 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYour Policy Regularizer is Secretly an Adversary
Apr 01, 2022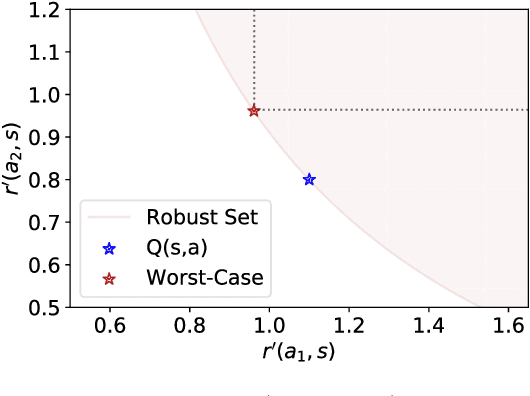


Policy regularization methods such as maximum entropy regularization are widely used in reinforcement learning to improve the robustness of a learned policy. In this paper, we show how this robustness arises from hedging against worst-case perturbations of the reward function, which are chosen from a limited set by an imagined adversary. Using convex duality, we characterize this robust set of adversarial reward perturbations under KL and alpha-divergence regularization, which includes Shannon and Tsallis entropy regularization as special cases. Importantly, generalization guarantees can be given within this robust set. We provide detailed discussion of the worst-case reward perturbations, and present intuitive empirical examples to illustrate this robustness and its relationship with generalization. Finally, we discuss how our analysis complements and extends previous results on adversarial reward robustness and path consistency optimality conditions.
Model-Free Risk-Sensitive Reinforcement Learning
Nov 04, 2021
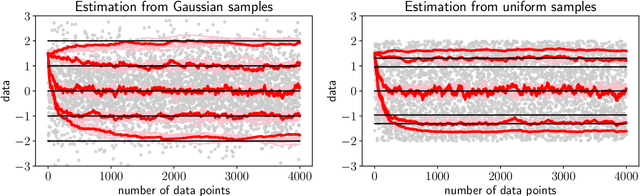
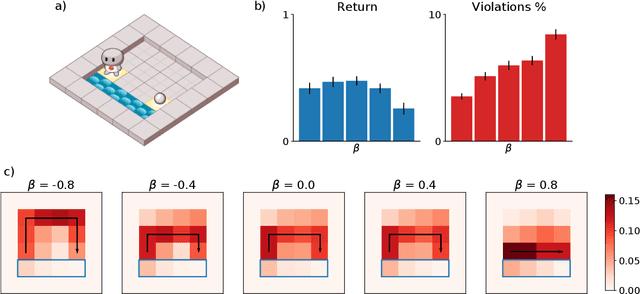

We extend temporal-difference (TD) learning in order to obtain risk-sensitive, model-free reinforcement learning algorithms. This extension can be regarded as modification of the Rescorla-Wagner rule, where the (sigmoidal) stimulus is taken to be either the event of over- or underestimating the TD target. As a result, one obtains a stochastic approximation rule for estimating the free energy from i.i.d. samples generated by a Gaussian distribution with unknown mean and variance. Since the Gaussian free energy is known to be a certainty-equivalent sensitive to the mean and the variance, the learning rule has applications in risk-sensitive decision-making.
Shaking the foundations: delusions in sequence models for interaction and control
Oct 20, 2021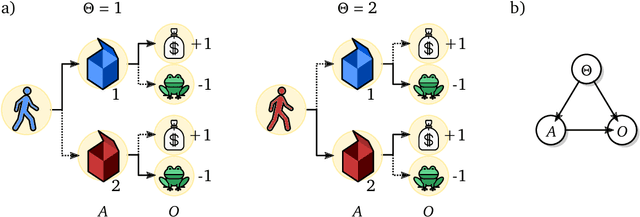
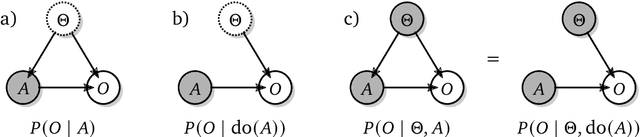
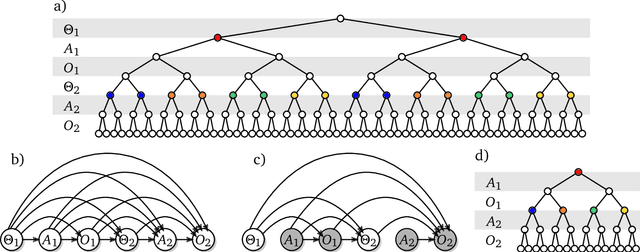
The recent phenomenal success of language models has reinvigorated machine learning research, and large sequence models such as transformers are being applied to a variety of domains. One important problem class that has remained relatively elusive however is purposeful adaptive behavior. Currently there is a common perception that sequence models "lack the understanding of the cause and effect of their actions" leading them to draw incorrect inferences due to auto-suggestive delusions. In this report we explain where this mismatch originates, and show that it can be resolved by treating actions as causal interventions. Finally, we show that in supervised learning, one can teach a system to condition or intervene on data by training with factual and counterfactual error signals respectively.
Causal Analysis of Agent Behavior for AI Safety
Mar 05, 2021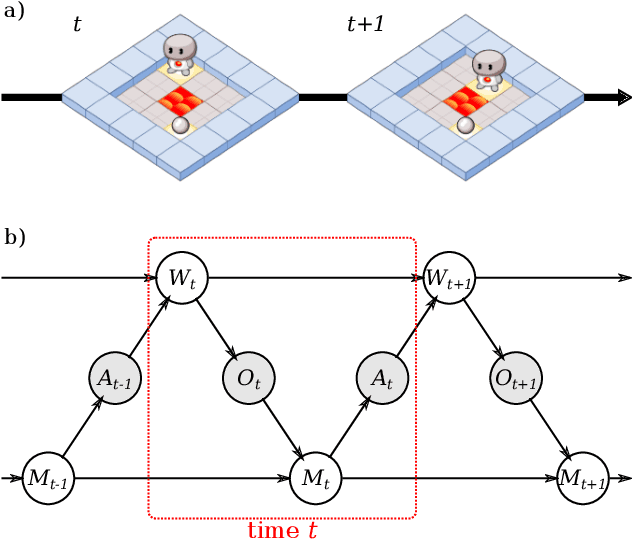
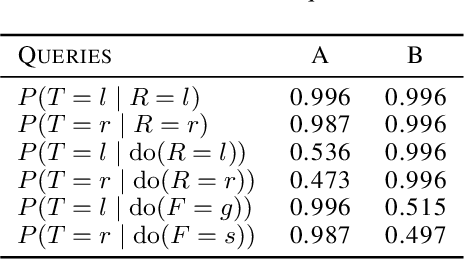
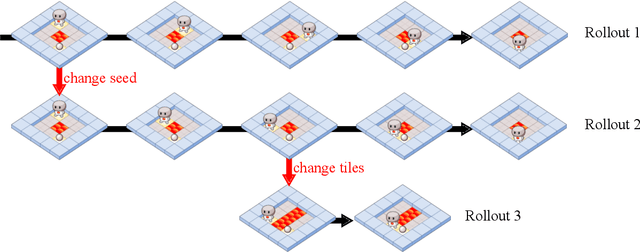
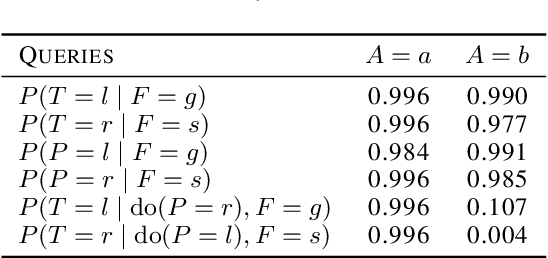
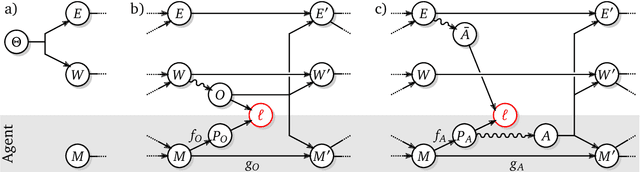
As machine learning systems become more powerful they also become increasingly unpredictable and opaque. Yet, finding human-understandable explanations of how they work is essential for their safe deployment. This technical report illustrates a methodology for investigating the causal mechanisms that drive the behaviour of artificial agents. Six use cases are covered, each addressing a typical question an analyst might ask about an agent. In particular, we show that each question cannot be addressed by pure observation alone, but instead requires conducting experiments with systematically chosen manipulations so as to generate the correct causal evidence.
Algorithms for Causal Reasoning in Probability Trees
Nov 12, 2020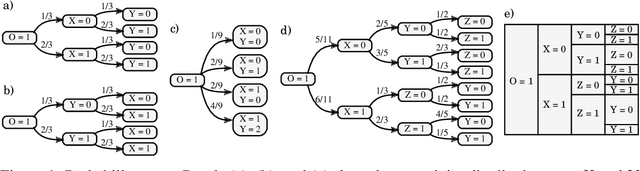
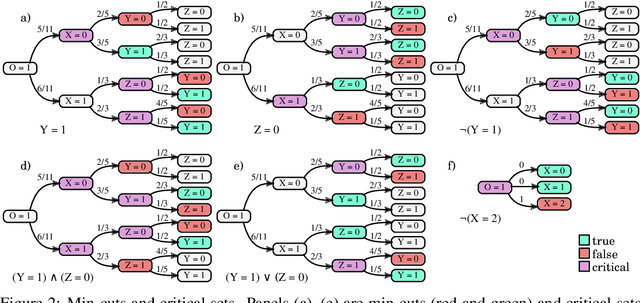


Probability trees are one of the simplest models of causal generative processes. They possess clean semantics and -- unlike causal Bayesian networks -- they can represent context-specific causal dependencies, which are necessary for e.g. causal induction. Yet, they have received little attention from the AI and ML community. Here we present concrete algorithms for causal reasoning in discrete probability trees that cover the entire causal hierarchy (association, intervention, and counterfactuals), and operate on arbitrary propositional and causal events. Our work expands the domain of causal reasoning to a very general class of discrete stochastic processes.
Meta-trained agents implement Bayes-optimal agents
Oct 21, 2020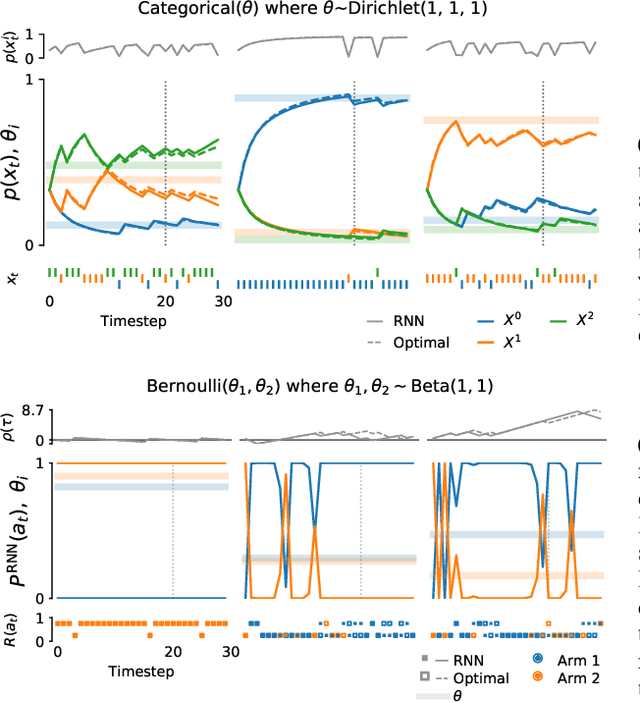

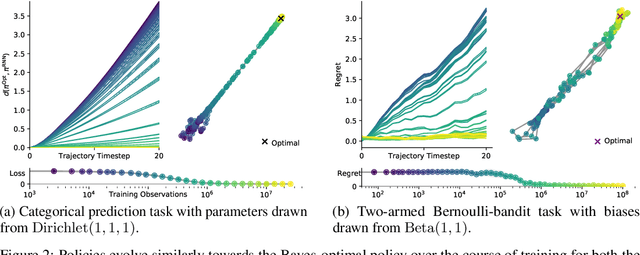
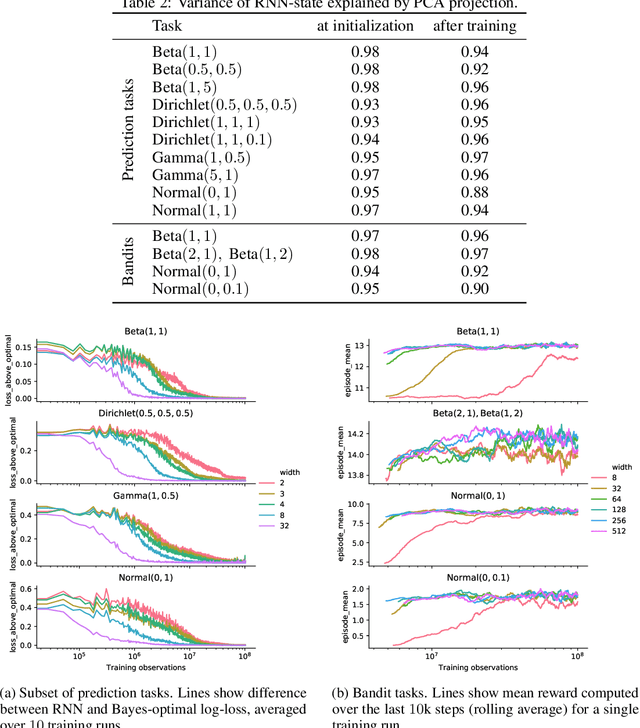
Memory-based meta-learning is a powerful technique to build agents that adapt fast to any task within a target distribution. A previous theoretical study has argued that this remarkable performance is because the meta-training protocol incentivises agents to behave Bayes-optimally. We empirically investigate this claim on a number of prediction and bandit tasks. Inspired by ideas from theoretical computer science, we show that meta-learned and Bayes-optimal agents not only behave alike, but they even share a similar computational structure, in the sense that one agent system can approximately simulate the other. Furthermore, we show that Bayes-optimal agents are fixed points of the meta-learning dynamics. Our results suggest that memory-based meta-learning might serve as a general technique for numerically approximating Bayes-optimal agents - that is, even for task distributions for which we currently don't possess tractable models.
Group Pruning using a Bounded-Lp norm for Group Gating and Regularization
Aug 09, 2019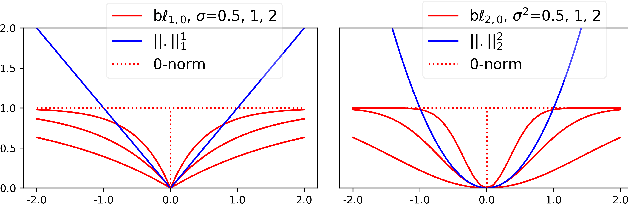
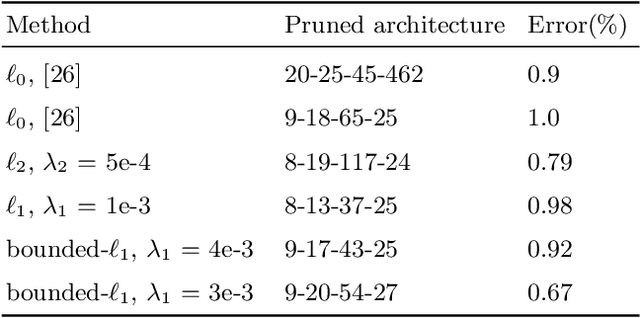
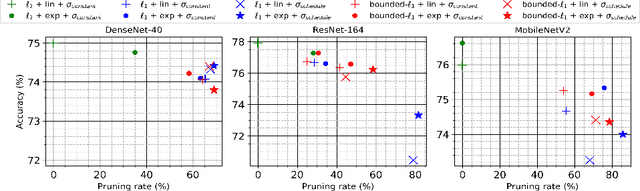
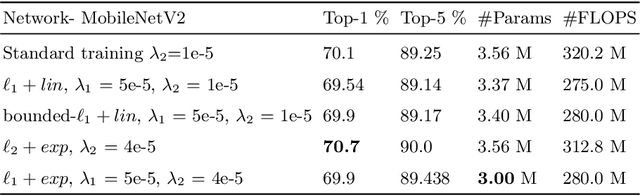
Deep neural networks achieve state-of-the-art results on several tasks while increasing in complexity. It has been shown that neural networks can be pruned during training by imposing sparsity inducing regularizers. In this paper, we investigate two techniques for group-wise pruning during training in order to improve network efficiency. We propose a gating factor after every convolutional layer to induce channel level sparsity, encouraging insignificant channels to become exactly zero. Further, we introduce and analyse a bounded variant of the L1 regularizer, which interpolates between L1 and L0-norms to retain performance of the network at higher pruning rates. To underline effectiveness of the proposed methods,we show that the number of parameters of ResNet-164, DenseNet-40 and MobileNetV2 can be reduced down by 30%, 69% and 75% on CIFAR100 respectively without a significant drop in accuracy. We achieve state-of-the-art pruning results for ResNet-50 with higher accuracy on ImageNet. Furthermore, we show that the light weight MobileNetV2 can further be compressed on ImageNet without a significant drop in performance.
Meta-learning of Sequential Strategies
May 08, 2019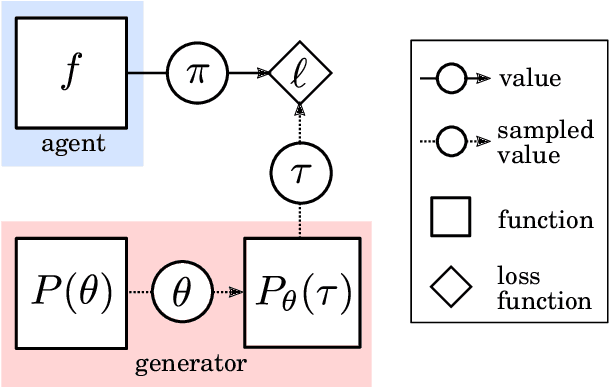
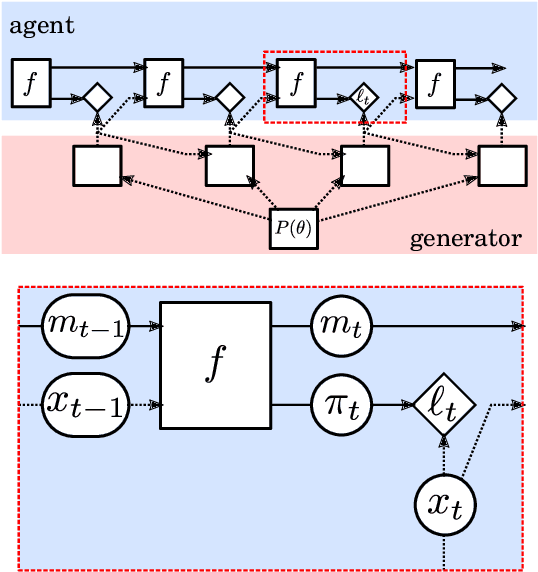
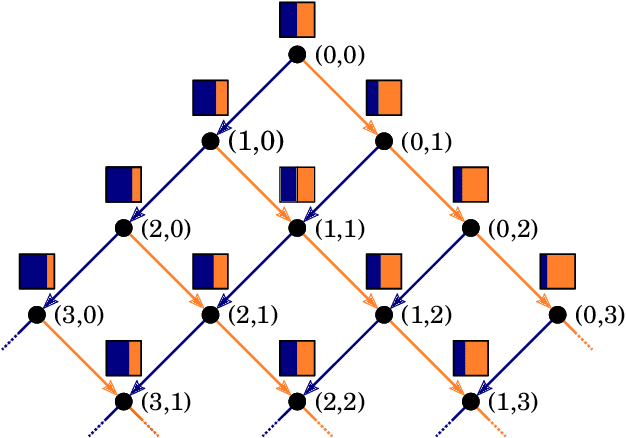
In this report we review memory-based meta-learning as a tool for building sample-efficient strategies that learn from past experience to adapt to any task within a target class. Our goal is to equip the reader with the conceptual foundations of this tool for building new, scalable agents that operate on broad domains. To do so, we present basic algorithmic templates for building near-optimal predictors and reinforcement learners which behave as if they had a probabilistic model that allowed them to efficiently exploit task structure. Furthermore, we recast memory-based meta-learning within a Bayesian framework, showing that the meta-learned strategies are near-optimal because they amortize Bayes-filtered data, where the adaptation is implemented in the memory dynamics as a state-machine of sufficient statistics. Essentially, memory-based meta-learning translates the hard problem of probabilistic sequential inference into a regression problem.
Sinkhorn AutoEncoders
Oct 03, 2018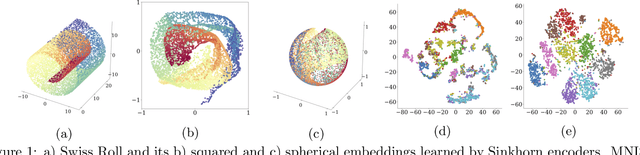
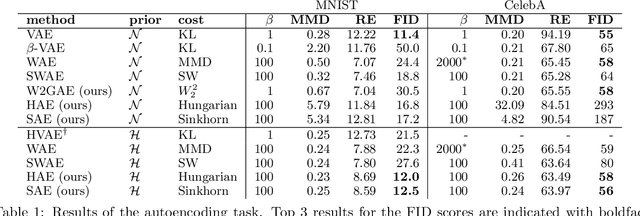

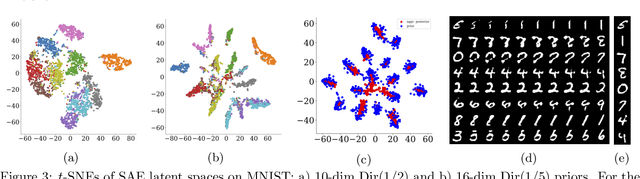
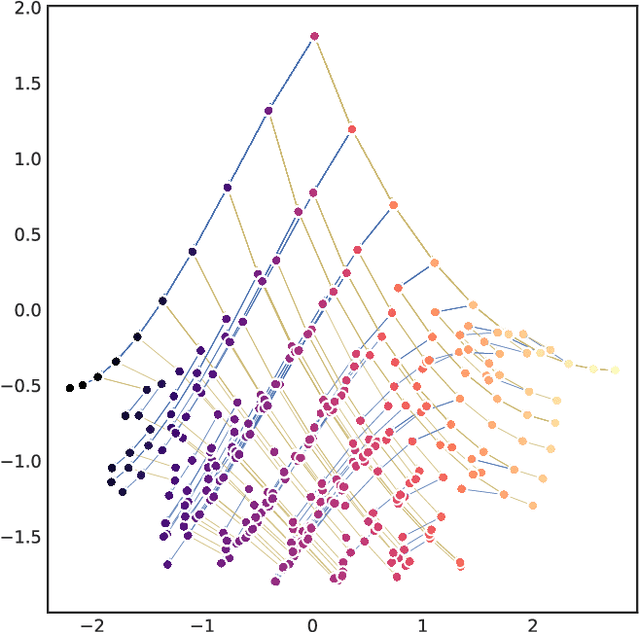
Optimal Transport offers an alternative to maximum likelihood for learning generative autoencoding models. We show how this principle dictates the minimization of the Wasserstein distance between the encoder aggregated posterior and the prior, plus a reconstruction error. We prove that in the non-parametric limit the autoencoder generates the data distribution if and only if the two distributions match exactly, and that the optimum can be obtained by deterministic autoencoders. We then introduce the Sinkhorn AutoEncoder (SAE), which casts the problem into Optimal Transport on the latent space. The resulting Wasserstein distance is minimized by backpropagating through the Sinkhorn algorithm. SAE models the aggregated posterior as an implicit distribution and therefore does not need a reparameterization trick for gradients estimation. Moreover, it requires virtually no adaptation to different prior distributions. We demonstrate its flexibility by considering models with hyperspherical and Dirichlet priors, as well as a simple case of probabilistic programming. SAE matches or outperforms other autoencoding models in visual quality and FID scores.
An information-theoretic on-line update principle for perception-action coupling
Apr 16, 2018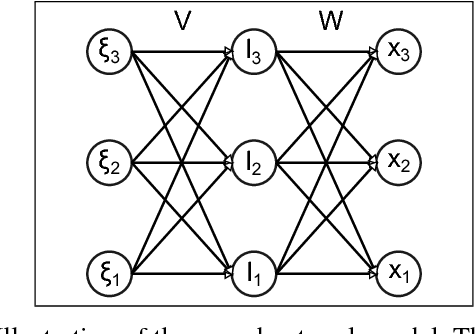
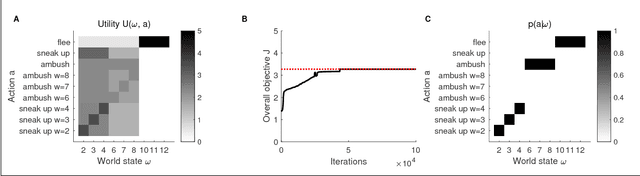
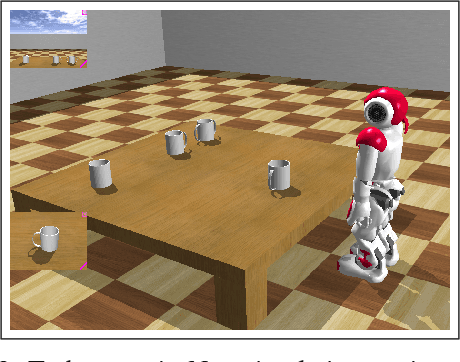
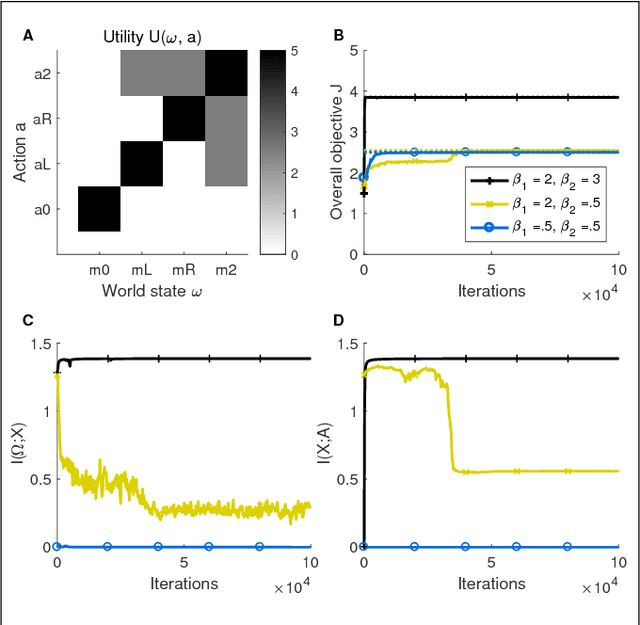
Inspired by findings of sensorimotor coupling in humans and animals, there has recently been a growing interest in the interaction between action and perception in robotic systems [Bogh et al., 2016]. Here we consider perception and action as two serial information channels with limited information-processing capacity. We follow [Genewein et al., 2015] and formulate a constrained optimization problem that maximizes utility under limited information-processing capacity in the two channels. As a solution we obtain an optimal perceptual channel and an optimal action channel that are coupled such that perceptual information is optimized with respect to downstream processing in the action module. The main novelty of this study is that we propose an online optimization procedure to find bounded-optimal perception and action channels in parameterized serial perception-action systems. In particular, we implement the perceptual channel as a multi-layer neural network and the action channel as a multinomial distribution. We illustrate our method in a NAO robot simulator with a simplified cup lifting task.