 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoBoSR: Structured Scene Representations for Embodied Robotic Reasoning
Jun 23, 2026Despite rapid progress, embodied reasoning under real-world variability remains challenging. Existing approaches rely on demonstration-driven sequential biases, limiting flexibility in open-ended and long-horizon tasks that require structured reasoning over evolving states. We introduce RoBoSR, an intermediate structural representation that formulates manipulation as step-wise state transitions over semantically grounded, object-centric scene graphs. By modeling object states and their spatial relations at the perception-action interface, RoBoSR disentangles high-level task reasoning from raw inputs and enables structured reasoning over preconditions, effects, and goal states. This representation endows the agent with causal reasoning capability, enforcing subtask dependencies and supporting coherent long-horizon task planning. To learn such structure-aware reasoning, we construct Manip-Cognition-1.6M, an open-world dataset that jointly supervises scene understanding, instruction interpretation, and subtask planning across diverse tasks. Across several benchmarks and real-world demonstrations, our method consistently outperforms prompting-based methods and classical TAMP baselines in zero-shot generalization and long-horizon tasks. The results underscore structured intermediate representations as a critical inductive bias for scalable embodied reasoning.
FREE-Switch: Frequency-based Dynamic LoRA Switch for Style Transfer
Apr 11, 2026With the growing availability of open-sourced adapters trained on the same diffusion backbone for diverse scenes and objects, combining these pretrained weights enables low-cost customized generation. However, most existing model merging methods are designed for classification or text generation, and when applied to image generation, they suffer from content drift due to error accumulation across multiple diffusion steps. For image-oriented methods, training-based approaches are computationally expensive and unsuitable for edge deployment, while training-free ones use uniform fusion strategies that ignore inter-adapter differences, leading to detail degradation. We find that since different adapters are specialized for generating different types of content, the contribution of each diffusion step carries different significance for each adapter. Accordingly, we propose a frequency-domain importance-driven dynamic LoRA switch method. Furthermore, we observe that maintaining semantic consistency across adapters effectively mitigates detail loss; thus, we design an automatic Generation Alignment mechanism to align generation intents at the semantic level. Experiments demonstrate that our FREE-Switch (Frequency-based Efficient and Dynamic LoRA Switch) framework efficiently combines adapters for different objects and styles, substantially reducing the training cost of high-quality customized generation.
NeuroLoRA: Context-Aware Neuromodulation for Parameter-Efficient Multi-Task Adaptation
Mar 12, 2026Parameter-Efficient Fine-Tuning (PEFT) techniques, particularly Low-Rank Adaptation (LoRA), have become essential for adapting Large Language Models (LLMs) to downstream tasks. While the recent FlyLoRA framework successfully leverages bio-inspired sparse random projections to mitigate parameter interference, it relies on a static, magnitude-based routing mechanism that is agnostic to input context. In this paper, we propose NeuroLoRA, a novel Mixture-of-Experts (MoE) based LoRA framework inspired by biological neuromodulation -- the dynamic regulation of neuronal excitability based on context. NeuroLoRA retains the computational efficiency of frozen random projections while introducing a lightweight, learnable neuromodulation gate that contextually rescales the projection space prior to expert selection. We further propose a Contrastive Orthogonality Loss to explicitly enforce separation between expert subspaces, enhancing both task decoupling and continual learning capacity. Extensive experiments on MMLU, GSM8K, and ScienceQA demonstrate that NeuroLoRA consistently outperforms FlyLoRA and other strong baselines across single-task adaptation, multi-task model merging, and sequential continual learning scenarios, while maintaining comparable parameter efficiency.
GSR: Learning Structured Reasoning for Embodied Manipulation
Feb 02, 2026Despite rapid progress, embodied agents still struggle with long-horizon manipulation that requires maintaining spatial consistency, causal dependencies, and goal constraints. A key limitation of existing approaches is that task reasoning is implicitly embedded in high-dimensional latent representations, making it challenging to separate task structure from perceptual variability. We introduce Grounded Scene-graph Reasoning (GSR), a structured reasoning paradigm that explicitly models world-state evolution as transitions over semantically grounded scene graphs. By reasoning step-wise over object states and spatial relations, rather than directly mapping perception to actions, GSR enables explicit reasoning about action preconditions, consequences, and goal satisfaction in a physically grounded space. To support learning such reasoning, we construct Manip-Cognition-1.6M, a large-scale dataset that jointly supervises world understanding, action planning, and goal interpretation. Extensive evaluations across RLBench, LIBERO, GSR-benchmark, and real-world robotic tasks show that GSR significantly improves zero-shot generalization and long-horizon task completion over prompting-based baselines. These results highlight explicit world-state representations as a key inductive bias for scalable embodied reasoning.
PGN: The RNN's New Successor is Effective for Long-Range Time Series Forecasting
Sep 26, 2024



Due to the recurrent structure of RNN, the long information propagation path poses limitations in capturing long-term dependencies, gradient explosion/vanishing issues, and inefficient sequential execution. Based on this, we propose a novel paradigm called Parallel Gated Network (PGN) as the new successor to RNN. PGN directly captures information from previous time steps through the designed Historical Information Extraction (HIE) layer and leverages gated mechanisms to select and fuse it with the current time step information. This reduces the information propagation path to $\mathcal{O}(1)$, effectively addressing the limitations of RNN. To enhance PGN's performance in long-range time series forecasting tasks, we propose a novel temporal modeling framework called Temporal PGN (TPGN). TPGN incorporates two branches to comprehensively capture the semantic information of time series. One branch utilizes PGN to capture long-term periodic patterns while preserving their local characteristics. The other branch employs patches to capture short-term information and aggregate the global representation of the series. TPGN achieves a theoretical complexity of $\mathcal{O}(\sqrt{L})$, ensuring efficiency in its operations. Experimental results on five benchmark datasets demonstrate the state-of-the-art (SOTA) performance and high efficiency of TPGN, further confirming the effectiveness of PGN as the new successor to RNN in long-range time series forecasting. The code is available in this repository: \url{https://github.com/Water2sea/TPGN}.
Pheno-Robot: An Auto-Digital Modelling System for In-Situ Phenotyping in the Field
Feb 15, 2024



Accurate reconstruction of plant models for phenotyping analysis is critical for optimising sustainable agricultural practices in precision agriculture. Traditional laboratory-based phenotyping, while valuable, falls short of understanding how plants grow under uncontrolled conditions. Robotic technologies offer a promising avenue for large-scale, direct phenotyping in real-world environments. This study explores the deployment of emerging robotics and digital technology in plant phenotyping to improve performance and efficiency. Three critical functional modules: environmental understanding, robotic motion planning, and in-situ phenotyping, are introduced to automate the entire process. Experimental results demonstrate the effectiveness of the system in agricultural environments. The pheno-robot system autonomously collects high-quality data by navigating around plants. In addition, the in-situ modelling model reconstructs high-quality plant models from the data collected by the robot. The developed robotic system shows high efficiency and robustness, demonstrating its potential to advance plant science in real-world agricultural environments.
FM-AE: Frequency-masked Multimodal Autoencoder for Zinc Electrolysis Plate Contact Abnormality Detection
Jan 08, 2024Zinc electrolysis is one of the key processes in zinc smelting, and maintaining stable operation of zinc electrolysis is an important factor in ensuring production efficiency and product quality. However, poor contact between the zinc electrolysis cathode and the anode is a common problem that leads to reduced production efficiency and damage to the electrolysis cell. Therefore, online monitoring of the contact status of the plates is crucial for ensuring production quality and efficiency. To address this issue, we propose an end-to-end network, the Frequency-masked Multimodal Autoencoder (FM-AE). This method takes the cell voltage signal and infrared image information as input, and through automatic encoding, fuses the two features together and predicts the poor contact status of the plates through a cascaded detector. Experimental results show that the proposed method maintains high accuracy (86.2%) while having good robustness and generalization ability, effectively detecting poor contact status of the zinc electrolysis cell, providing strong support for production practice.
Design and Challenges of Cloze-Style Reading Comprehension Tasks on Multiparty Dialogue
Nov 02, 2019
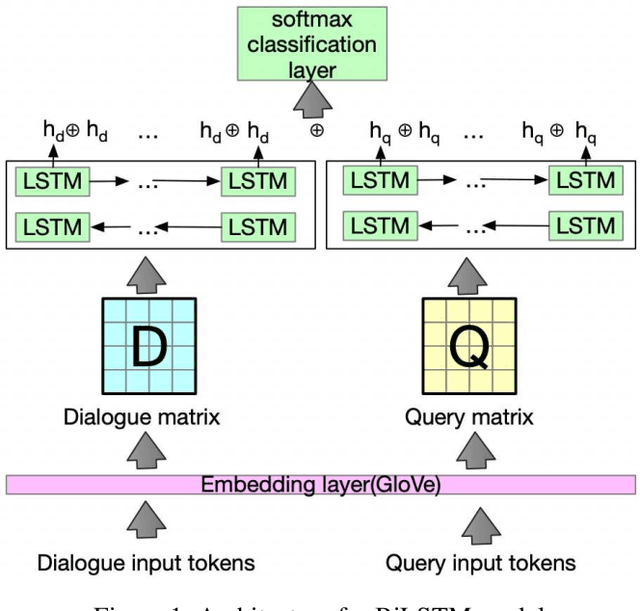
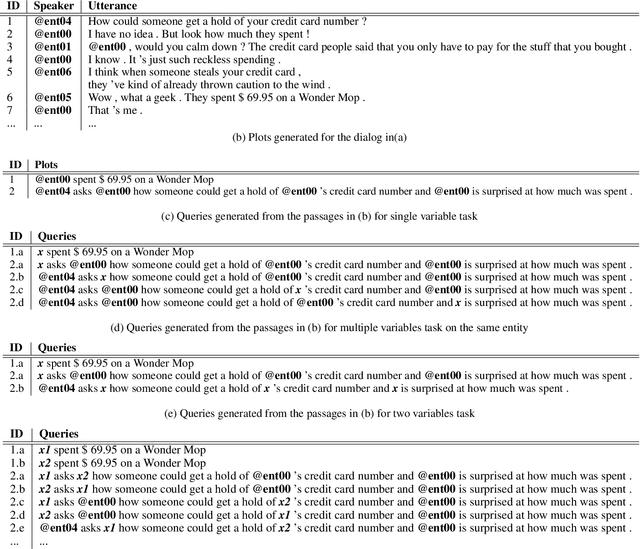
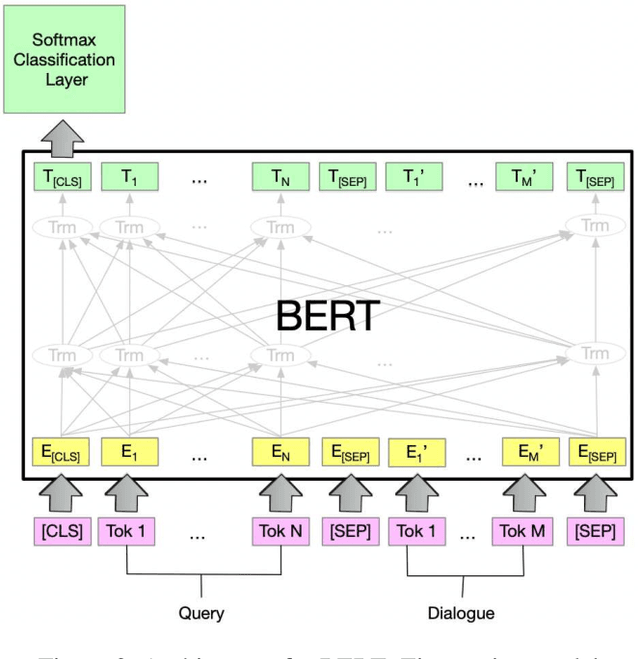
This paper analyzes challenges in cloze-style reading comprehension on multiparty dialogue and suggests two new tasks for more comprehensive predictions of personal entities in daily conversations. We first demonstrate that there are substantial limitations to the evaluation methods of previous work, namely that randomized assignment of samples to training and test data substantially decreases the complexity of cloze-style reading comprehension. According to our analysis, replacing the random data split with a chronological data split reduces test accuracy on previous single-variable passage completion task from 72\% to 34\%, that leaves much more room to improve. Our proposed tasks extend the previous single-variable passage completion task by replacing more character mentions with variables. Several deep learning models are developed to validate these three tasks. A thorough error analysis is provided to understand the challenges and guide the future direction of this research.