 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuestion Answering over Knowledge Bases by Leveraging Semantic Parsing and Neuro-Symbolic Reasoning
Dec 03, 2020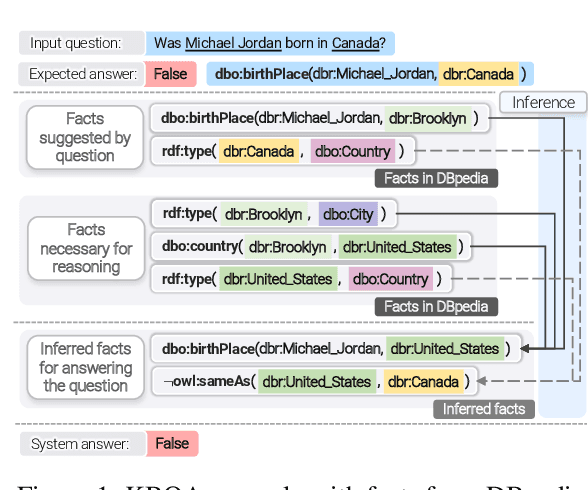
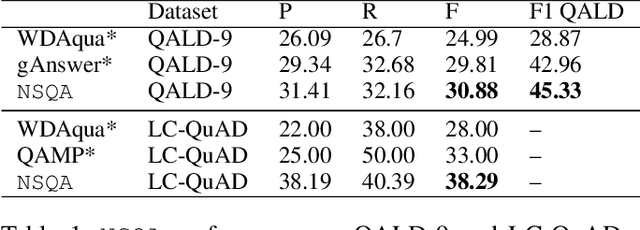
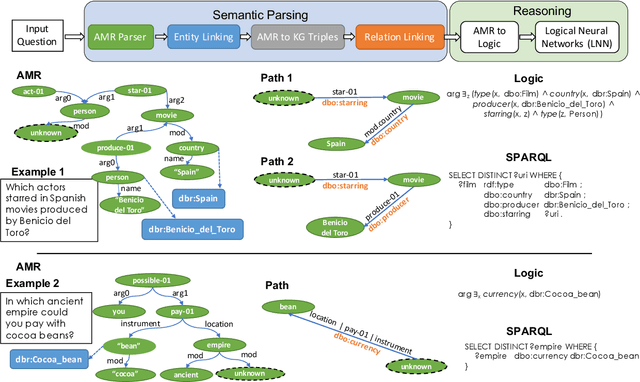

Knowledge base question answering (KBQA) is an important task in Natural Language Processing. Existing approaches face significant challenges including complex question understanding, necessity for reasoning, and lack of large training datasets. In this work, we propose a semantic parsing and reasoning-based Neuro-Symbolic Question Answering(NSQA) system, that leverages (1) Abstract Meaning Representation (AMR) parses for task-independent question under-standing; (2) a novel path-based approach to transform AMR parses into candidate logical queries that are aligned to the KB; (3) a neuro-symbolic reasoner called Logical Neural Net-work (LNN) that executes logical queries and reasons over KB facts to provide an answer; (4) system of systems approach,which integrates multiple, reusable modules that are trained specifically for their individual tasks (e.g. semantic parsing,entity linking, and relationship linking) and do not require end-to-end training data. NSQA achieves state-of-the-art performance on QALD-9 and LC-QuAD 1.0. NSQA's novelty lies in its modular neuro-symbolic architecture and its task-general approach to interpreting natural language questions.
Pushing the Limits of AMR Parsing with Self-Learning
Oct 20, 2020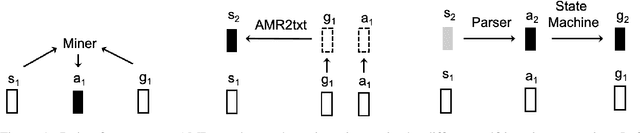

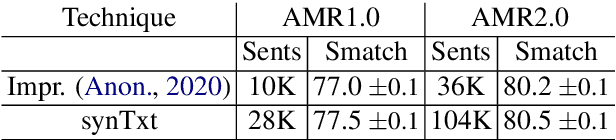
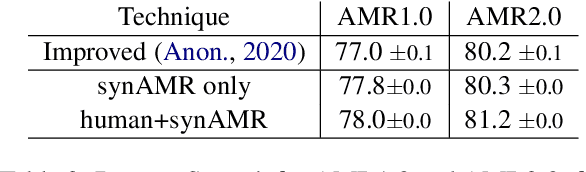
Abstract Meaning Representation (AMR) parsing has experienced a notable growth in performance in the last two years, due both to the impact of transfer learning and the development of novel architectures specific to AMR. At the same time, self-learning techniques have helped push the performance boundaries of other natural language processing applications, such as machine translation or question answering. In this paper, we explore different ways in which trained models can be applied to improve AMR parsing performance, including generation of synthetic text and AMR annotations as well as refinement of actions oracle. We show that, without any additional human annotations, these techniques improve an already performant parser and achieve state-of-the-art results on AMR 1.0 and AMR 2.0.
Transition-based Parsing with Stack-Transformers
Oct 20, 2020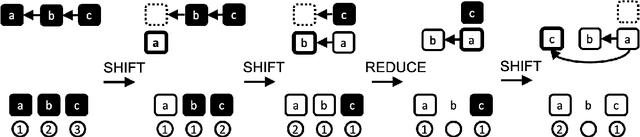

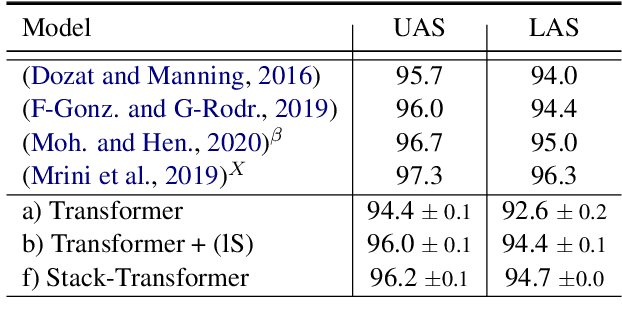
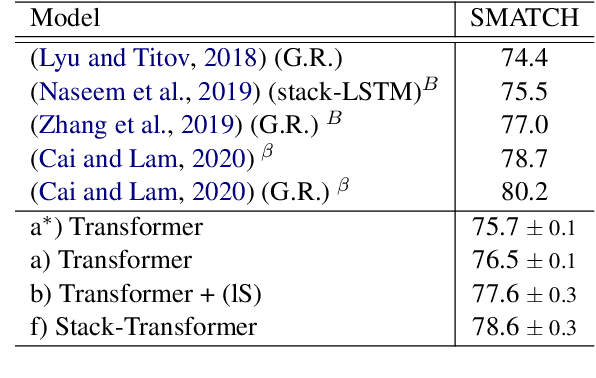
Modeling the parser state is key to good performance in transition-based parsing. Recurrent Neural Networks considerably improved the performance of transition-based systems by modelling the global state, e.g. stack-LSTM parsers, or local state modeling of contextualized features, e.g. Bi-LSTM parsers. Given the success of Transformer architectures in recent parsing systems, this work explores modifications of the sequence-to-sequence Transformer architecture to model either global or local parser states in transition-based parsing. We show that modifications of the cross attention mechanism of the Transformer considerably strengthen performance both on dependency and Abstract Meaning Representation (AMR) parsing tasks, particularly for smaller models or limited training data.
Event Presence Prediction Helps Trigger Detection Across Languages
Sep 15, 2020
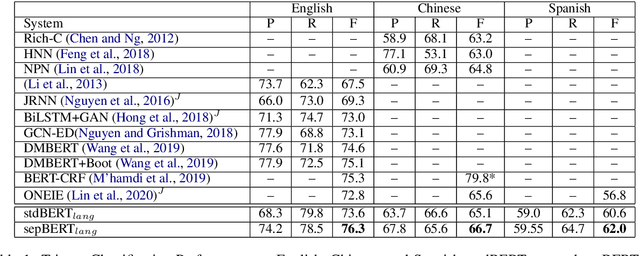
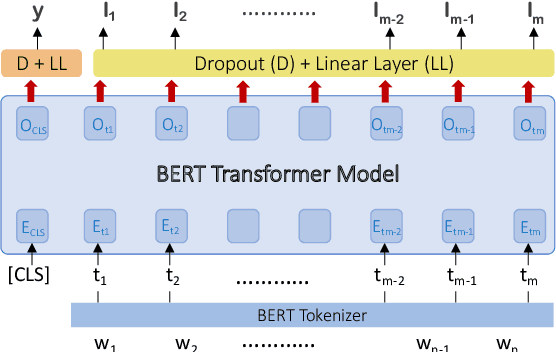
The task of event detection and classification is central to most information retrieval applications. We show that a Transformer based architecture can effectively model event extraction as a sequence labeling task. We propose a combination of sentence level and token level training objectives that significantly boosts the performance of a BERT based event extraction model. Our approach achieves a new state-of-the-art performance on ACE 2005 data for English and Chinese. We also test our model on ERE Spanish, achieving an average gain of 2 absolute F1 points over prior best performing model.
GPT-too: A language-model-first approach for AMR-to-text generation
May 27, 2020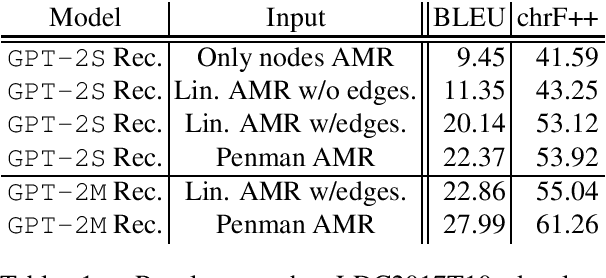

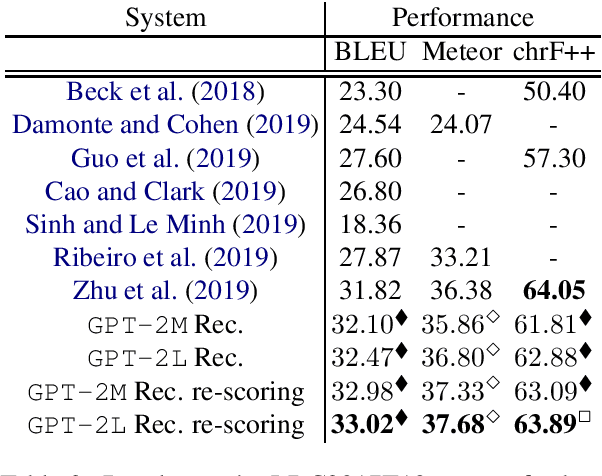
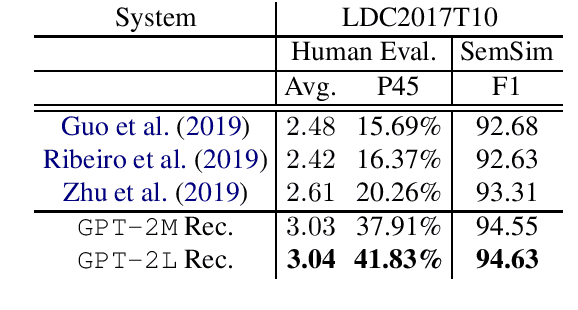
Meaning Representations (AMRs) are broad-coverage sentence-level semantic graphs. Existing approaches to generating text from AMR have focused on training sequence-to-sequence or graph-to-sequence models on AMR annotated data only. In this paper, we propose an alternative approach that combines a strong pre-trained language model with cycle consistency-based re-scoring. Despite the simplicity of the approach, our experimental results show these models outperform all previous techniques on the English LDC2017T10dataset, including the recent use of transformer architectures. In addition to the standard evaluation metrics, we provide human evaluation experiments that further substantiate the strength of our approach.
Rewarding Smatch: Transition-Based AMR Parsing with Reinforcement Learning
May 31, 2019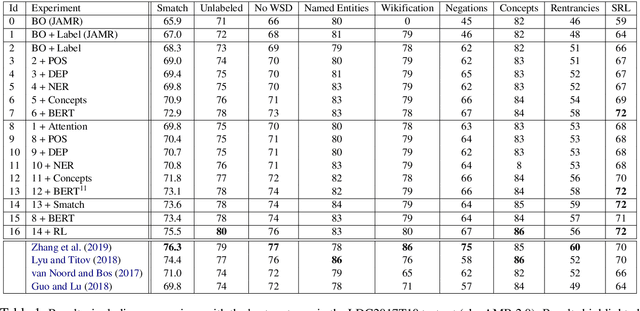
Our work involves enriching the Stack-LSTM transition-based AMR parser (Ballesteros and Al-Onaizan, 2017) by augmenting training with Policy Learning and rewarding the Smatch score of sampled graphs. In addition, we also combined several AMR-to-text alignments with an attention mechanism and we supplemented the parser with pre-processed concept identification, named entities and contextualized embeddings. We achieve a highly competitive performance that is comparable to the best published results. We show an in-depth study ablating each of the new components of the parser
Multilingual Part-of-Speech Tagging: Two Unsupervised Approaches
Jan 15, 2014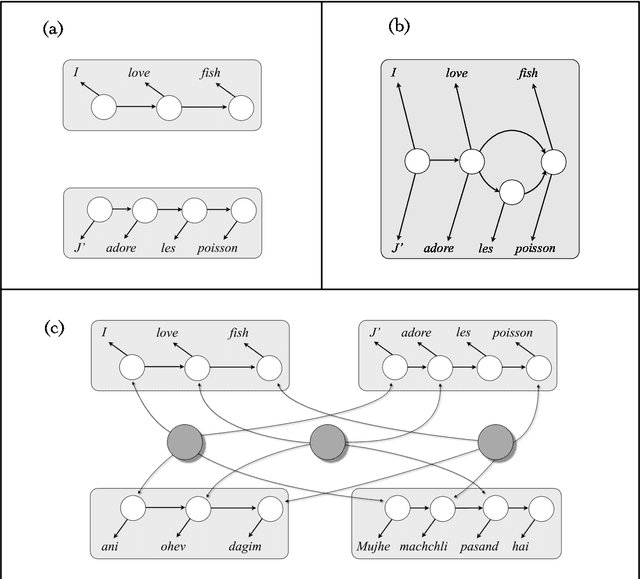
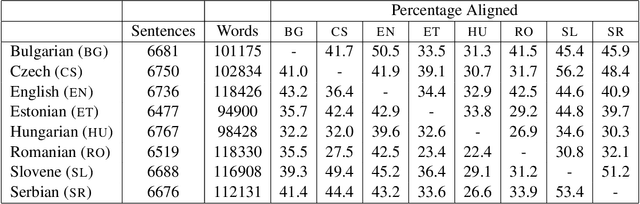
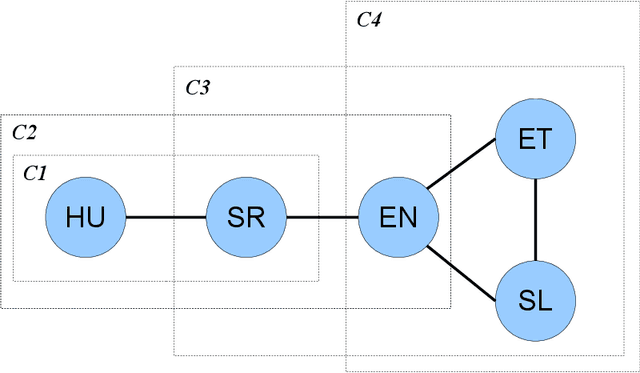
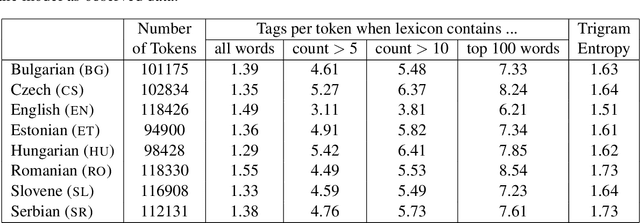
We demonstrate the effectiveness of multilingual learning for unsupervised part-of-speech tagging. The central assumption of our work is that by combining cues from multiple languages, the structure of each becomes more apparent. We consider two ways of applying this intuition to the problem of unsupervised part-of-speech tagging: a model that directly merges tag structures for a pair of languages into a single sequence and a second model which instead incorporates multilingual context using latent variables. Both approaches are formulated as hierarchical Bayesian models, using Markov Chain Monte Carlo sampling techniques for inference. Our results demonstrate that by incorporating multilingual evidence we can achieve impressive performance gains across a range of scenarios. We also found that performance improves steadily as the number of available languages increases.