 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantum Inverse Contextual Vision Transformers (Q-ICVT): A New Frontier in 3D Object Detection for AVs
Aug 20, 2024



The field of autonomous vehicles (AVs) predominantly leverages multi-modal integration of LiDAR and camera data to achieve better performance compared to using a single modality. However, the fusion process encounters challenges in detecting distant objects due to the disparity between the high resolution of cameras and the sparse data from LiDAR. Insufficient integration of global perspectives with local-level details results in sub-optimal fusion performance.To address this issue, we have developed an innovative two-stage fusion process called Quantum Inverse Contextual Vision Transformers (Q-ICVT). This approach leverages adiabatic computing in quantum concepts to create a novel reversible vision transformer known as the Global Adiabatic Transformer (GAT). GAT aggregates sparse LiDAR features with semantic features in dense images for cross-modal integration in a global form. Additionally, the Sparse Expert of Local Fusion (SELF) module maps the sparse LiDAR 3D proposals and encodes position information of the raw point cloud onto the dense camera feature space using a gating point fusion approach. Our experiments show that Q-ICVT achieves an mAPH of 82.54 for L2 difficulties on the Waymo dataset, improving by 1.88% over current state-of-the-art fusion methods. We also analyze GAT and SELF in ablation studies to highlight the impact of Q-ICVT. Our code is available at https://github.com/sanjay-810/Qicvt Q-ICVT
AYDIV: Adaptable Yielding 3D Object Detection via Integrated Contextual Vision Transformer
Feb 12, 2024Combining LiDAR and camera data has shown potential in enhancing short-distance object detection in autonomous driving systems. Yet, the fusion encounters difficulties with extended distance detection due to the contrast between LiDAR's sparse data and the dense resolution of cameras. Besides, discrepancies in the two data representations further complicate fusion methods. We introduce AYDIV, a novel framework integrating a tri-phase alignment process specifically designed to enhance long-distance detection even amidst data discrepancies. AYDIV consists of the Global Contextual Fusion Alignment Transformer (GCFAT), which improves the extraction of camera features and provides a deeper understanding of large-scale patterns; the Sparse Fused Feature Attention (SFFA), which fine-tunes the fusion of LiDAR and camera details; and the Volumetric Grid Attention (VGA) for a comprehensive spatial data fusion. AYDIV's performance on the Waymo Open Dataset (WOD) with an improvement of 1.24% in mAPH value(L2 difficulty) and the Argoverse2 Dataset with a performance improvement of 7.40% in AP value demonstrates its efficacy in comparison to other existing fusion-based methods. Our code is publicly available at https://github.com/sanjay-810/AYDIV2
OrthoSeisnet: Seismic Inversion through Orthogonal Multi-scale Frequency Domain U-Net for Geophysical Exploration
Jan 09, 2024Seismic inversion is crucial in hydrocarbon exploration, particularly for detecting hydrocarbons in thin layers. However, the detection of sparse thin layers within seismic datasets presents a significant challenge due to the ill-posed nature and poor non-linearity of the problem. While data-driven deep learning algorithms have shown promise, effectively addressing sparsity remains a critical area for improvement. To overcome this limitation, we propose OrthoSeisnet, a novel technique that integrates a multi-scale frequency domain transform within the U-Net framework. OrthoSeisnet aims to enhance the interpretability and resolution of seismic images, enabling the identification and utilization of sparse frequency components associated with hydrocarbon-bearing layers. By leveraging orthogonal basis functions and decoupling frequency components, OrthoSeisnet effectively improves data sparsity. We evaluate the performance of OrthoSeisnet using synthetic and real datasets obtained from the Krishna-Godavari basin. Orthoseisnet outperforms the traditional method through extensive performance analysis utilizing commonly used measures, such as mean absolute error (MAE), mean squared error (MSE), and structural similarity index (SSIM) https://github.com/supriyo100/Orthoseisnet.
Knowledge from Uncertainty in Evidential Deep Learning
Oct 19, 2023This work reveals an evidential signal that emerges from the uncertainty value in Evidential Deep Learning (EDL). EDL is one example of a class of uncertainty-aware deep learning approaches designed to provide confidence (or epistemic uncertainty) about the current test sample. In particular for computer vision and bidirectional encoder large language models, the `evidential signal' arising from the Dirichlet strength in EDL can, in some cases, discriminate between classes, which is particularly strong when using large language models. We hypothesise that the KL regularisation term causes EDL to couple aleatoric and epistemic uncertainty. In this paper, we empirically investigate the correlations between misclassification and evaluated uncertainty, and show that EDL's `evidential signal' is due to misclassification bias. We critically evaluate EDL with other Dirichlet-based approaches, namely Generative Evidential Neural Networks (EDL-GEN) and Prior Networks, and show theoretically and empirically the differences between these loss functions. We conclude that EDL's coupling of uncertainty arises from these differences due to the use (or lack) of out-of-distribution samples during training.
On the amplification of security and privacy risks by post-hoc explanations in machine learning models
Jun 28, 2022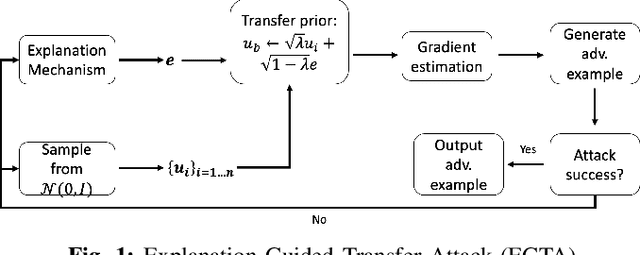
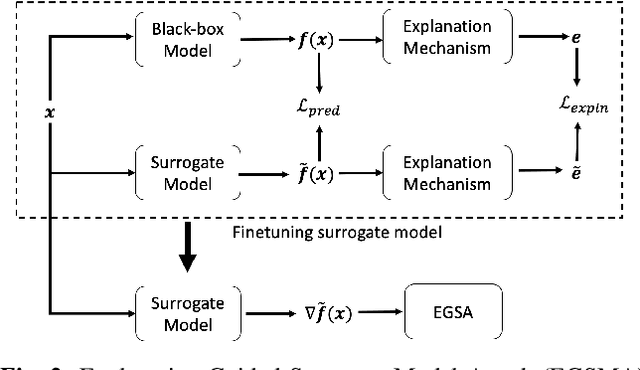
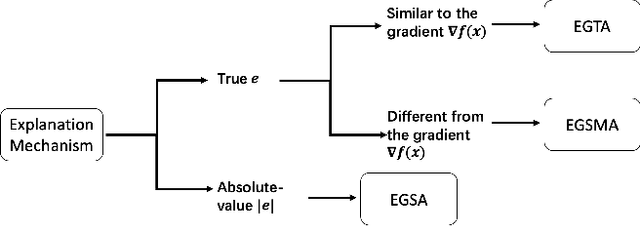
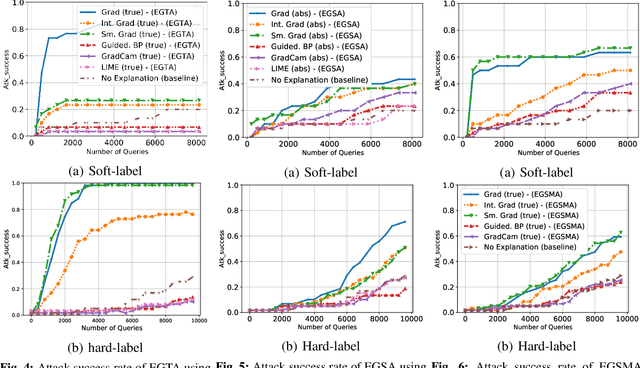
A variety of explanation methods have been proposed in recent years to help users gain insights into the results returned by neural networks, which are otherwise complex and opaque black-boxes. However, explanations give rise to potential side-channels that can be leveraged by an adversary for mounting attacks on the system. In particular, post-hoc explanation methods that highlight input dimensions according to their importance or relevance to the result also leak information that weakens security and privacy. In this work, we perform the first systematic characterization of the privacy and security risks arising from various popular explanation techniques. First, we propose novel explanation-guided black-box evasion attacks that lead to 10 times reduction in query count for the same success rate. We show that the adversarial advantage from explanations can be quantified as a reduction in the total variance of the estimated gradient. Second, we revisit the membership information leaked by common explanations. Contrary to observations in prior studies, via our modified attacks we show significant leakage of membership information (above 100% improvement over prior results), even in a much stricter black-box setting. Finally, we study explanation-guided model extraction attacks and demonstrate adversarial gains through a large reduction in query count.
SparseFed: Mitigating Model Poisoning Attacks in Federated Learning with Sparsification
Dec 12, 2021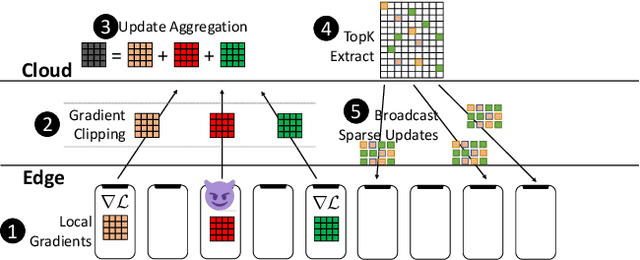
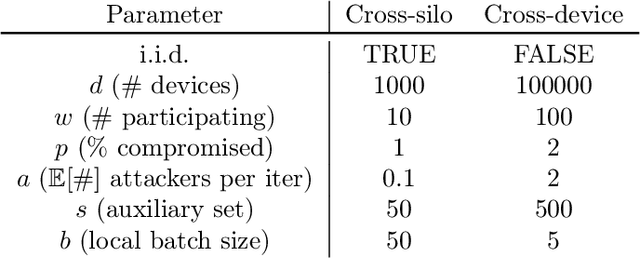
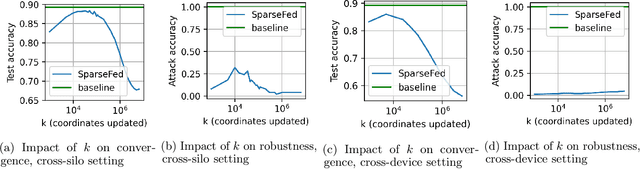

Federated learning is inherently vulnerable to model poisoning attacks because its decentralized nature allows attackers to participate with compromised devices. In model poisoning attacks, the attacker reduces the model's performance on targeted sub-tasks (e.g. classifying planes as birds) by uploading "poisoned" updates. In this report we introduce \algoname{}, a novel defense that uses global top-k update sparsification and device-level gradient clipping to mitigate model poisoning attacks. We propose a theoretical framework for analyzing the robustness of defenses against poisoning attacks, and provide robustness and convergence analysis of our algorithm. To validate its empirical efficacy we conduct an open-source evaluation at scale across multiple benchmark datasets for computer vision and federated learning.
Adversarial training in communication constrained federated learning
Mar 01, 2021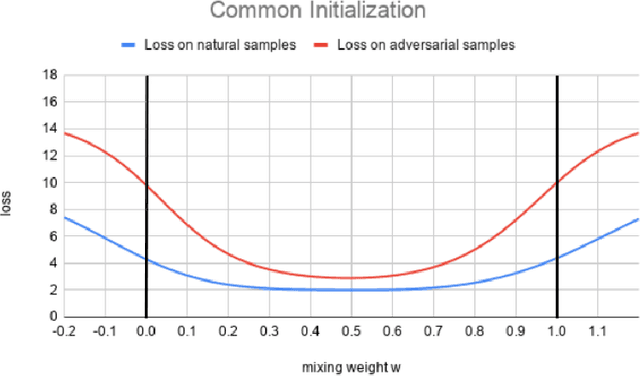
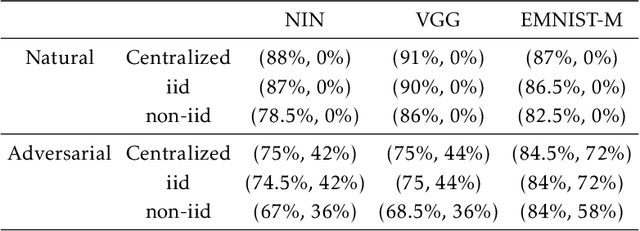
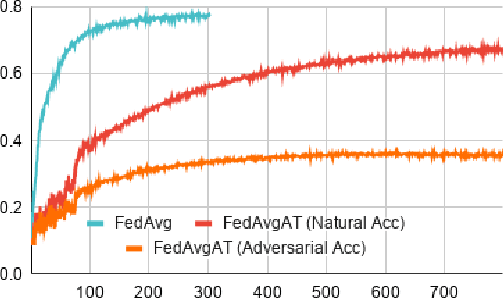
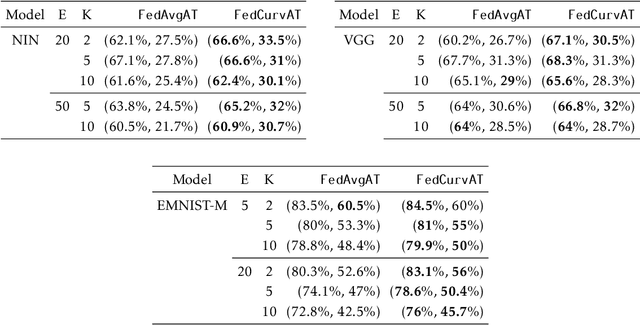
Federated learning enables model training over a distributed corpus of agent data. However, the trained model is vulnerable to adversarial examples, designed to elicit misclassification. We study the feasibility of using adversarial training (AT) in the federated learning setting. Furthermore, we do so assuming a fixed communication budget and non-iid data distribution between participating agents. We observe a significant drop in both natural and adversarial accuracies when AT is used in the federated setting as opposed to centralized training. We attribute this to the number of epochs of AT performed locally at the agents, which in turn effects (i) drift between local models; and (ii) convergence time (measured in number of communication rounds). Towards this end, we propose FedDynAT, a novel algorithm for performing AT in federated setting. Through extensive experimentation we show that FedDynAT significantly improves both natural and adversarial accuracy, as well as model convergence time by reducing the model drift.
IBM Federated Learning: an Enterprise Framework White Paper V0.1
Jul 22, 2020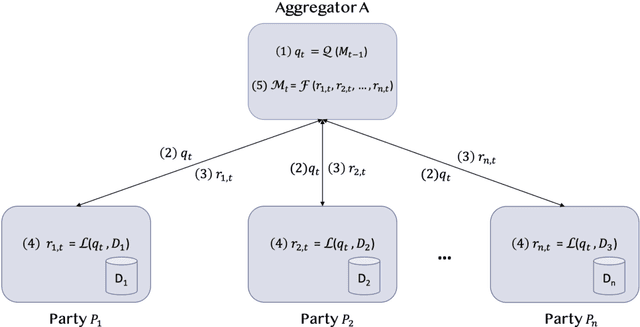
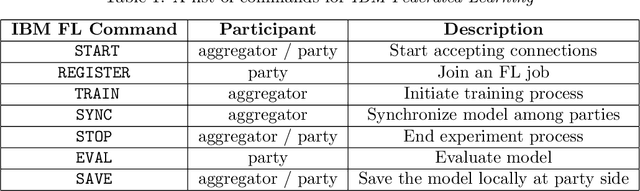
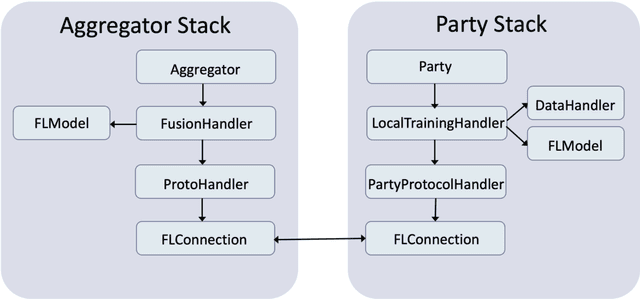
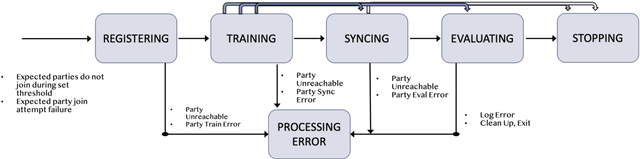
Federated Learning (FL) is an approach to conduct machine learning without centralizing training data in a single place, for reasons of privacy, confidentiality or data volume. However, solving federated machine learning problems raises issues above and beyond those of centralized machine learning. These issues include setting up communication infrastructure between parties, coordinating the learning process, integrating party results, understanding the characteristics of the training data sets of different participating parties, handling data heterogeneity, and operating with the absence of a verification data set. IBM Federated Learning provides infrastructure and coordination for federated learning. Data scientists can design and run federated learning jobs based on existing, centralized machine learning models and can provide high-level instructions on how to run the federation. The framework applies to both Deep Neural Networks as well as ``traditional'' approaches for the most common machine learning libraries. {\proj} enables data scientists to expand their scope from centralized to federated machine learning, minimizing the learning curve at the outset while also providing the flexibility to deploy to different compute environments and design custom fusion algorithms.
Explaining Motion Relevance for Activity Recognition in Video Deep Learning Models
Mar 31, 2020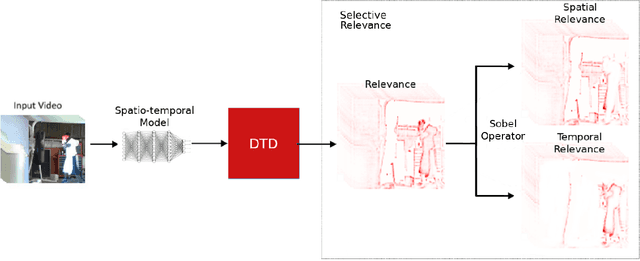
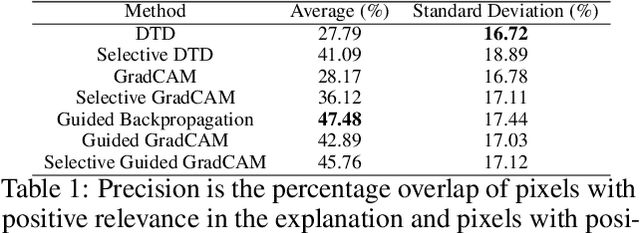
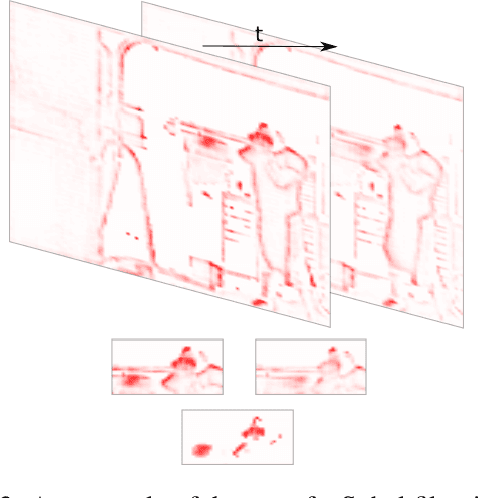

A small subset of explainability techniques developed initially for image recognition models has recently been applied for interpretability of 3D Convolutional Neural Network models in activity recognition tasks. Much like the models themselves, the techniques require little or no modification to be compatible with 3D inputs. However, these explanation techniques regard spatial and temporal information jointly. Therefore, using such explanation techniques, a user cannot explicitly distinguish the role of motion in a 3D model's decision. In fact, it has been shown that these models do not appropriately factor motion information into their decision. We propose a selective relevance method for adapting the 2D explanation techniques to provide motion-specific explanations, better aligning them with the human understanding of motion as conceptually separate from static spatial features. We demonstrate the utility of our method in conjunction with several widely-used 2D explanation methods, and show that it improves explanation selectivity for motion. Our results show that the selective relevance method can not only provide insight on the role played by motion in the model's decision -- in effect, revealing and quantifying the model's spatial bias -- but the method also simplifies the resulting explanations for human consumption.
Improving Adversarial Robustness Through Progressive Hardening
Mar 18, 2020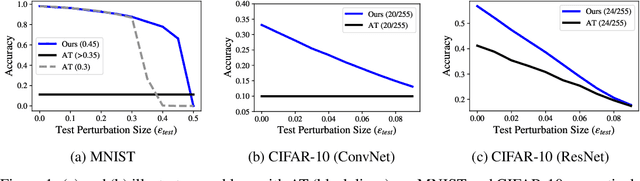
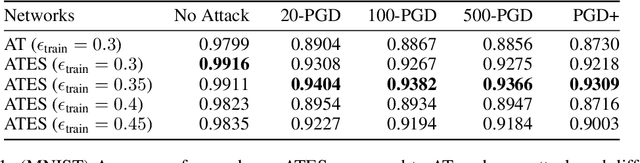
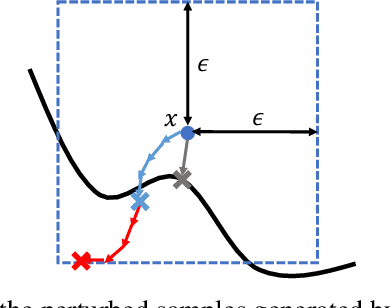

Adversarial training (AT) has become a popular choice for training robust networks. However, by virtue of its formulation, AT tends to sacrifice clean accuracy heavily in favor of robustness. Furthermore, AT with a large perturbation budget can cause models to get stuck at poor local minima and behave like a constant function, always predicting the same class. To address the above concerns we propose Adversarial Training with Early Stopping (ATES). The design of ATES is guided by principles from curriculum learning that emphasizes on starting "easy" and gradually ramping up on the "difficulty" of training. We do so by early stopping the adversarial example generation step in AT, progressively increasing difficulty of the samples the network trains on. This stabilizes network training even for large perturbation budgets and allows the network to operate at a better clean accuracy versus robustness trade-off curve compared to AT. Functionally, this leads to a significant improvement in both clean accuracy and robustness for ATES models.