 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Prediction-Powered Inference
Oct 11, 2023



While reliable data-driven decision-making hinges on high-quality labeled data, the acquisition of quality labels often involves laborious human annotations or slow and expensive scientific measurements. Machine learning is becoming an appealing alternative as sophisticated predictive techniques are being used to quickly and cheaply produce large amounts of predicted labels; e.g., predicted protein structures are used to supplement experimentally derived structures, predictions of socioeconomic indicators from satellite imagery are used to supplement accurate survey data, and so on. Since predictions are imperfect and potentially biased, this practice brings into question the validity of downstream inferences. We introduce cross-prediction: a method for valid inference powered by machine learning. With a small labeled dataset and a large unlabeled dataset, cross-prediction imputes the missing labels via machine learning and applies a form of debiasing to remedy the prediction inaccuracies. The resulting inferences achieve the desired error probability and are more powerful than those that only leverage the labeled data. Closely related is the recent proposal of prediction-powered inference, which assumes that a good pre-trained model is already available. We show that cross-prediction is consistently more powerful than an adaptation of prediction-powered inference in which a fraction of the labeled data is split off and used to train the model. Finally, we observe that cross-prediction gives more stable conclusions than its competitors; its confidence intervals typically have significantly lower variability.
Plug-in Performative Optimization
May 30, 2023When predictions are performative, the choice of which predictor to deploy influences the distribution of future observations. The overarching goal in learning under performativity is to find a predictor that has low \emph{performative risk}, that is, good performance on its induced distribution. One family of solutions for optimizing the performative risk, including bandits and other derivative-free methods, is agnostic to any structure in the performative feedback, leading to exceedingly slow convergence rates. A complementary family of solutions makes use of explicit \emph{models} for the feedback, such as best-response models in strategic classification, enabling significantly faster rates. However, these rates critically rely on the feedback model being well-specified. In this work we initiate a study of the use of possibly \emph{misspecified} models in performative prediction. We study a general protocol for making use of models, called \emph{plug-in performative optimization}, and prove bounds on its excess risk. We show that plug-in performative optimization can be far more efficient than model-agnostic strategies, as long as the misspecification is not too extreme. Altogether, our results support the hypothesis that models--even if misspecified--can indeed help with learning in performative settings.
Algorithmic Collective Action in Machine Learning
Feb 08, 2023



We initiate a principled study of algorithmic collective action on digital platforms that deploy machine learning algorithms. We propose a simple theoretical model of a collective interacting with a firm's learning algorithm. The collective pools the data of participating individuals and executes an algorithmic strategy by instructing participants how to modify their own data to achieve a collective goal. We investigate the consequences of this model in three fundamental learning-theoretic settings: the case of a nonparametric optimal learning algorithm, a parametric risk minimizer, and gradient-based optimization. In each setting, we come up with coordinated algorithmic strategies and characterize natural success criteria as a function of the collective's size. Complementing our theory, we conduct systematic experiments on a skill classification task involving tens of thousands of resumes from a gig platform for freelancers. Through more than two thousand model training runs of a BERT-like language model, we see a striking correspondence emerge between our empirical observations and the predictions made by our theory. Taken together, our theory and experiments broadly support the conclusion that algorithmic collectives of exceedingly small fractional size can exert significant control over a platform's learning algorithm.
Prediction-Powered Inference
Feb 02, 2023We introduce prediction-powered inference $\unicode{x2013}$ a framework for performing valid statistical inference when an experimental data set is supplemented with predictions from a machine-learning system. Our framework yields provably valid conclusions without making any assumptions on the machine-learning algorithm that supplies the predictions. Higher accuracy of the predictions translates to smaller confidence intervals, permitting more powerful inference. Prediction-powered inference yields simple algorithms for computing valid confidence intervals for statistical objects such as means, quantiles, and linear and logistic regression coefficients. We demonstrate the benefits of prediction-powered inference with data sets from proteomics, genomics, electronic voting, remote sensing, census analysis, and ecology.
Valid Inference after Causal Discovery
Aug 11, 2022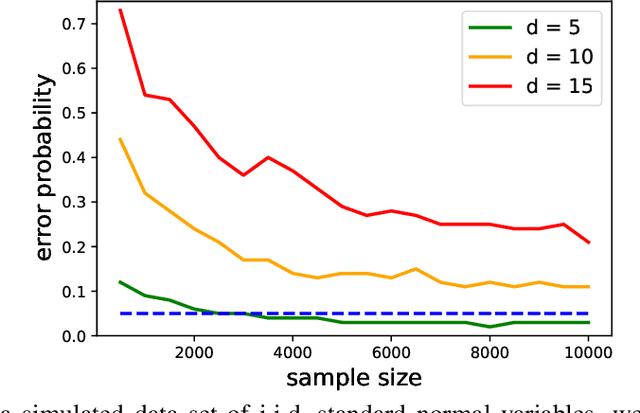

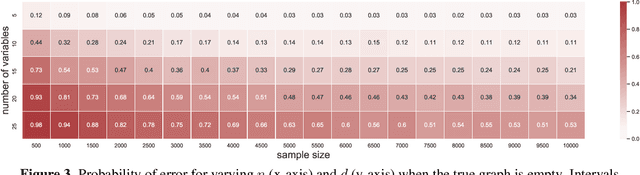
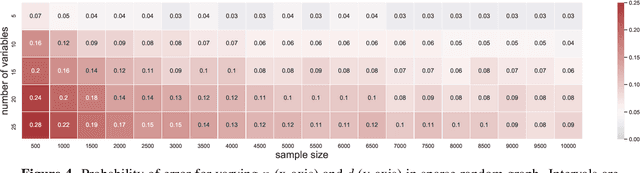
Causal graph discovery and causal effect estimation are two fundamental tasks in causal inference. While many methods have been developed for each task individually, statistical challenges arise when applying these methods jointly: estimating causal effects after running causal discovery algorithms on the same data leads to "double dipping," invalidating coverage guarantees of classical confidence intervals. To this end, we develop tools for valid post-causal-discovery inference. One key contribution is a randomized version of the greedy equivalence search (GES) algorithm, which permits a valid, finite-sample correction of classical confidence intervals. Across empirical studies, we show that a naive combination of causal discovery and subsequent inference algorithms typically leads to highly inflated miscoverage rates; at the same time, our noisy GES method provides reliable coverage control while achieving more accurate causal graph recovery than data splitting.
A Note on Zeroth-Order Optimization on the Simplex
Aug 02, 2022We construct a zeroth-order gradient estimator for a smooth function defined on the probability simplex. The proposed estimator queries the simplex only. We prove that projected gradient descent and the exponential weights algorithm, when run with this estimator instead of exact gradients, converge at a $\mathcal O(T^{-1/4})$ rate.
Regret Minimization with Performative Feedback
Feb 01, 2022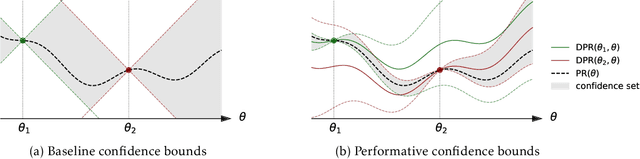
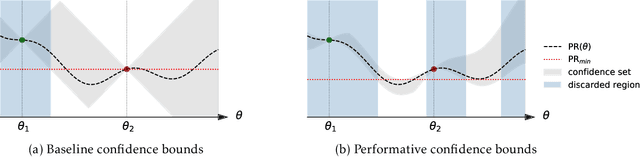
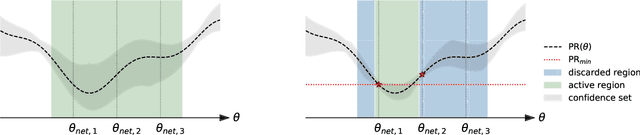
In performative prediction, the deployment of a predictive model triggers a shift in the data distribution. As these shifts are typically unknown ahead of time, the learner needs to deploy a model to get feedback about the distribution it induces. We study the problem of finding near-optimal models under performativity while maintaining low regret. On the surface, this problem might seem equivalent to a bandit problem. However, it exhibits a fundamentally richer feedback structure that we refer to as performative feedback: after every deployment, the learner receives samples from the shifted distribution rather than only bandit feedback about the reward. Our main contribution is regret bounds that scale only with the complexity of the distribution shifts and not that of the reward function. The key algorithmic idea is careful exploration of the distribution shifts that informs a novel construction of confidence bounds on the risk of unexplored models. The construction only relies on smoothness of the shifts and does not assume convexity. More broadly, our work establishes a conceptual approach for leveraging tools from the bandits literature for the purpose of regret minimization with performative feedback.
Who Leads and Who Follows in Strategic Classification?
Jun 23, 2021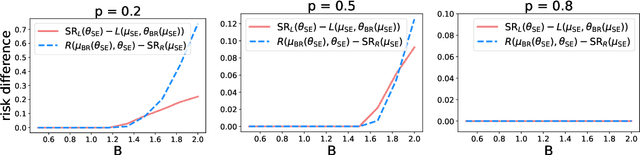
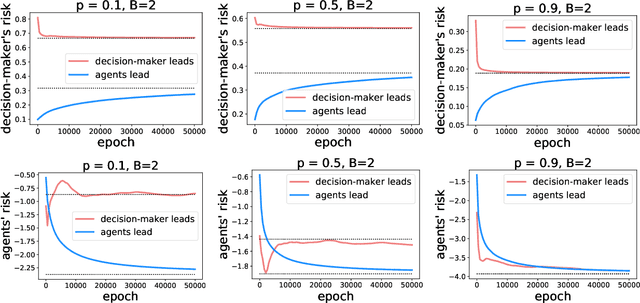
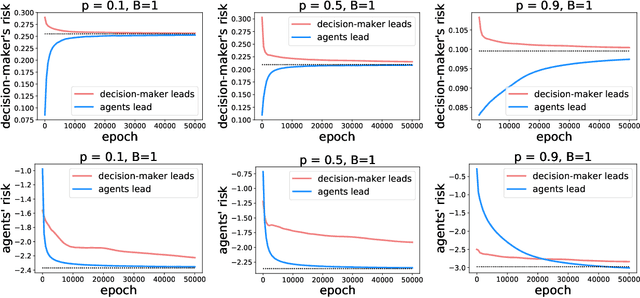
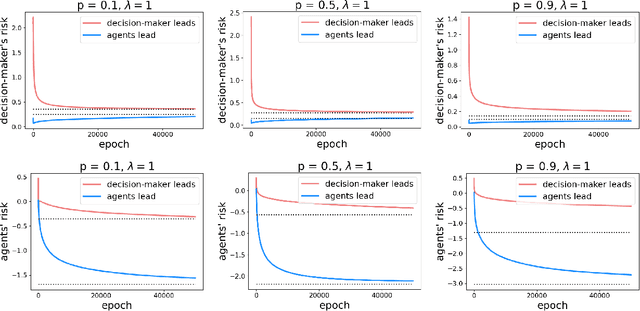
As predictive models are deployed into the real world, they must increasingly contend with strategic behavior. A growing body of work on strategic classification treats this problem as a Stackelberg game: the decision-maker "leads" in the game by deploying a model, and the strategic agents "follow" by playing their best response to the deployed model. Importantly, in this framing, the burden of learning is placed solely on the decision-maker, while the agents' best responses are implicitly treated as instantaneous. In this work, we argue that the order of play in strategic classification is fundamentally determined by the relative frequencies at which the decision-maker and the agents adapt to each other's actions. In particular, by generalizing the standard model to allow both players to learn over time, we show that a decision-maker that makes updates faster than the agents can reverse the order of play, meaning that the agents lead and the decision-maker follows. We observe in standard learning settings that such a role reversal can be desirable for both the decision-maker and the strategic agents. Finally, we show that a decision-maker with the freedom to choose their update frequency can induce learning dynamics that converge to Stackelberg equilibria with either order of play.
Outside the Echo Chamber: Optimizing the Performative Risk
Feb 17, 2021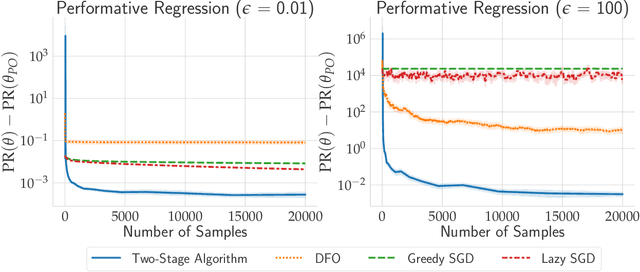
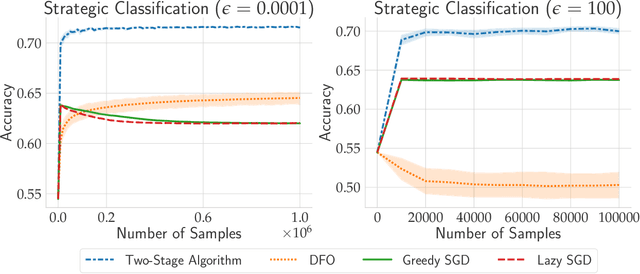
In performative prediction, predictions guide decision-making and hence can influence the distribution of future data. To date, work on performative prediction has focused on finding performatively stable models, which are the fixed points of repeated retraining. However, stable solutions can be far from optimal when evaluated in terms of the performative risk, the loss experienced by the decision maker when deploying a model. In this paper, we shift attention beyond performative stability and focus on optimizing the performative risk directly. We identify a natural set of properties of the loss function and model-induced distribution shift under which the performative risk is convex, a property which does not follow from convexity of the loss alone. Furthermore, we develop algorithms that leverage our structural assumptions to optimize the performative risk with better sample efficiency than generic methods for derivative-free convex optimization.
Private Prediction Sets
Feb 11, 2021
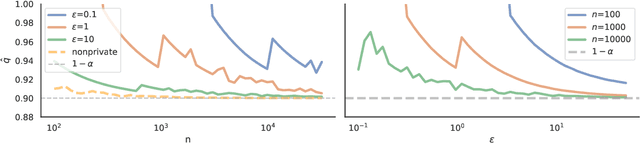
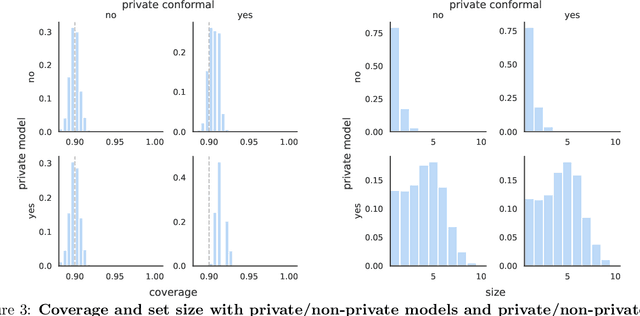
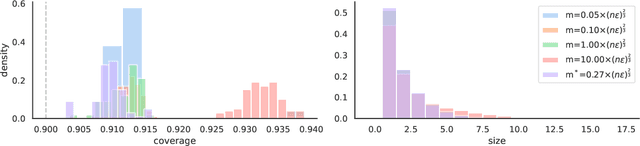
In real-world settings involving consequential decision-making, the deployment of machine learning systems generally requires both reliable uncertainty quantification and protection of individuals' privacy. We present a framework that treats these two desiderata jointly. Our framework is based on conformal prediction, a methodology that augments predictive models to return prediction sets that provide uncertainty quantification -- they provably cover the true response with a user-specified probability, such as 90%. One might hope that when used with privately-trained models, conformal prediction would yield privacy guarantees for the resulting prediction sets; unfortunately this is not the case. To remedy this key problem, we develop a method that takes any pre-trained predictive model and outputs differentially private prediction sets. Our method follows the general approach of split conformal prediction; we use holdout data to calibrate the size of the prediction sets but preserve privacy by using a privatized quantile subroutine. This subroutine compensates for the noise introduced to preserve privacy in order to guarantee correct coverage. We evaluate the method with experiments on the CIFAR-10, ImageNet, and CoronaHack datasets.