 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoSQL: A Conversational Text-to-SQL Challenge Towards Cross-Domain Natural Language Interfaces to Databases
Sep 11, 2019
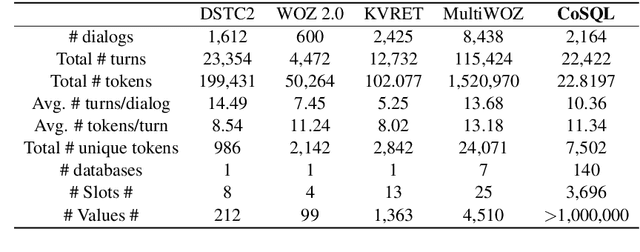
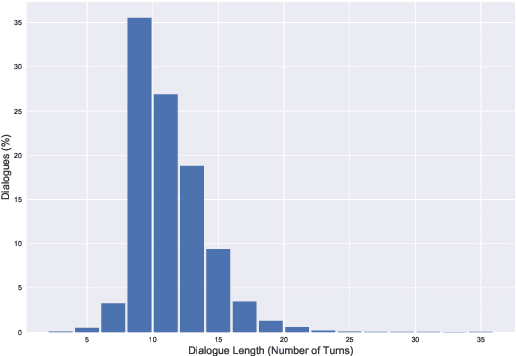
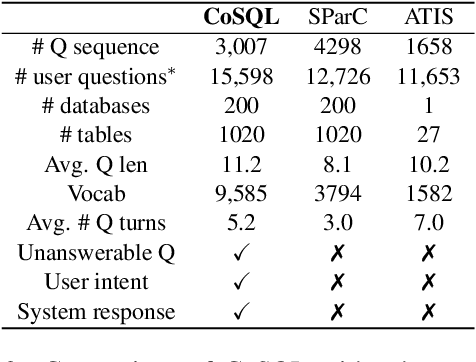
We present CoSQL, a corpus for building cross-domain, general-purpose database (DB) querying dialogue systems. It consists of 30k+ turns plus 10k+ annotated SQL queries, obtained from a Wizard-of-Oz (WOZ) collection of 3k dialogues querying 200 complex DBs spanning 138 domains. Each dialogue simulates a real-world DB query scenario with a crowd worker as a user exploring the DB and a SQL expert retrieving answers with SQL, clarifying ambiguous questions, or otherwise informing of unanswerable questions. When user questions are answerable by SQL, the expert describes the SQL and execution results to the user, hence maintaining a natural interaction flow. CoSQL introduces new challenges compared to existing task-oriented dialogue datasets:(1) the dialogue states are grounded in SQL, a domain-independent executable representation, instead of domain-specific slot-value pairs, and (2) because testing is done on unseen databases, success requires generalizing to new domains. CoSQL includes three tasks: SQL-grounded dialogue state tracking, response generation from query results, and user dialogue act prediction. We evaluate a set of strong baselines for each task and show that CoSQL presents significant challenges for future research. The dataset, baselines, and leaderboard will be released at https://yale-lily.github.io/cosql.
Editing-Based SQL Query Generation for Cross-Domain Context-Dependent Questions
Sep 10, 2019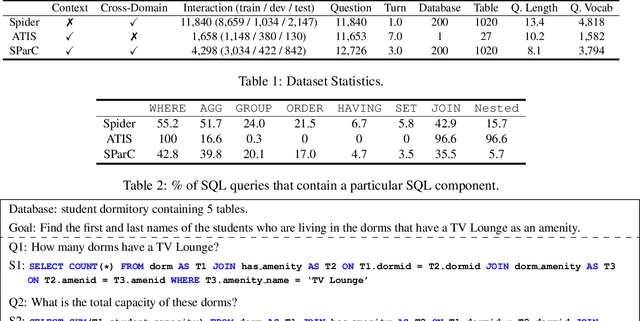
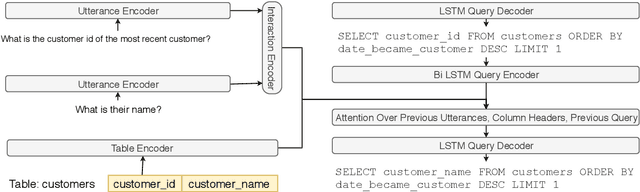
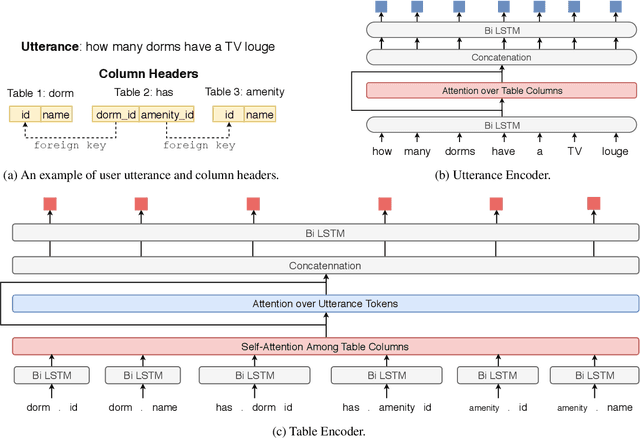
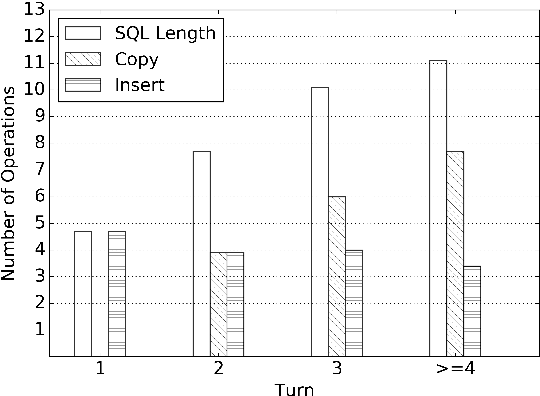
We focus on the cross-domain context-dependent text-to-SQL generation task. Based on the observation that adjacent natural language questions are often linguistically dependent and their corresponding SQL queries tend to overlap, we utilize the interaction history by editing the previous predicted query to improve the generation quality. Our editing mechanism views SQL as sequences and reuses generation results at the token level in a simple manner. It is flexible to change individual tokens and robust to error propagation. Furthermore, to deal with complex table structures in different domains, we employ an utterance-table encoder and a table-aware decoder to incorporate the context of the user utterance and the table schema. We evaluate our approach on the SParC dataset and demonstrate the benefit of editing compared with the state-of-the-art baselines which generate SQL from scratch. Our code is available at https://github.com/ryanzhumich/sparc_atis_pytorch.
IncSQL: Training Incremental Text-to-SQL Parsers with Non-Deterministic Oracles
Oct 01, 2018

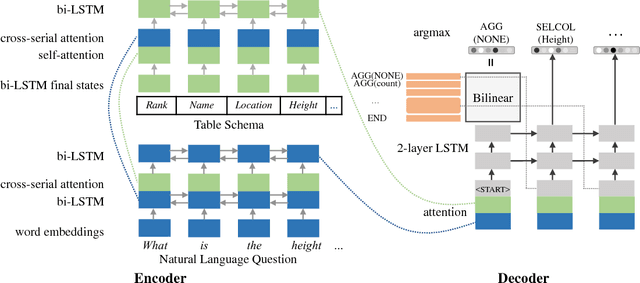
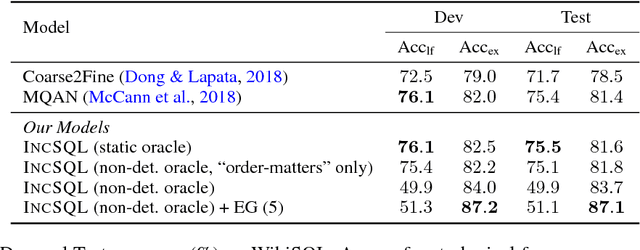
We present a sequence-to-action parsing approach for the natural language to SQL task that incrementally fills the slots of a SQL query with feasible actions from a pre-defined inventory. To account for the fact that typically there are multiple correct SQL queries with the same or very similar semantics, we draw inspiration from syntactic parsing techniques and propose to train our sequence-to-action models with non-deterministic oracles. We evaluate our models on the WikiSQL dataset and achieve an execution accuracy of 83.7% on the test set, a 2.1% absolute improvement over the models trained with traditional static oracles assuming a single correct target SQL query. When further combined with the execution-guided decoding strategy, our model sets a new state-of-the-art performance at an execution accuracy of 87.1%.
Global Transition-based Non-projective Dependency Parsing
Jul 04, 2018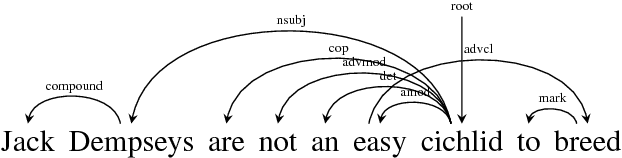


Shi, Huang, and Lee (2017) obtained state-of-the-art results for English and Chinese dependency parsing by combining dynamic-programming implementations of transition-based dependency parsers with a minimal set of bidirectional LSTM features. However, their results were limited to projective parsing. In this paper, we extend their approach to support non-projectivity by providing the first practical implementation of the MH_4 algorithm, an $O(n^4)$ mildly nonprojective dynamic-programming parser with very high coverage on non-projective treebanks. To make MH_4 compatible with minimal transition-based feature sets, we introduce a transition-based interpretation of it in which parser items are mapped to sequences of transitions. We thus obtain the first implementation of global decoding for non-projective transition-based parsing, and demonstrate empirically that it is more effective than its projective counterpart in parsing a number of highly non-projective languages
* Proceedings of ACL 2018. 13 pages
Improving Coverage and Runtime Complexity for Exact Inference in Non-Projective Transition-Based Dependency Parsers
May 02, 2018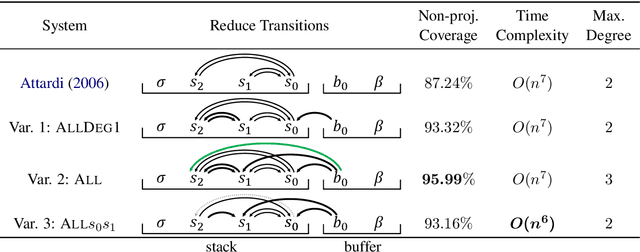
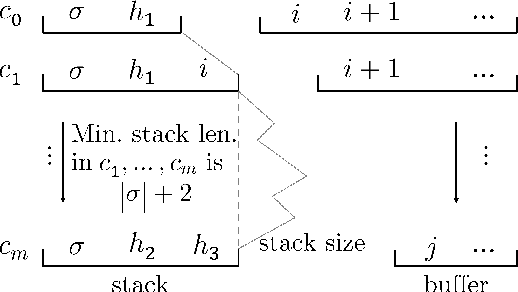
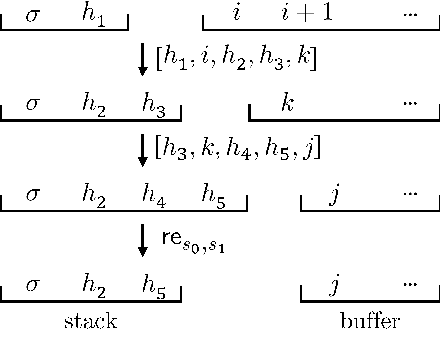
We generalize Cohen, G\'omez-Rodr\'iguez, and Satta's (2011) parser to a family of non-projective transition-based dependency parsers allowing polynomial-time exact inference. This includes novel parsers with better coverage than Cohen et al. (2011), and even a variant that reduces time complexity to $O(n^6)$, improving over the known bounds in exact inference for non-projective transition-based parsing. We hope that this piece of theoretical work inspires design of novel transition systems with better coverage and better run-time guarantees. Code available at https://github.com/tzshi/nonproj-dp-variants-naacl2018
* Proceedings of NAACL-HLT 2018. 6 pages. This version fixes display issue in an author name
Fast Exact Decoding and Global Training for Transition-Based Dependency Parsing via a Minimal Feature Set
Aug 30, 2017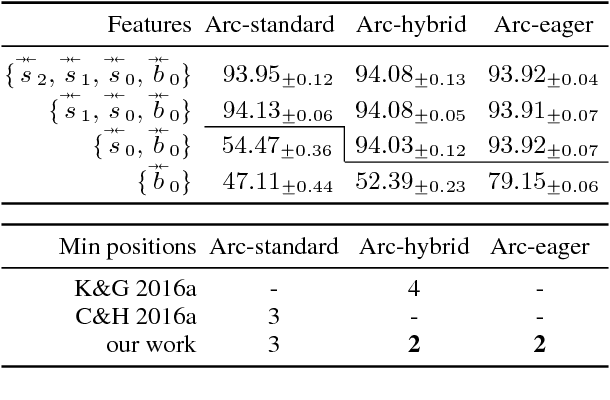
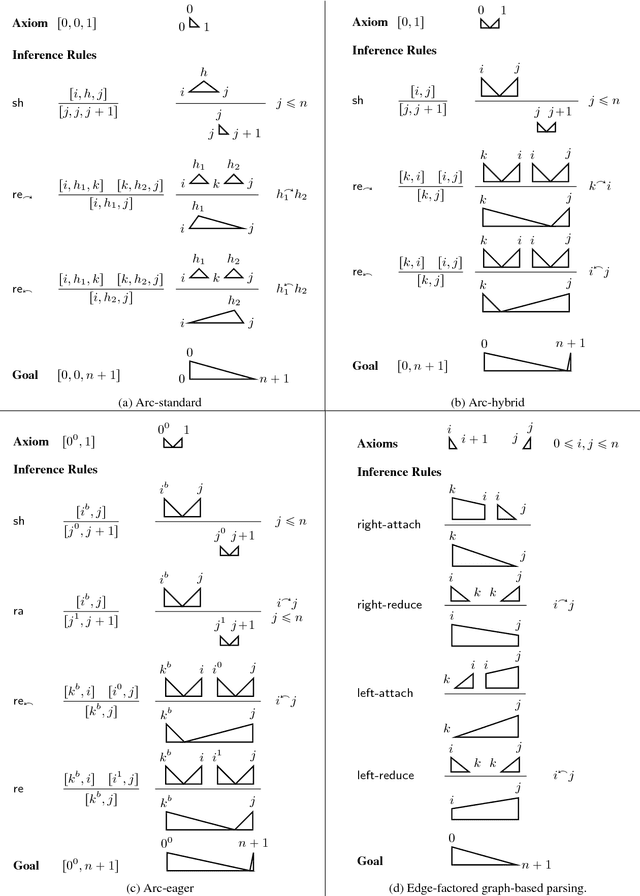
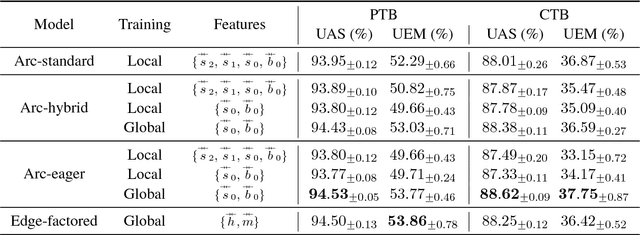
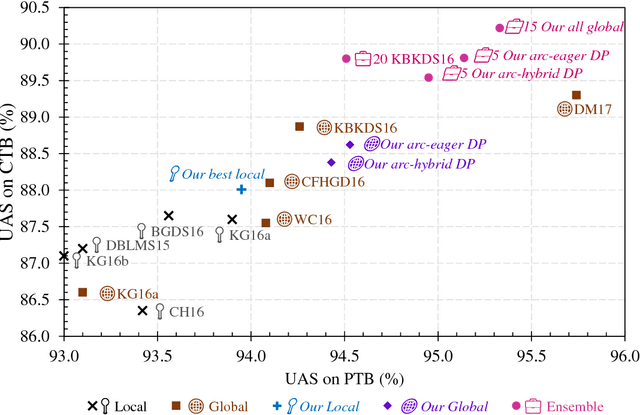
We first present a minimal feature set for transition-based dependency parsing, continuing a recent trend started by Kiperwasser and Goldberg (2016a) and Cross and Huang (2016a) of using bi-directional LSTM features. We plug our minimal feature set into the dynamic-programming framework of Huang and Sagae (2010) and Kuhlmann et al. (2011) to produce the first implementation of worst-case O(n^3) exact decoders for arc-hybrid and arc-eager transition systems. With our minimal features, we also present O(n^3) global training methods. Finally, using ensembles including our new parsers, we achieve the best unlabeled attachment score reported (to our knowledge) on the Chinese Treebank and the "second-best-in-class" result on the English Penn Treebank.
* Proceedings of EMNLP, 2017. 12 pages
Linking GloVe with word2vec
Nov 26, 2014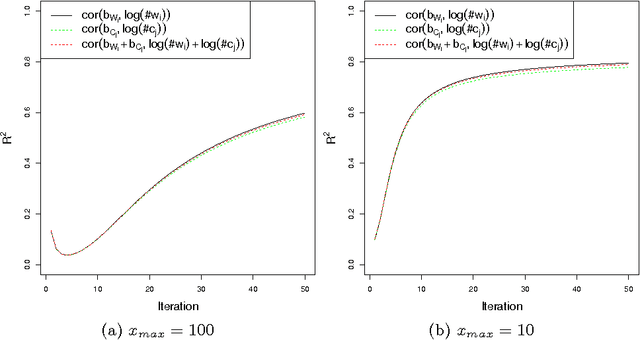
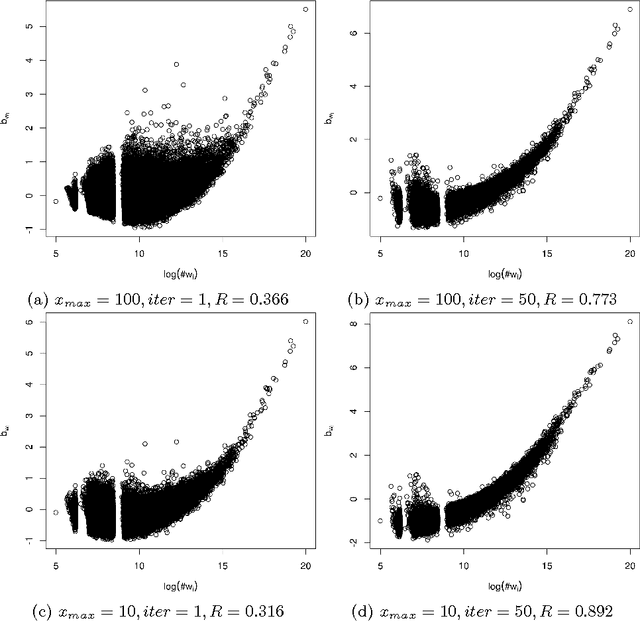
The Global Vectors for word representation (GloVe), introduced by Jeffrey Pennington et al. is reported to be an efficient and effective method for learning vector representations of words. State-of-the-art performance is also provided by skip-gram with negative-sampling (SGNS) implemented in the word2vec tool. In this note, we explain the similarities between the training objectives of the two models, and show that the objective of SGNS is similar to the objective of a specialized form of GloVe, though their cost functions are defined differently.