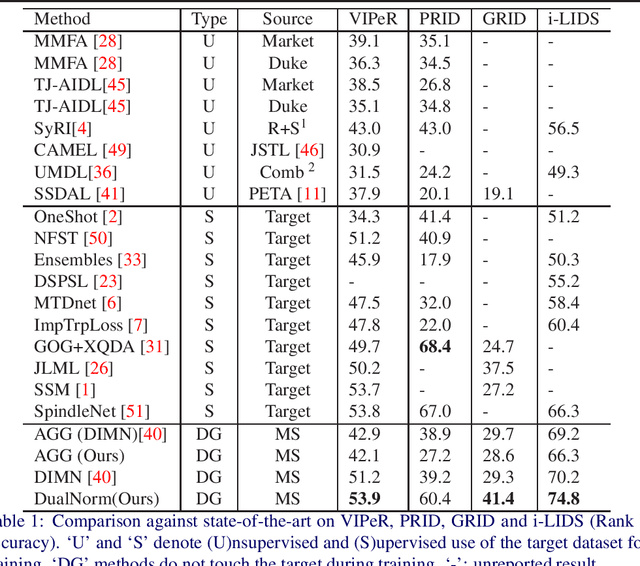
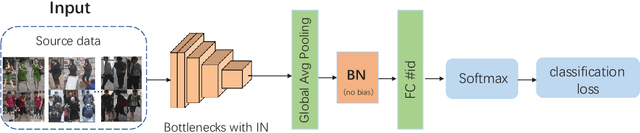
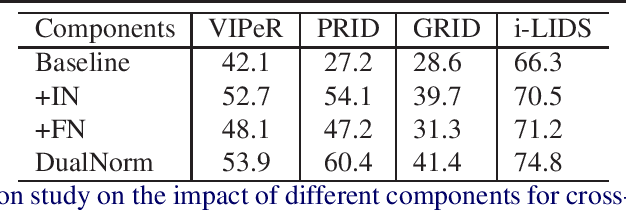
Contemporary person re-identification (Re-ID) methods usually require access to data from the deployment camera network during training in order to perform well. This is because contemporary Re-ID models trained on one dataset do not generalise to other camera networks due to the domain-shift between datasets. This requirement is often the bottleneck for deploying Re-ID systems in practical security or commercial applications as it may be impossible to collect this data in advance or prohibitively costly to annotate it. This paper alleviates this issue by proposing a simple baseline for domain generalizable~(DG) person re-identification. That is, to learn a Re-ID model from a set of source domains that is suitable for application to unseen datasets out-of-the-box, without any model updating. Specifically, we observe that the domain discrepancy in Re-ID is due to style and content variance across datasets and demonstrate appropriate Instance and Feature Normalization alleviates much of the resulting domain-shift in Deep Re-ID models. Instance Normalization~(IN) in early layers filters out style statistic variations and Feature Normalization~(FN) in deep layers is able to further eliminate disparity in content statistics. Compared to contemporary alternatives, this approach is extremely simple to implement, while being faster to train and test, thus making it an extremely valuable baseline for implementing Re-ID in practice. With a few lines of code, it increases the rank 1 Re-ID accuracy by 11.7\%, 28.9\%, 10.1\% and 6.3\% on the VIPeR, PRID, GRID, and i-LIDS benchmarks respectively. Source code will be made available.
Investigating Generalisation in Continuous Deep Reinforcement Learning
Feb 20, 2019
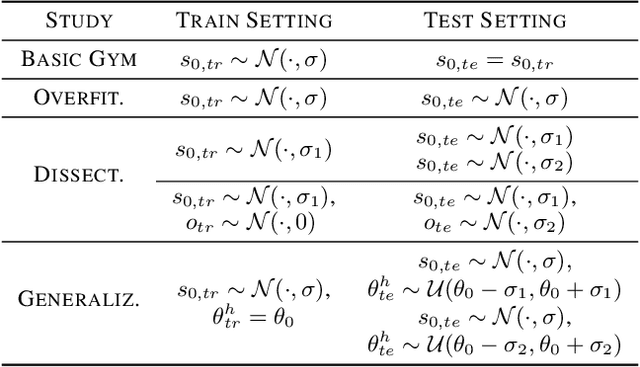

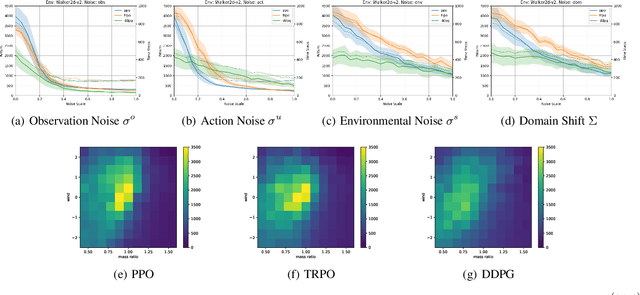
Deep Reinforcement Learning has shown great success in a variety of control tasks. However, it is unclear how close we are to the vision of putting Deep RL into practice to solve real world problems. In particular, common practice in the field is to train policies on largely deterministic simulators and to evaluate algorithms through training performance alone, without a train/test distinction to ensure models generalise and are not overfitted. Moreover, it is not standard practice to check for generalisation under domain shift, although robustness to such system change between training and testing would be necessary for real-world Deep RL control, for example, in robotics. In this paper we study these issues by first characterising the sources of uncertainty that provide generalisation challenges in Deep RL. We then provide a new benchmark and thorough empirical evaluation of generalisation challenges for state of the art Deep RL methods. In particular, we show that, if generalisation is the goal, then common practice of evaluating algorithms based on their training performance leads to the wrong conclusions about algorithm choice. Finally, we evaluate several techniques for improving generalisation and draw conclusions about the most robust techniques to date.
Episodic Training for Domain Generalization
Jan 31, 2019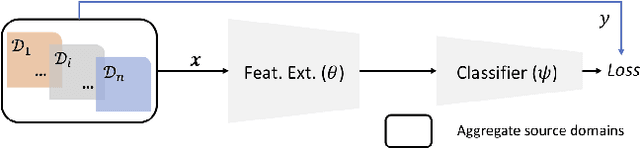
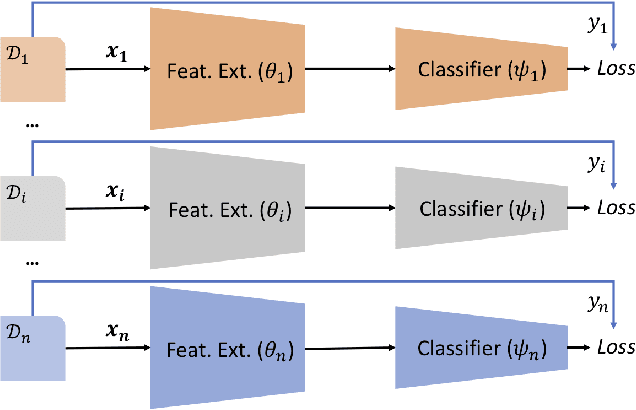
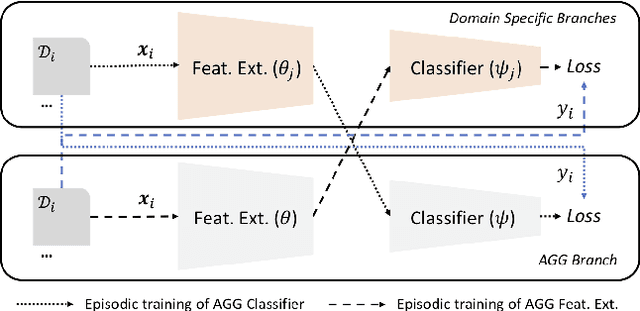
Domain generalization (DG) is the challenging and topical problem of learning models that generalize to novel testing domain with different statistics than a set of known training domains. The simple approach of aggregating data from all source domains and training a single deep neural network end-to-end on all the data provides a surprisingly strong baseline that surpasses many prior published methods. In this paper we build on this strong baseline by designing an episodic training procedure that trains a single deep network in a way that exposes it to the domain shift that characterises a novel domain at runtime. Specifically, we decompose a deep network into feature extractor and classifier components, and then train each component by simulating it interacting with a partner who is badly tuned for the current domain. This makes both components more robust, ultimately leading to our networks producing state-of-the-art performance on three DG benchmarks. As a demonstration, we consider the pervasive workflow of using an ImageNet trained CNN as a fixed feature extractor for downstream recognition tasks. Using the Visual Decathlon benchmark, we demonstrate that our episodic-DG training improves the performance of such a general purpose feature extractor by explicitly training it for robustness to novel problems. This provides the largest-scale demonstration of heterogeneous DG to date.
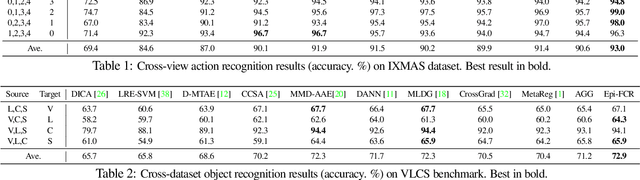
Feature-Critic Networks for Heterogeneous Domain Generalization
Jan 31, 2019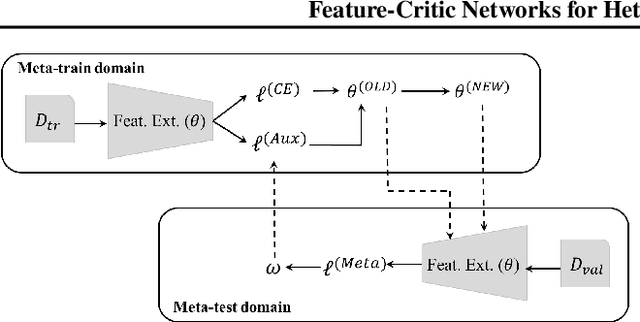


The well known domain shift issue causes model performance to degrade when deployed to a new target domain with different statistics to training. Domain adaptation techniques alleviate this, but need some instances from the target domain to drive adaptation. Domain generalization is the recently topical problem of learning a model that generalizes to unseen domains out of the box, without accessing any target data. Various domain generalization approaches aim to train a domain-invariant feature extractor, typically by adding some manually designed losses. In this work, we propose a learning to learn approach, where the auxiliary loss that helps generalization is itself learned. This approach is conceptually simple and flexible, and leads to considerable improvement in robustness to domain shift. Beyond conventional domain generalization, we consider a more challenging setting of heterogeneous domain generalization, where the unseen domains do not share label space with the seen ones, and the goal is to train a feature which is useful off-the-shelf for novel data and novel categories. Experimental evaluation demonstrates that our method outperforms state-of-the-art solutions in both settings.