 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeColoring the Blank Slate: Pre-training Imparts a Hierarchical Inductive Bias to Sequence-to-sequence Models
Mar 17, 2022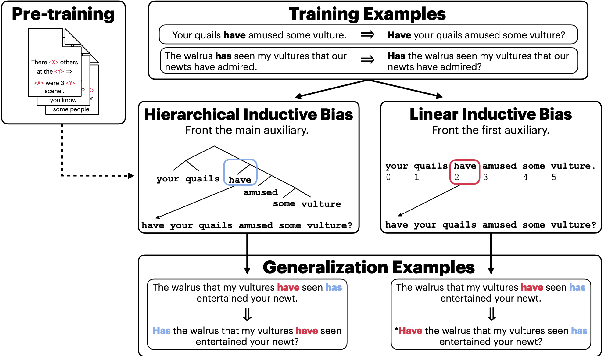


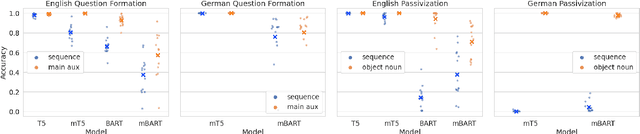
Relations between words are governed by hierarchical structure rather than linear ordering. Sequence-to-sequence (seq2seq) models, despite their success in downstream NLP applications, often fail to generalize in a hierarchy-sensitive manner when performing syntactic transformations - for example, transforming declarative sentences into questions. However, syntactic evaluations of seq2seq models have only observed models that were not pre-trained on natural language data before being trained to perform syntactic transformations, in spite of the fact that pre-training has been found to induce hierarchical linguistic generalizations in language models; in other words, the syntactic capabilities of seq2seq models may have been greatly understated. We address this gap using the pre-trained seq2seq models T5 and BART, as well as their multilingual variants mT5 and mBART. We evaluate whether they generalize hierarchically on two transformations in two languages: question formation and passivization in English and German. We find that pre-trained seq2seq models generalize hierarchically when performing syntactic transformations, whereas models trained from scratch on syntactic transformations do not. This result presents evidence for the learnability of hierarchical syntactic information from non-annotated natural language text while also demonstrating that seq2seq models are capable of syntactic generalization, though only after exposure to much more language data than human learners receive.
Improving Compositional Generalization with Latent Structure and Data Augmentation
Dec 14, 2021
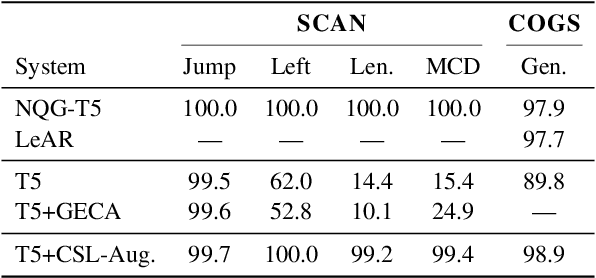
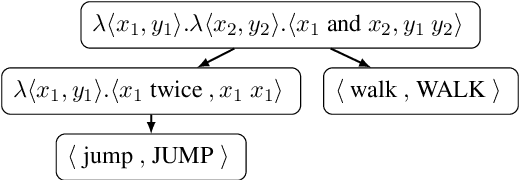
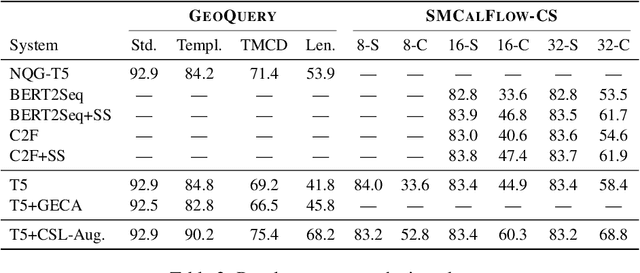
Generic unstructured neural networks have been shown to struggle on out-of-distribution compositional generalization. Compositional data augmentation via example recombination has transferred some prior knowledge about compositionality to such black-box neural models for several semantic parsing tasks, but this often required task-specific engineering or provided limited gains. We present a more powerful data recombination method using a model called Compositional Structure Learner (CSL). CSL is a generative model with a quasi-synchronous context-free grammar backbone, which we induce from the training data. We sample recombined examples from CSL and add them to the fine-tuning data of a pre-trained sequence-to-sequence model (T5). This procedure effectively transfers most of CSL's compositional bias to T5 for diagnostic tasks, and results in a model even stronger than a T5-CSL ensemble on two real world compositional generalization tasks. This results in new state-of-the-art performance for these challenging semantic parsing tasks requiring generalization to both natural language variation and novel compositions of elements.
How much do language models copy from their training data? Evaluating linguistic novelty in text generation using RAVEN
Nov 18, 2021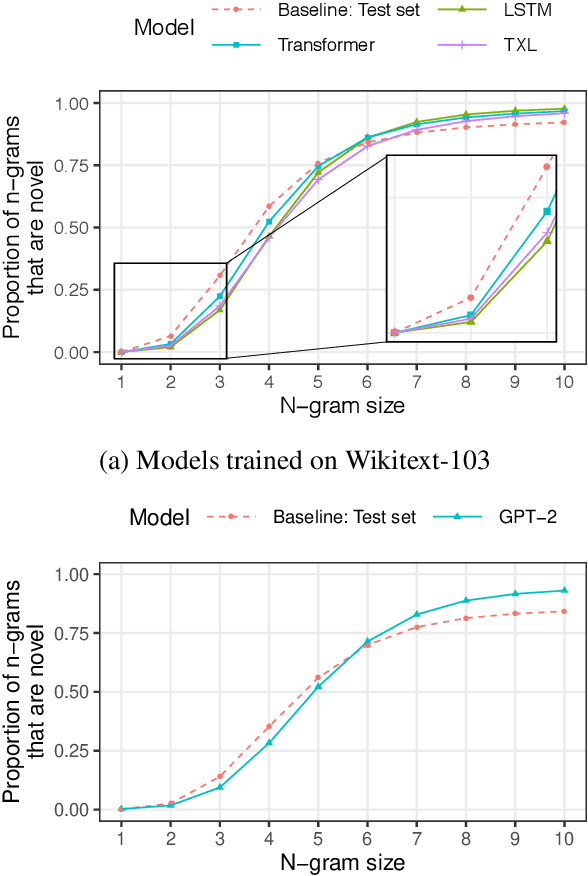
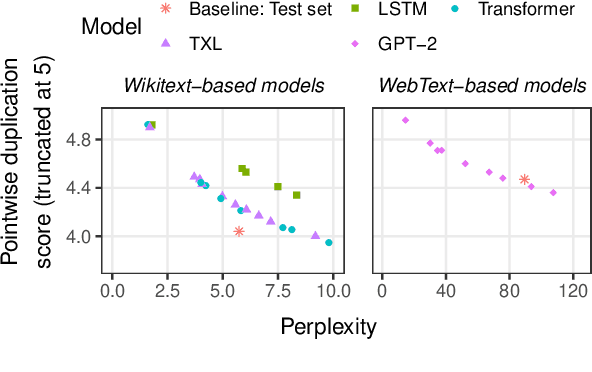
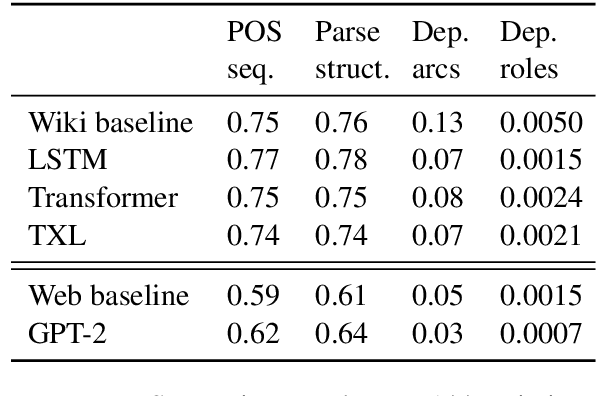
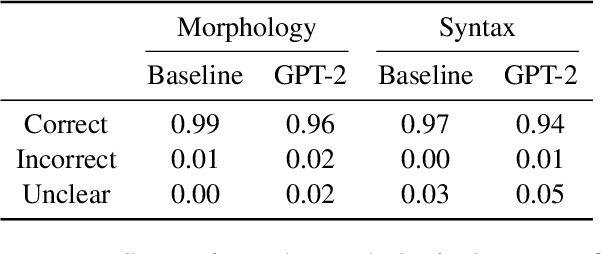
Current language models can generate high-quality text. Are they simply copying text they have seen before, or have they learned generalizable linguistic abstractions? To tease apart these possibilities, we introduce RAVEN, a suite of analyses for assessing the novelty of generated text, focusing on sequential structure (n-grams) and syntactic structure. We apply these analyses to four neural language models (an LSTM, a Transformer, Transformer-XL, and GPT-2). For local structure - e.g., individual dependencies - model-generated text is substantially less novel than our baseline of human-generated text from each model's test set. For larger-scale structure - e.g., overall sentence structure - model-generated text is as novel or even more novel than the human-generated baseline, but models still sometimes copy substantially, in some cases duplicating passages over 1,000 words long from the training set. We also perform extensive manual analysis showing that GPT-2's novel text is usually well-formed morphologically and syntactically but has reasonably frequent semantic issues (e.g., being self-contradictory).
Learning to Generalize Compositionally by Transferring Across Semantic Parsing Tasks
Nov 09, 2021

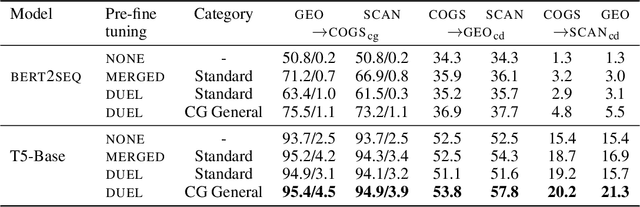

Neural network models often generalize poorly to mismatched domains or distributions. In NLP, this issue arises in particular when models are expected to generalize compositionally, that is, to novel combinations of familiar words and constructions. We investigate learning representations that facilitate transfer learning from one compositional task to another: the representation and the task-specific layers of the models are strategically trained differently on a pre-finetuning task such that they generalize well on mismatched splits that require compositionality. We apply this method to semantic parsing, using three very different datasets, COGS, GeoQuery and SCAN, used alternately as the pre-finetuning and target task. Our method significantly improves compositional generalization over baselines on the test set of the target task, which is held out during fine-tuning. Ablation studies characterize the utility of the major steps in the proposed algorithm and support our hypothesis.
The Language Model Understood the Prompt was Ambiguous: Probing Syntactic Uncertainty Through Generation
Sep 16, 2021
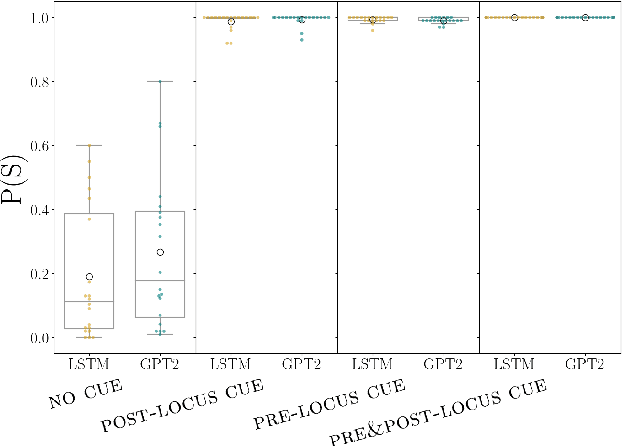

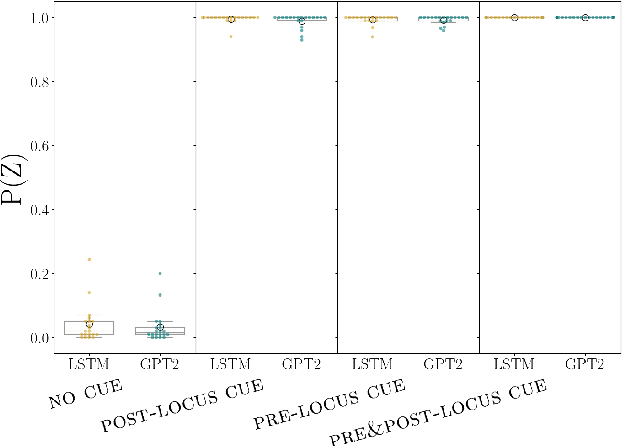
Temporary syntactic ambiguities arise when the beginning of a sentence is compatible with multiple syntactic analyses. We inspect to which extent neural language models (LMs) exhibit uncertainty over such analyses when processing temporarily ambiguous inputs, and how that uncertainty is modulated by disambiguating cues. We probe the LM's expectations by generating from it: we use stochastic decoding to derive a set of sentence completions, and estimate the probability that the LM assigns to each interpretation based on the distribution of parses across completions. Unlike scoring-based methods for targeted syntactic evaluation, this technique makes it possible to explore completions that are not hypothesized in advance by the researcher. We apply this method to study the behavior of two LMs (GPT2 and an LSTM) on three types of temporary ambiguity, using materials from human sentence processing experiments. We find that LMs can track multiple analyses simultaneously; the degree of uncertainty varies across constructions and contexts. As a response to disambiguating cues, the LMs often select the correct interpretation, but occasional errors point to potential areas of improvement.
Frequency Effects on Syntactic Rule Learning in Transformers
Sep 14, 2021
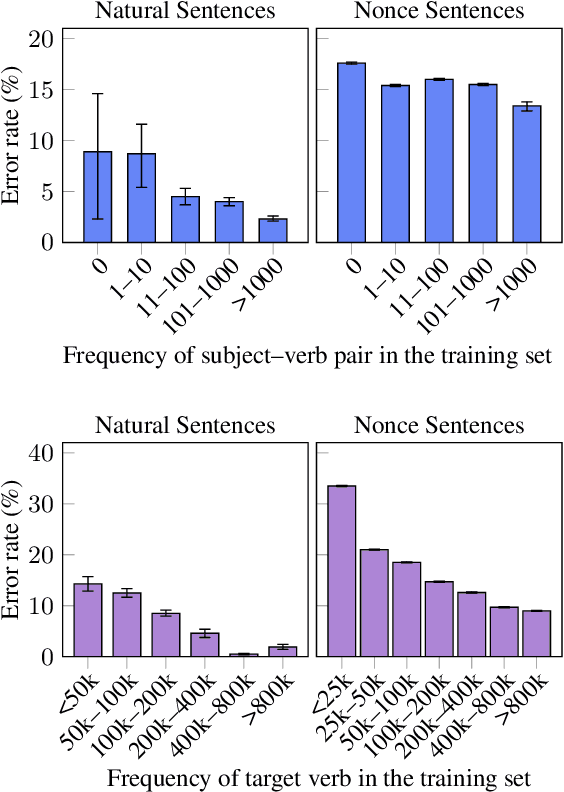
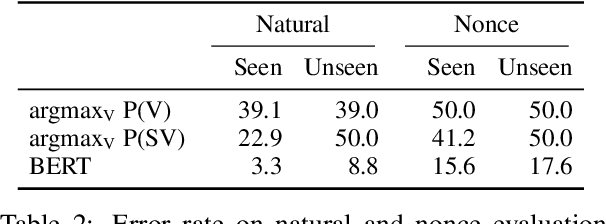
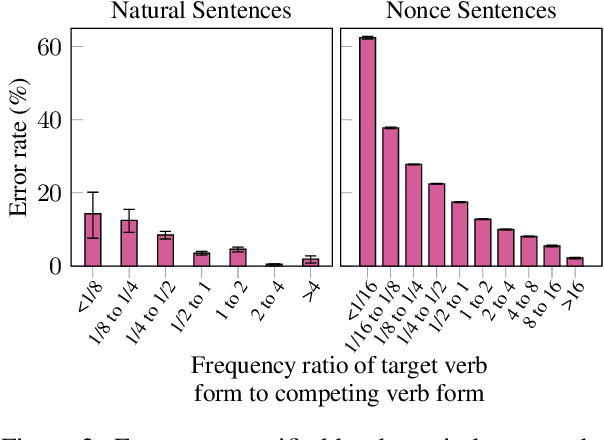
Pre-trained language models perform well on a variety of linguistic tasks that require symbolic reasoning, raising the question of whether such models implicitly represent abstract symbols and rules. We investigate this question using the case study of BERT's performance on English subject-verb agreement. Unlike prior work, we train multiple instances of BERT from scratch, allowing us to perform a series of controlled interventions at pre-training time. We show that BERT often generalizes well to subject-verb pairs that never occurred in training, suggesting a degree of rule-governed behavior. We also find, however, that performance is heavily influenced by word frequency, with experiments showing that both the absolute frequency of a verb form, as well as the frequency relative to the alternate inflection, are causally implicated in the predictions BERT makes at inference time. Closer analysis of these frequency effects reveals that BERT's behavior is consistent with a system that correctly applies the SVA rule in general but struggles to overcome strong training priors and to estimate agreement features (singular vs. plural) on infrequent lexical items.
NOPE: A Corpus of Naturally-Occurring Presuppositions in English
Sep 14, 2021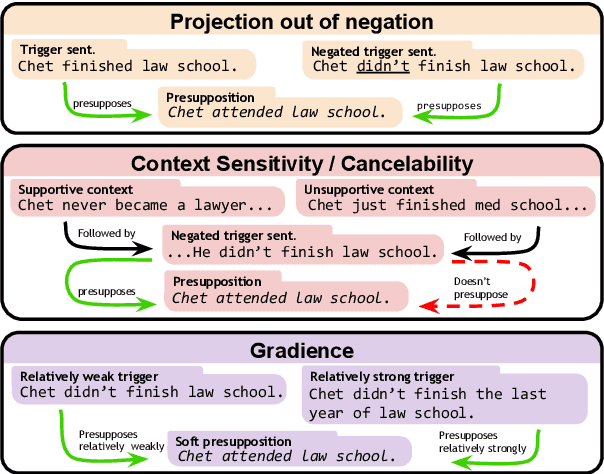
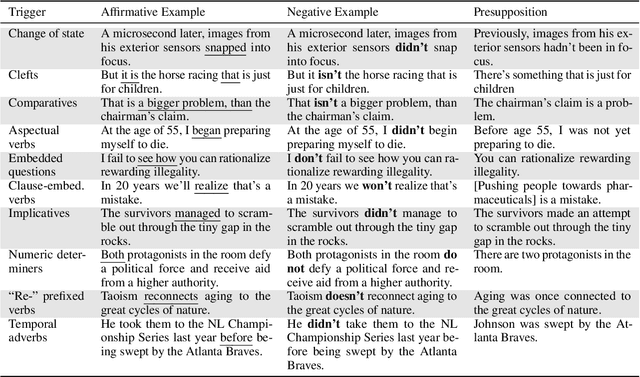
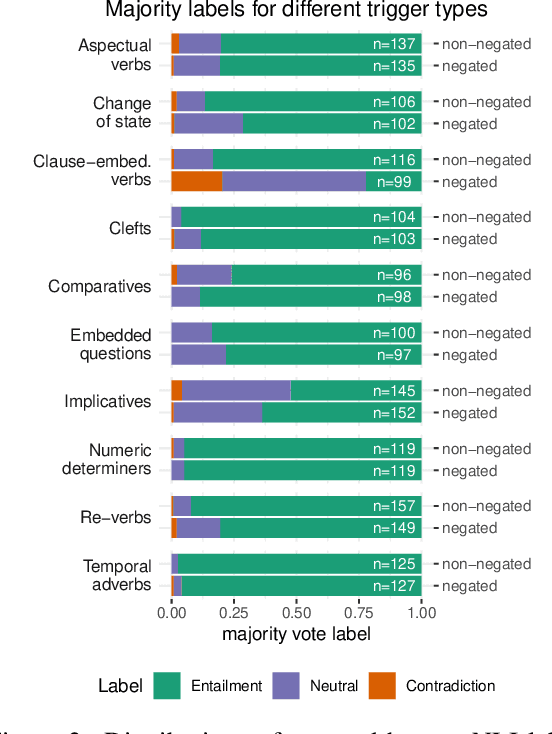
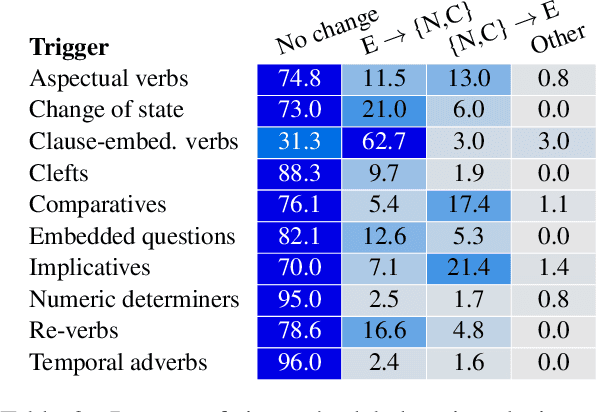
Understanding language requires grasping not only the overtly stated content, but also making inferences about things that were left unsaid. These inferences include presuppositions, a phenomenon by which a listener learns about new information through reasoning about what a speaker takes as given. Presuppositions require complex understanding of the lexical and syntactic properties that trigger them as well as the broader conversational context. In this work, we introduce the Naturally-Occurring Presuppositions in English (NOPE) Corpus to investigate the context-sensitivity of 10 different types of presupposition triggers and to evaluate machine learning models' ability to predict human inferences. We find that most of the triggers we investigate exhibit moderate variability. We further find that transformer-based models draw correct inferences in simple cases involving presuppositions, but they fail to capture the minority of exceptional cases in which human judgments reveal complex interactions between context and triggers.
The MultiBERTs: BERT Reproductions for Robustness Analysis
Jun 30, 2021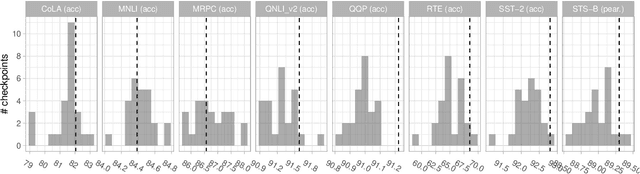
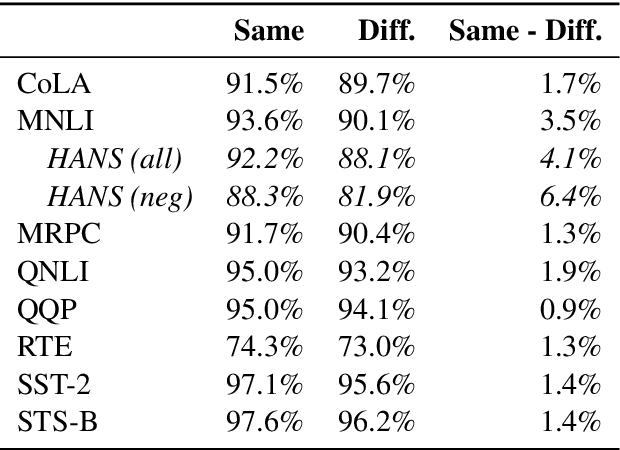
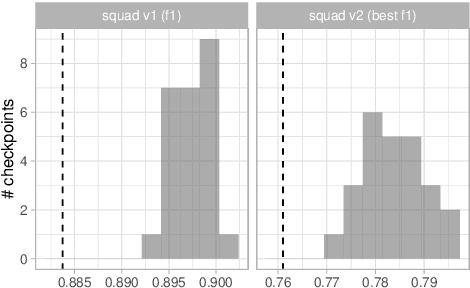
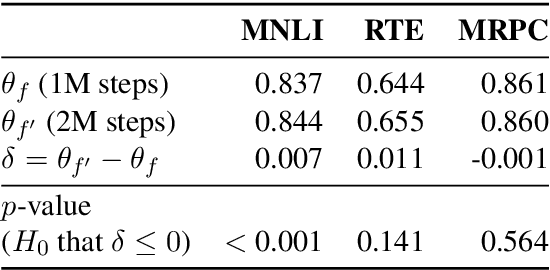
Experiments with pretrained models such as BERT are often based on a single checkpoint. While the conclusions drawn apply to the artifact (i.e., the particular instance of the model), it is not always clear whether they hold for the more general procedure (which includes the model architecture, training data, initialization scheme, and loss function). Recent work has shown that re-running pretraining can lead to substantially different conclusions about performance, suggesting that alternative evaluations are needed to make principled statements about procedures. To address this question, we introduce MultiBERTs: a set of 25 BERT-base checkpoints, trained with similar hyper-parameters as the original BERT model but differing in random initialization and data shuffling. The aim is to enable researchers to draw robust and statistically justified conclusions about pretraining procedures. The full release includes 25 fully trained checkpoints, as well as statistical guidelines and a code library implementing our recommended hypothesis testing methods. Finally, for five of these models we release a set of 28 intermediate checkpoints in order to support research on learning dynamics.
Causal Analysis of Syntactic Agreement Mechanisms in Neural Language Models
Jun 22, 2021

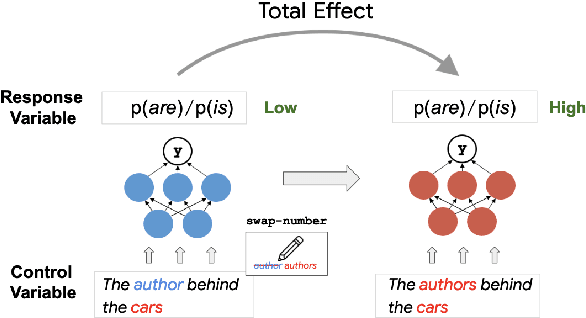
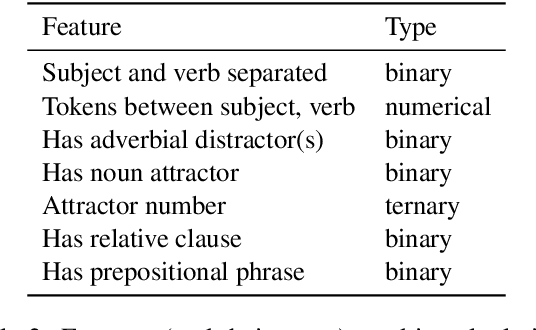
Targeted syntactic evaluations have demonstrated the ability of language models to perform subject-verb agreement given difficult contexts. To elucidate the mechanisms by which the models accomplish this behavior, this study applies causal mediation analysis to pre-trained neural language models. We investigate the magnitude of models' preferences for grammatical inflections, as well as whether neurons process subject-verb agreement similarly across sentences with different syntactic structures. We uncover similarities and differences across architectures and model sizes -- notably, that larger models do not necessarily learn stronger preferences. We also observe two distinct mechanisms for producing subject-verb agreement depending on the syntactic structure of the input sentence. Finally, we find that language models rely on similar sets of neurons when given sentences with similar syntactic structure.
Counterfactual Interventions Reveal the Causal Effect of Relative Clause Representations on Agreement Prediction
May 19, 2021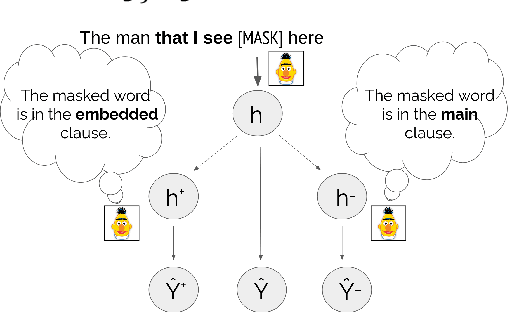

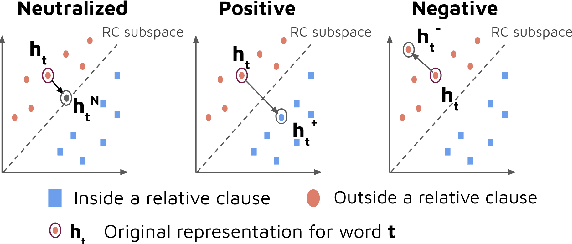
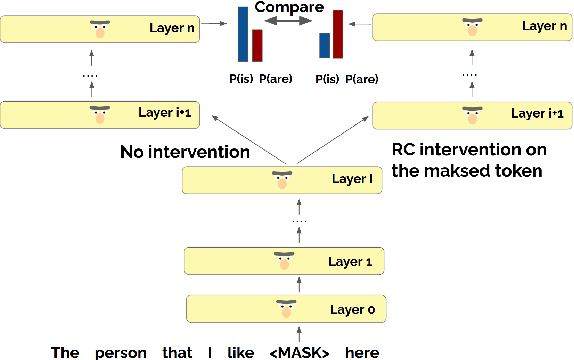
When language models process syntactically complex sentences, do they use abstract syntactic information present in these sentences in a manner that is consistent with the grammar of English, or do they rely solely on a set of heuristics? We propose a method to tackle this question, AlterRep. For any linguistic feature in the sentence, AlterRep allows us to generate counterfactual representations by altering how this feature is encoded, while leaving all other aspects of the original representation intact. Then, by measuring the change in a models' word prediction with these counterfactual representations in different sentences, we can draw causal conclusions about the contexts in which the model uses the linguistic feature (if any). Applying this method to study how BERT uses relative clause (RC) span information, we found that BERT uses information about RC spans during agreement prediction using the linguistically correct strategy. We also found that counterfactual representations generated for a specific RC subtype influenced the number prediction in sentences with other RC subtypes, suggesting that information about RC boundaries was encoded abstractly in BERT's representation.