 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQwenSafe: Multimodal Content Rating Description Identification via Preference-Aligned VLMs
May 20, 2026Mobile app marketplaces require developers to disclose standardized content rating descriptors (CRDs) to inform users about potentially sensitive or restricted content. Ensuring the accuracy and consistency of these disclosures remains challenging due to the multimodal nature of app content, which spans textual descriptions and visual interfaces. In this paper, we present QwenSafe, a Vision-Language Model (VLM) designed to automatically identify the presence of Apple-defined CRDs by jointly reasoning over app metadata and screenshots. To enable scalable training for this task, we introduce metadata2CRD, a data-construction pipeline that synthesizes descriptor-aligned question-answer pairs by combining app descriptions, screenshots, and formal descriptor definitions. We adapt Qwen3-VL-8B using supervised fine-tuning followed by Direct Preference Optimization (DPO) to align model predictions with descriptor-specific evidence and explanations across visual and textual modalities. We evaluate QwenSafe on 12 Apple-defined content rating descriptors and compare it against state-of-the-art vision-language models, including Qwen3-VL, LLaVA-1.6, and Gemini-2.5-Flash. QwenSafe consistently outperforms all baselines in binary CRD classification, achieving improvements in positive-class recall of 111.8%, 36.1%, and 2.1%, respectively. Our results demonstrate that descriptor-aware multimodal alignment substantially improves automated content classification and highlights the potential of vision-language models to support scalable and consistent content rating in mobile app marketplaces.
PrivPRISM: Automatically Detecting Discrepancies Between Google Play Data Safety Declarations and Developer Privacy Policies
Mar 10, 2026End-users seldom read verbose privacy policies, leading app stores like Google Play to mandate simplified data safety declarations as a user-friendly alternative. However, these self-declared disclosures often contradict the full privacy policies, deceiving users about actual data practices and violating regulatory requirements for consistency. To address this, we introduce PrivPRISM, a robust framework that combines encoder and decoder language models to systematically extract and compare fine-grained data practices from privacy policies and to compare against data safety declarations, enabling scalable detection of non-compliance. Evaluating 7,770 popular mobile games uncovers discrepancies in nearly 53% of cases, rising to 61% among 1,711 widely used generic apps. Additionally, static code analysis reveals possible under-disclosures, with privacy policies disclosing just 66.8% of potential accesses to sensitive data like location and financial information, versus only 36.4% in data safety declarations of mobile games. Our findings expose systemic issues, including widespread reuse of generic privacy policies, vague / contradictory statements, and hidden risks in high-profile apps with 100M+ downloads, underscoring the urgent need for automated enforcement to protect platform integrity and for end-users to be vigilant about sensitive data they disclose via popular apps.
Entailment-Driven Privacy Policy Classification with LLMs
Sep 25, 2024



While many online services provide privacy policies for end users to read and understand what personal data are being collected, these documents are often lengthy and complicated. As a result, the vast majority of users do not read them at all, leading to data collection under uninformed consent. Several attempts have been made to make privacy policies more user friendly by summarising them, providing automatic annotations or labels for key sections, or by offering chat interfaces to ask specific questions. With recent advances in Large Language Models (LLMs), there is an opportunity to develop more effective tools to parse privacy policies and help users make informed decisions. In this paper, we propose an entailment-driven LLM based framework to classify paragraphs of privacy policies into meaningful labels that are easily understood by users. The results demonstrate that our framework outperforms traditional LLM methods, improving the F1 score in average by 11.2%. Additionally, our framework provides inherently explainable and meaningful predictions.
Long-Tail Learning with Rebalanced Contrastive Loss
Dec 04, 2023



Integrating supervised contrastive loss to cross entropy-based communication has recently been proposed as a solution to address the long-tail learning problem. However, when the class imbalance ratio is high, it requires adjusting the supervised contrastive loss to support the tail classes, as the conventional contrastive learning is biased towards head classes by default. To this end, we present Rebalanced Contrastive Learning (RCL), an efficient means to increase the long tail classification accuracy by addressing three main aspects: 1. Feature space balancedness - Equal division of the feature space among all the classes, 2. Intra-Class compactness - Reducing the distance between same-class embeddings, 3. Regularization - Enforcing larger margins for tail classes to reduce overfitting. RCL adopts class frequency-based SoftMax loss balancing to supervised contrastive learning loss and exploits scalar multiplied features fed to the contrastive learning loss to enforce compactness. We implement RCL on the Balanced Contrastive Learning (BCL) Framework, which has the SOTA performance. Our experiments on three benchmark datasets demonstrate the richness of the learnt embeddings and increased top-1 balanced accuracy RCL provides to the BCL framework. We further demonstrate that the performance of RCL as a standalone loss also achieves state-of-the-art level accuracy.
PointCaps: Raw Point Cloud Processing using Capsule Networks with Euclidean Distance Routing
Dec 21, 2021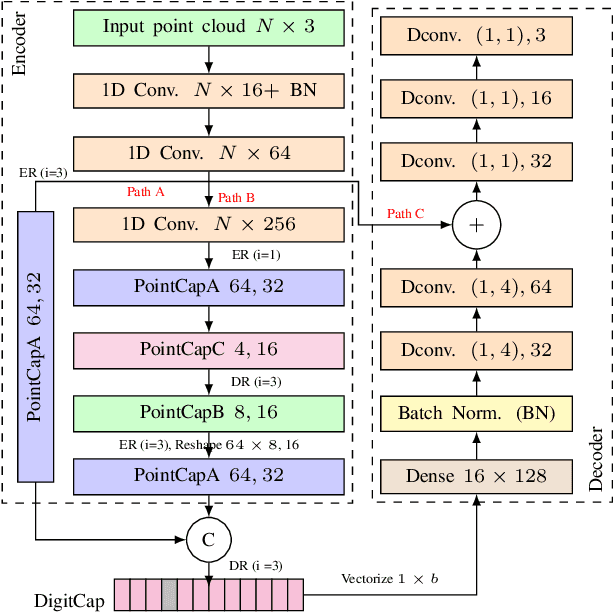
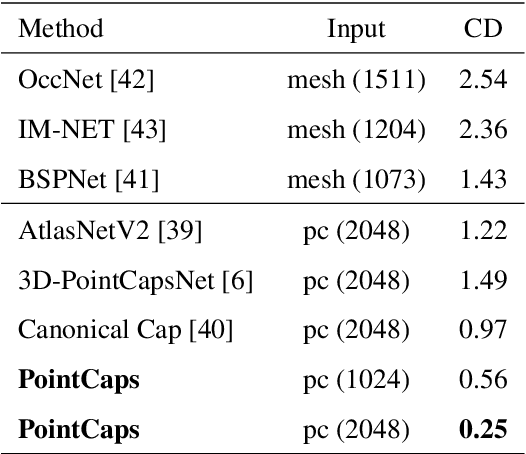

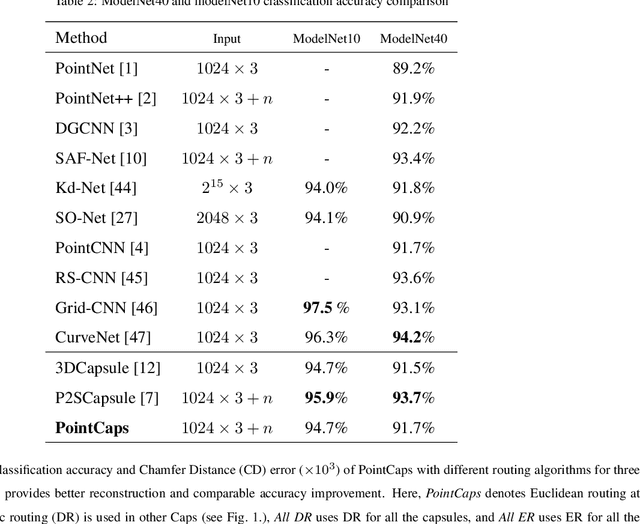
Raw point cloud processing using capsule networks is widely adopted in classification, reconstruction, and segmentation due to its ability to preserve spatial agreement of the input data. However, most of the existing capsule based network approaches are computationally heavy and fail at representing the entire point cloud as a single capsule. We address these limitations in existing capsule network based approaches by proposing PointCaps, a novel convolutional capsule architecture with parameter sharing. Along with PointCaps, we propose a novel Euclidean distance routing algorithm and a class-independent latent representation. The latent representation captures physically interpretable geometric parameters of the point cloud, with dynamic Euclidean routing, PointCaps well-represents the spatial (point-to-part) relationships of points. PointCaps has a significantly lower number of parameters and requires a significantly lower number of FLOPs while achieving better reconstruction with comparable classification and segmentation accuracy for raw point clouds compared to state-of-the-art capsule networks.