 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-Fidelity Image Generation With Fewer Labels
Mar 06, 2019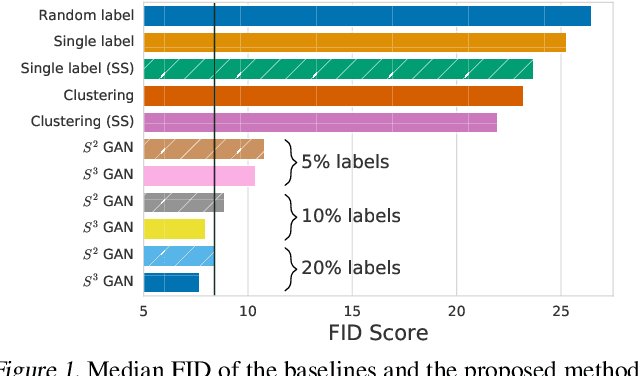

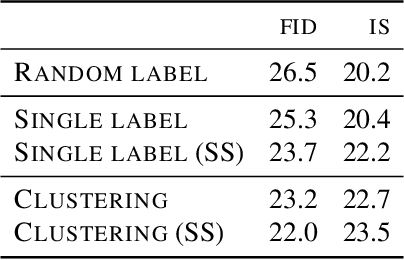
Deep generative models are becoming a cornerstone of modern machine learning. Recent work on conditional generative adversarial networks has shown that learning complex, high-dimensional distributions over natural images is within reach. While the latest models are able to generate high-fidelity, diverse natural images at high resolution, they rely on a vast quantity of labeled data. In this work we demonstrate how one can benefit from recent work on self- and semi-supervised learning to outperform state-of-the-art (SOTA) on both unsupervised ImageNet synthesis, as well as in the conditional setting. In particular, the proposed approach is able to match the sample quality (as measured by FID) of the current state-of-the art conditional model BigGAN on ImageNet using only 10% of the labels and outperform it using 20% of the labels.
Episodic Curiosity through Reachability
Feb 22, 2019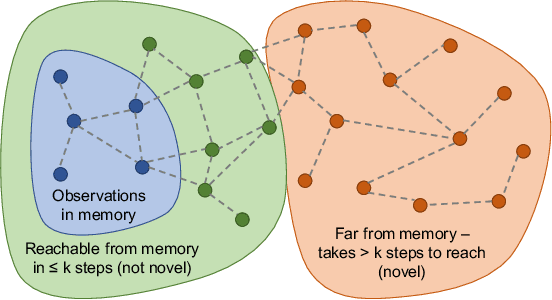
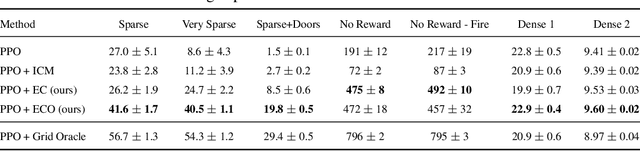
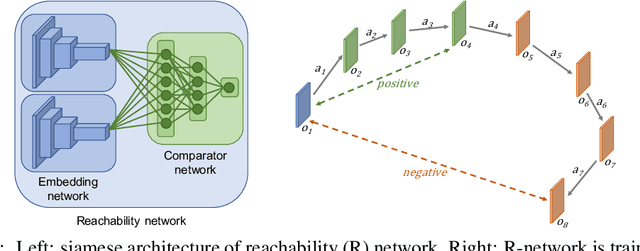
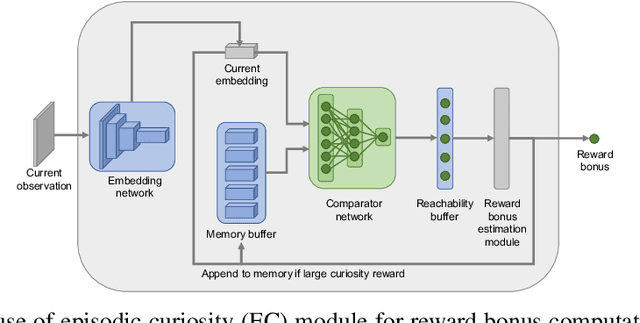
Rewards are sparse in the real world and most today's reinforcement learning algorithms struggle with such sparsity. One solution to this problem is to allow the agent to create rewards for itself - thus making rewards dense and more suitable for learning. In particular, inspired by curious behaviour in animals, observing something novel could be rewarded with a bonus. Such bonus is summed up with the real task reward - making it possible for RL algorithms to learn from the combined reward. We propose a new curiosity method which uses episodic memory to form the novelty bonus. To determine the bonus, the current observation is compared with the observations in memory. Crucially, the comparison is done based on how many environment steps it takes to reach the current observation from those in memory - which incorporates rich information about environment dynamics. This allows us to overcome the known "couch-potato" issues of prior work - when the agent finds a way to instantly gratify itself by exploiting actions which lead to hardly predictable consequences. We test our approach in visually rich 3D environments in ViZDoom, DMLab and MuJoCo. In navigational tasks from ViZDoom and DMLab, our agent outperforms the state-of-the-art curiosity method ICM. In MuJoCo, an ant equipped with our curiosity module learns locomotion out of the first-person-view curiosity only.
Breaking the Softmax Bottleneck via Learnable Monotonic Pointwise Non-linearities
Feb 21, 2019
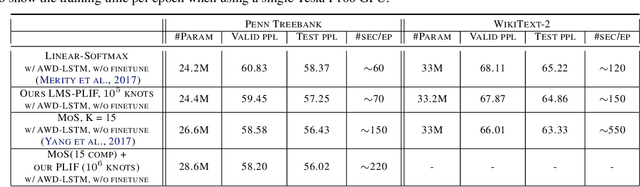
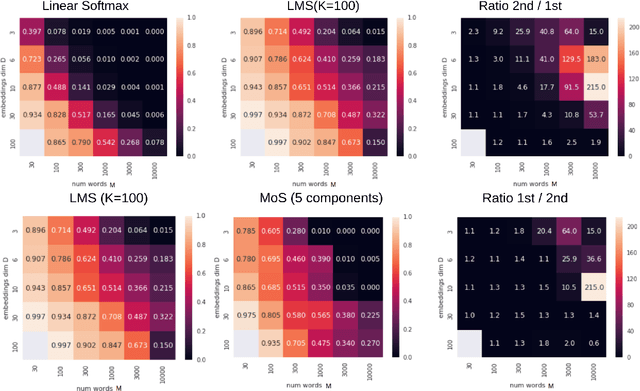
The softmax function on top of a final linear layer is the de facto method to output probability distributions in neural networks. In many applications such as language models or text generation, this model has to produce distributions over large output vocabularies. Recently, this has been shown to have limited representational capacity due to its connection with the rank bottleneck in matrix factorization. However, little is known about the limitations of linear-softmax for quantities of practical interest such as cross entropy or mode estimation, a direction that we theoretically and empirically explore here. As an efficient and effective solution to alleviate this issue, we propose to learn parametric monotonic functions on top of the logits. We theoretically investigate the rank increasing capabilities of such monotonic functions. Empirically, our method improves in two different quality metrics over the traditional softmax-linear layer in synthetic and real language model experiments, adding little time or memory overhead, while being comparable to the more computationally expensive mixture of softmaxes.
Parameter-Efficient Transfer Learning for NLP
Feb 02, 2019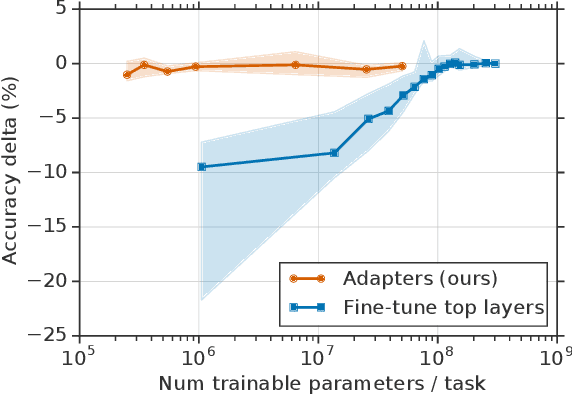

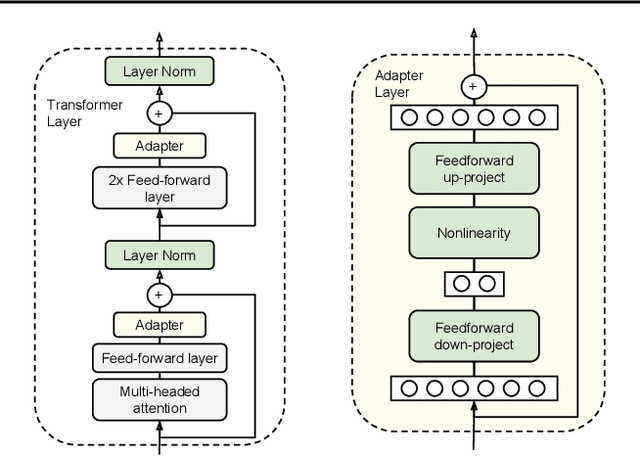
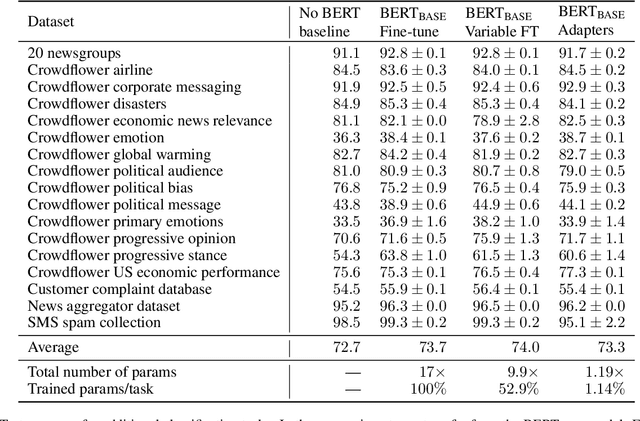
Fine-tuning large pre-trained models is an effective transfer mechanism in NLP. However, in the presence of many downstream tasks, fine-tuning is parameter inefficient: an entire new model is required for every task. As an alternative, we propose transfer with adapter modules. Adapter modules yield a compact and extensible model; they add only a few trainable parameters per task, and new tasks can be added without revisiting previous ones. The parameters of the original network remain fixed, yielding a high degree of parameter sharing. To demonstrate adapter's effectiveness, we transfer the recently proposed BERT Transformer model to 26 diverse text classification tasks, including the GLUE benchmark. Adapters attain near state-of-the-art performance, whilst adding only a few parameters per task. On GLUE, we attain within 0.4% of the performance of full fine-tuning, adding only 3.6% parameters per task. By contrast, fine-tuning trains 100% of the parameters per task.
Towards Accurate Generative Models of Video: A New Metric & Challenges
Dec 03, 2018

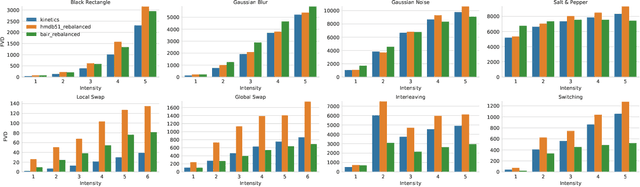
Recent advances in deep generative models have lead to remarkable progress in synthesizing high quality images. Following their successful application in image processing and representation learning, an important next step is to consider videos. Learning generative models of video is a much harder task, requiring a model to capture the temporal dynamics of a scene, in addition to the visual presentation of objects. Although recent attempts at formulating generative models of video have had some success, current progress is hampered by (1) the lack of qualitative metrics that consider visual quality, temporal coherence, and diversity of samples, and (2) the wide gap between purely synthetic video datasets and challenging real-world datasets in terms of complexity. To this extent we propose Fr\'echet Video Distance (FVD), a new metric for generative models of video based on FID, and StarCraft 2 Videos (SCV), a collection of progressively harder datasets that challenge the capabilities of the current iteration of generative models for video. We conduct a large-scale human study, which confirms that FVD correlates well with qualitative human judgment of generated videos, and provide initial benchmark results on SCV.
Challenging Common Assumptions in the Unsupervised Learning of Disentangled Representations
Dec 02, 2018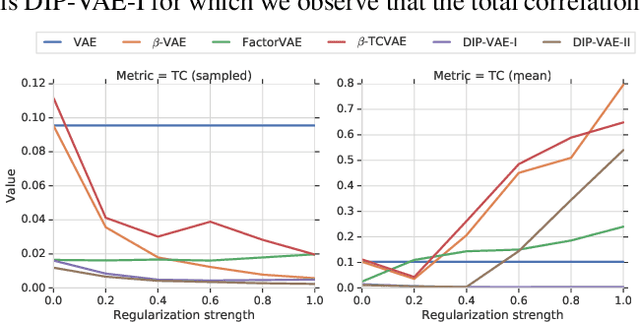

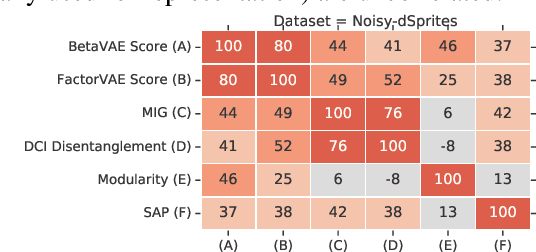

In recent years, the interest in unsupervised learning of disentangled representations has significantly increased. The key assumption is that real-world data is generated by a few explanatory factors of variation and that these factors can be recovered by unsupervised learning algorithms. A large number of unsupervised learning approaches based on auto-encoding and quantitative evaluation metrics of disentanglement have been proposed; yet, the efficacy of the proposed approaches and utility of proposed notions of disentanglement has not been challenged in prior work. In this paper, we provide a sober look on recent progress in the field and challenge some common assumptions. We first theoretically show that the unsupervised learning of disentangled representations is fundamentally impossible without inductive biases on both the models and the data. Then, we train more than 12000 models covering the six most prominent methods, and evaluate them across six disentanglement metrics in a reproducible large-scale experimental study on seven different data sets. On the positive side, we observe that different methods successfully enforce properties "encouraged" by the corresponding losses. On the negative side, we observe in our study that well-disentangled models seemingly cannot be identified without access to ground-truth labels even if we are allowed to transfer hyperparameters across data sets. Furthermore, increased disentanglement does not seem to lead to a decreased sample complexity of learning for downstream tasks. These results suggest that future work on disentanglement learning should be explicit about the role of inductive biases and (implicit) supervision, investigate concrete benefits of enforcing disentanglement of the learned representations, and consider a reproducible experimental setup covering several data sets.
Are GANs Created Equal? A Large-Scale Study
Oct 29, 2018
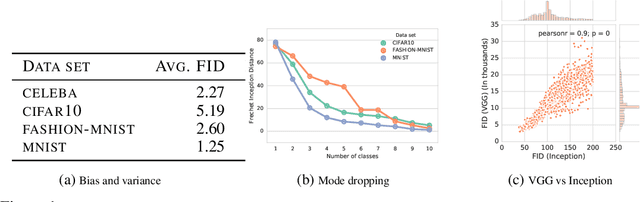
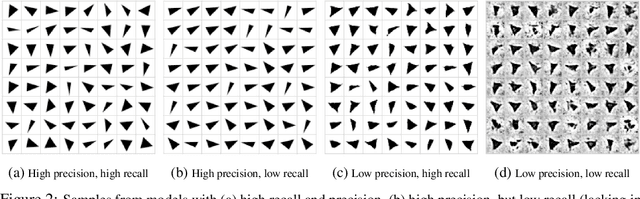
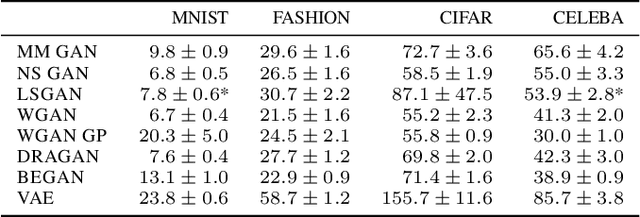
Generative adversarial networks (GAN) are a powerful subclass of generative models. Despite a very rich research activity leading to numerous interesting GAN algorithms, it is still very hard to assess which algorithm(s) perform better than others. We conduct a neutral, multi-faceted large-scale empirical study on state-of-the art models and evaluation measures. We find that most models can reach similar scores with enough hyperparameter optimization and random restarts. This suggests that improvements can arise from a higher computational budget and tuning more than fundamental algorithmic changes. To overcome some limitations of the current metrics, we also propose several data sets on which precision and recall can be computed. Our experimental results suggest that future GAN research should be based on more systematic and objective evaluation procedures. Finally, we did not find evidence that any of the tested algorithms consistently outperforms the non-saturating GAN introduced in \cite{goodfellow2014generative}.
Assessing Generative Models via Precision and Recall
Oct 28, 2018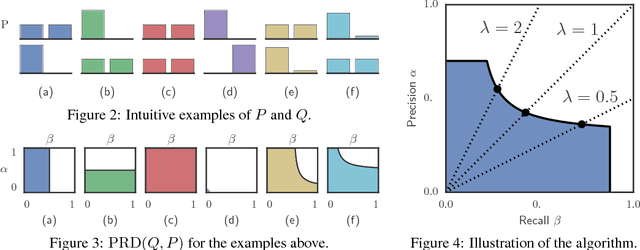
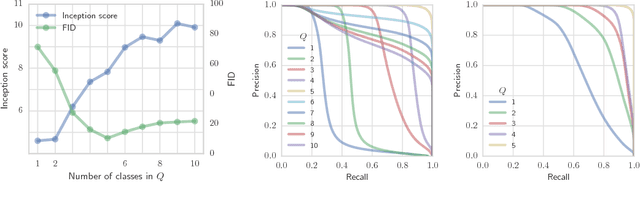
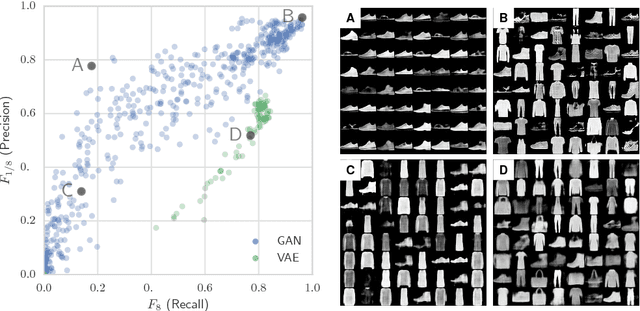
Recent advances in generative modeling have led to an increased interest in the study of statistical divergences as means of model comparison. Commonly used evaluation methods, such as the Frechet Inception Distance (FID), correlate well with the perceived quality of samples and are sensitive to mode dropping. However, these metrics are unable to distinguish between different failure cases since they only yield one-dimensional scores. We propose a novel definition of precision and recall for distributions which disentangles the divergence into two separate dimensions. The proposed notion is intuitive, retains desirable properties, and naturally leads to an efficient algorithm that can be used to evaluate generative models. We relate this notion to total variation as well as to recent evaluation metrics such as Inception Score and FID. To demonstrate the practical utility of the proposed approach we perform an empirical study on several variants of Generative Adversarial Networks and Variational Autoencoders. In an extensive set of experiments we show that the proposed metric is able to disentangle the quality of generated samples from the coverage of the target distribution.
The GAN Landscape: Losses, Architectures, Regularization, and Normalization
Oct 26, 2018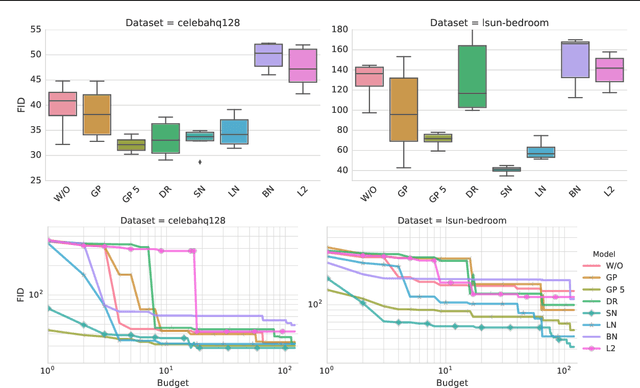

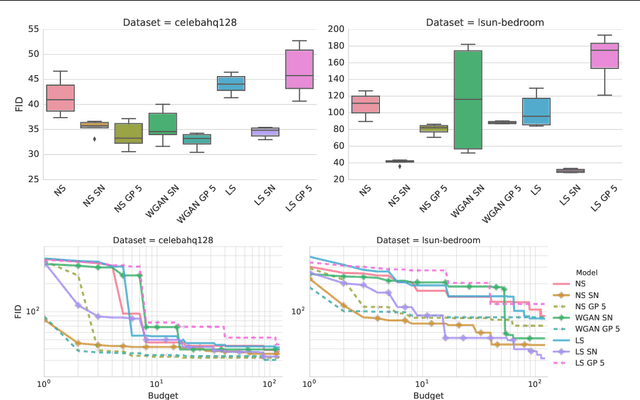
Generative adversarial networks (GANs) are a class of deep generative models which aim to learn a target distribution in an unsupervised fashion. While they were successfully applied to many problems, training a GAN is a notoriously challenging task and requires a significant amount of hyperparameter tuning, neural architecture engineering, and a non-trivial amount of "tricks". The success in many practical applications coupled with the lack of a measure to quantify the failure modes of GANs resulted in a plethora of proposed losses, regularization and normalization schemes, and neural architectures. In this work we take a sober view of the current state of GANs from a practical perspective. We reproduce the current state of the art and go beyond fairly exploring the GAN landscape. We discuss common pitfalls and reproducibility issues, open-source our code on Github, and provide pre-trained models on TensorFlow Hub.
A Case for Object Compositionality in Deep Generative Models of Images
Oct 17, 2018
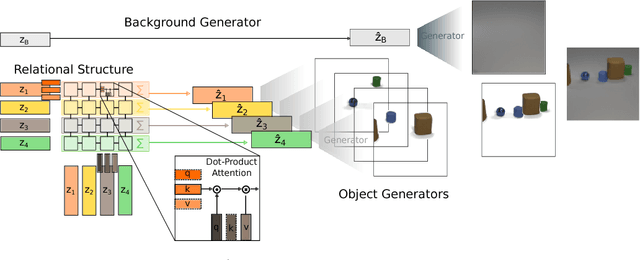

Deep generative models seek to recover the process with which the observed data was generated. They may be used to synthesize new samples or to subsequently extract representations. Successful approaches in the domain of images are driven by several core inductive biases. However, a bias to account for the compositional way in which humans structure a visual scene in terms of objects has frequently been overlooked. In this work we propose to structure the generator of a GAN to consider objects and their relations explicitly, and generate images by means of composition. This provides a way to efficiently learn a more accurate generative model of real-world images, and serves as an initial step towards learning corresponding object representations. We evaluate our approach on several multi-object image datasets, and find that the generator learns to identify and disentangle information corresponding to different objects at a representational level. A human study reveals that the resulting generative model is better at generating images that are more faithful to the reference distribution.