 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI Planning Annotation for Sample Efficient Reinforcement Learning
Mar 01, 2022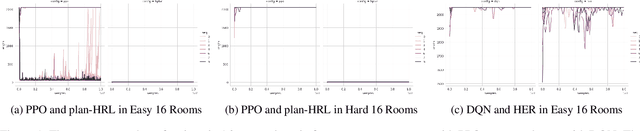

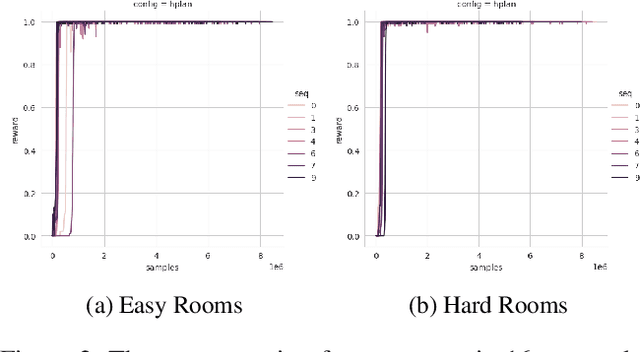
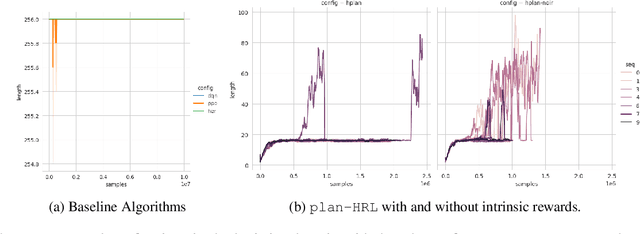
AI planning and Reinforcement Learning (RL) both solve sequential decision-making problems under the different formulations. AI Planning requires operator models, but then allows efficient plan generation. RL requires no operator model, instead learns a policy to guide an agent to high reward states. Planning can be brittle in the face of noise whereas RL is more tolerant. However, RL requires a large number of training examples to learn the policy. In this work, we aim to bring AI planning and RL closer by showing that a suitably defined planning model can be used to improve the efficiency of RL. Specifically, we show that the options in the hierarchical RL can be derived from a planning task and integrate planning and RL algorithms for training option policy functions. Our experiments demonstrate an improved sample efficiency on a variety of RL environments over the previous state-of-the-art.
Consolidation via Policy Information Regularization in Deep RL for Multi-Agent Games
Nov 23, 2020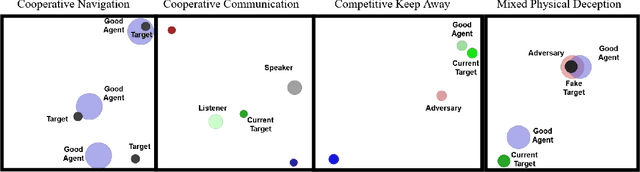
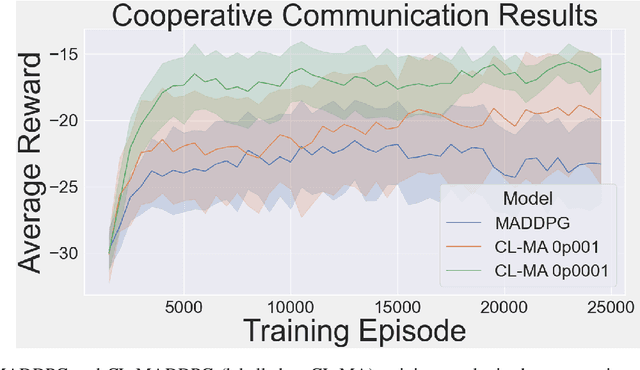
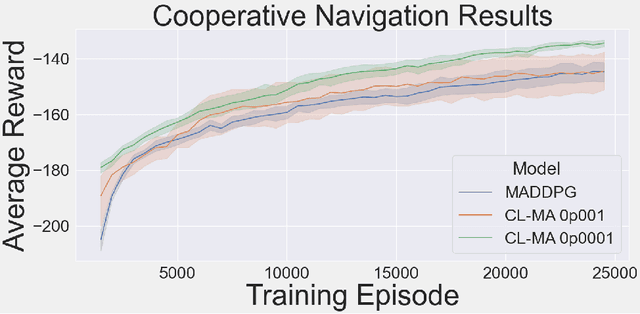
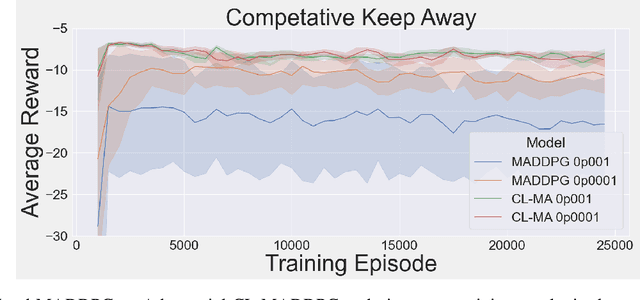
This paper introduces an information-theoretic constraint on learned policy complexity in the Multi-Agent Deep Deterministic Policy Gradient (MADDPG) reinforcement learning algorithm. Previous research with a related approach in continuous control experiments suggests that this method favors learning policies that are more robust to changing environment dynamics. The multi-agent game setting naturally requires this type of robustness, as other agents' policies change throughout learning, introducing a nonstationary environment. For this reason, recent methods in continual learning are compared to our approach, termed Capacity-Limited MADDPG. Results from experimentation in multi-agent cooperative and competitive tasks demonstrate that the capacity-limited approach is a good candidate for improving learning performance in these environments.
Deep RL With Information Constrained Policies: Generalization in Continuous Control
Oct 09, 2020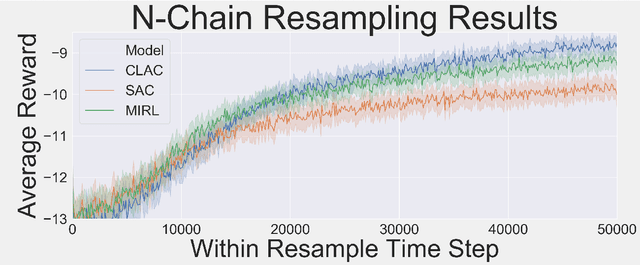
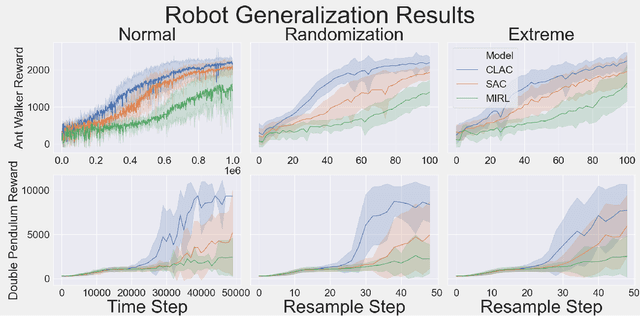
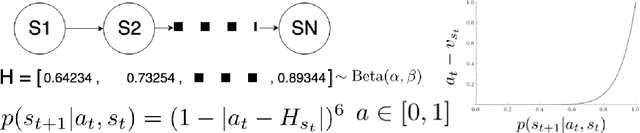
Biological agents learn and act intelligently in spite of a highly limited capacity to process and store information. Many real-world problems involve continuous control, which represents a difficult task for artificial intelligence agents. In this paper we explore the potential learning advantages a natural constraint on information flow might confer onto artificial agents in continuous control tasks. We focus on the model-free reinforcement learning (RL) setting and formalize our approach in terms of an information-theoretic constraint on the complexity of learned policies. We show that our approach emerges in a principled fashion from the application of rate-distortion theory. We implement a novel Capacity-Limited Actor-Critic (CLAC) algorithm and situate it within a broader family of RL algorithms such as the Soft Actor Critic (SAC) and Mutual Information Reinforcement Learning (MIRL) algorithm. Our experiments using continuous control tasks show that compared to alternative approaches, CLAC offers improvements in generalization between training and modified test environments. This is achieved in the CLAC model while displaying the high sample efficiency of similar methods.
A Study of Compositional Generalization in Neural Models
Jul 08, 2020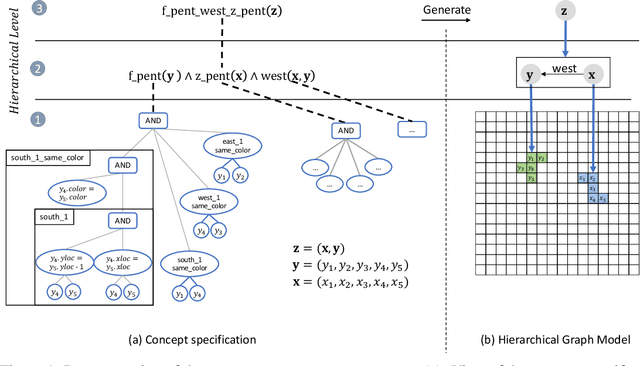
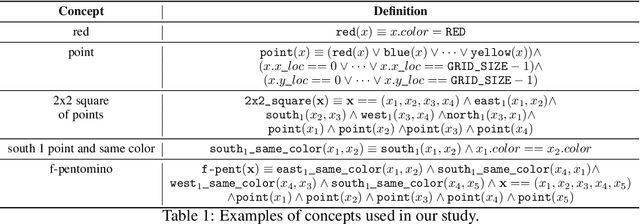
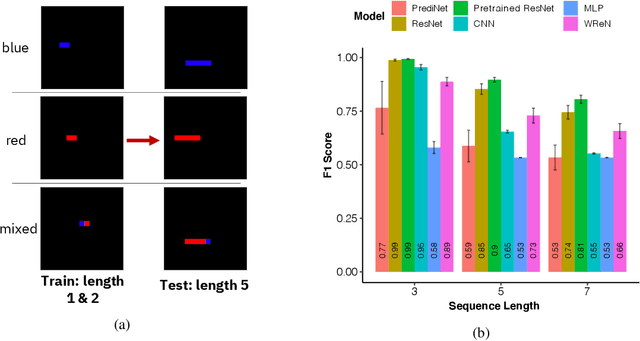
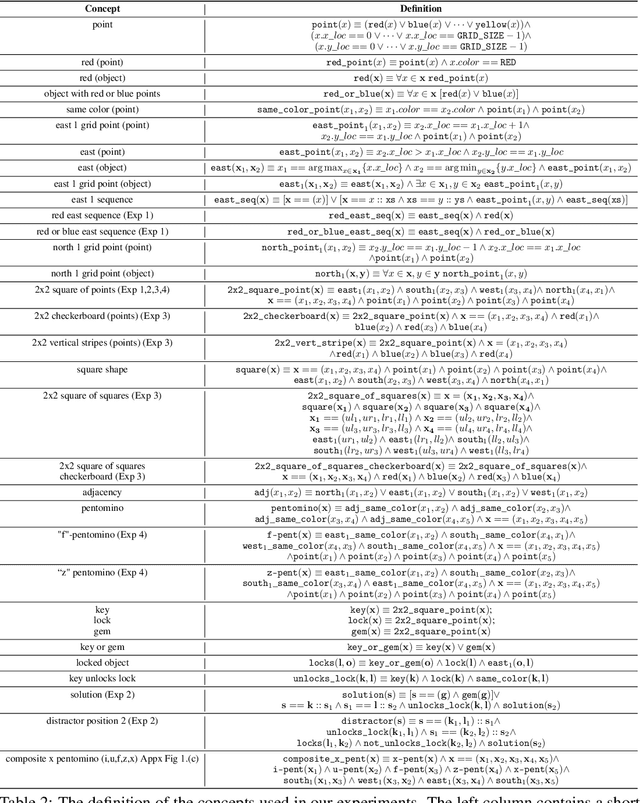
Compositional and relational learning is a hallmark of human intelligence, but one which presents challenges for neural models. One difficulty in the development of such models is the lack of benchmarks with clear compositional and relational task structure on which to systematically evaluate them. In this paper, we introduce an environment called ConceptWorld, which enables the generation of images from compositional and relational concepts, defined using a logical domain specific language. We use it to generate images for a variety of compositional structures: 2x2 squares, pentominoes, sequences, scenes involving these objects, and other more complex concepts. We perform experiments to test the ability of standard neural architectures to generalize on relations with compositional arguments as the compositional depth of those arguments increases and under substitution. We compare standard neural networks such as MLP, CNN and ResNet, as well as state-of-the-art relational networks including WReN and PrediNet in a multi-class image classification setting. For simple problems, all models generalize well to close concepts but struggle with longer compositional chains. For more complex tests involving substitutivity, all models struggle, even with short chains. In highlighting these difficulties and providing an environment for further experimentation, we hope to encourage the development of models which are able to generalize effectively in compositional, relational domains.
Finding Macro-Actions with Disentangled Effects for Efficient Planning with the Goal-Count Heuristic
Apr 28, 2020

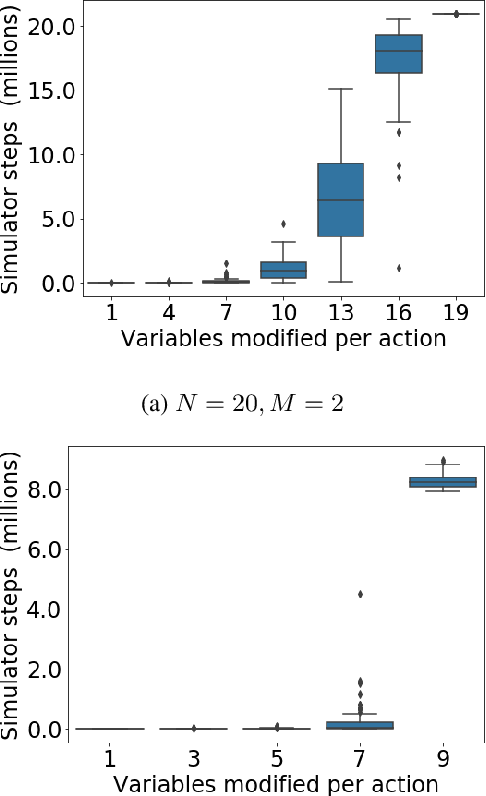

The difficulty of classical planning increases exponentially with search-tree depth. Heuristic search can make planning more efficient, but good heuristics often require domain-specific assumptions and may not generalize to new problems. Rather than treating the planning problem as fixed and carefully designing a heuristic to match it, we instead construct macro-actions that support efficient planning with the simple and general-purpose "goal-count" heuristic. Our approach searches for macro-actions that modify only a small number of state variables (we call this measure "entanglement"). We show experimentally that reducing entanglement exponentially decreases planning time with the goal-count heuristic. Our method discovers macro-actions with disentangled effects that dramatically improve planning efficiency for 15-puzzle and Rubik's cube, reliably solving each domain without prior knowledge, and solving Rubik's cube with orders of magnitude less data than competing approaches.
Routing Networks and the Challenges of Modular and Compositional Computation
Apr 29, 2019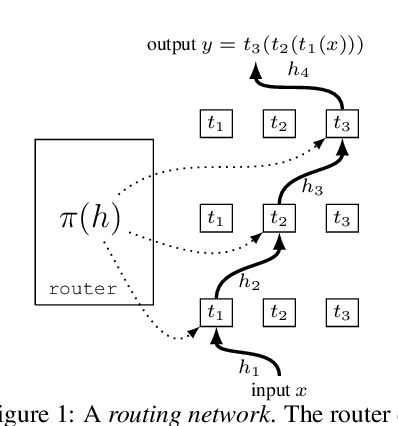
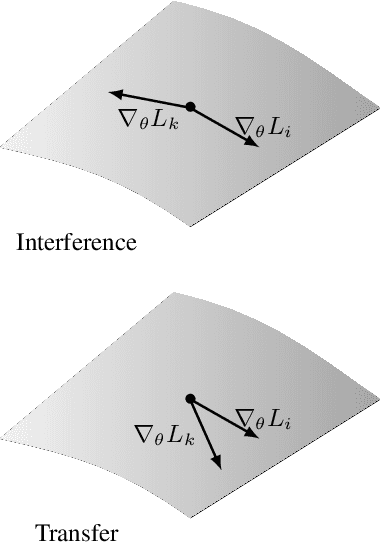
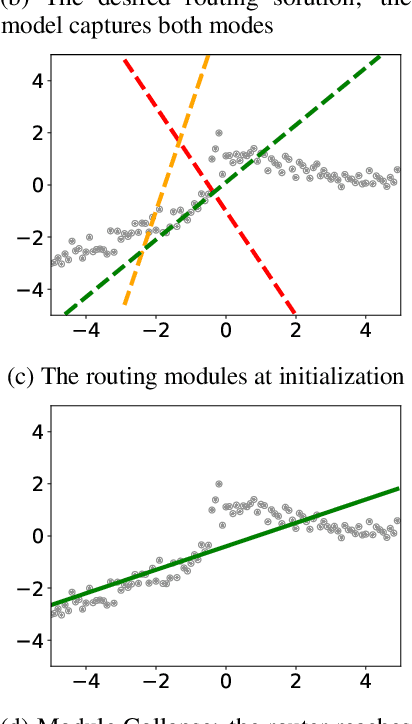
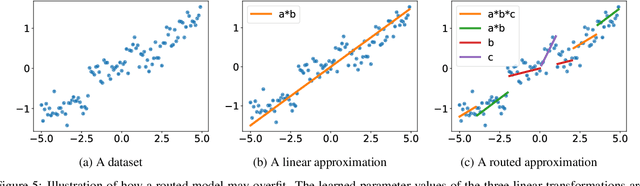
Compositionality is a key strategy for addressing combinatorial complexity and the curse of dimensionality. Recent work has shown that compositional solutions can be learned and offer substantial gains across a variety of domains, including multi-task learning, language modeling, visual question answering, machine comprehension, and others. However, such models present unique challenges during training when both the module parameters and their composition must be learned jointly. In this paper, we identify several of these issues and analyze their underlying causes. Our discussion focuses on routing networks, a general approach to this problem, and examines empirically the interplay of these challenges and a variety of design decisions. In particular, we consider the effect of how the algorithm decides on module composition, how the algorithm updates the modules, and if the algorithm uses regularization.
Logical Rule Induction and Theory Learning Using Neural Theorem Proving
Sep 12, 2018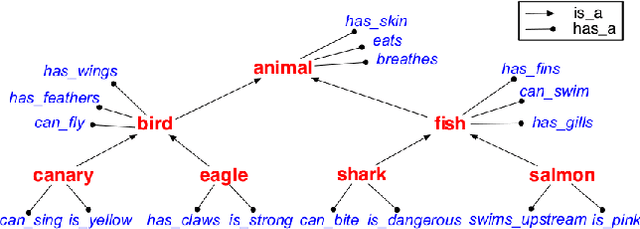
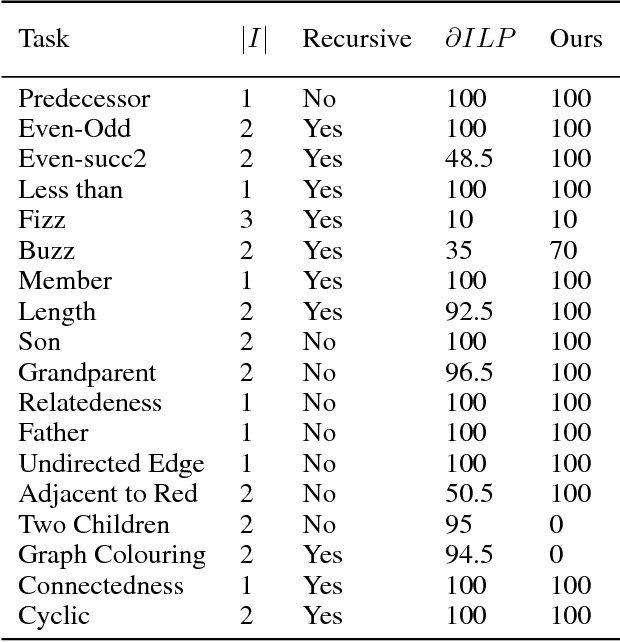
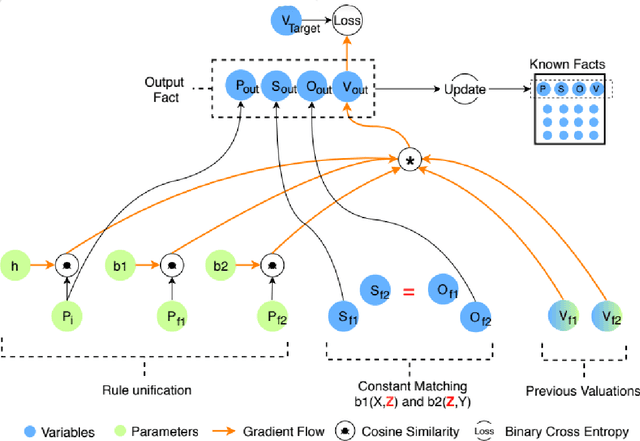
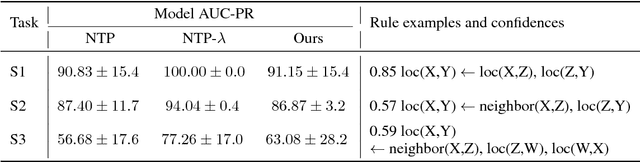
A hallmark of human cognition is the ability to continually acquire and distill observations of the world into meaningful, predictive theories. In this paper we present a new mechanism for logical theory acquisition which takes a set of observed facts and learns to extract from them a set of logical rules and a small set of core facts which together entail the observations. Our approach is neuro-symbolic in the sense that the rule pred- icates and core facts are given dense vector representations. The rules are applied to the core facts using a soft unification procedure to infer additional facts. After k steps of forward inference, the consequences are compared to the initial observations and the rules and core facts are then encouraged towards representations that more faithfully generate the observations through inference. Our approach is based on a novel neural forward-chaining differentiable rule induction network. The rules are interpretable and learned compositionally from their predicates, which may be invented. We demonstrate the efficacy of our approach on a variety of ILP rule induction and domain theory learning datasets.
Evidence Aggregation for Answer Re-Ranking in Open-Domain Question Answering
Apr 26, 2018

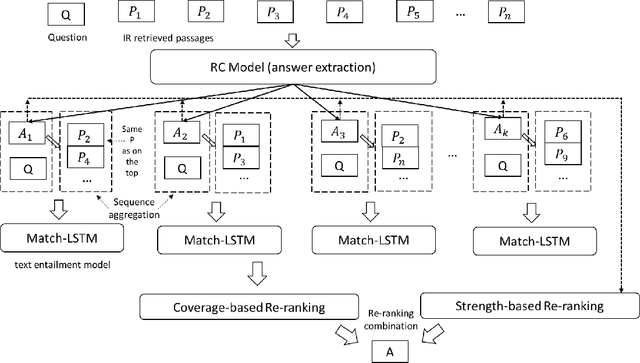
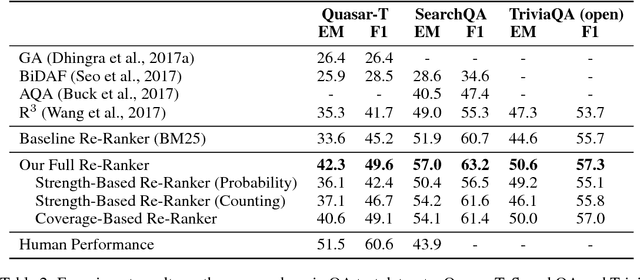
A popular recent approach to answering open-domain questions is to first search for question-related passages and then apply reading comprehension models to extract answers. Existing methods usually extract answers from single passages independently. But some questions require a combination of evidence from across different sources to answer correctly. In this paper, we propose two models which make use of multiple passages to generate their answers. Both use an answer-reranking approach which reorders the answer candidates generated by an existing state-of-the-art QA model. We propose two methods, namely, strength-based re-ranking and coverage-based re-ranking, to make use of the aggregated evidence from different passages to better determine the answer. Our models have achieved state-of-the-art results on three public open-domain QA datasets: Quasar-T, SearchQA and the open-domain version of TriviaQA, with about 8 percentage points of improvement over the former two datasets.
Scalable Recollections for Continual Lifelong Learning
Feb 26, 2018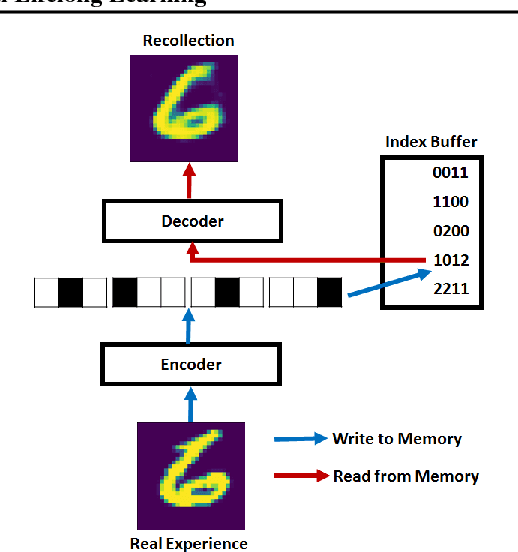

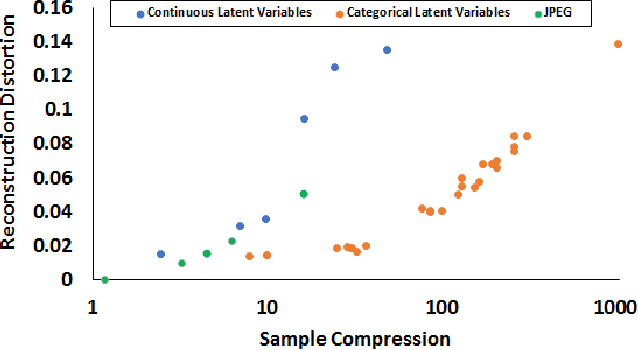
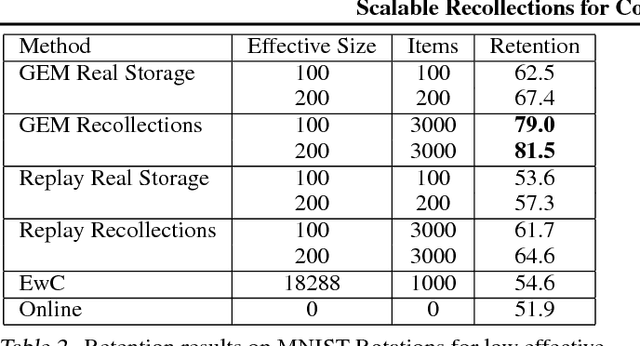
Given the recent success of Deep Learning applied to a variety of single tasks, it is natural to consider more human-realistic settings. Perhaps the most difficult of these settings is that of continual lifelong learning, where the model must learn online over a continuous stream of non-stationary data. A continual lifelong learning system must have three primary capabilities to succeed: it must learn and adapt over time, it must not forget what it has learned, and it must be efficient in both training time and memory. Recent techniques have focused their efforts largely on the first two capabilities while the third capability remains largely unexplored. In this paper, we consider the problem of efficient and effective storage of experiences over very large time-frames. In particular we consider the case where typical experiences are n bits and memories are limited to k bits for k << n. We present a novel scalable architecture and training algorithm in this challenging domain and provide an extensive evaluation of its performance. Our results show that we can achieve considerable gains on top of state-of-the-art methods such as GEM.
Routing Networks: Adaptive Selection of Non-linear Functions for Multi-Task Learning
Dec 31, 2017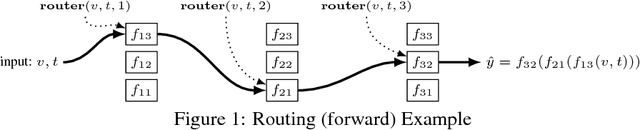
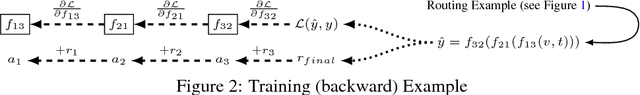
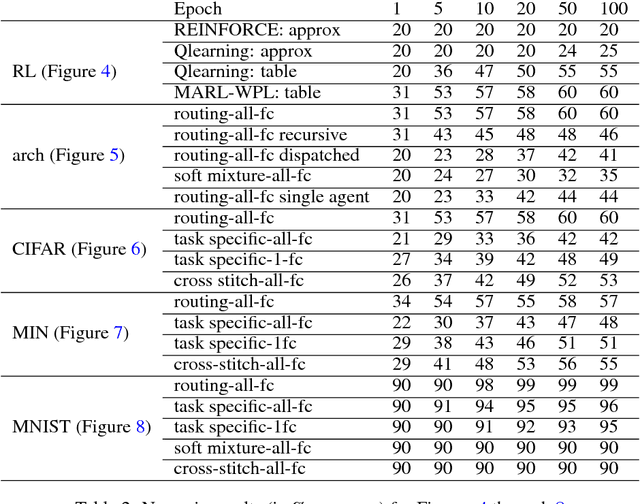
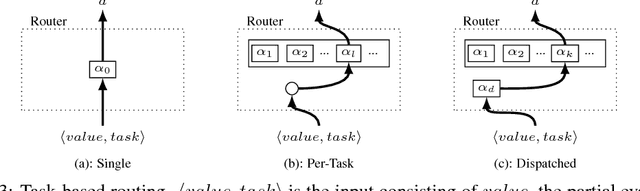
Multi-task learning (MTL) with neural networks leverages commonalities in tasks to improve performance, but often suffers from task interference which reduces the benefits of transfer. To address this issue we introduce the routing network paradigm, a novel neural network and training algorithm. A routing network is a kind of self-organizing neural network consisting of two components: a router and a set of one or more function blocks. A function block may be any neural network - for example a fully-connected or a convolutional layer. Given an input the router makes a routing decision, choosing a function block to apply and passing the output back to the router recursively, terminating when a fixed recursion depth is reached. In this way the routing network dynamically composes different function blocks for each input. We employ a collaborative multi-agent reinforcement learning (MARL) approach to jointly train the router and function blocks. We evaluate our model against cross-stitch networks and shared-layer baselines on multi-task settings of the MNIST, mini-imagenet, and CIFAR-100 datasets. Our experiments demonstrate a significant improvement in accuracy, with sharper convergence. In addition, routing networks have nearly constant per-task training cost while cross-stitch networks scale linearly with the number of tasks. On CIFAR-100 (20 tasks) we obtain cross-stitch performance levels with an 85% reduction in training time.