 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Language Models with Memory Augmentation
May 25, 2022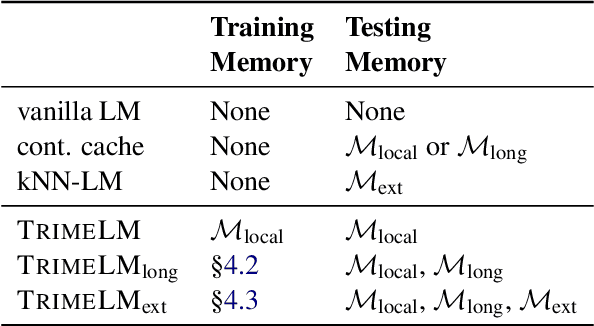
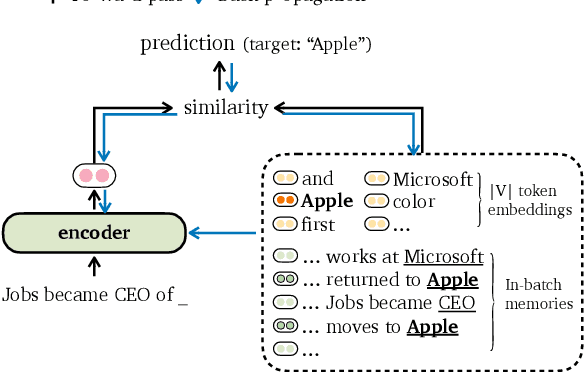
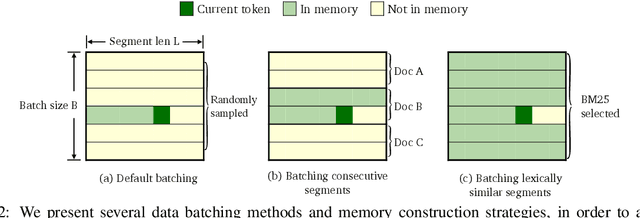
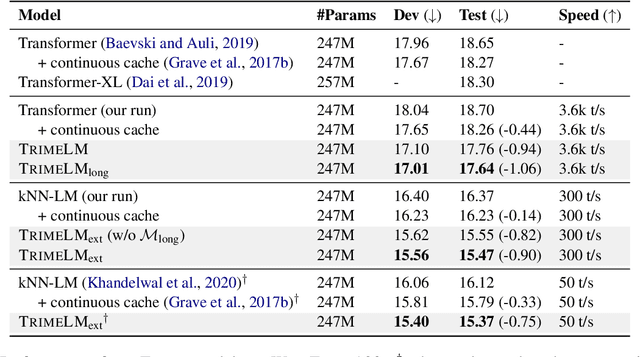
Recent work has improved language models remarkably by equipping them with a non-parametric memory component. However, most existing approaches only introduce memories at testing time, or represent them using a separately trained encoder -- resulting in sub-optimal training of the language model. In this work, we present TRIME, a novel yet simple training approach designed for training language models with memory augmentation. Our approach uses a training objective that directly takes in-batch examples as accessible memory. We also present new methods for memory construction and data batching, which are used for adapting to different sets of memories -- local, long-term, and external memory -- at testing time. We evaluate our approach on multiple language modeling and machine translation benchmarks. We find that simply replacing the vanilla language modeling objective by ours greatly reduces the perplexity, without modifying the model architecture or incorporating extra context (e.g., 18.70 $\to$ 17.76 on WikiText-103). We further augment language models with long-range contexts and external knowledge and demonstrate significant gains over previous memory-augmented approaches.
Simple Recurrence Improves Masked Language Models
May 23, 2022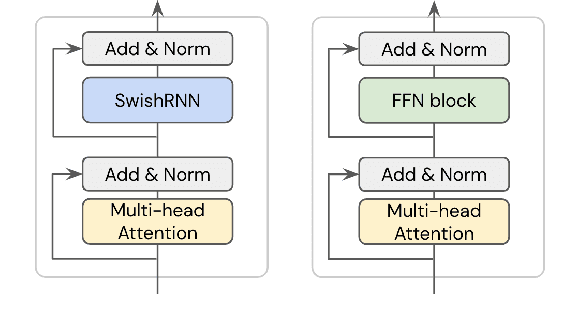
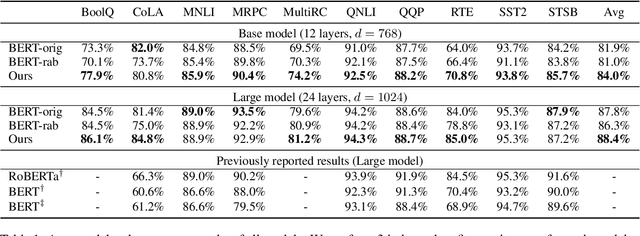
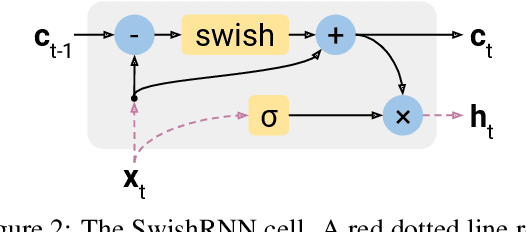
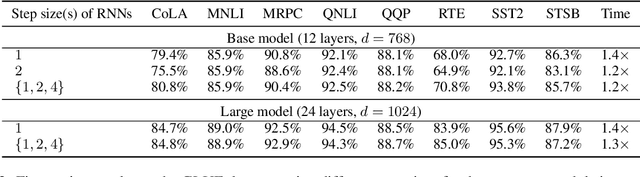
In this work, we explore whether modeling recurrence into the Transformer architecture can both be beneficial and efficient, by building an extremely simple recurrent module into the Transformer. We compare our model to baselines following the training and evaluation recipe of BERT. Our results confirm that recurrence can indeed improve Transformer models by a consistent margin, without requiring low-level performance optimizations, and while keeping the number of parameters constant. For example, our base model achieves an absolute improvement of 2.1 points averaged across 10 tasks and also demonstrates increased stability in fine-tuning over a range of learning rates.
Mixture-of-Experts with Expert Choice Routing
Feb 18, 2022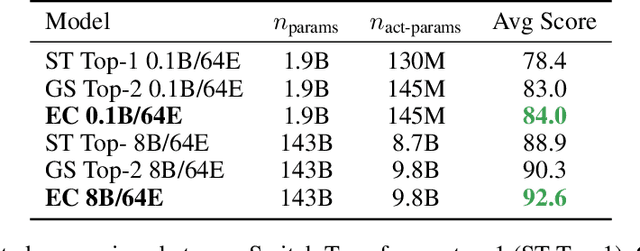
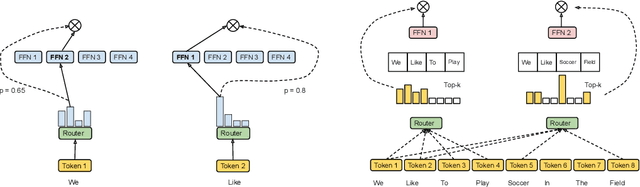

Sparsely-activated Mixture-of-experts (MoE) models allow the number of parameters to greatly increase while keeping the amount of computation for a given token or a given sample unchanged. However, a poor expert routing strategy (e.g. one resulting in load imbalance) can cause certain experts to be under-trained, leading to an expert being under or over-specialized. Prior work allocates a fixed number of experts to each token using a top-k function regardless of the relative importance of different tokens. To address this, we propose a heterogeneous mixture-of-experts employing an expert choice method. Instead of letting tokens select the top-k experts, we have experts selecting the top-k tokens. As a result, each token can be routed to a variable number of experts and each expert can have a fixed bucket size. We systematically study pre-training speedups using the same computational resources of the Switch Transformer top-1 and GShard top-2 gating of prior work and find that our method improves training convergence time by more than 2x. For the same computational cost, our method demonstrates higher performance in fine-tuning 11 selected tasks in the GLUE and SuperGLUE benchmarks. For a smaller activation cost, our method outperforms the T5 dense model in 7 out of the 11 tasks.
SRU++: Pioneering Fast Recurrence with Attention for Speech Recognition
Oct 11, 2021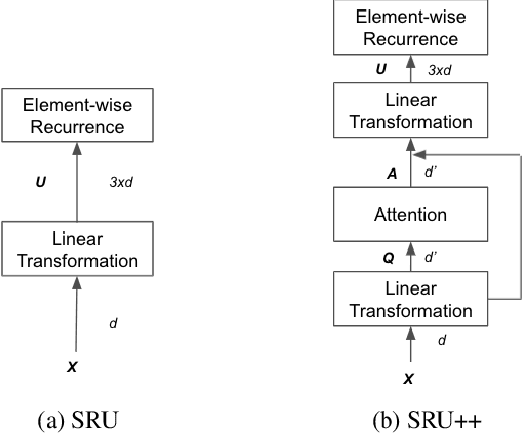



The Transformer architecture has been well adopted as a dominant architecture in most sequence transduction tasks including automatic speech recognition (ASR), since its attention mechanism excels in capturing long-range dependencies. While models built solely upon attention can be better parallelized than regular RNN, a novel network architecture, SRU++, was recently proposed. By combining the fast recurrence and attention mechanism, SRU++ exhibits strong capability in sequence modeling and achieves near-state-of-the-art results in various language modeling and machine translation tasks with improved compute efficiency. In this work, we present the advantages of applying SRU++ in ASR tasks by comparing with Conformer across multiple ASR benchmarks and study how the benefits can be generalized to long-form speech inputs. On the popular LibriSpeech benchmark, our SRU++ model achieves 2.0% / 4.7% WER on test-clean / test-other, showing competitive performances compared with the state-of-the-art Conformer encoder under the same set-up. Specifically, SRU++ can surpass Conformer on long-form speech input with a large margin, based on our analysis.
Channel-Temporal Attention for First-Person Video Domain Adaptation
Aug 19, 2021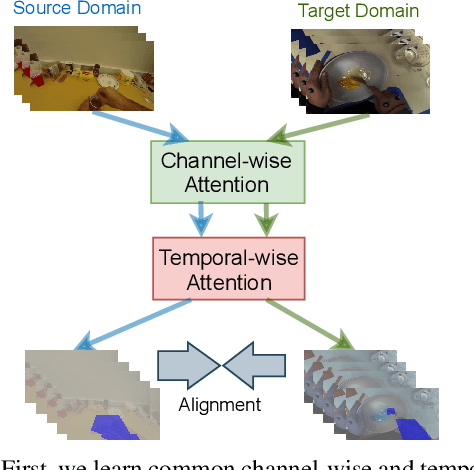

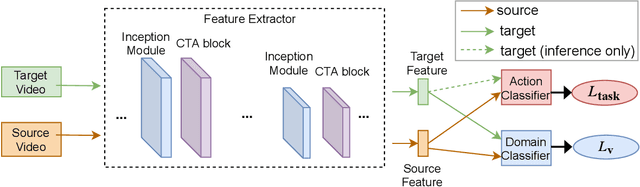
Unsupervised Domain Adaptation (UDA) can transfer knowledge from labeled source data to unlabeled target data of the same categories. However, UDA for first-person action recognition is an under-explored problem, with lack of datasets and limited consideration of first-person video characteristics. This paper focuses on addressing this problem. Firstly, we propose two small-scale first-person video domain adaptation datasets: ADL$_{small}$ and GTEA-KITCHEN. Secondly, we introduce channel-temporal attention blocks to capture the channel-wise and temporal-wise relationships and model their inter-dependencies important to first-person vision. Finally, we propose a Channel-Temporal Attention Network (CTAN) to integrate these blocks into existing architectures. CTAN outperforms baselines on the two proposed datasets and one existing dataset EPIC$_{cvpr20}$.
Team PyKale Submission to the EPIC-Kitchens 2021 Unsupervised Domain Adaptation Challenge for Action Recognition
Jun 22, 2021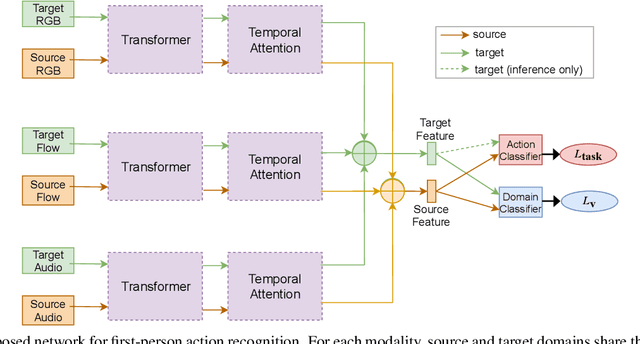

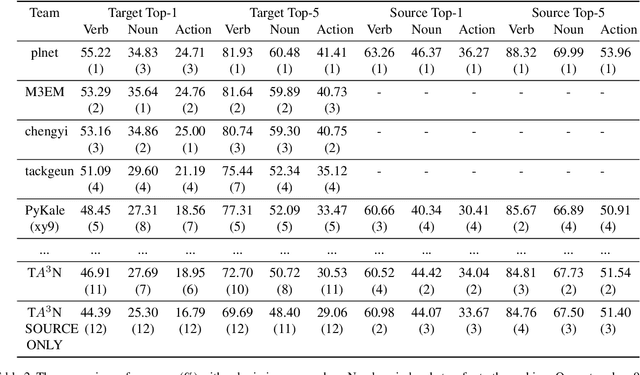
This report describes the technical details of our submission to the EPIC-Kitchens 2021 Unsupervised Domain Adaptation Challenge for Action Recognition. The EPIC-Kitchens dataset is more difficult than other video domain adaptation datasets due to multi-tasks with more modalities. Firstly, to participate in the challenge, we employ a transformer to capture the spatial information from each modality. Secondly, we employ a temporal attention module to model temporal-wise inter-dependency. Thirdly, we employ the adversarial domain adaptation network to learn the general features between labeled source and unlabeled target domain. Finally, we incorporate multiple modalities to improve the performance by a three-stream network with late fusion. Our network achieves the comparable performance with the state-of-the-art baseline T$A^3$N and outperforms the baseline on top-1 accuracy for verb class and top-5 accuracies for all three tasks which are verb, noun and action. Under the team name xy9, our submission achieved 5th place in terms of top-1 accuracy for verb class and all top-5 accuracies.
Nutribullets Hybrid: Multi-document Health Summarization
Apr 08, 2021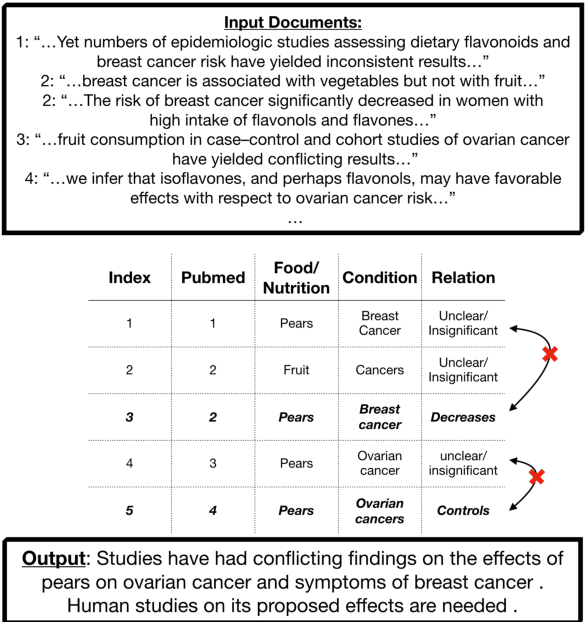

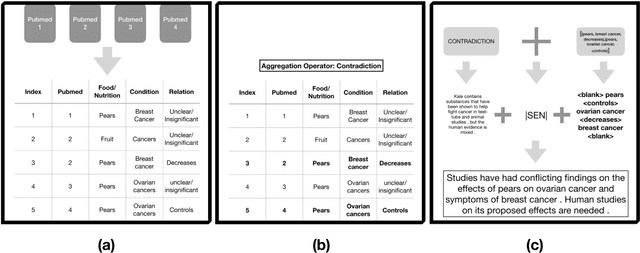

We present a method for generating comparative summaries that highlights similarities and contradictions in input documents. The key challenge in creating such summaries is the lack of large parallel training data required for training typical summarization systems. To this end, we introduce a hybrid generation approach inspired by traditional concept-to-text systems. To enable accurate comparison between different sources, the model first learns to extract pertinent relations from input documents. The content planning component uses deterministic operators to aggregate these relations after identifying a subset for inclusion into a summary. The surface realization component lexicalizes this information using a text-infilling language model. By separately modeling content selection and realization, we can effectively train them with limited annotations. We implemented and tested the model in the domain of nutrition and health -- rife with inconsistencies. Compared to conventional methods, our framework leads to more faithful, relevant and aggregation-sensitive summarization -- while being equally fluent.
Nutri-bullets: Summarizing Health Studies by Composing Segments
Mar 22, 2021


We introduce \emph{Nutri-bullets}, a multi-document summarization task for health and nutrition. First, we present two datasets of food and health summaries from multiple scientific studies. Furthermore, we propose a novel \emph{extract-compose} model to solve the problem in the regime of limited parallel data. We explicitly select key spans from several abstracts using a policy network, followed by composing the selected spans to present a summary via a task specific language model. Compared to state-of-the-art methods, our approach leads to more faithful, relevant and diverse summarization -- properties imperative to this application. For instance, on the BreastCancer dataset our approach gets a more than 50\% improvement on relevance and faithfulness.\footnote{Our code and data is available at \url{https://github.com/darsh10/Nutribullets.}}
* 12 pages
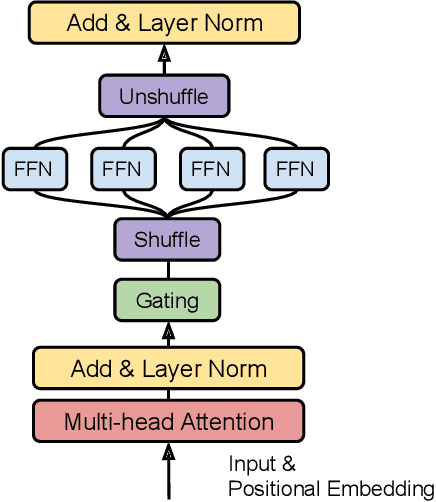
When Attention Meets Fast Recurrence: Training Language Models with Reduced Compute
Feb 24, 2021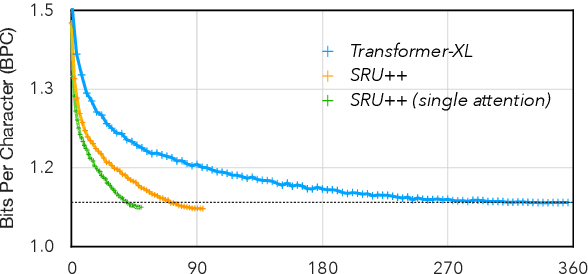
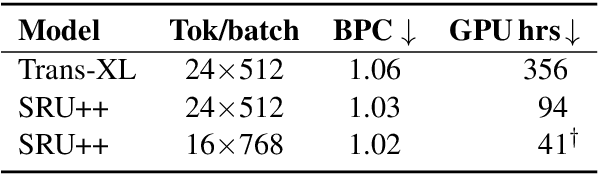
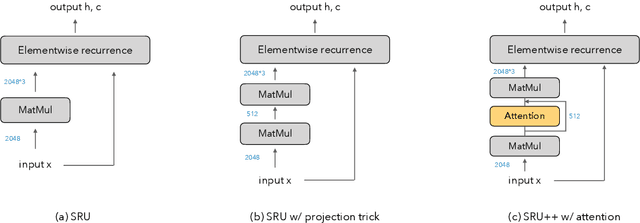
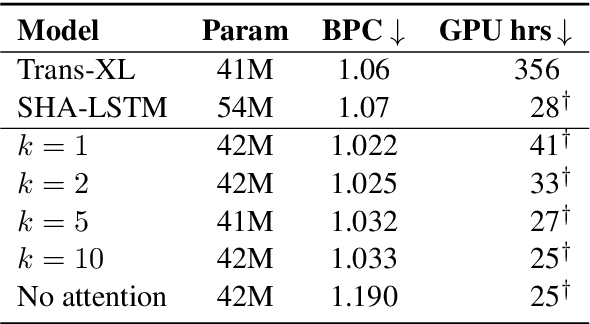
Large language models have become increasingly difficult to train because of the required computation time and cost. In this work, we present SRU++, a recurrent unit with optional built-in attention that exhibits state-of-the-art modeling capacity and training efficiency. On standard language modeling benchmarks such as enwik8 and Wiki-103 datasets, our model obtains better perplexity and bits-per-character (bpc) while using 2.5x-10x less training time and cost compared to top-performing Transformer models. Our results reaffirm that attention is not all we need and can be complementary to other sequential modeling modules. Moreover, fast recurrence with little attention can be a leading model architecture.
Medical Image Segmentation Using Deep Learning: A Survey
Sep 28, 2020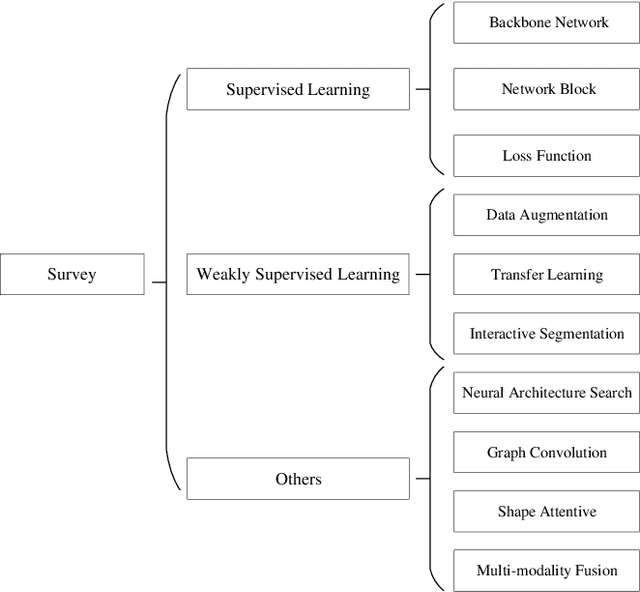
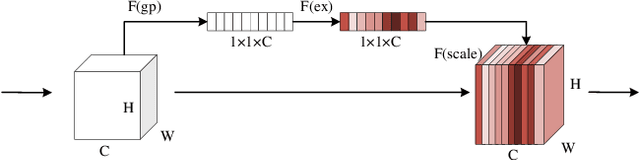
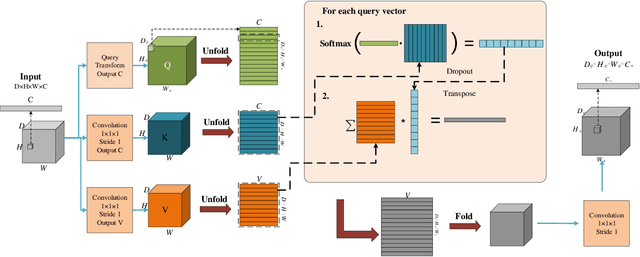
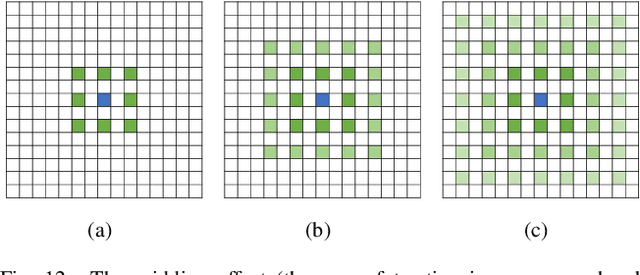
Deep learning has been widely used for medical image segmentation and a large number of papers has been presented recording the success of deep learning in the field. In this paper, we present a comprehensive thematic survey on medical image segmentation using deep learning techniques. This paper makes two original contributions. Firstly, compared to traditional surveys that directly divide literatures of deep learning on medical image segmentation into many groups and introduce literatures in detail for each group, we classify currently popular literatures according to a multi-level structure from coarse to fine. Secondly, this paper focuses on supervised and weakly supervised learning approaches, without including unsupervised approaches since they have been introduced in many old surveys and they are not popular currently. For supervised learning approaches, we analyze literatures in three aspects: the selection of backbone networks, the design of network blocks, and the improvement of loss functions. For weakly supervised learning approaches, we investigate literature according to data augmentation, transfer learning, and interactive segmentation, separately. Compared to existing surveys, this survey classifies the literatures very differently from before and is more convenient for readers to understand the relevant rationale and will guide them to think of appropriate improvements in medical image segmentation based on deep learning approaches.