 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Frequency Collaborative Training Network and Dataset for Semi-supervised First Molar Root Canal Segmentation
Apr 16, 2025Root canal (RC) treatment is a highly delicate and technically complex procedure in clinical practice, heavily influenced by the clinicians' experience and subjective judgment. Deep learning has made significant advancements in the field of computer-aided diagnosis (CAD) because it can provide more objective and accurate diagnostic results. However, its application in RC treatment is still relatively rare, mainly due to the lack of public datasets in this field. To address this issue, in this paper, we established a First Molar Root Canal segmentation dataset called FMRC-2025. Additionally, to alleviate the workload of manual annotation for dentists and fully leverage the unlabeled data, we designed a Cross-Frequency Collaborative training semi-supervised learning (SSL) Network called CFC-Net. It consists of two components: (1) Cross-Frequency Collaborative Mean Teacher (CFC-MT), which introduces two specialized students (SS) and one comprehensive teacher (CT) for collaborative multi-frequency training. The CT and SS are trained on different frequency components while fully integrating multi-frequency knowledge through cross and full frequency consistency supervisions. (2) Uncertainty-guided Cross-Frequency Mix (UCF-Mix) mechanism enables the network to generate high-confidence pseudo-labels while learning to integrate multi-frequency information and maintaining the structural integrity of the targets. Extensive experiments on FMRC-2025 and three public dental datasets demonstrate that CFC-MT is effective for RC segmentation and can also exhibit strong generalizability on other dental segmentation tasks, outperforming state-of-the-art SSL medical image segmentation methods. Codes and dataset will be released.
Traffic Adaptive Moving-window Service Patrolling for Real-time Incident Management during High-impact Events
Apr 15, 2025



This paper presents the Traffic Adaptive Moving-window Patrolling Algorithm (TAMPA), designed to improve real-time incident management during major events like sports tournaments and concerts. Such events significantly stress transportation networks, requiring efficient and adaptive patrol solutions. TAMPA integrates predictive traffic modeling and real-time complaint estimation, dynamically optimizing patrol deployment. Using dynamic programming, the algorithm continuously adjusts patrol strategies within short planning windows, effectively balancing immediate response and efficient routing. Leveraging the Dvoretzky-Kiefer-Wolfowitz inequality, TAMPA detects significant shifts in complaint patterns, triggering proactive adjustments in patrol routes. Theoretical analyses ensure performance remains closely aligned with optimal solutions. Simulation results from an urban traffic network demonstrate TAMPA's superior performance, showing improvements of approximately 87.5\% over stationary methods and 114.2\% over random strategies. Future work includes enhancing adaptability and incorporating digital twin technology for improved predictive accuracy, particularly relevant for events like the 2026 FIFA World Cup at MetLife Stadium.
PRAD: Periapical Radiograph Analysis Dataset and Benchmark Model Development
Apr 10, 2025



Deep learning (DL), a pivotal technology in artificial intelligence, has recently gained substantial traction in the domain of dental auxiliary diagnosis. However, its application has predominantly been confined to imaging modalities such as panoramic radiographs and Cone Beam Computed Tomography, with limited focus on auxiliary analysis specifically targeting Periapical Radiographs (PR). PR are the most extensively utilized imaging modality in endodontics and periodontics due to their capability to capture detailed local lesions at a low cost. Nevertheless, challenges such as resolution limitations and artifacts complicate the annotation and recognition of PR, leading to a scarcity of publicly available, large-scale, high-quality PR analysis datasets. This scarcity has somewhat impeded the advancement of DL applications in PR analysis. In this paper, we present PRAD-10K, a dataset for PR analysis. PRAD-10K comprises 10,000 clinical periapical radiograph images, with pixel-level annotations provided by professional dentists for nine distinct anatomical structures, lesions, and artificial restorations or medical devices, We also include classification labels for images with typical conditions or lesions. Furthermore, we introduce a DL network named PRNet to establish benchmarks for PR segmentation tasks. Experimental results demonstrate that PRNet surpasses previous state-of-the-art medical image segmentation models on the PRAD-10K dataset. The codes and dataset will be made publicly available.
Two Heads Are Better than One: Model-Weight and Latent-Space Analysis for Federated Learning on Non-iid Data against Poisoning Attacks
Mar 30, 2025



Federated Learning is a popular paradigm that enables remote clients to jointly train a global model without sharing their raw data. However, FL has been shown to be vulnerable towards model poisoning attacks due to its distributed nature. Particularly, attackers acting as participants can upload arbitrary model updates that effectively compromise the global model of FL. While extensive research has been focusing on fighting against these attacks, we find that most of them assume data at remote clients are under iid while in practice they are inevitably non-iid. Our benchmark evaluations reveal that existing defenses generally fail to live up to their reputation when applied to various non-iid scenarios. In this paper, we propose a novel approach, GeminiGuard, that aims to address such a significant gap. We design GeminiGuard to be lightweight, versatile, and unsupervised so that it aligns well with the practical requirements of deploying such defenses. The key challenge from non-iids is that they make benign model updates look more similar to malicious ones. GeminiGuard is mainly built on two fundamental observations: (1) existing defenses based on either model-weight analysis or latent-space analysis face limitations in covering different MPAs and non-iid scenarios, and (2) model-weight and latent-space analysis are sufficiently different yet potentially complementary methods as MPA defenses. We hence incorporate a novel model-weight analysis component as well as a custom latent-space analysis component in GeminiGuard, aiming to further enhance its defense performance. We conduct extensive experiments to evaluate our defense across various settings, demonstrating its effectiveness in countering multiple types of untargeted and targeted MPAs, including adaptive ones. Our comprehensive evaluations show that GeminiGuard consistently outperforms SOTA defenses under various settings.
Buffer is All You Need: Defending Federated Learning against Backdoor Attacks under Non-iids via Buffering
Mar 30, 2025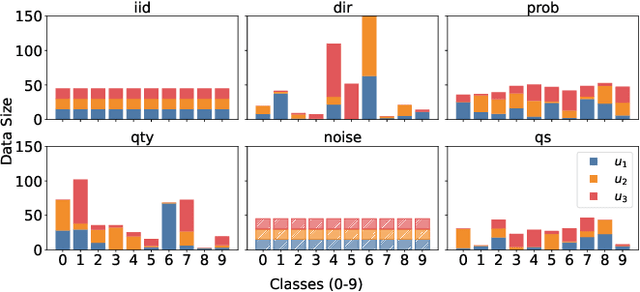
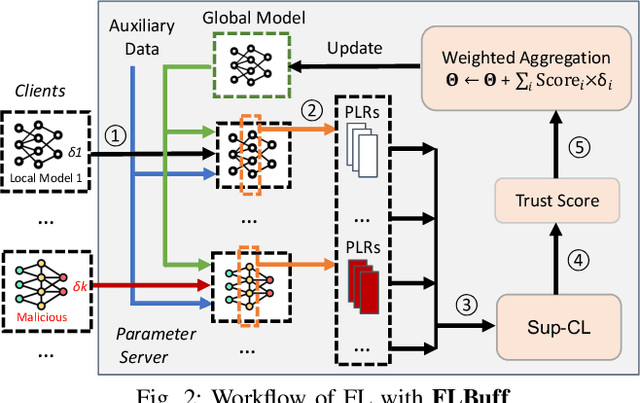
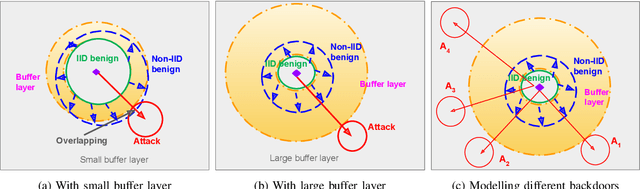
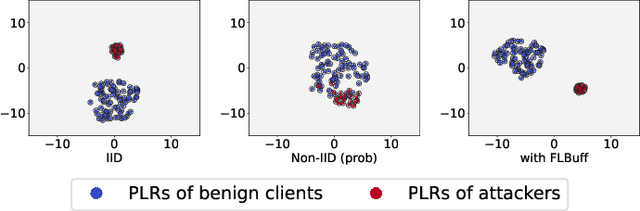
Federated Learning (FL) is a popular paradigm enabling clients to jointly train a global model without sharing raw data. However, FL is known to be vulnerable towards backdoor attacks due to its distributed nature. As participants, attackers can upload model updates that effectively compromise FL. What's worse, existing defenses are mostly designed under independent-and-identically-distributed (iid) settings, hence neglecting the fundamental non-iid characteristic of FL. Here we propose FLBuff for tackling backdoor attacks even under non-iids. The main challenge for such defenses is that non-iids bring benign and malicious updates closer, hence harder to separate. FLBuff is inspired by our insight that non-iids can be modeled as omni-directional expansion in representation space while backdoor attacks as uni-directional. This leads to the key design of FLBuff, i.e., a supervised-contrastive-learning model extracting penultimate-layer representations to create a large in-between buffer layer. Comprehensive evaluations demonstrate that FLBuff consistently outperforms state-of-the-art defenses.
EvalMuse-40K: A Reliable and Fine-Grained Benchmark with Comprehensive Human Annotations for Text-to-Image Generation Model Evaluation
Dec 24, 2024Recently, Text-to-Image (T2I) generation models have achieved significant advancements. Correspondingly, many automated metrics have emerged to evaluate the image-text alignment capabilities of generative models. However, the performance comparison among these automated metrics is limited by existing small datasets. Additionally, these datasets lack the capacity to assess the performance of automated metrics at a fine-grained level. In this study, we contribute an EvalMuse-40K benchmark, gathering 40K image-text pairs with fine-grained human annotations for image-text alignment-related tasks. In the construction process, we employ various strategies such as balanced prompt sampling and data re-annotation to ensure the diversity and reliability of our benchmark. This allows us to comprehensively evaluate the effectiveness of image-text alignment metrics for T2I models. Meanwhile, we introduce two new methods to evaluate the image-text alignment capabilities of T2I models: FGA-BLIP2 which involves end-to-end fine-tuning of a vision-language model to produce fine-grained image-text alignment scores and PN-VQA which adopts a novel positive-negative VQA manner in VQA models for zero-shot fine-grained evaluation. Both methods achieve impressive performance in image-text alignment evaluations. We also use our methods to rank current AIGC models, in which the results can serve as a reference source for future study and promote the development of T2I generation. The data and code will be made publicly available.
Grimm: A Plug-and-Play Perturbation Rectifier for Graph Neural Networks Defending against Poisoning Attacks
Dec 11, 2024



End-to-end training with global optimization have popularized graph neural networks (GNNs) for node classification, yet inadvertently introduced vulnerabilities to adversarial edge-perturbing attacks. Adversaries can exploit the inherent opened interfaces of GNNs' input and output, perturbing critical edges and thus manipulating the classification results. Current defenses, due to their persistent utilization of global-optimization-based end-to-end training schemes, inherently encapsulate the vulnerabilities of GNNs. This is specifically evidenced in their inability to defend against targeted secondary attacks. In this paper, we propose the Graph Agent Network (GAgN) to address the aforementioned vulnerabilities of GNNs. GAgN is a graph-structured agent network in which each node is designed as an 1-hop-view agent. Through the decentralized interactions between agents, they can learn to infer global perceptions to perform tasks including inferring embeddings, degrees and neighbor relationships for given nodes. This empowers nodes to filtering adversarial edges while carrying out classification tasks. Furthermore, agents' limited view prevents malicious messages from propagating globally in GAgN, thereby resisting global-optimization-based secondary attacks. We prove that single-hidden-layer multilayer perceptrons (MLPs) are theoretically sufficient to achieve these functionalities. Experimental results show that GAgN effectively implements all its intended capabilities and, compared to state-of-the-art defenses, achieves optimal classification accuracy on the perturbed datasets.
Personalized Sleep Staging Leveraging Source-free Unsupervised Domain Adaptation
Dec 11, 2024



Sleep staging is crucial for assessing sleep quality and diagnosing related disorders. Recent deep learning models for automatic sleep staging using polysomnography often suffer from poor generalization to new subjects because they are trained and tested on the same labeled datasets, overlooking individual differences. To tackle this issue, we propose a novel Source-Free Unsupervised Individual Domain Adaptation (SF-UIDA) framework. This two-step adaptation scheme allows the model to effectively adjust to new unlabeled individuals without needing source data, facilitating personalized customization in clinical settings. Our framework has been applied to three established sleep staging models and tested on three public datasets, achieving state-of-the-art performance.
CBraMod: A Criss-Cross Brain Foundation Model for EEG Decoding
Dec 10, 2024



Electroencephalography (EEG) is a non-invasive technique to measure and record brain electrical activity, widely used in various BCI and healthcare applications. Early EEG decoding methods rely on supervised learning, limited by specific tasks and datasets, hindering model performance and generalizability. With the success of large language models, there is a growing body of studies focusing on EEG foundation models. However, these studies still leave challenges: Firstly, most of existing EEG foundation models employ full EEG modeling strategy. It models the spatial and temporal dependencies between all EEG patches together, but ignores that the spatial and temporal dependencies are heterogeneous due to the unique structural characteristics of EEG signals. Secondly, existing EEG foundation models have limited generalizability on a wide range of downstream BCI tasks due to varying formats of EEG data, making it challenging to adapt to. To address these challenges, we propose a novel foundation model called CBraMod. Specifically, we devise a criss-cross transformer as the backbone to thoroughly leverage the structural characteristics of EEG signals, which can model spatial and temporal dependencies separately through two parallel attention mechanisms. And we utilize an asymmetric conditional positional encoding scheme which can encode positional information of EEG patches and be easily adapted to the EEG with diverse formats. CBraMod is pre-trained on a very large corpus of EEG through patch-based masked EEG reconstruction. We evaluate CBraMod on up to 10 downstream BCI tasks (12 public datasets). CBraMod achieves the state-of-the-art performance across the wide range of tasks, proving its strong capability and generalizability. The source code is publicly available at \url{https://github.com/wjq-learning/CBraMod}.
Inference-to-complete: A High-performance and Programmable Data-plane Co-processor for Neural-network-driven Traffic Analysis
Nov 01, 2024



Neural-networks-driven intelligent data-plane (NN-driven IDP) is becoming an emerging topic for excellent accuracy and high performance. Meanwhile we argue that NN-driven IDP should satisfy three design goals: the flexibility to support various NNs models, the low-latency-high-throughput inference performance, and the data-plane-unawareness harming no performance and functionality. Unfortunately, existing work either over-modify NNs for IDP, or insert inline pipelined accelerators into the data-plane, failing to meet the flexibility and unawareness goals. In this paper, we propose Kaleidoscope, a flexible and high-performance co-processor located at the bypass of the data-plane. To address the challenge of meeting three design goals, three key techniques are presented. The programmable run-to-completion accelerators are developed for flexible inference. To further improve performance, we design a scalable inference engine which completes low-latency and low-cost inference for the mouse flows, and perform complex NNs with high-accuracy for the elephant flows. Finally, raw-bytes-based NNs are introduced, which help to achieve unawareness. We prototype Kaleidoscope on both FPGA and ASIC library. In evaluation on six NNs models, Kaleidoscope reaches 256-352 ns inference latency and 100 Gbps throughput with negligible influence on the data-plane. The on-board tested NNs perform state-of-the-art accuracy among other NN-driven IDP, exhibiting the the significant impact of flexibility on enhancing traffic analysis accuracy.