 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecent Advances in Adversarial Training for Adversarial Robustness
Feb 23, 2021
Adversarial training is one of the most effective approaches defending against adversarial examples for deep learning models. Unlike other defense strategies, adversarial training aims to promote the robustness of models intrinsically. During the last few years, adversarial training has been studied and discussed from various aspects. A variety of improvements and developments of adversarial training are proposed, which were, however, neglected in existing surveys. For the first time in this survey, we systematically review the recent progress on adversarial training for adversarial robustness with a novel taxonomy. Then we discuss the generalization problems in adversarial training from three perspectives. Finally, we highlight the challenges which are not fully tackled and present potential future directions.
Recent Advances in Understanding Adversarial Robustness of Deep Neural Networks
Nov 03, 2020Adversarial examples are inevitable on the road of pervasive applications of deep neural networks (DNN). Imperceptible perturbations applied on natural samples can lead DNN-based classifiers to output wrong prediction with fair confidence score. It is increasingly important to obtain models with high robustness that are resistant to adversarial examples. In this paper, we survey recent advances in how to understand such intriguing property, i.e. adversarial robustness, from different perspectives. We give preliminary definitions on what adversarial attacks and robustness are. After that, we study frequently-used benchmarks and mention theoretically-proved bounds for adversarial robustness. We then provide an overview on analyzing correlations among adversarial robustness and other critical indicators of DNN models. Lastly, we introduce recent arguments on potential costs of adversarial training which have attracted wide attention from the research community.
Feature Distillation With Guided Adversarial Contrastive Learning
Sep 21, 2020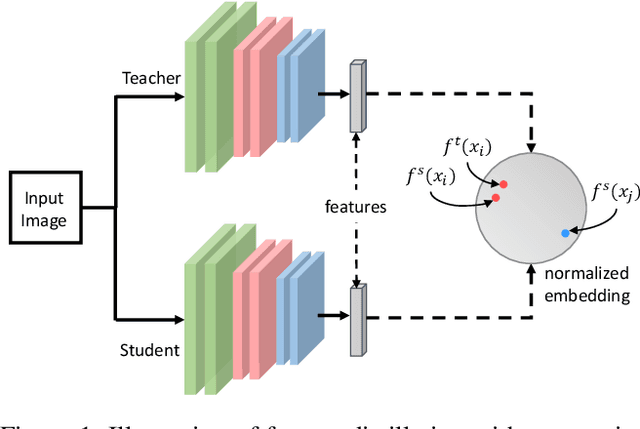
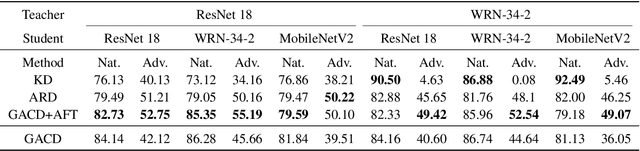
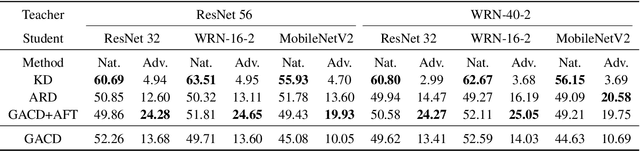
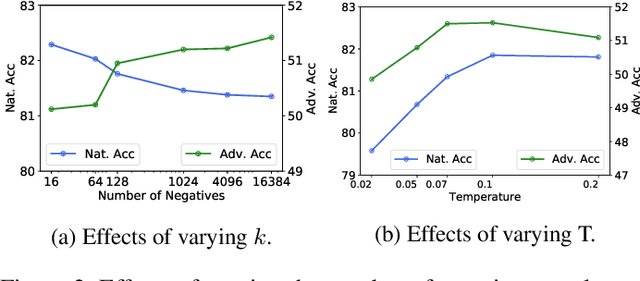
Deep learning models are shown to be vulnerable to adversarial examples. Though adversarial training can enhance model robustness, typical approaches are computationally expensive. Recent works proposed to transfer the robustness to adversarial attacks across different tasks or models with soft labels.Compared to soft labels, feature contains rich semantic information and holds the potential to be applied to different downstream tasks. In this paper, we propose a novel approach called Guided Adversarial Contrastive Distillation (GACD), to effectively transfer adversarial robustness from teacher to student with features. We first formulate this objective as contrastive learning and connect it with mutual information. With a well-trained teacher model as an anchor, students are expected to extract features similar to the teacher. Then considering the potential errors made by teachers, we propose sample reweighted estimation to eliminate the negative effects from teachers. With GACD, the student not only learns to extract robust features, but also captures structural knowledge from the teacher. By extensive experiments evaluating over popular datasets such as CIFAR-10, CIFAR-100 and STL-10, we demonstrate that our approach can effectively transfer robustness across different models and even different tasks, and achieve comparable or better results than existing methods. Besides, we provide a detailed analysis of various methods, showing that students produced by our approach capture more structural knowledge from teachers and learn more robust features under adversarial attacks.
Generating Adversarial yet Inconspicuous Patches with a Single Image
Sep 21, 2020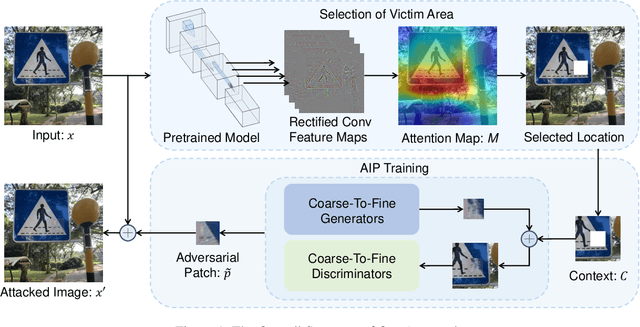
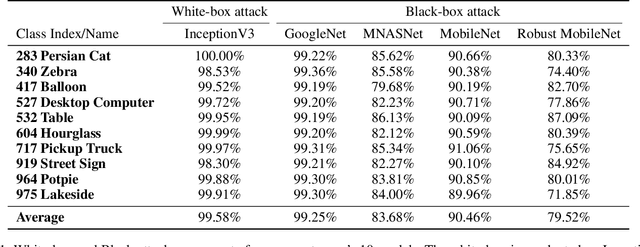
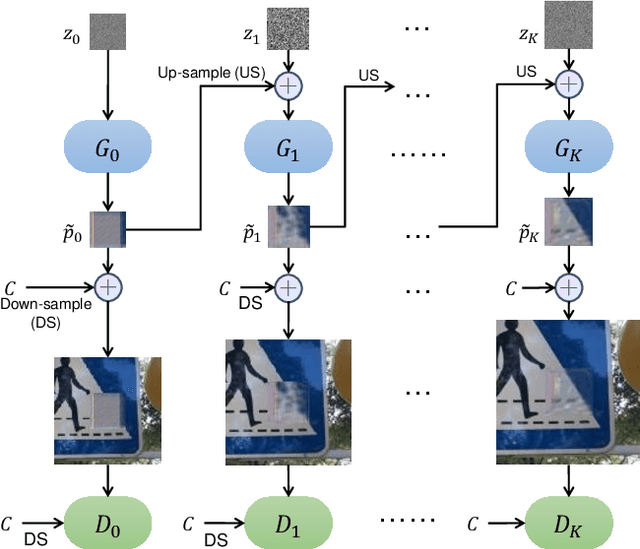

Deep neural networks have been shown vulnerable toadversarial patches, where exotic patterns can resultin models wrong prediction. Nevertheless, existing ap-proaches to adversarial patch generation hardly con-sider the contextual consistency between patches andthe image background, causing such patches to be eas-ily detected and adversarial attacks to fail. On the otherhand, these methods require a large amount of data fortraining, which is computationally expensive. To over-come these challenges, we propose an approach to gen-erate adversarial yet inconspicuous patches with onesingle image. In our approach, adversarial patches areproduced in a coarse-to-fine way with multiple scalesof generators and discriminators. Contextual informa-tion is encoded during the Min-Max training to makepatches consistent with surroundings. The selection ofpatch location is based on the perceptual sensitivity ofvictim models. Through extensive experiments, our ap-proach shows strong attacking ability in both the white-box and black-box setting. Experiments on saliency de-tection and user evaluation indicate that our adversar-ial patches can evade human observations, demonstratethe inconspicuousness of our approach. Lastly, we showthat our approach preserves the attack ability in thephysical world.
AI-GAN: Attack-Inspired Generation of Adversarial Examples
Feb 06, 2020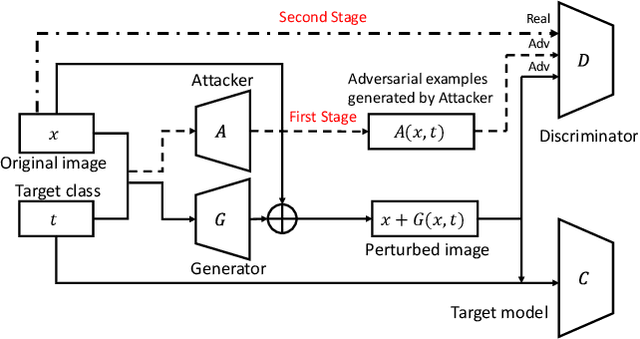

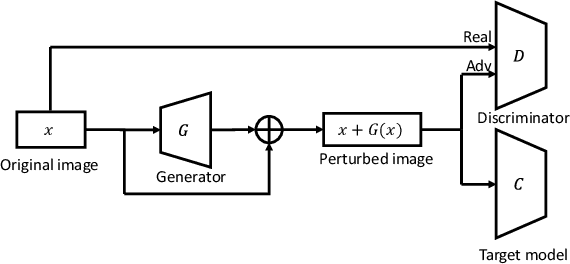
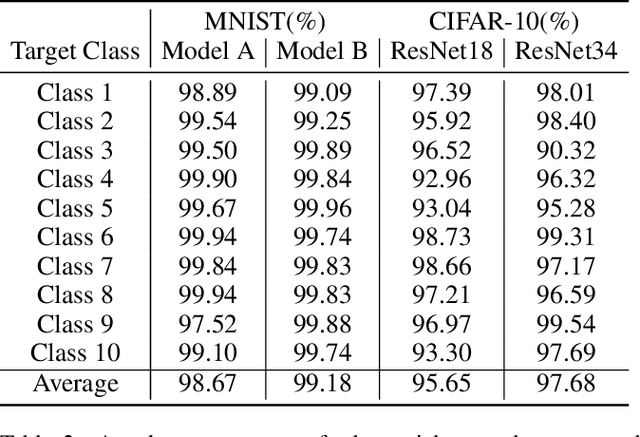
Adversarial examples that can fool deep models are mainly crafted by adding small perturbations imperceptible to human eyes. There are various optimization-based methods in the literature to generate adversarial perturbations, most of which are time-consuming. AdvGAN, a method proposed by Xiao~\emph{et al.}~in IJCAI~2018, employs Generative Adversarial Networks (GAN) to generate adversarial perturbation with original images as inputs, which is faster than optimization-based methods at inference time. AdvGAN, however, fixes the target classes in the training and we find it difficult to train AdvGAN when it is modified to take original images and target classes as inputs. In this paper, we propose \mbox{Attack-Inspired} GAN (\mbox{AI-GAN}) with a different training strategy to solve this problem. \mbox{AI-GAN} is a two-stage method, in which we use projected gradient descent (PGD) attack to inspire the training of GAN in the first stage and apply standard training of GAN in the second stage. Once trained, the Generator can approximate the conditional distribution of adversarial instances and generate \mbox{imperceptible} adversarial perturbations given different target classes. We conduct experiments and evaluate the performance of \mbox{AI-GAN} on MNIST and \mbox{CIFAR-10}. Compared with AdvGAN, \mbox{AI-GAN} achieves higher attack success rates with similar perturbation magnitudes.
Reviewing and Improving the Gaussian Mechanism for Differential Privacy
Dec 07, 2019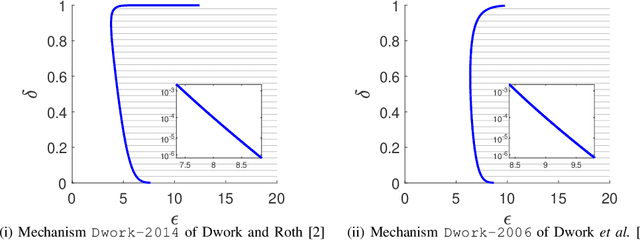
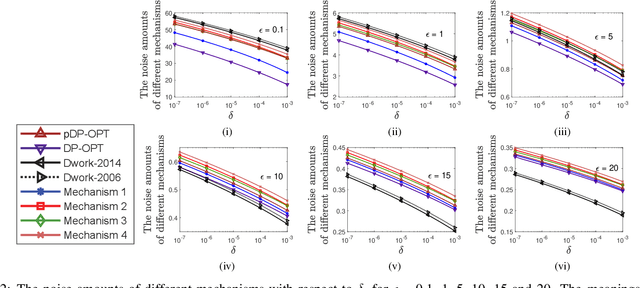
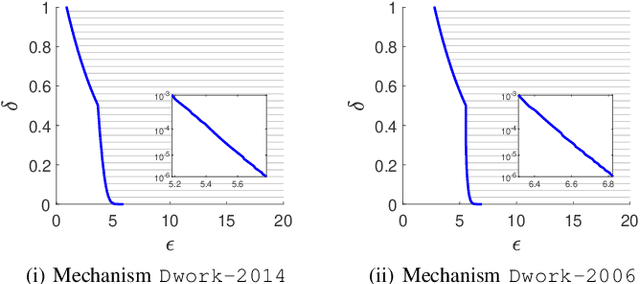
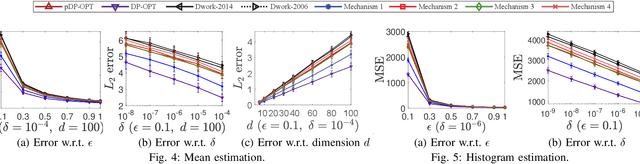
Differential privacy provides a rigorous framework to quantify data privacy, and has received considerable interest recently. A randomized mechanism satisfying $(\epsilon, \delta)$-differential privacy (DP) roughly means that, except with a small probability $\delta$, altering a record in a dataset cannot change the probability that an output is seen by more than a multiplicative factor $e^{\epsilon} $. A well-known solution to $(\epsilon, \delta)$-DP is the Gaussian mechanism initiated by Dwork et al. [1] in 2006 with an improvement by Dwork and Roth [2] in 2014, where a Gaussian noise amount $\sqrt{2\ln \frac{2}{\delta}} \times \frac{\Delta}{\epsilon}$ of [1] or $\sqrt{2\ln \frac{1.25}{\delta}} \times \frac{\Delta}{\epsilon}$ of [2] is added independently to each dimension of the query result, for a query with $\ell_2$-sensitivity $\Delta$. Although both classical Gaussian mechanisms [1,2] assume $0 < \epsilon \leq 1$, our review finds that many studies in the literature have used the classical Gaussian mechanisms under values of $\epsilon$ and $\delta$ where the added noise amounts of [1,2] do not achieve $(\epsilon,\delta)$-DP. We obtain such result by analyzing the optimal noise amount $\sigma_{DP-OPT}$ for $(\epsilon,\delta)$-DP and identifying $\epsilon$ and $\delta$ where the noise amounts of classical mechanisms are even less than $\sigma_{DP-OPT}$. Since $\sigma_{DP-OPT}$ has no closed-form expression and needs to be approximated in an iterative manner, we propose Gaussian mechanisms by deriving closed-form upper bounds for $\sigma_{DP-OPT}$. Our mechanisms achieve $(\epsilon,\delta)$-DP for any $\epsilon$, while the classical mechanisms [1,2] do not achieve $(\epsilon,\delta)$-DP for large $\epsilon$ given $\delta$. Moreover, the utilities of our mechanisms improve those of [1,2] and are close to that of the optimal yet more computationally expensive Gaussian mechanism.
Targeting Ultimate Accuracy: Face Recognition via Deep Embedding
Jul 23, 2015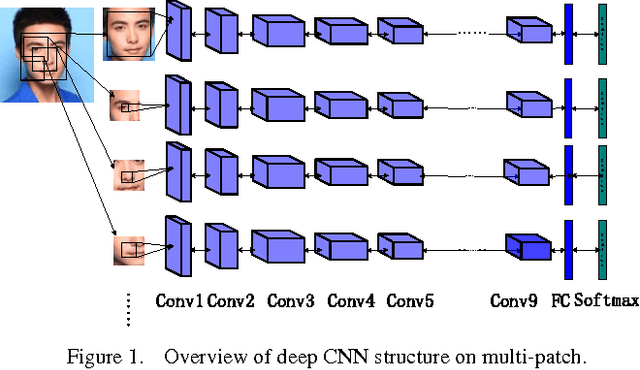
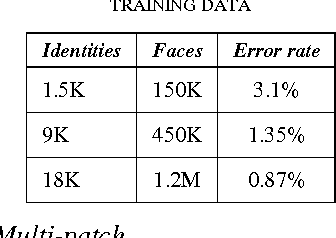
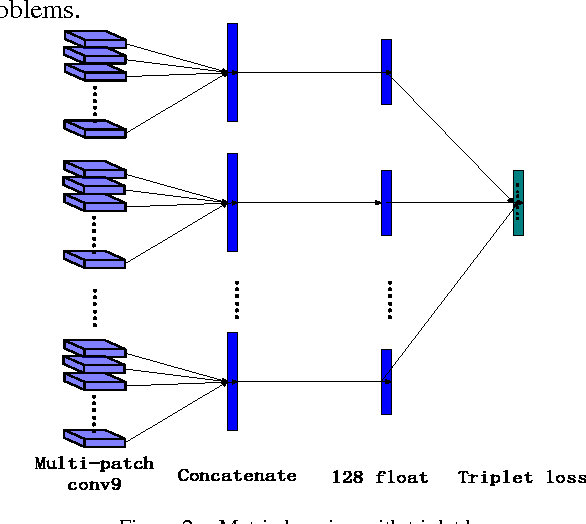
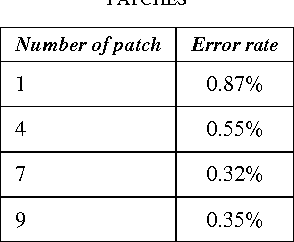
Face Recognition has been studied for many decades. As opposed to traditional hand-crafted features such as LBP and HOG, much more sophisticated features can be learned automatically by deep learning methods in a data-driven way. In this paper, we propose a two-stage approach that combines a multi-patch deep CNN and deep metric learning, which extracts low dimensional but very discriminative features for face verification and recognition. Experiments show that this method outperforms other state-of-the-art methods on LFW dataset, achieving 99.77% pair-wise verification accuracy and significantly better accuracy under other two more practical protocols. This paper also discusses the importance of data size and the number of patches, showing a clear path to practical high-performance face recognition systems in real world.