 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Exploration of Left-Corner Transformations
Nov 27, 2023



The left-corner transformation (Rosenkrantz and Lewis, 1970) is used to remove left recursion from context-free grammars, which is an important step towards making the grammar parsable top-down with simple techniques. This paper generalizes prior left-corner transformations to support semiring-weighted production rules and to provide finer-grained control over which left corners may be moved. Our generalized left-corner transformation (GLCT) arose from unifying the left-corner transformation and speculation transformation (Eisner and Blatz, 2007), originally for logic programming. Our new transformation and speculation define equivalent weighted languages. Yet, their derivation trees are structurally different in an important way: GLCT replaces left recursion with right recursion, and speculation does not. We also provide several technical results regarding the formal relationships between the outputs of GLCT, speculation, and the original grammar. Lastly, we empirically investigate the efficiency of GLCT for left-recursion elimination from grammars of nine languages.
Efficient Algorithms for Recognizing Weighted Tree-Adjoining Languages
Oct 23, 2023



The class of tree-adjoining languages can be characterized by various two-level formalisms, consisting of a context-free grammar (CFG) or pushdown automaton (PDA) controlling another CFG or PDA. These four formalisms are equivalent to tree-adjoining grammars (TAG), linear indexed grammars (LIG), pushdown-adjoining automata (PAA), and embedded pushdown automata (EPDA). We define semiring-weighted versions of the above two-level formalisms, and we design new algorithms for computing their stringsums (the weight of all derivations of a string) and allsums (the weight of all derivations). From these, we also immediately obtain stringsum and allsum algorithms for TAG, LIG, PAA, and EPDA. For LIG, our algorithm is more time-efficient by a factor of $\mathcal{O}(n|\mathcal{N}|)$ (where $n$ is the string length and $|\mathcal{N}|$ is the size of the nonterminal set) and more space-efficient by a factor of $\mathcal{O}(|\Gamma|)$ (where $|\Gamma|$ is the size of the stack alphabet) than the algorithm of Vijay-Shanker and Weir (1989). For EPDA, our algorithm is both more space-efficient and time-efficient than the algorithm of Alonso et al. (2001) by factors of $\mathcal{O}(|\Gamma|^2)$ and $\mathcal{O}(|\Gamma|^3)$, respectively. Finally, we give the first PAA stringsum and allsum algorithms.
Efficient Semiring-Weighted Earley Parsing
Jul 06, 2023



This paper provides a reference description, in the form of a deduction system, of Earley's (1970) context-free parsing algorithm with various speed-ups. Our presentation includes a known worst-case runtime improvement from Earley's $O (N^3|G||R|)$, which is unworkable for the large grammars that arise in natural language processing, to $O (N^3|G|)$, which matches the runtime of CKY on a binarized version of the grammar $G$. Here $N$ is the length of the sentence, $|R|$ is the number of productions in $G$, and $|G|$ is the total length of those productions. We also provide a version that achieves runtime of $O (N^3|M|)$ with $|M| \leq |G|$ when the grammar is represented compactly as a single finite-state automaton $M$ (this is partly novel). We carefully treat the generalization to semiring-weighted deduction, preprocessing the grammar like Stolcke (1995) to eliminate deduction cycles, and further generalize Stolcke's method to compute the weights of sentence prefixes. We also provide implementation details for efficient execution, ensuring that on a preprocessed grammar, the semiring-weighted versions of our methods have the same asymptotic runtime and space requirements as the unweighted methods, including sub-cubic runtime on some grammars.
A Formal Perspective on Byte-Pair Encoding
Jun 29, 2023



Byte-Pair Encoding (BPE) is a popular algorithm used for tokenizing data in NLP, despite being devised initially as a compression method. BPE appears to be a greedy algorithm at face value, but the underlying optimization problem that BPE seeks to solve has not yet been laid down. We formalize BPE as a combinatorial optimization problem. Via submodular functions, we prove that the iterative greedy version is a $\frac{1}{{\sigma(\boldsymbol{\mu}^\star)}}(1-e^{-{\sigma(\boldsymbol{\mu}^\star)}})$-approximation of an optimal merge sequence, where ${\sigma(\boldsymbol{\mu}^\star)}$ is the total backward curvature with respect to the optimal merge sequence $\boldsymbol{\mu}^\star$. Empirically the lower bound of the approximation is $\approx 0.37$. We provide a faster implementation of BPE which improves the runtime complexity from $\mathcal{O}\left(N M\right)$ to $\mathcal{O}\left(N \log M\right)$, where $N$ is the sequence length and $M$ is the merge count. Finally, we optimize the brute-force algorithm for optimal BPE using memoization.
Algorithms for Acyclic Weighted Finite-State Automata with Failure Arcs
Jan 17, 2023Weighted finite-state automata (WSFAs) are commonly used in NLP. Failure transitions are a useful extension for compactly representing backoffs or interpolation in $n$-gram models and CRFs, which are special cases of WFSAs. The pathsum in ordinary acyclic WFSAs is efficiently computed by the backward algorithm in time $O(|E|)$, where $E$ is the set of transitions. However, this does not allow failure transitions, and preprocessing the WFSA to eliminate failure transitions could greatly increase $|E|$. We extend the backward algorithm to handle failure transitions directly. Our approach is efficient when the average state has outgoing arcs for only a small fraction $s \ll 1$ of the alphabet $\Sigma$. We propose an algorithm for general acyclic WFSAs which runs in $O{\left(|E| + s |\Sigma| |Q| T_\text{max} \log{|\Sigma|}\right)}$, where $Q$ is the set of states and $T_\text{max}$ is the size of the largest connected component of failure transitions. When the failure transition topology satisfies a condition exemplified by CRFs, the $T_\text{max}$ factor can be dropped, and when the weight semiring is a ring, the $\log{|\Sigma|}$ factor can be dropped. In the latter case (ring-weighted acyclic WFSAs), we also give an alternative algorithm with complexity $\displaystyle O{\left(|E| + |\Sigma| |Q| \min(1,s\pi_\text{max}) \right)}$, where $\pi_\text{max}$ is the size of the longest failure path.
Algorithms for Weighted Pushdown Automata
Oct 19, 2022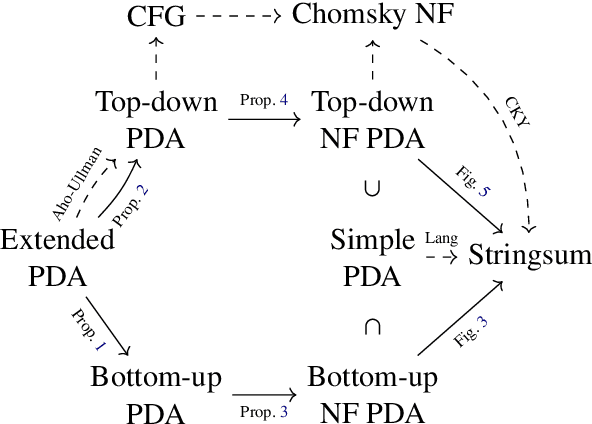
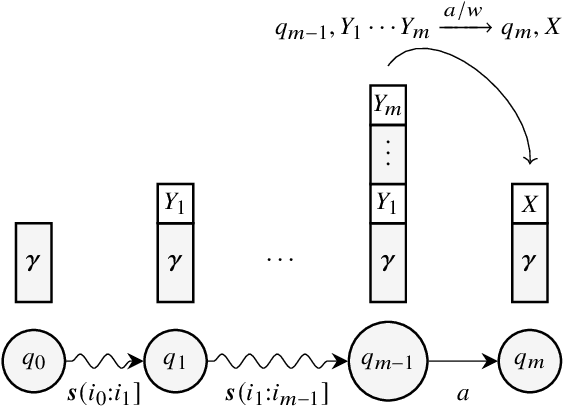
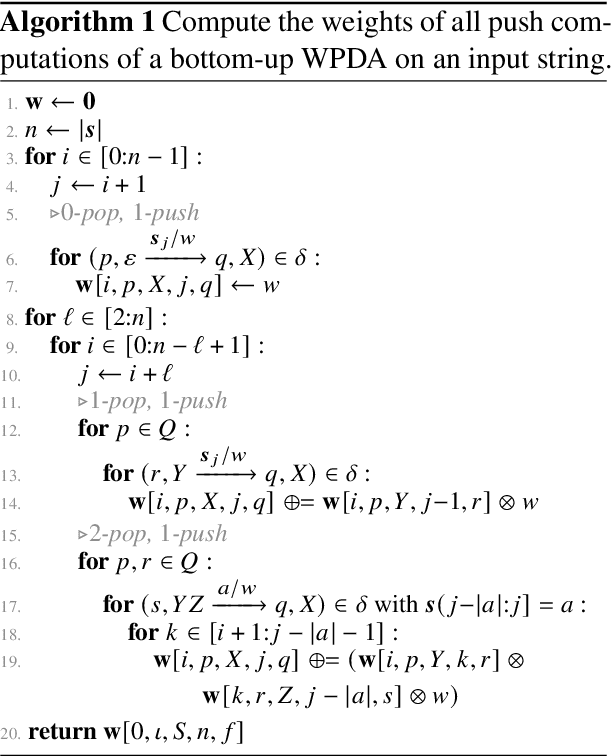
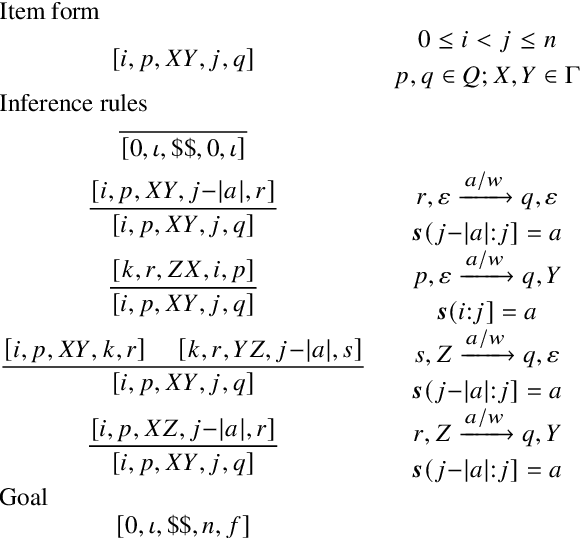
Weighted pushdown automata (WPDAs) are at the core of many natural language processing tasks, like syntax-based statistical machine translation and transition-based dependency parsing. As most existing dynamic programming algorithms are designed for context-free grammars (CFGs), algorithms for PDAs often resort to a PDA-to-CFG conversion. In this paper, we develop novel algorithms that operate directly on WPDAs. Our algorithms are inspired by Lang's algorithm, but use a more general definition of pushdown automaton and either reduce the space requirements by a factor of $|\Gamma|$ (the size of the stack alphabet) or reduce the runtime by a factor of more than $|Q|$ (the number of states). When run on the same class of PDAs as Lang's algorithm, our algorithm is both more space-efficient by a factor of $|\Gamma|$ and more time-efficient by a factor of $|Q| \cdot |\Gamma|$.
On the Intersection of Context-Free and Regular Languages
Sep 14, 2022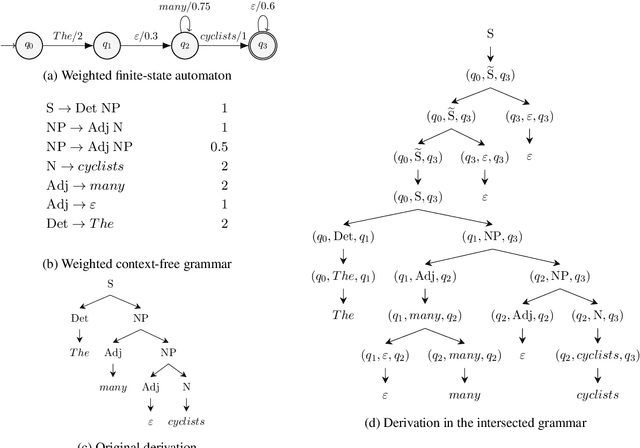
The Bar-Hillel construction is a classic result in formal language theory. It shows, by construction, that the intersection between a context-free language and a regular language is itself context-free. However, neither its original formulation (Bar-Hillel et al., 1961) nor its weighted extension (Nederhof and Satta, 2003) can handle automata with $\epsilon$-arcs. In this short note, we generalize the Bar-Hillel construction to correctly compute the intersection even when the automaton contains $\epsilon$-arcs. We further prove that our generalized construction leads to a grammar that encodes the structure of both the input automaton and grammar while retaining the asymptotic size of the original construction.
Exact Paired-Permutation Testing for Structured Test Statistics
May 04, 2022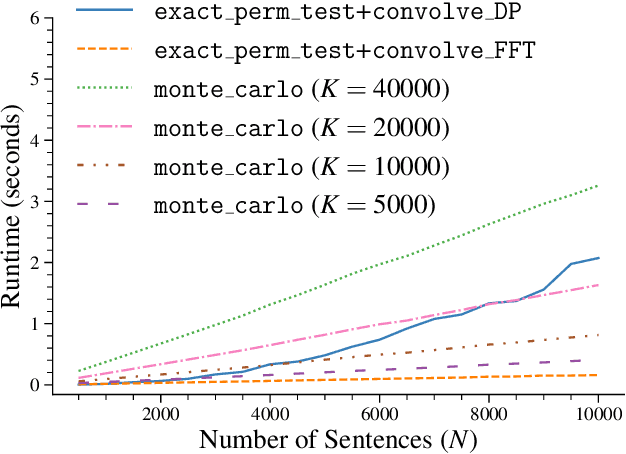
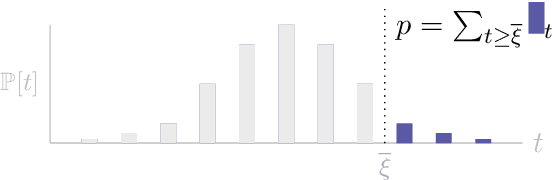
Significance testing -- especially the paired-permutation test -- has played a vital role in developing NLP systems to provide confidence that the difference in performance between two systems (i.e., the test statistic) is not due to luck. However, practitioners rely on Monte Carlo approximation to perform this test due to a lack of a suitable exact algorithm. In this paper, we provide an efficient exact algorithm for the paired-permutation test for a family of structured test statistics. Our algorithm runs in $\mathcal{O}(GN (\log GN )(\log N ))$ time where $N$ is the dataset size and $G$ is the range of the test statistic. We found that our exact algorithm was $10$x faster than the Monte Carlo approximation with $20000$ samples on a common dataset.
Searching for More Efficient Dynamic Programs
Sep 14, 2021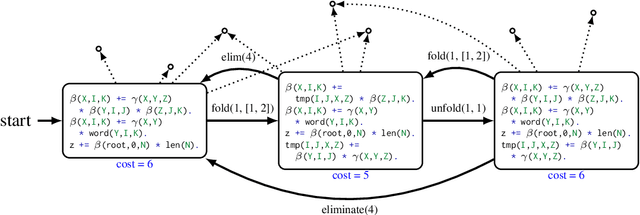
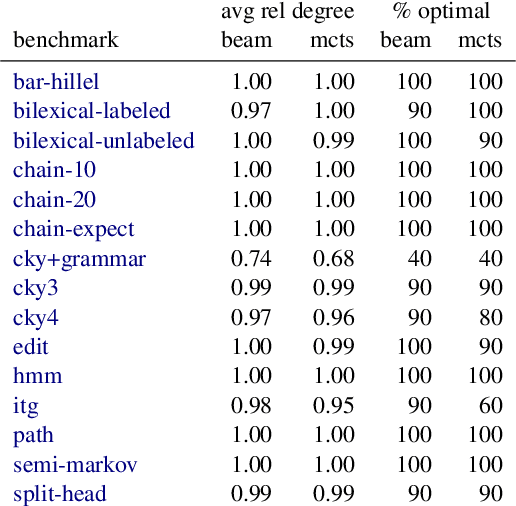

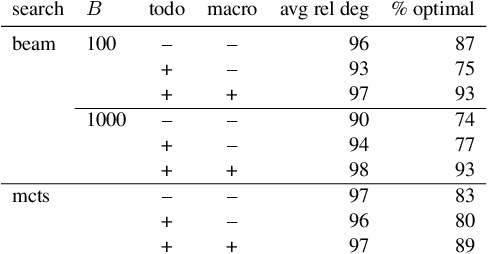
Computational models of human language often involve combinatorial problems. For instance, a probabilistic parser may marginalize over exponentially many trees to make predictions. Algorithms for such problems often employ dynamic programming and are not always unique. Finding one with optimal asymptotic runtime can be unintuitive, time-consuming, and error-prone. Our work aims to automate this laborious process. Given an initial correct declarative program, we search for a sequence of semantics-preserving transformations to improve its running time as much as possible. To this end, we describe a set of program transformations, a simple metric for assessing the efficiency of a transformed program, and a heuristic search procedure to improve this metric. We show that in practice, automated search -- like the mental search performed by human programmers -- can find substantial improvements to the initial program. Empirically, we show that many common speed-ups described in the NLP literature could have been discovered automatically by our system.
Efficient Sampling of Dependency Structures
Sep 14, 2021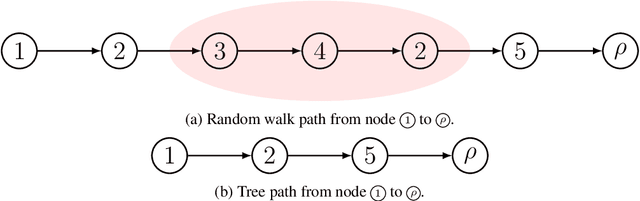



Probabilistic distributions over spanning trees in directed graphs are a fundamental model of dependency structure in natural language processing, syntactic dependency trees. In NLP, dependency trees often have an additional root constraint: only one edge may emanate from the root. However, no sampling algorithm has been presented in the literature to account for this additional constraint. In this paper, we adapt two spanning tree sampling algorithms to faithfully sample dependency trees from a graph subject to the root constraint. Wilson (1996)'s sampling algorithm has a running time of $\mathcal{O}(H)$ where $H$ is the mean hitting time of the graph. Colbourn (1996)'s sampling algorithm has a running time of $\mathcal{O}(N^3)$, which is often greater than the mean hitting time of a directed graph. Additionally, we build upon Colbourn's algorithm and present a novel extension that can sample $K$ trees without replacement in $\mathcal{O}(K N^3 + K^2 N)$ time. To the best of our knowledge, no algorithm has been given for sampling spanning trees without replacement from a directed graph.