 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgent Security is a Systems Problem
May 20, 2026We take the position that agent security must be approached as a systems problem: the AI model powering the agent must be treated as an untrusted component, and security invariants must be enforced at the system level. Through this lens, efforts to increase model robustness (the dominant viewpoint in the community) are insufficient on their own. Instead, we must complement existing efforts with techniques from the systems security domain. Based on our experience as cybersecurity researchers in operating systems, networks, formal methods, and adversarial machine learning, we articulate a set of core principles, grounded in decades of systems security research, that provide a foundation for designing agentic systems with predictable guarantees. As evidence, we analyze eleven representative real-world attacks on agents and discuss how systems principles, if realized, could have prevented these attacks. We also identify the research challenges that stand in the way of implementing these principles in agents.
May I have your Attention? Breaking Fine-Tuning based Prompt Injection Defenses using Architecture-Aware Attacks
Jul 10, 2025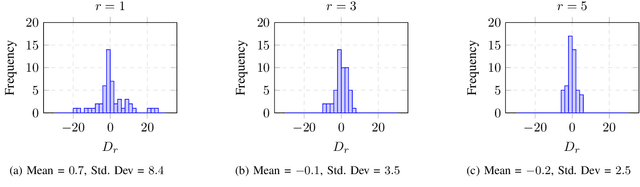
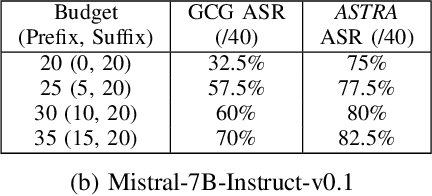
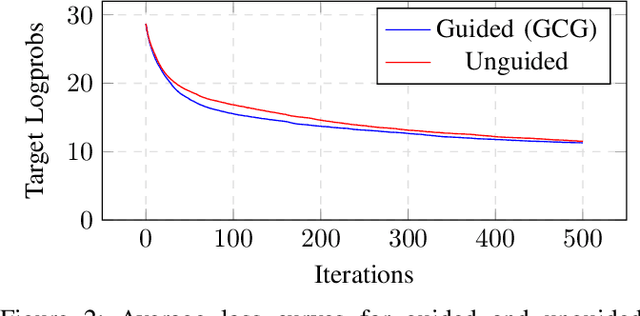

A popular class of defenses against prompt injection attacks on large language models (LLMs) relies on fine-tuning the model to separate instructions and data, so that the LLM does not follow instructions that might be present with data. There are several academic systems and production-level implementations of this idea. We evaluate the robustness of this class of prompt injection defenses in the whitebox setting by constructing strong optimization-based attacks and showing that the defenses do not provide the claimed security properties. Specifically, we construct a novel attention-based attack algorithm for text-based LLMs and apply it to two recent whitebox defenses SecAlign (CCS 2025) and StruQ (USENIX Security 2025), showing attacks with success rates of up to 70% with modest increase in attacker budget in terms of tokens. Our findings make fundamental progress towards understanding the robustness of prompt injection defenses in the whitebox setting. We release our code and attacks at https://github.com/nishitvp/better_opts_attacks
Re-purposing Perceptual Hashing based Client Side Scanning for Physical Surveillance
Dec 08, 2022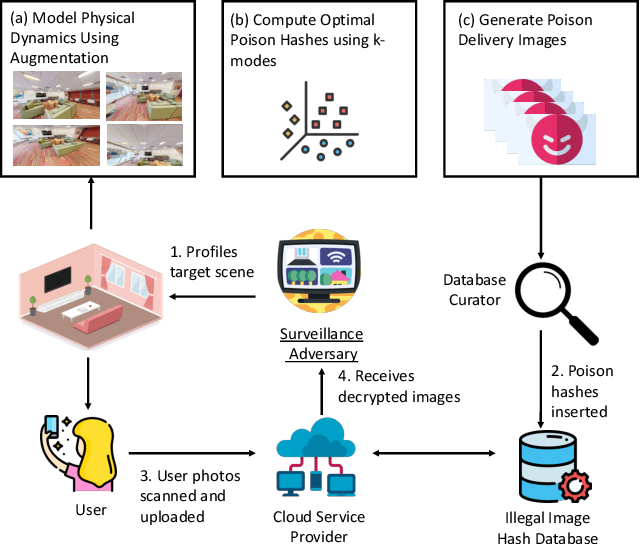
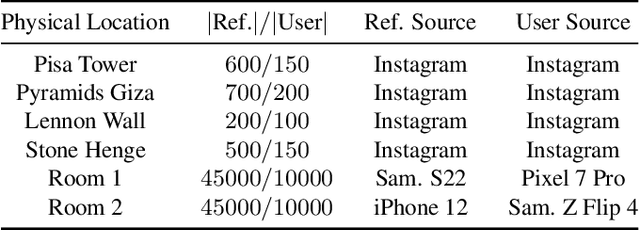
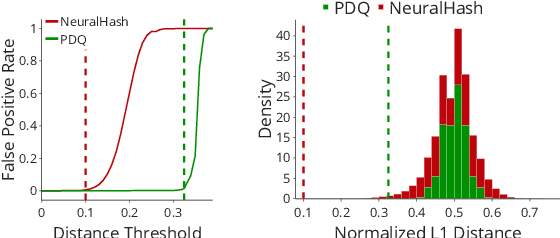

Content scanning systems employ perceptual hashing algorithms to scan user content for illegal material, such as child pornography or terrorist recruitment flyers. Perceptual hashing algorithms help determine whether two images are visually similar while preserving the privacy of the input images. Several efforts from industry and academia propose to conduct content scanning on client devices such as smartphones due to the impending roll out of end-to-end encryption that will make server-side content scanning difficult. However, these proposals have met with strong criticism because of the potential for the technology to be misused and re-purposed. Our work informs this conversation by experimentally characterizing the potential for one type of misuse -- attackers manipulating the content scanning system to perform physical surveillance on target locations. Our contributions are threefold: (1) we offer a definition of physical surveillance in the context of client-side image scanning systems; (2) we experimentally characterize this risk and create a surveillance algorithm that achieves physical surveillance rates of >40% by poisoning 5% of the perceptual hash database; (3) we experimentally study the trade-off between the robustness of client-side image scanning systems and surveillance, showing that more robust detection of illegal material leads to increased potential for physical surveillance.
Overview of Abusive and Threatening Language Detection in Urdu at FIRE 2021
Jul 14, 2022



With the growth of social media platform influence, the effect of their misuse becomes more and more impactful. The importance of automatic detection of threatening and abusive language can not be overestimated. However, most of the existing studies and state-of-the-art methods focus on English as the target language, with limited work on low- and medium-resource languages. In this paper, we present two shared tasks of abusive and threatening language detection for the Urdu language which has more than 170 million speakers worldwide. Both are posed as binary classification tasks where participating systems are required to classify tweets in Urdu into two classes, namely: (i) Abusive and Non-Abusive for the first task, and (ii) Threatening and Non-Threatening for the second. We present two manually annotated datasets containing tweets labelled as (i) Abusive and Non-Abusive, and (ii) Threatening and Non-Threatening. The abusive dataset contains 2400 annotated tweets in the train part and 1100 annotated tweets in the test part. The threatening dataset contains 6000 annotated tweets in the train part and 3950 annotated tweets in the test part. We also provide logistic regression and BERT-based baseline classifiers for both tasks. In this shared task, 21 teams from six countries registered for participation (India, Pakistan, China, Malaysia, United Arab Emirates, and Taiwan), 10 teams submitted their runs for Subtask A, which is Abusive Language Detection and 9 teams submitted their runs for Subtask B, which is Threatening Language detection, and seven teams submitted their technical reports. The best performing system achieved an F1-score value of 0.880 for Subtask A and 0.545 for Subtask B. For both subtasks, m-Bert based transformer model showed the best performance.