 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStealthy World Model Manipulation via Data Poisoning
Jun 17, 2026Model-based learning agents use learned world models to predict future states, plan actions, and adapt to new environments. However, the process of updating world models from collected experience creates a training-time attack surface: adversarially poisoned fine-tuning trajectories can manipulate the learned dynamics and thereby corrupt downstream planning. In this paper, we propose SWAAP, the first two-stage data poisoning framework for learned world models. In the first stage, SWAAP identifies a harmful target world model that induces low-return behavior under planning while remaining close to clean dynamics, using first-order bilevel optimization enabled by a transition-gradient theorem. In the second stage, SWAAP realizes this target through stealth-constrained gradient matching, modifying only a limited fraction of fine-tuning transition targets so that the induced training gradients steer the victim model toward the adversarial target, while a prediction-error regularizer encourages the poisoned targets to remain close to the world model's natural approximation error. To assess attack stealthiness, we evaluate defenses and detectability across three stages of the poisoning pipeline: pre-training detection of poisoned transitions, robust training during fine-tuning, and test-time monitoring of the resulting world model. Across diverse continuous-control tasks, SWAAP causes substantial performance degradation while keeping poisoned transitions close to clean data and evading the evaluated non-adaptive residual/CUSUM/TRIM-style defenses. These results reveal a practical vulnerability in world-model adaptation pipelines and highlight the need for robustness methods that protect both world-model training data and learned dynamics.
Robust Optimization for Mitigating Reward Hacking with Correlated Proxies
Apr 13, 2026Designing robust reinforcement learning (RL) agents in the presence of imperfect reward signals remains a core challenge. In practice, agents are often trained with proxy rewards that only approximate the true objective, leaving them vulnerable to reward hacking, where high proxy returns arise from unintended or exploitative behaviors. Recent work formalizes this issue using r-correlation between proxy and true rewards, but existing methods like occupancy-regularized policy optimization (ORPO) optimize against a fixed proxy and do not provide strong guarantees against broader classes of correlated proxies. In this work, we formulate reward hacking as a robust policy optimization problem over the space of all r-correlated proxy rewards. We derive a tractable max-min formulation, where the agent maximizes performance under the worst-case proxy consistent with the correlation constraint. We further show that when the reward is a linear function of known features, our approach can be adapted to incorporate this prior knowledge, yielding both improved policies and interpretable worst-case rewards. Experiments across several environments show that our algorithms consistently outperform ORPO in worst-case returns, and offer improved robustness and stability across different levels of proxy-true reward correlation. These results show that our approach provides both robustness and transparency in settings where reward design is inherently uncertain. The code is available at https://github.com/ZixuanLiu4869/reward_hacking.
MemBoost: A Memory-Boosted Framework for Cost-Aware LLM Inference
Mar 27, 2026Large Language Models (LLMs) deliver strong performance but incur high inference cost in real-world services, especially under workloads with repeated or near-duplicate queries across users and sessions. In this work, we propose MemBoost, a memory-boosted LLM serving framework that enables a lightweight model to reuse previously generated answers and retrieve relevant supporting information for cheap inference, while selectively escalating difficult or uncertain queries to a stronger model. Unlike standard retrieval-augmented generation, which primarily grounds a single response, MemBoost is designed for interactive settings by supporting answer reuse, continual memory growth, and cost-aware routing. Experiments across multiple models under simulated workloads show that MemBoost substantially reduces expensive large-model invocations and overall inference cost, while maintaining high answer quality comparable to the strong model baseline.
From Classical to Quantum Reinforcement Learning and Its Applications in Quantum Control: A Beginner's Tutorial
Jan 13, 2026This tutorial is designed to make reinforcement learning (RL) more accessible to undergraduate students by offering clear, example-driven explanations. It focuses on bridging the gap between RL theory and practical coding applications, addressing common challenges that students face when transitioning from conceptual understanding to implementation. Through hands-on examples and approachable explanations, the tutorial aims to equip students with the foundational skills needed to confidently apply RL techniques in real-world scenarios.
Online Learning with Probing for Sequential User-Centric Selection
Jul 27, 2025


We formalize sequential decision-making with information acquisition as the probing-augmented user-centric selection (PUCS) framework, where a learner first probes a subset of arms to obtain side information on resources and rewards, and then assigns $K$ plays to $M$ arms. PUCS covers applications such as ridesharing, wireless scheduling, and content recommendation, in which both resources and payoffs are initially unknown and probing is costly. For the offline setting with known distributions, we present a greedy probing algorithm with a constant-factor approximation guarantee $\zeta = (e-1)/(2e-1)$. For the online setting with unknown distributions, we introduce OLPA, a stochastic combinatorial bandit algorithm that achieves a regret bound $\mathcal{O}(\sqrt{T} + \ln^{2} T)$. We also prove a lower bound $\Omega(\sqrt{T})$, showing that the upper bound is tight up to logarithmic factors. Experiments on real-world data demonstrate the effectiveness of our solutions.
Fair Algorithms with Probing for Multi-Agent Multi-Armed Bandits
Jun 17, 2025
We propose a multi-agent multi-armed bandit (MA-MAB) framework aimed at ensuring fair outcomes across agents while maximizing overall system performance. A key challenge in this setting is decision-making under limited information about arm rewards. To address this, we introduce a novel probing framework that strategically gathers information about selected arms before allocation. In the offline setting, where reward distributions are known, we leverage submodular properties to design a greedy probing algorithm with a provable performance bound. For the more complex online setting, we develop an algorithm that achieves sublinear regret while maintaining fairness. Extensive experiments on synthetic and real-world datasets show that our approach outperforms baseline methods, achieving better fairness and efficiency.
Meta Stackelberg Game: Robust Federated Learning against Adaptive and Mixed Poisoning Attacks
Oct 22, 2024



Federated learning (FL) is susceptible to a range of security threats. Although various defense mechanisms have been proposed, they are typically non-adaptive and tailored to specific types of attacks, leaving them insufficient in the face of multiple uncertain, unknown, and adaptive attacks employing diverse strategies. This work formulates adversarial federated learning under a mixture of various attacks as a Bayesian Stackelberg Markov game, based on which we propose the meta-Stackelberg defense composed of pre-training and online adaptation. {The gist is to simulate strong attack behavior using reinforcement learning (RL-based attacks) in pre-training and then design meta-RL-based defense to combat diverse and adaptive attacks.} We develop an efficient meta-learning approach to solve the game, leading to a robust and adaptive FL defense. Theoretically, our meta-learning algorithm, meta-Stackelberg learning, provably converges to the first-order $\varepsilon$-meta-equilibrium point in $O(\varepsilon^{-2})$ gradient iterations with $O(\varepsilon^{-4})$ samples per iteration. Experiments show that our meta-Stackelberg framework performs superbly against strong model poisoning and backdoor attacks of uncertain and unknown types.
Belief-Enriched Pessimistic Q-Learning against Adversarial State Perturbations
Mar 06, 2024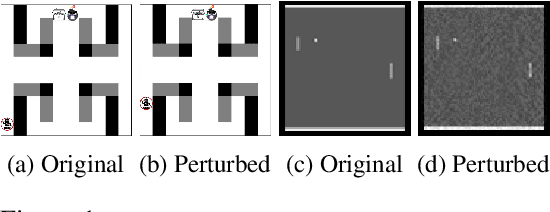



Reinforcement learning (RL) has achieved phenomenal success in various domains. However, its data-driven nature also introduces new vulnerabilities that can be exploited by malicious opponents. Recent work shows that a well-trained RL agent can be easily manipulated by strategically perturbing its state observations at the test stage. Existing solutions either introduce a regularization term to improve the smoothness of the trained policy against perturbations or alternatively train the agent's policy and the attacker's policy. However, the former does not provide sufficient protection against strong attacks, while the latter is computationally prohibitive for large environments. In this work, we propose a new robust RL algorithm for deriving a pessimistic policy to safeguard against an agent's uncertainty about true states. This approach is further enhanced with belief state inference and diffusion-based state purification to reduce uncertainty. Empirical results show that our approach obtains superb performance under strong attacks and has a comparable training overhead with regularization-based methods. Our code is available at https://github.com/SliencerX/Belief-enriched-robust-Q-learning.
Enhancing LLM Safety via Constrained Direct Preference Optimization
Mar 04, 2024



The rapidly increasing capabilities of large language models (LLMs) raise an urgent need to align AI systems with diverse human preferences to simultaneously enhance their usefulness and safety, despite the often conflicting nature of these goals. To address this important problem, a promising approach is to enforce a safety constraint at the fine-tuning stage through a constrained Reinforcement Learning from Human Feedback (RLHF) framework. This approach, however, is computationally expensive and often unstable. In this work, we introduce Constrained DPO (C-DPO), a novel extension of the recently proposed Direct Preference Optimization (DPO) approach for fine-tuning LLMs that is both efficient and lightweight. By integrating dual gradient descent and DPO, our method identifies a nearly optimal trade-off between helpfulness and harmlessness without using reinforcement learning. Empirically, our approach provides a safety guarantee to LLMs that is missing in DPO while achieving significantly higher rewards under the same safety constraint compared to a recently proposed safe RLHF approach. Warning: This paper contains example data that may be offensive or harmful.
A First Order Meta Stackelberg Method for Robust Federated Learning
Jul 16, 2023

Previous research has shown that federated learning (FL) systems are exposed to an array of security risks. Despite the proposal of several defensive strategies, they tend to be non-adaptive and specific to certain types of attacks, rendering them ineffective against unpredictable or adaptive threats. This work models adversarial federated learning as a Bayesian Stackelberg Markov game (BSMG) to capture the defender's incomplete information of various attack types. We propose meta-Stackelberg learning (meta-SL), a provably efficient meta-learning algorithm, to solve the equilibrium strategy in BSMG, leading to an adaptable FL defense. We demonstrate that meta-SL converges to the first-order $\varepsilon$-equilibrium point in $O(\varepsilon^{-2})$ gradient iterations, with $O(\varepsilon^{-4})$ samples needed per iteration, matching the state of the art. Empirical evidence indicates that our meta-Stackelberg framework performs exceptionally well against potent model poisoning and backdoor attacks of an uncertain nature.