 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext-aware Fine-tuning of Self-supervised Speech Models
Dec 16, 2022



Self-supervised pre-trained transformers have improved the state of the art on a variety of speech tasks. Due to the quadratic time and space complexity of self-attention, they usually operate at the level of relatively short (e.g., utterance) segments. In this paper, we study the use of context, i.e., surrounding segments, during fine-tuning and propose a new approach called context-aware fine-tuning. We attach a context module on top of the last layer of a pre-trained model to encode the whole segment into a context embedding vector which is then used as an additional feature for the final prediction. During the fine-tuning stage, we introduce an auxiliary loss that encourages this context embedding vector to be similar to context vectors of surrounding segments. This allows the model to make predictions without access to these surrounding segments at inference time and requires only a tiny overhead compared to standard fine-tuned models. We evaluate the proposed approach using the SLUE and Librilight benchmarks for several downstream tasks: Automatic speech recognition (ASR), named entity recognition (NER), and sentiment analysis (SA). The results show that context-aware fine-tuning not only outperforms a standard fine-tuning baseline but also rivals a strong context injection baseline that uses neighboring speech segments during inference.
On the Use of External Data for Spoken Named Entity Recognition
Dec 14, 2021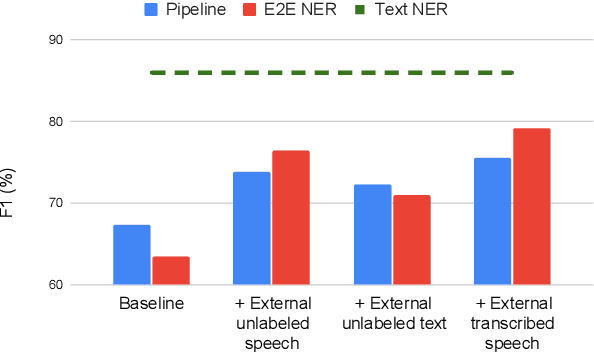

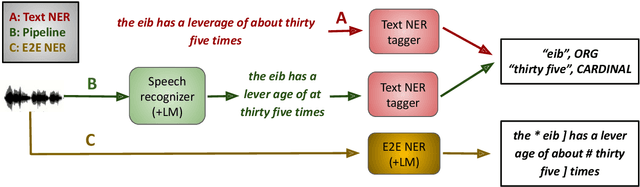
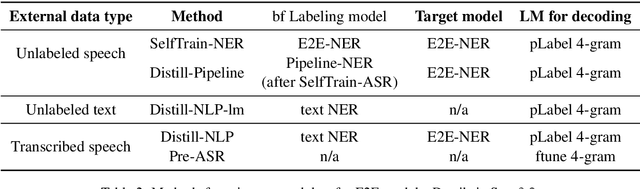
Spoken language understanding (SLU) tasks involve mapping from speech audio signals to semantic labels. Given the complexity of such tasks, good performance might be expected to require large labeled datasets, which are difficult to collect for each new task and domain. However, recent advances in self-supervised speech representations have made it feasible to consider learning SLU models with limited labeled data. In this work we focus on low-resource spoken named entity recognition (NER) and address the question: Beyond self-supervised pre-training, how can we use external speech and/or text data that are not annotated for the task? We draw on a variety of approaches, including self-training, knowledge distillation, and transfer learning, and consider their applicability to both end-to-end models and pipeline (speech recognition followed by text NER model) approaches. We find that several of these approaches improve performance in resource-constrained settings beyond the benefits from pre-trained representations alone. Compared to prior work, we find improved F1 scores of up to 16%. While the best baseline model is a pipeline approach, the best performance when using external data is ultimately achieved by an end-to-end model. We provide detailed comparisons and analyses, showing for example that end-to-end models are able to focus on the more NER-specific words.
SLUE: New Benchmark Tasks for Spoken Language Understanding Evaluation on Natural Speech
Nov 19, 2021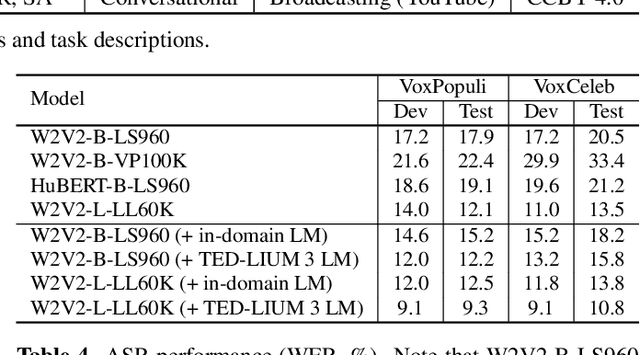
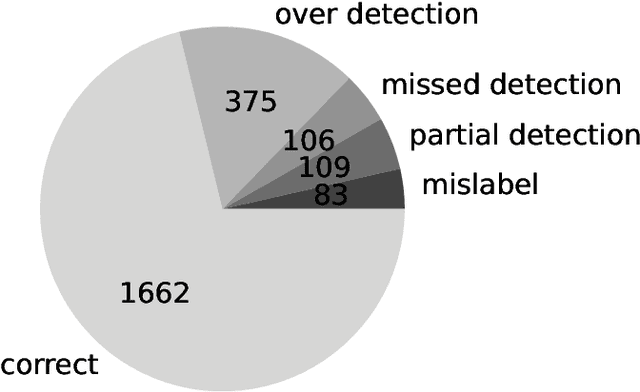
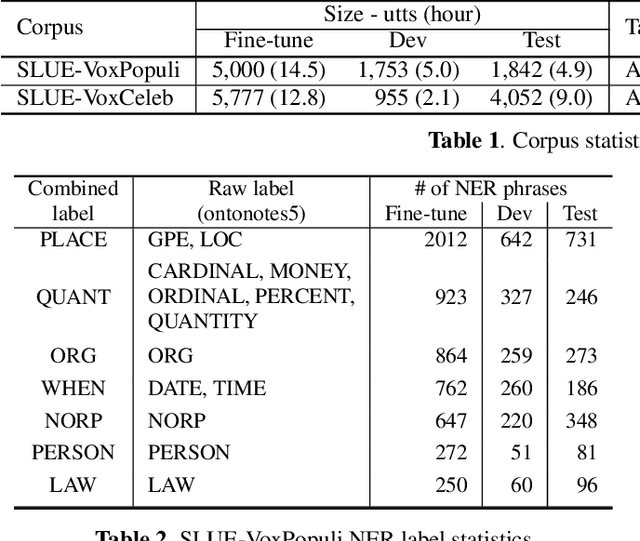
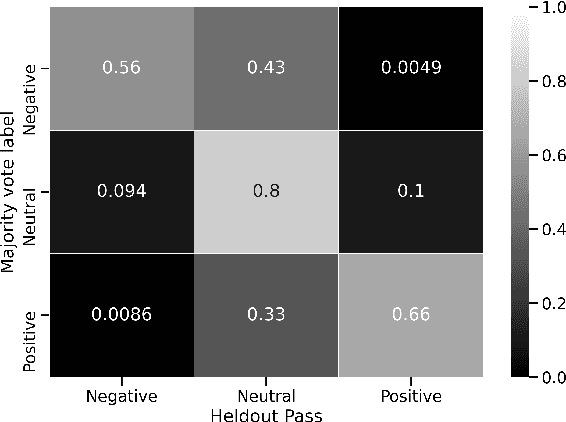
Progress in speech processing has been facilitated by shared datasets and benchmarks. Historically these have focused on automatic speech recognition (ASR), speaker identification, or other lower-level tasks. Interest has been growing in higher-level spoken language understanding tasks, including using end-to-end models, but there are fewer annotated datasets for such tasks. At the same time, recent work shows the possibility of pre-training generic representations and then fine-tuning for several tasks using relatively little labeled data. We propose to create a suite of benchmark tasks for Spoken Language Understanding Evaluation (SLUE) consisting of limited-size labeled training sets and corresponding evaluation sets. This resource would allow the research community to track progress, evaluate pre-trained representations for higher-level tasks, and study open questions such as the utility of pipeline versus end-to-end approaches. We present the first phase of the SLUE benchmark suite, consisting of named entity recognition, sentiment analysis, and ASR on the corresponding datasets. We focus on naturally produced (not read or synthesized) speech, and freely available datasets. We provide new transcriptions and annotations on subsets of the VoxCeleb and VoxPopuli datasets, evaluation metrics and results for baseline models, and an open-source toolkit to reproduce the baselines and evaluate new models.
Leveraging Pre-trained Language Model for Speech Sentiment Analysis
Jun 11, 2021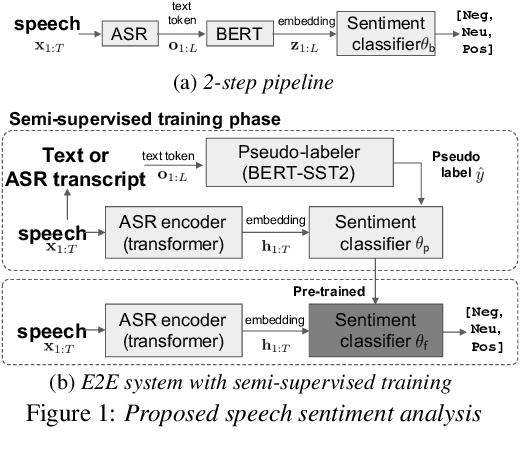
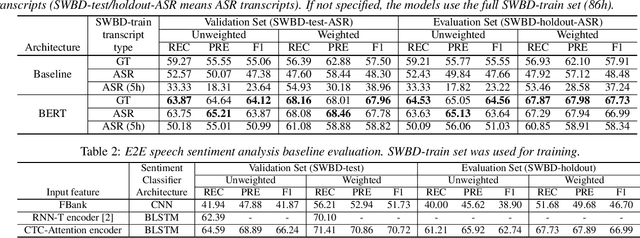
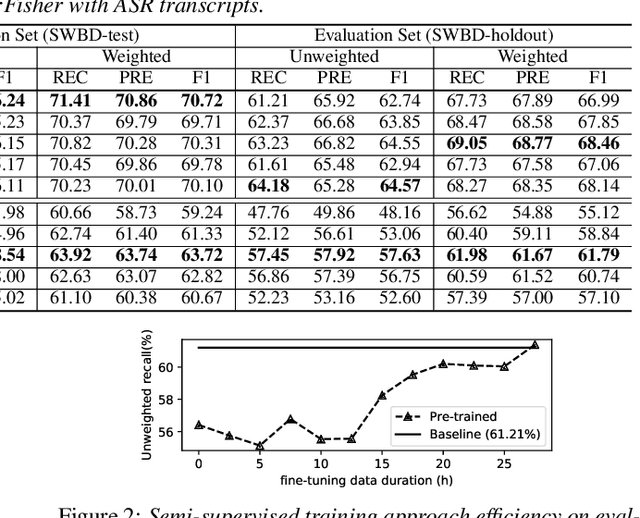
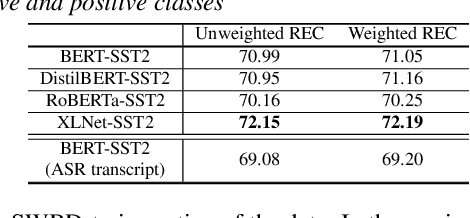
In this paper, we explore the use of pre-trained language models to learn sentiment information of written texts for speech sentiment analysis. First, we investigate how useful a pre-trained language model would be in a 2-step pipeline approach employing Automatic Speech Recognition (ASR) and transcripts-based sentiment analysis separately. Second, we propose a pseudo label-based semi-supervised training strategy using a language model on an end-to-end speech sentiment approach to take advantage of a large, but unlabeled speech dataset for training. Although spoken and written texts have different linguistic characteristics, they can complement each other in understanding sentiment. Therefore, the proposed system can not only model acoustic characteristics to bear sentiment-specific information in speech signals, but learn latent information to carry sentiments in the text representation. In these experiments, we demonstrate the proposed approaches improve F1 scores consistently compared to systems without a language model. Moreover, we also show that the proposed framework can reduce 65% of human supervision by leveraging a large amount of data without human sentiment annotation and boost performance in a low-resource condition where the human sentiment annotation is not available enough.
Time-Contrastive Learning Based Deep Bottleneck Features for Text-Dependent Speaker Verification
May 11, 2019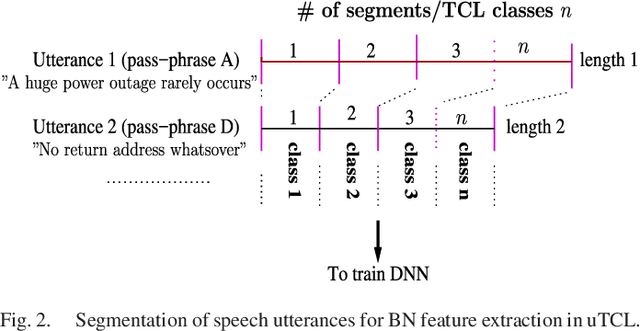
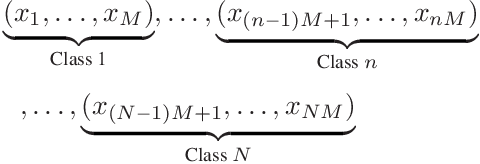
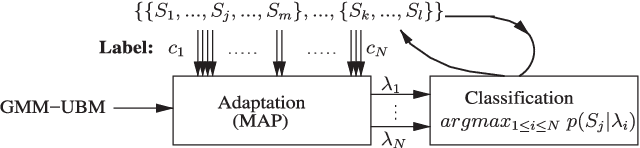
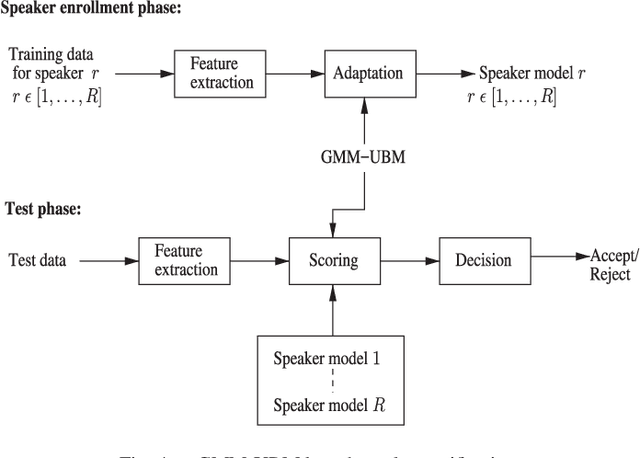
There are a number of studies about extraction of bottleneck (BN) features from deep neural networks (DNNs)trained to discriminate speakers, pass-phrases and triphone states for improving the performance of text-dependent speaker verification (TD-SV). However, a moderate success has been achieved. A recent study [1] presented a time contrastive learning (TCL) concept to explore the non-stationarity of brain signals for classification of brain states. Speech signals have similar non-stationarity property, and TCL further has the advantage of having no need for labeled data. We therefore present a TCL based BN feature extraction method. The method uniformly partitions each speech utterance in a training dataset into a predefined number of multi-frame segments. Each segment in an utterance corresponds to one class, and class labels are shared across utterances. DNNs are then trained to discriminate all speech frames among the classes to exploit the temporal structure of speech. In addition, we propose a segment-based unsupervised clustering algorithm to re-assign class labels to the segments. TD-SV experiments were conducted on the RedDots challenge database. The TCL-DNNs were trained using speech data of fixed pass-phrases that were excluded from the TD-SV evaluation set, so the learned features can be considered phrase-independent. We compare the performance of the proposed TCL bottleneck (BN) feature with those of short-time cepstral features and BN features extracted from DNNs discriminating speakers, pass-phrases, speaker+pass-phrase, as well as monophones whose labels and boundaries are generated by three different automatic speech recognition (ASR) systems. Experimental results show that the proposed TCL-BN outperforms cepstral features and speaker+pass-phrase discriminant BN features, and its performance is on par with those of ASR derived BN features. Moreover,....
* Copyright (c) 2019 IEEE. Personal use of this material is permitted. Permission from IEEE must be obtained for all other uses, in any current or future media, including reprinting/republishing this material for advertising or promotional purposes, creating new collective works, for resale or redistribution to servers or lists, or reuse of any copyrighted component of this work in other works
Domain Attentive Fusion for End-to-end Dialect Identification with Unknown Target Domain
Dec 04, 2018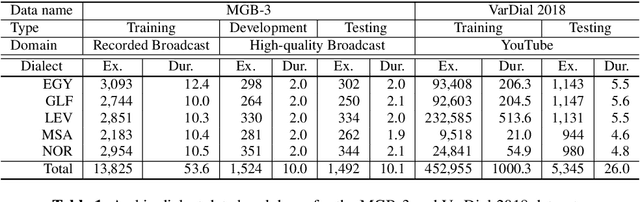
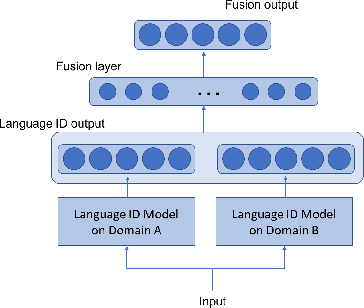
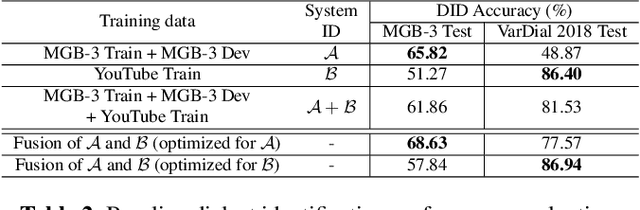
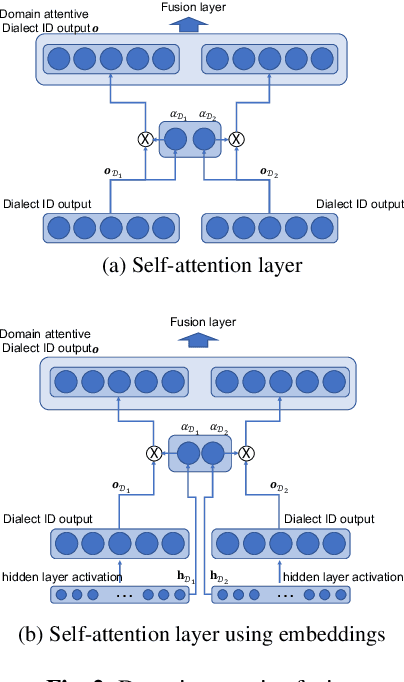
End-to-end deep learning language or dialect identification systems operate on the spectrogram or other acoustic feature and directly generate identification scores for each class. An important issue for end-to-end systems is to have some knowledge of the application domain, because the system can be vulnerable to use cases that were not seen in the training phase; such a scenario is often referred to as a domain mismatched condition. In general, we assume that there is enough variation in the training dataset to expose the system to multiple domains. In this work, we study how to best make use a training dataset in order to have maximum effectiveness on unknown target domains. Our goal is to process the input without any knowledge of the target domain while preserving robust performance on other domains as well. To accomplish this objective, we propose a domain attentive fusion approach for end-to-end dialect/language identification systems. To help with experimentation, we collect a dataset from three different domains, and create experimental protocols for a domain mismatched condition. The results of our proposed approach, which were tested on a variety of broadcast and YouTube data, shows significant performance gain compared to traditional approaches, even without any prior target domain information.
Noise-tolerant Audio-visual Online Person Verification using an Attention-based Neural Network Fusion
Nov 27, 2018
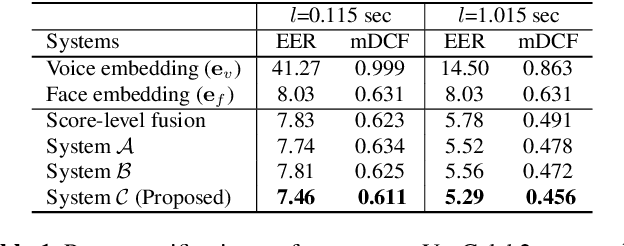
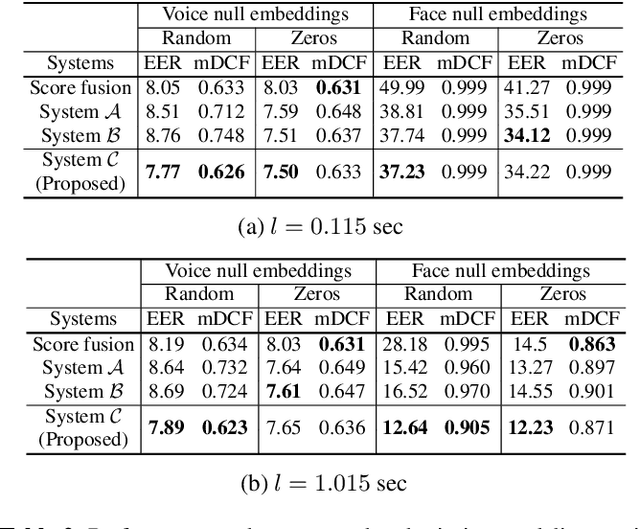
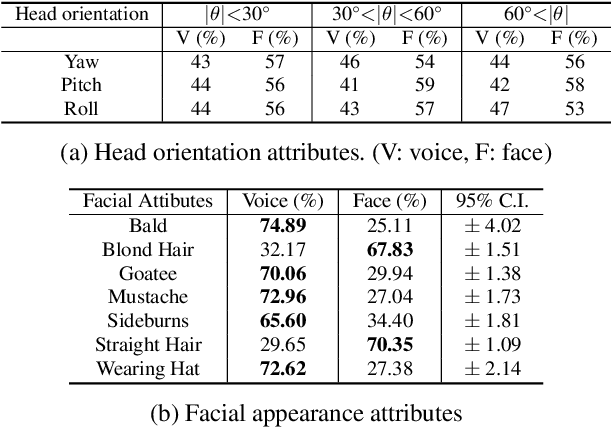
In this paper, we present a multi-modal online person verification system using both speech and visual signals. Inspired by neuroscientific findings on the association of voice and face, we propose an attention-based end-to-end neural network that learns multi-sensory associations for the task of person verification. The attention mechanism in our proposed network learns to conditionally select a salient modality between speech and facial representations that provides a balance between complementary inputs. By virtue of this capability, the network is robust to missing or corrupted data from either modality. In the VoxCeleb2 dataset, we show that our method performs favorably against competing multi-modal methods. Even for extreme cases of large corruption or an entirely missing modality, our method demonstrates robustness over other unimodal methods.
Unsupervised Representation Learning of Speech for Dialect Identification
Sep 12, 2018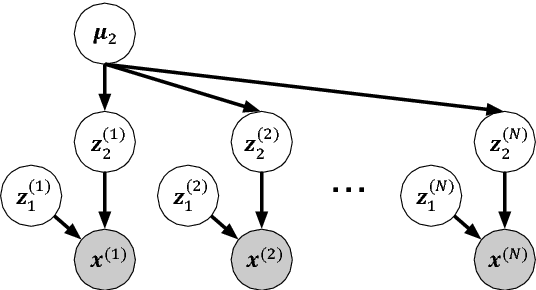
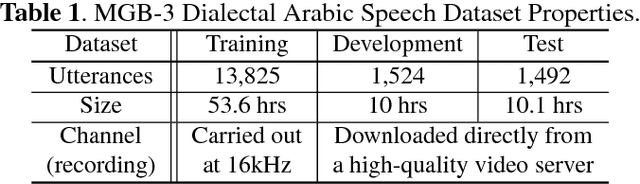
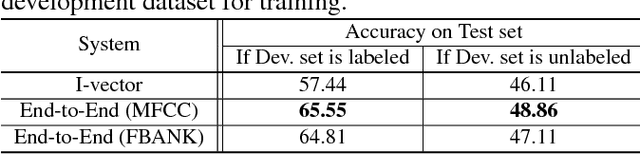
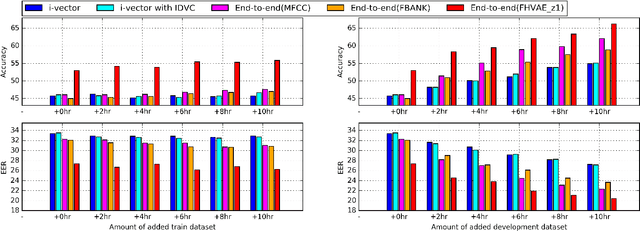
In this paper, we explore the use of a factorized hierarchical variational autoencoder (FHVAE) model to learn an unsupervised latent representation for dialect identification (DID). An FHVAE can learn a latent space that separates the more static attributes within an utterance from the more dynamic attributes by encoding them into two different sets of latent variables. Useful factors for dialect identification, such as phonetic or linguistic content, are encoded by a segmental latent variable, while irrelevant factors that are relatively constant within a sequence, such as a channel or a speaker information, are encoded by a sequential latent variable. The disentanglement property makes the segmental latent variable less susceptible to channel and speaker variation, and thus reduces degradation from channel domain mismatch. We demonstrate that on fully-supervised DID tasks, an end-to-end model trained on the features extracted from the FHVAE model achieves the best performance, compared to the same model trained on conventional acoustic features and an i-vector based system. Moreover, we also show that the proposed approach can leverage a large amount of unlabeled data for FHVAE training to learn domain-invariant features for DID, and significantly improve the performance in a low-resource condition, where the labels for the in-domain data are not available.
Frame-level speaker embeddings for text-independent speaker recognition and analysis of end-to-end model
Sep 12, 2018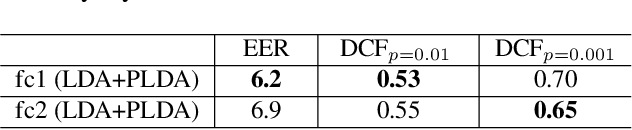
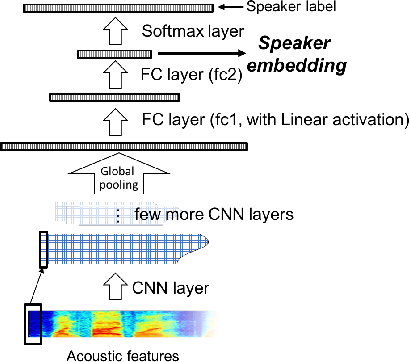
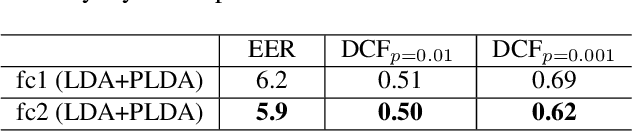
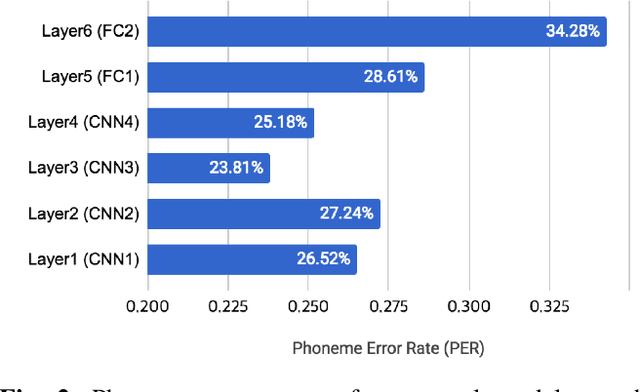
In this paper, we propose a Convolutional Neural Network (CNN) based speaker recognition model for extracting robust speaker embeddings. The embedding can be extracted efficiently with linear activation in the embedding layer. To understand how the speaker recognition model operates with text-independent input, we modify the structure to extract frame-level speaker embeddings from each hidden layer. We feed utterances from the TIMIT dataset to the trained network and use several proxy tasks to study the networks ability to represent speech input and differentiate voice identity. We found that the networks are better at discriminating broad phonetic classes than individual phonemes. In particular, frame-level embeddings that belong to the same phonetic classes are similar (based on cosine distance) for the same speaker. The frame level representation also allows us to analyze the networks at the frame level, and has the potential for other analyses to improve speaker recognition.
MIT-QCRI Arabic Dialect Identification System for the 2017 Multi-Genre Broadcast Challenge
Aug 28, 2017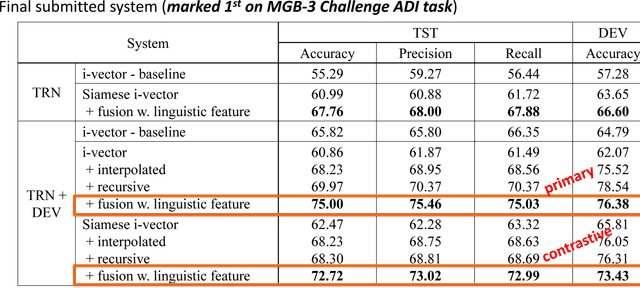
In order to successfully annotate the Arabic speech con- tent found in open-domain media broadcasts, it is essential to be able to process a diverse set of Arabic dialects. For the 2017 Multi-Genre Broadcast challenge (MGB-3) there were two possible tasks: Arabic speech recognition, and Arabic Dialect Identification (ADI). In this paper, we describe our efforts to create an ADI system for the MGB-3 challenge, with the goal of distinguishing amongst four major Arabic dialects, as well as Modern Standard Arabic. Our research fo- cused on dialect variability and domain mismatches between the training and test domain. In order to achieve a robust ADI system, we explored both Siamese neural network models to learn similarity and dissimilarities among Arabic dialects, as well as i-vector post-processing to adapt domain mismatches. Both Acoustic and linguistic features were used for the final MGB-3 submissions, with the best primary system achieving 75% accuracy on the official 10hr test set.