 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain Generalisation via Domain Adaptation: An Adversarial Fourier Amplitude Approach
Feb 23, 2023



We tackle the domain generalisation (DG) problem by posing it as a domain adaptation (DA) task where we adversarially synthesise the worst-case target domain and adapt a model to that worst-case domain, thereby improving the model's robustness. To synthesise data that is challenging yet semantics-preserving, we generate Fourier amplitude images and combine them with source domain phase images, exploiting the widely believed conjecture from signal processing that amplitude spectra mainly determines image style, while phase data mainly captures image semantics. To synthesise a worst-case domain for adaptation, we train the classifier and the amplitude generator adversarially. Specifically, we exploit the maximum classifier discrepancy (MCD) principle from DA that relates the target domain performance to the discrepancy of classifiers in the model hypothesis space. By Bayesian hypothesis modeling, we express the model hypothesis space effectively as a posterior distribution over classifiers given the source domains, making adversarial MCD minimisation feasible. On the DomainBed benchmark including the large-scale DomainNet dataset, the proposed approach yields significantly improved domain generalisation performance over the state-of-the-art.
Meta-Learned Kernel For Blind Super-Resolution Kernel Estimation
Dec 15, 2022



Recent image degradation estimation methods have enabled single-image super-resolution (SR) approaches to better upsample real-world images. Among these methods, explicit kernel estimation approaches have demonstrated unprecedented performance at handling unknown degradations. Nonetheless, a number of limitations constrain their efficacy when used by downstream SR models. Specifically, this family of methods yields i) excessive inference time due to long per-image adaptation times and ii) inferior image fidelity due to kernel mismatch. In this work, we introduce a learning-to-learn approach that meta-learns from the information contained in a distribution of images, thereby enabling significantly faster adaptation to new images with substantially improved performance in both kernel estimation and image fidelity. Specifically, we meta-train a kernel-generating GAN, named MetaKernelGAN, on a range of tasks, such that when a new image is presented, the generator starts from an informed kernel estimate and the discriminator starts with a strong capability to distinguish between patch distributions. Compared with state-of-the-art methods, our experiments show that MetaKernelGAN better estimates the magnitude and covariance of the kernel, leading to state-of-the-art blind SR results within a similar computational regime when combined with a non-blind SR model. Through supervised learning of an unsupervised learner, our method maintains the generalizability of the unsupervised learner, improves the optimization stability of kernel estimation, and hence image adaptation, and leads to a faster inference with a speedup between 14.24 to 102.1x over existing methods.
Federated Learning for Inference at Anytime and Anywhere
Dec 08, 2022



Federated learning has been predominantly concerned with collaborative training of deep networks from scratch, and especially the many challenges that arise, such as communication cost, robustness to heterogeneous data, and support for diverse device capabilities. However, there is no unified framework that addresses all these problems together. This paper studies the challenges and opportunities of exploiting pre-trained Transformer models in FL. In particular, we propose to efficiently adapt such pre-trained models by injecting a novel attention-based adapter module at each transformer block that both modulates the forward pass and makes an early prediction. Training only the lightweight adapter by FL leads to fast and communication-efficient learning even in the presence of heterogeneous data and devices. Extensive experiments on standard FL benchmarks, including CIFAR-100, FEMNIST and SpeechCommandsv2 demonstrate that this simple framework provides fast and accurate FL while supporting heterogenous device capabilities, efficient personalization, and scalable-cost anytime inference.
MEDFAIR: Benchmarking Fairness for Medical Imaging
Oct 04, 2022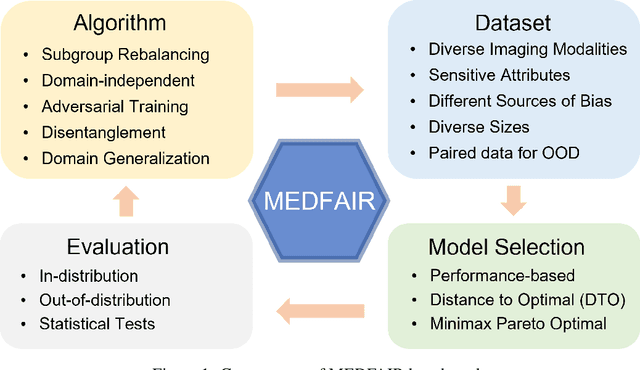
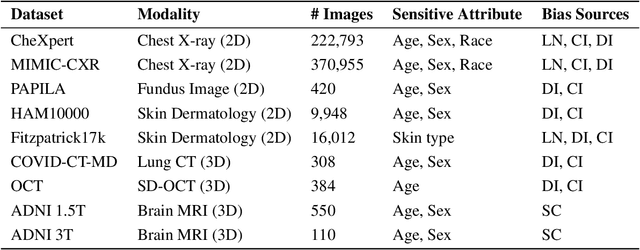
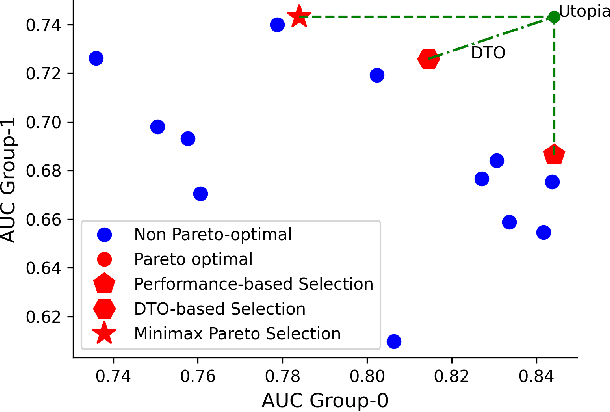
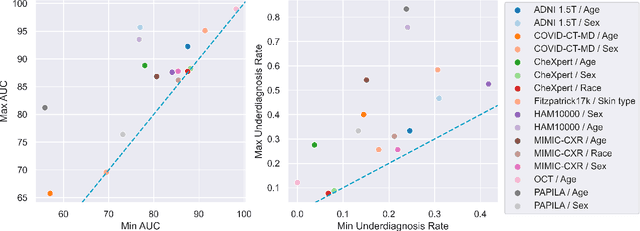
A multitude of work has shown that machine learning-based medical diagnosis systems can be biased against certain subgroups of people. This has motivated a growing number of bias mitigation algorithms that aim to address fairness issues in machine learning. However, it is difficult to compare their effectiveness in medical imaging for two reasons. First, there is little consensus on the criteria to assess fairness. Second, existing bias mitigation algorithms are developed under different settings, e.g., datasets, model selection strategies, backbones, and fairness metrics, making a direct comparison and evaluation based on existing results impossible. In this work, we introduce MEDFAIR, a framework to benchmark the fairness of machine learning models for medical imaging. MEDFAIR covers eleven algorithms from various categories, nine datasets from different imaging modalities, and three model selection criteria. Through extensive experiments, we find that the under-studied issue of model selection criterion can have a significant impact on fairness outcomes; while in contrast, state-of-the-art bias mitigation algorithms do not significantly improve fairness outcomes over empirical risk minimization (ERM) in both in-distribution and out-of-distribution settings. We evaluate fairness from various perspectives and make recommendations for different medical application scenarios that require different ethical principles. Our framework provides a reproducible and easy-to-use entry point for the development and evaluation of future bias mitigation algorithms in deep learning. Code is available at https://github.com/ys-zong/MEDFAIR.
Attacking Adversarial Defences by Smoothing the Loss Landscape
Aug 05, 2022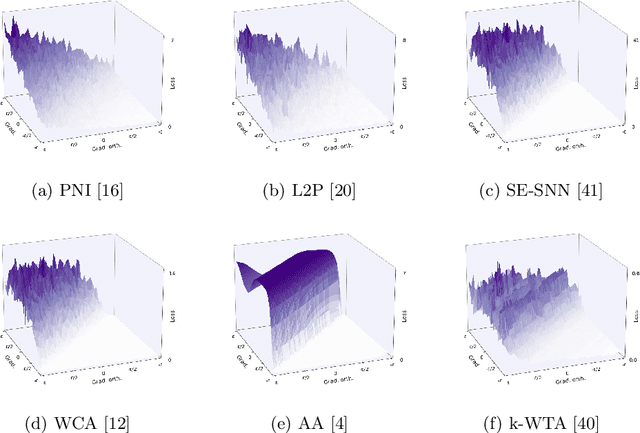
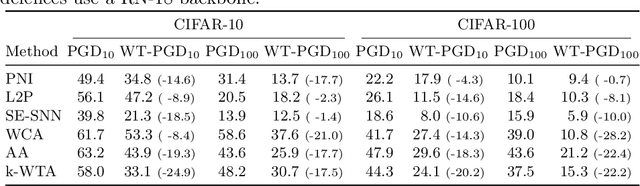
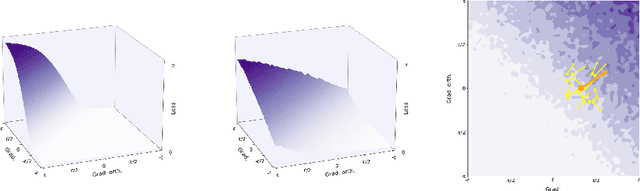
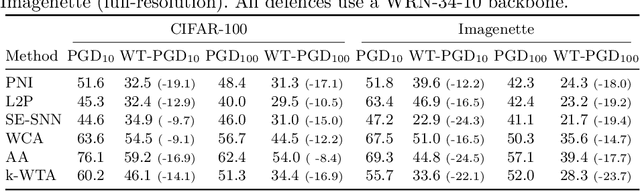
This paper investigates a family of methods for defending against adversarial attacks that owe part of their success to creating a noisy, discontinuous, or otherwise rugged loss landscape that adversaries find difficult to navigate. A common, but not universal, way to achieve this effect is via the use of stochastic neural networks. We show that this is a form of gradient obfuscation, and propose a general extension to gradient-based adversaries based on the Weierstrass transform, which smooths the surface of the loss function and provides more reliable gradient estimates. We further show that the same principle can strengthen gradient-free adversaries. We demonstrate the efficacy of our loss-smoothing method against both stochastic and non-stochastic adversarial defences that exhibit robustness due to this type of obfuscation. Furthermore, we provide analysis of how it interacts with Expectation over Transformation; a popular gradient-sampling method currently used to attack stochastic defences.
HyperInvariances: Amortizing Invariance Learning
Jul 17, 2022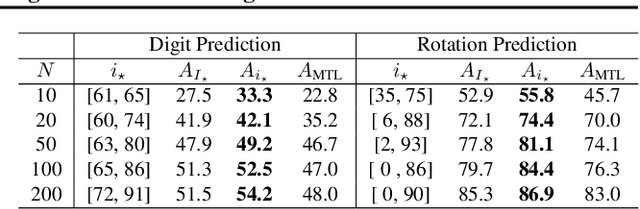
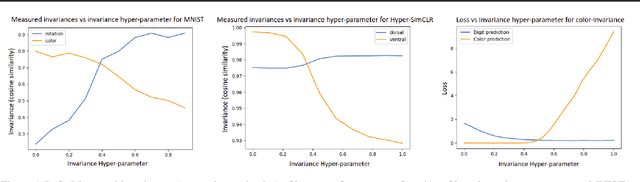

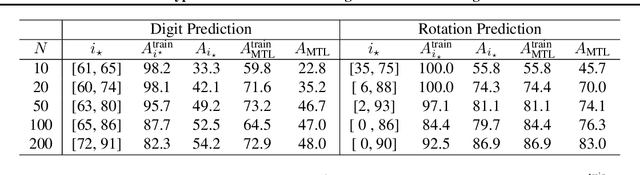
Providing invariances in a given learning task conveys a key inductive bias that can lead to sample-efficient learning and good generalisation, if correctly specified. However, the ideal invariances for many problems of interest are often not known, which has led both to a body of engineering lore as well as attempts to provide frameworks for invariance learning. However, invariance learning is expensive and data intensive for popular neural architectures. We introduce the notion of amortizing invariance learning. In an up-front learning phase, we learn a low-dimensional manifold of feature extractors spanning invariance to different transformations using a hyper-network. Then, for any problem of interest, both model and invariance learning are rapid and efficient by fitting a low-dimensional invariance descriptor an output head. Empirically, this framework can identify appropriate invariances in different downstream tasks and lead to comparable or better test performance than conventional approaches. Our HyperInvariance framework is also theoretically appealing as it enables generalisation-bounds that provide an interesting new operating point in the trade-off between model fit and complexity.
Feed-Forward Source-Free Latent Domain Adaptation via Cross-Attention
Jul 15, 2022
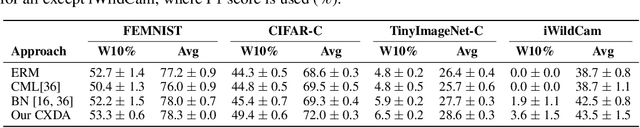
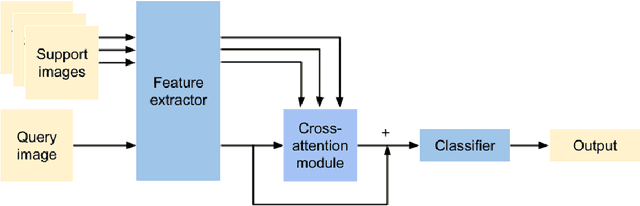

We study the highly practical but comparatively under-studied problem of latent-domain adaptation, where a source model should be adapted to a target dataset that contains a mixture of unlabelled domain-relevant and domain-irrelevant examples. Furthermore, motivated by the requirements for data privacy and the need for embedded and resource-constrained devices of all kinds to adapt to local data distributions, we focus on the setting of feed-forward source-free domain adaptation, where adaptation should not require access to the source dataset, and also be back propagation-free. Our solution is to meta-learn a network capable of embedding the mixed-relevance target dataset and dynamically adapting inference for target examples using cross-attention. The resulting framework leads to consistent improvement on strong ERM baselines. We also show that our framework sometimes even improves on the upper bound of domain-supervised adaptation, where only domain-relevant instances are provided for adaptation. This suggests that human annotated domain labels may not always be optimal, and raises the possibility of doing better through automated instance selection.
MetaAudio: A Few-Shot Audio Classification Benchmark
Apr 10, 2022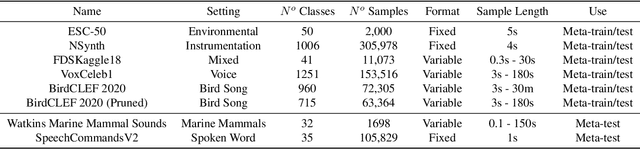
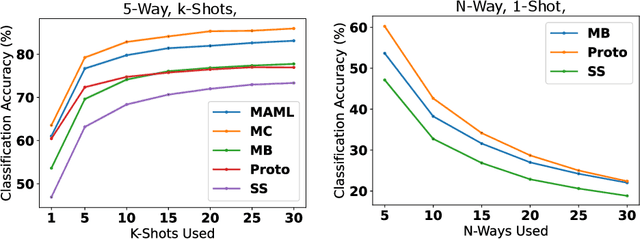
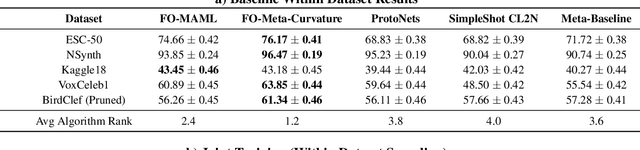
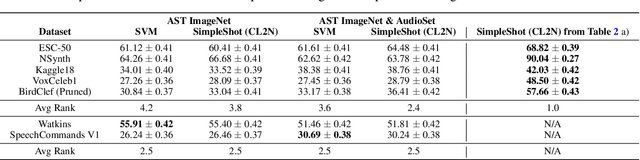
Currently available benchmarks for few-shot learning (machine learning with few training examples) are limited in the domains they cover, primarily focusing on image classification. This work aims to alleviate this reliance on image-based benchmarks by offering the first comprehensive, public and fully reproducible audio based alternative, covering a variety of sound domains and experimental settings. We compare the few-shot classification performance of a variety of techniques on seven audio datasets (spanning environmental sounds to human-speech). Extending this, we carry out in-depth analyses of joint training (where all datasets are used during training) and cross-dataset adaptation protocols, establishing the possibility of a generalised audio few-shot classification algorithm. Our experimentation shows gradient-based meta-learning methods such as MAML and Meta-Curvature consistently outperform both metric and baseline methods. We also demonstrate that the joint training routine helps overall generalisation for the environmental sound databases included, as well as being a somewhat-effective method of tackling the cross-dataset/domain setting.
Finding lost DG: Explaining domain generalization via model complexity
Feb 01, 2022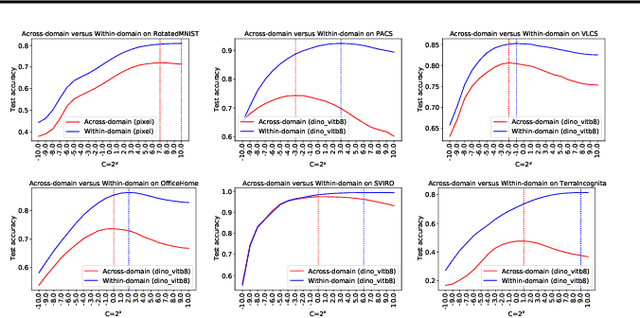
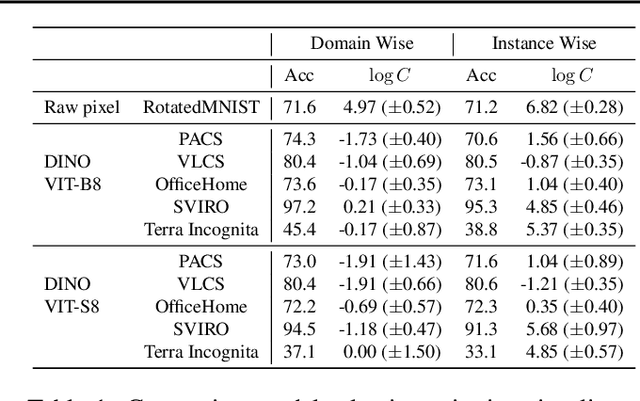
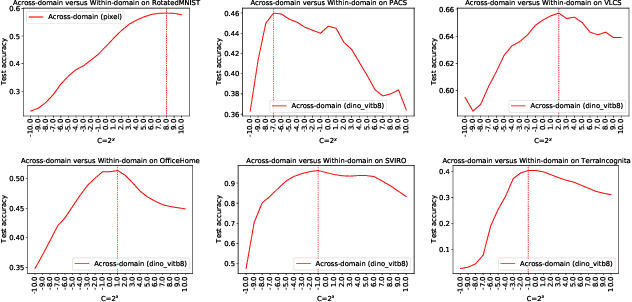
The domain generalization (DG) problem setting challenges a model trained on multiple known data distributions to generalise well on unseen data distributions. Due to its practical importance, a large number of methods have been proposed to address this challenge. However much of the work in general purpose DG is heuristically motivated, as the DG problem is hard to model formally; and recent evaluations have cast doubt on existing methods' practical efficacy -- in particular compared to a well tuned empirical risk minimisation baseline. We present a novel learning-theoretic generalisation bound for DG that bounds unseen domain generalisation performance in terms of the model's Rademacher complexity. Based on this, we conjecture that existing methods' efficacy or lack thereof is largely determined by an empirical risk vs predictor complexity trade-off, and demonstrate that their performance variability can be explained in these terms. Algorithmically, this analysis suggests that domain generalisation should be achieved by simply performing regularised ERM with a leave-one-domain-out cross-validation objective. Empirical results on the DomainBed benchmark corroborate this.
Gaussian Process Meta Few-shot Classifier Learning via Linear Discriminant Laplace Approximation
Nov 09, 2021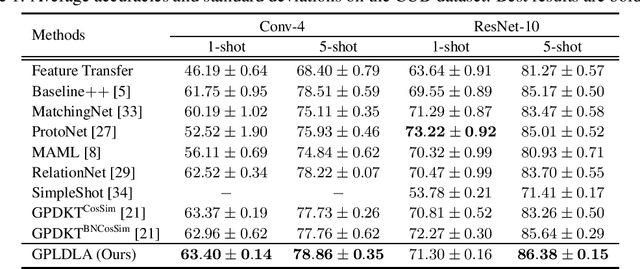
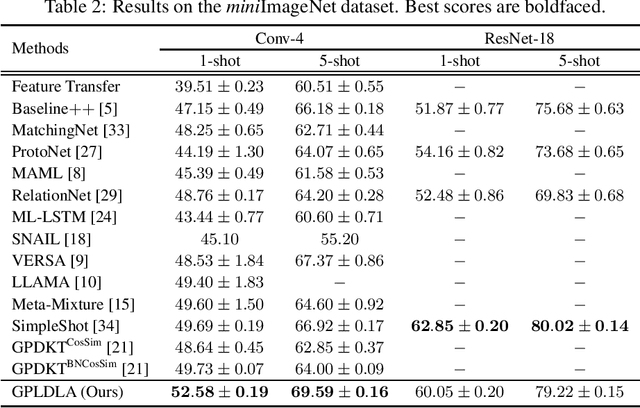
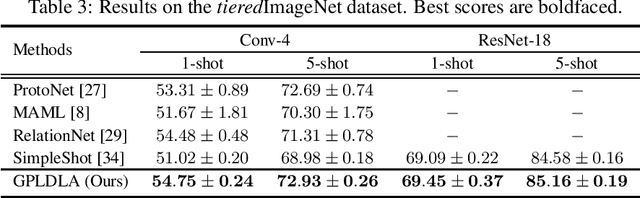
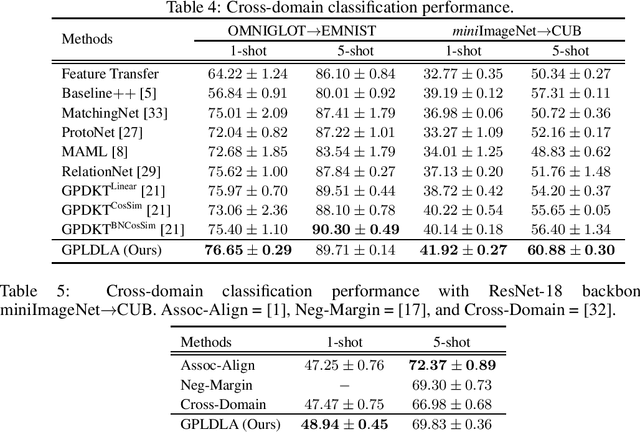
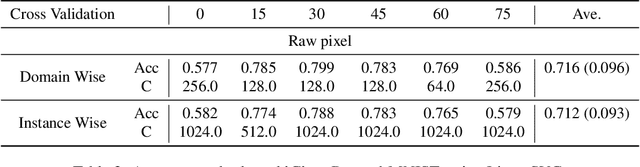
The meta learning few-shot classification is an emerging problem in machine learning that received enormous attention recently, where the goal is to learn a model that can quickly adapt to a new task with only a few labeled data. We consider the Bayesian Gaussian process (GP) approach, in which we meta-learn the GP prior, and the adaptation to a new task is carried out by the GP predictive model from the posterior inference. We adopt the Laplace posterior approximation, but to circumvent the iterative gradient steps for finding the MAP solution, we introduce a novel linear discriminant analysis (LDA) plugin as a surrogate for the MAP solution. In essence, the MAP solution is approximated by the LDA estimate, but to take the GP prior into account, we adopt the prior-norm adjustment to estimate LDA's shared variance parameters, which ensures that the adjusted estimate is consistent with the GP prior. This enables closed-form differentiable GP posteriors and predictive distributions, thus allowing fast meta training. We demonstrate considerable improvement over the previous approaches.