 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNearly Optimal Robust Method for Convex Compositional Problems with Heavy-Tailed Noise
Jun 17, 2020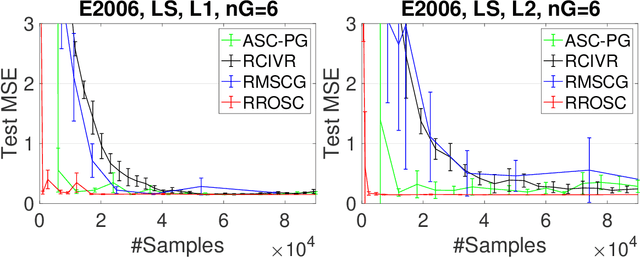
In this paper, we propose robust stochastic algorithms for solving convex compositional problems of the form $f(\E_\xi g(\cdot; \xi)) + r(\cdot)$ by establishing {\bf sub-Gaussian confidence bounds} under weak assumptions about the tails of noise distribution, i.e., {\bf heavy-tailed noise} with bounded second-order moments. One can achieve this goal by using an existing boosting strategy that boosts a low probability convergence result into a high probability result. However, piecing together existing results for solving compositional problems suffers from several drawbacks: (i) the boosting technique requires strong convexity of the objective; (ii) it requires a separate algorithm to handle non-smooth $r$; (iii) it also suffers from an additional polylogarithmic factor of the condition number. To address these issues, we directly develop a single-trial stochastic algorithm for minimizing optimal strongly convex compositional objectives, which has a nearly optimal high probability convergence result matching the lower bound of stochastic strongly convex optimization up to a logarithmic factor. To the best of our knowledge, this is the first work that establishes nearly optimal sub-Gaussian confidence bounds for compositional problems under heavy-tailed assumptions.
Communication-Efficient Distributed Stochastic AUC Maximization with Deep Neural Networks
May 05, 2020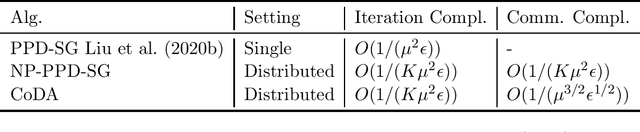
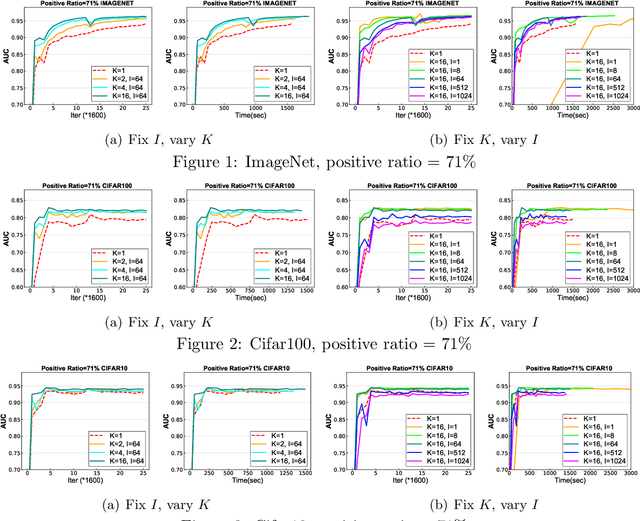
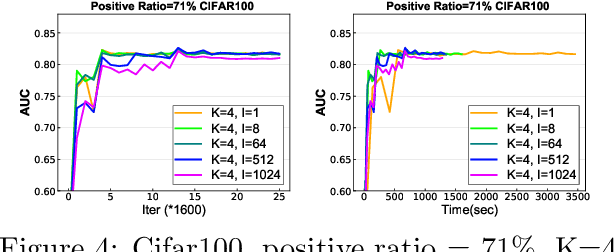
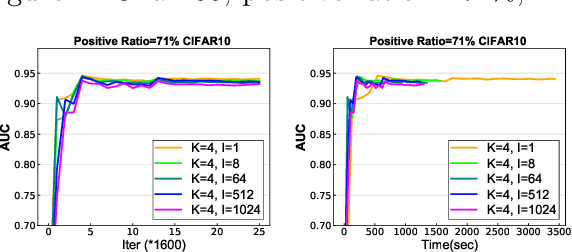
In this paper, we study distributed algorithms for large-scale AUC maximization with a deep neural network as a predictive model. Although distributed learning techniques have been investigated extensively in deep learning, they are not directly applicable to stochastic AUC maximization with deep neural networks due to its striking differences from standard loss minimization problems (e.g., cross-entropy). Towards addressing this challenge, we propose and analyze a communication-efficient distributed optimization algorithm based on a {\it non-convex concave} reformulation of the AUC maximization, in which the communication of both the primal variable and the dual variable between each worker and the parameter server only occurs after multiple steps of gradient-based updates in each worker. Compared with the naive parallel version of an existing algorithm that computes stochastic gradients at individual machines and averages them for updating the model parameter, our algorithm requires a much less number of communication rounds and still achieves a linear speedup in theory. To the best of our knowledge, this is the \textbf{first} work that solves the {\it non-convex concave min-max} problem for AUC maximization with deep neural networks in a communication-efficient distributed manner while still maintaining the linear speedup property in theory. Our experiments on several benchmark datasets show the effectiveness of our algorithm and also confirm our theory.
Revisiting SGD with Increasingly Weighted Averaging: Optimization and Generalization Perspectives
Mar 09, 2020
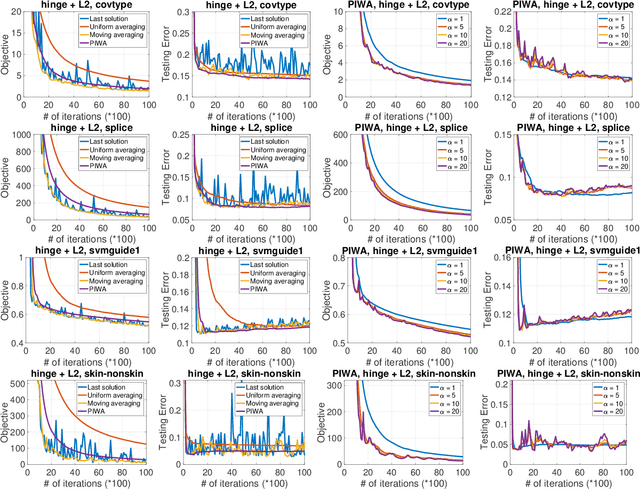
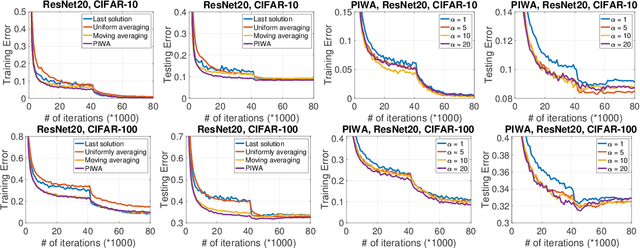
Stochastic gradient descent (SGD) has been widely studied in the literature from different angles, and is commonly employed for solving many big data machine learning problems. However, the averaging technique, which combines all iterative solutions into a single solution, is still under-explored. While some increasingly weighted averaging schemes have been considered in the literature, existing works are mostly restricted to strongly convex objective functions and the convergence of optimization error. It remains unclear how these averaging schemes affect the convergence of {\it both optimization error and generalization error} (two equally important components of testing error) for {\bf non-strongly convex objectives, including non-convex problems}. In this paper, we {\it fill the gap} by comprehensively analyzing the increasingly weighted averaging on convex, strongly convex and non-convex objective functions in terms of both optimization error and generalization error. In particular, we analyze a family of increasingly weighted averaging, where the weight for the solution at iteration $t$ is proportional to $t^{\alpha}$ ($\alpha > 0$). We show how $\alpha$ affects the optimization error and the generalization error, and exhibit the trade-off caused by $\alpha$. Experiments have demonstrated this trade-off and the effectiveness of polynomially increased weighted averaging compared with other averaging schemes for a wide range of problems including deep learning.
Sharp Analysis of Epoch Stochastic Gradient Descent Ascent Methods for Min-Max Optimization
Feb 13, 2020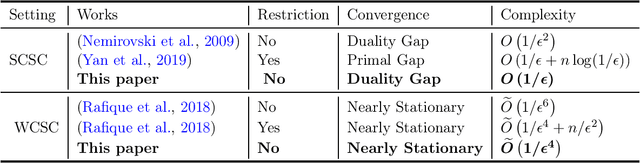
Epoch gradient descent method (a.k.a. Epoch-GD) proposed by (Hazan and Kale, 2011) was deemed a breakthrough for stochastic strongly convex minimization, which achieves the optimal convergence rate of O(1/T) with T iterative updates for the objective gap. However, its extension to solving stochastic min-max problems with strong convexity and strong concavity still remains open, and it is still unclear whether a fast rate of O(1/T) for the duality gap is achievable for stochastic min-max optimization under strong convexity and strong concavity. Although some recent studies have proposed stochastic algorithms with fast convergence rates for min-max problems, they require additional assumptions about the problem, e.g., smoothness, bi-linear structure, etc. In this paper, we bridge this gap by providing a sharp analysis of epoch-wise stochastic gradient descent ascent method (referred to as Epoch-GDA) for solving strongly convex strongly concave (SCSC) min-max problems, without imposing any additional assumptions about smoothness or its structure. To the best of our knowledge, our result is the first one that shows Epoch-GDA can achieve the fast rate of O(1/T) for the duality gap of general SCSC min-max problems. We emphasize that such generalization of Epoch-GD for strongly convex minimization problems to Epoch-GDA for SCSC min-max problems is non-trivial and requires novel technical analysis. Moreover, we notice that the key lemma can be also used for proving the convergence of Epoch-GDA for weakly-convex strongly-concave min-max problems, leading to the best complexity as well without smoothness or other structural conditions.
Minimizing Dynamic Regret and Adaptive Regret Simultaneously
Feb 06, 2020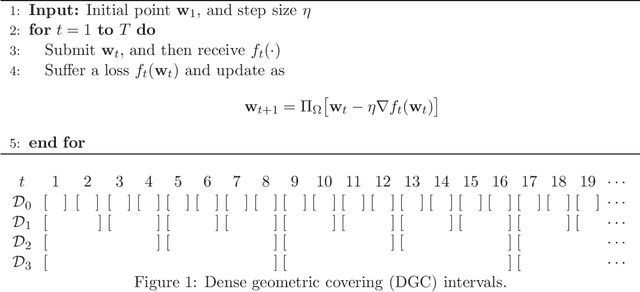
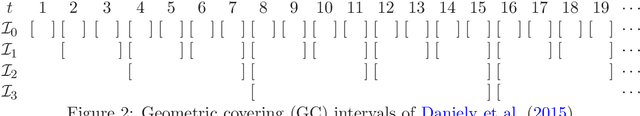
Regret minimization is treated as the golden rule in the traditional study of online learning. However, regret minimization algorithms tend to converge to the static optimum, thus being suboptimal for changing environments. To address this limitation, new performance measures, including dynamic regret and adaptive regret have been proposed to guide the design of online algorithms. The former one aims to minimize the global regret with respect to a sequence of changing comparators, and the latter one attempts to minimize every local regret with respect to a fixed comparator. Existing algorithms for dynamic regret and adaptive regret are developed independently, and only target one performance measure. In this paper, we bridge this gap by proposing novel online algorithms that are able to minimize the dynamic regret and adaptive regret simultaneously. In fact, our theoretical guarantee is even stronger in the sense that one algorithm is able to minimize the dynamic regret over any interval.
A Simple and Effective Framework for Pairwise Deep Metric Learning
Jan 11, 2020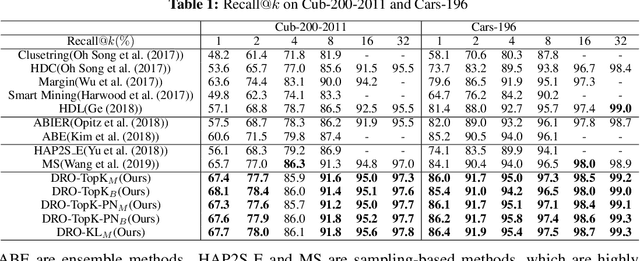
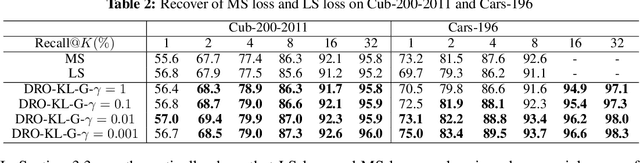
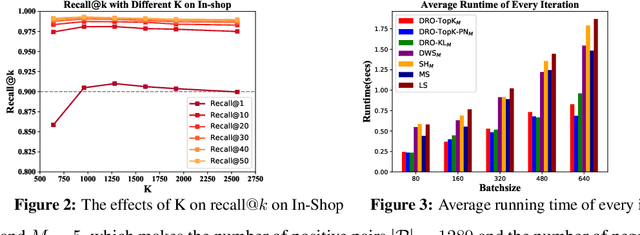
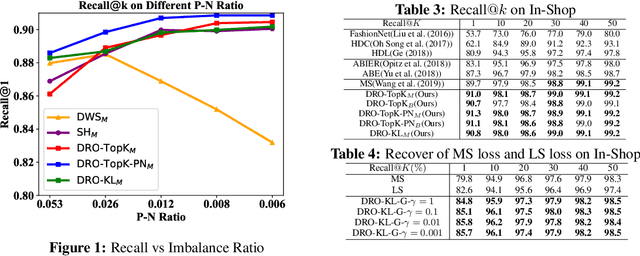
Deep metric learning (DML) has received much attention in deep learning due to its wide applications in computer vision. Previous studies have focused on designing complicated losses and hard example mining methods, which are mostly heuristic and lack of theoretical understanding. In this paper, we cast DML as a simple pairwise binary classification problem that classifies a pair of examples as similar or dissimilar. It identifies the most critical issue in this problem--imbalanced data pairs. To tackle this issue, we propose a simple and effective framework to sample pairs in a batch of data for updating the model. The key to this framework is to define a robust loss for all pairs over a mini-batch of data, which is formulated by distributionally robust optimization. The flexibility in constructing the uncertainty decision set of the dual variable allows us to recover state-of-the-art complicated losses and also to induce novel variants. Empirical studies on several benchmark data sets demonstrate that our simple and effective method outperforms the state-of-the-art results. Codes are available at: https://github.com/qiqi-helloworld/A-Simple-and-Effective-Framework-for-Pairewise-Distance-Metric-Learning
Towards Better Understanding of Adaptive Gradient Algorithms in Generative Adversarial Nets
Dec 26, 2019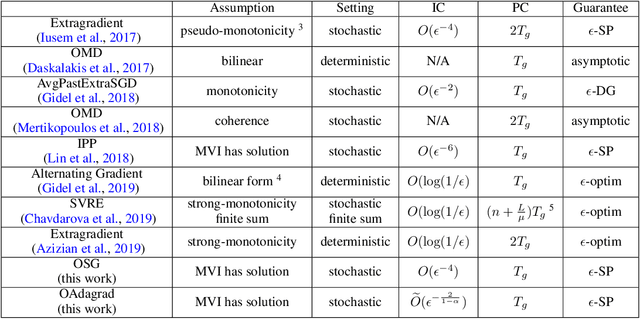
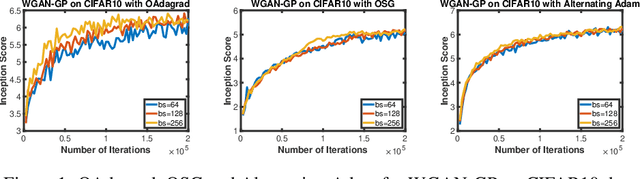
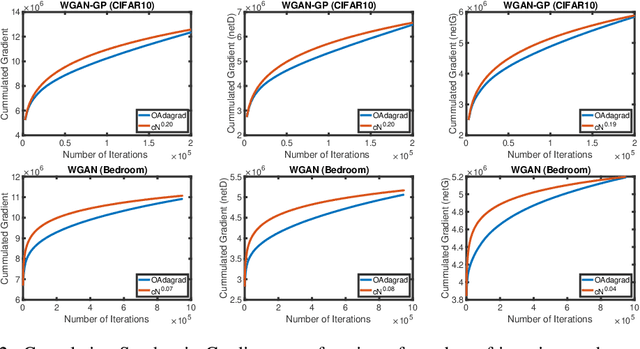
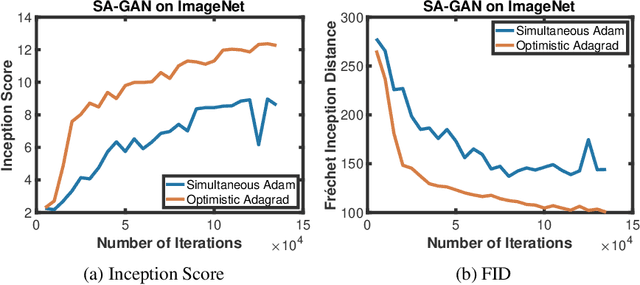
Adaptive gradient algorithms perform gradient-based updates using the history of gradients and are ubiquitous in training deep neural networks. While adaptive gradient methods theory is well understood for minimization problems, the underlying factors driving their empirical success in min-max problems such as GANs remain unclear. In this paper, we aim at bridging this gap from both theoretical and empirical perspectives. First, we analyze a variant of Optimistic Stochastic Gradient (OSG) proposed in~\citep{daskalakis2017training} for solving a class of non-convex non-concave min-max problem and establish $O(\epsilon^{-4})$ complexity for finding $\epsilon$-first-order stationary point, in which the algorithm only requires invoking one stochastic first-order oracle while enjoying state-of-the-art iteration complexity achieved by stochastic extragradient method by~\citep{iusem2017extragradient}. Then we propose an adaptive variant of OSG named Optimistic Adagrad (OAdagrad) and reveal an \emph{improved} adaptive complexity $\widetilde{O}\left(\epsilon^{-\frac{2}{1-\alpha}}\right)$~\footnote{Here $\widetilde{O}(\cdot)$ compresses a logarithmic factor of $\epsilon$.}, where $\alpha$ characterizes the growth rate of the cumulative stochastic gradient and $0\leq \alpha\leq 1/2$. To the best of our knowledge, this is the first work for establishing adaptive complexity in non-convex non-concave min-max optimization. Empirically, our experiments show that indeed adaptive gradient algorithms outperform their non-adaptive counterparts in GAN training. Moreover, this observation can be explained by the slow growth rate of the cumulative stochastic gradient, as observed empirically.
Learning with Long-term Remembering: Following the Lead of Mixed Stochastic Gradient
Oct 31, 2019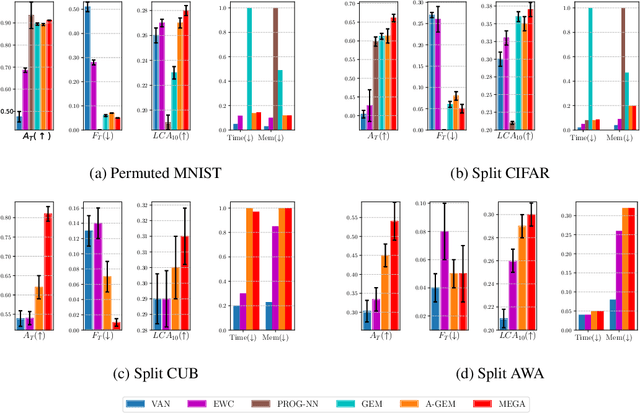
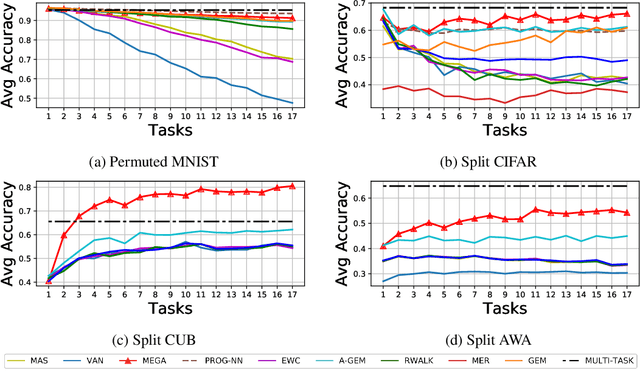

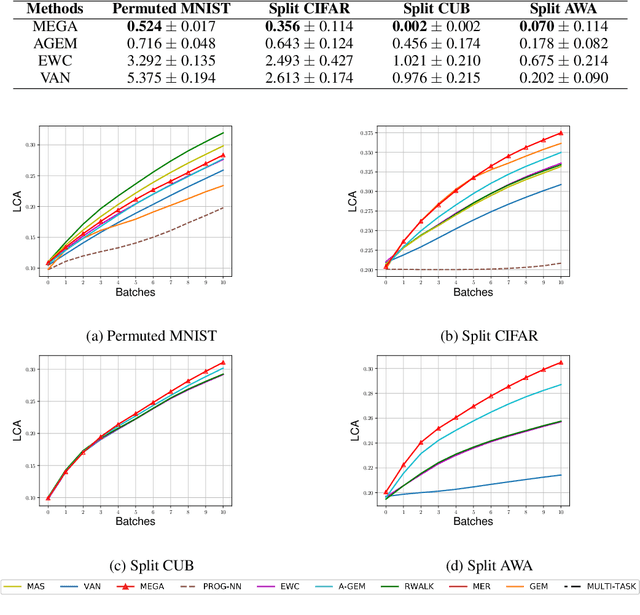
Current deep neural networks can achieve remarkable performance on a single task. However, when the deep neural network is continually trained on a sequence of tasks, it seems to gradually forget the previous learned knowledge. This phenomenon is referred to as catastrophic forgetting and motivates the field called lifelong learning. The central question in lifelong learning is how to enable deep neural networks to maintain performance on old tasks while learning a new task. In this paper, we introduce a novel and effective lifelong learning algorithm, called MixEd stochastic GrAdient (MEGA), which allows deep neural networks to acquire the ability of retaining performance on old tasks while learning new tasks. MEGA modulates the balance between old tasks and the new task by integrating the current gradient with the gradient computed on a small reference episodic memory. Extensive experimental results show that the proposed MEGA algorithm significantly advances the state-of-the-art on all four commonly used lifelong learning benchmarks, reducing the error by up to 18%.
Decentralized Parallel Algorithm for Training Generative Adversarial Nets
Oct 30, 2019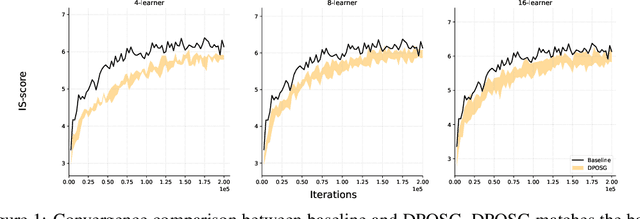
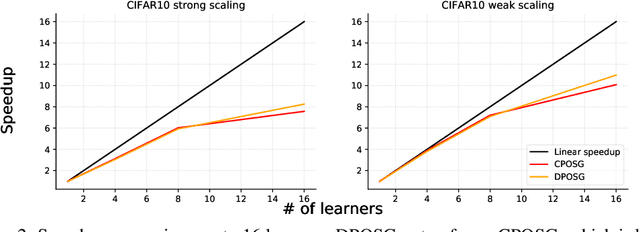
Generative Adversarial Networks (GANs) are powerful class of generative models in the deep learning community. Current practice on large-scale GAN training \cite{brock2018large} utilizes large models and distributed large-batch training strategies, and is implemented on deep learning frameworks (e.g., TensorFlow, PyTorch, etc.) designed in a centralized manner. In the centralized network topology, every worker needs to communicate with the central node. However, when the network bandwidth is low or network latency is high, the performance would be significantly degraded. Despite recent progress on decentralized algorithms for training deep neural networks, it remains unclear whether it is possible to train GANs in a decentralized manner. In this paper, we design a decentralized algorithm for solving a class of non-convex non-concave min-max problem with provable guarantee. Experimental results on GANs demonstrate the effectiveness of the proposed algorithm.
Stochastic AUC Maximization with Deep Neural Networks
Aug 30, 2019

Stochastic AUC maximization has garnered an increasing interest due to better fit to imbalanced data classification. However, existing works are limited to stochastic AUC maximization with a linear predictive model, which restricts its predictive power when dealing with extremely complex data. In this paper, we consider stochastic AUC maximization problem with a deep neural network as the predictive model. Building on the saddle point reformulation of a surrogated loss of AUC, the problem can be cast into a {\it non-convex concave} min-max problem. The main contribution made in this paper is to make stochastic AUC maximization more practical for deep neural networks and big data with theoretical insights as well. In particular, we propose to explore Polyak-\L{}ojasiewicz (PL) condition that has been proved and observed in deep learning, which enables us to develop new stochastic algorithms with even faster convergence rate and more practical step size scheme. An AdaGrad-style algorithm is also analyzed under the PL condition with adaptive convergence rate. Our experimental results demonstrate the effectiveness of the proposed algorithms.