 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative AI meets 3D: A Survey on Text-to-3D in AIGC Era
May 10, 2023



Generative AI (AIGC, a.k.a. AI generated content) has made remarkable progress in the past few years, among which text-guided content generation is the most practical one since it enables the interaction between human instruction and AIGC. Due to the development in text-to-image as well 3D modeling technologies (like NeRF), text-to-3D has become a newly emerging yet highly active research field. Our work conducts the first yet comprehensive survey on text-to-3D to help readers interested in this direction quickly catch up with its fast development. First, we introduce 3D data representations, including both Euclidean data and non-Euclidean data. On top of that, we introduce various foundation technologies as well as summarize how recent works combine those foundation technologies to realize satisfactory text-to-3D. Moreover, we summarize how text-to-3D technology is used in various applications, including avatar generation, texture generation, shape transformation, and scene generation.
Attack-SAM: Towards Attacking Segment Anything Model With Adversarial Examples
May 08, 2023



Segment Anything Model (SAM) has attracted significant attention recently, due to its impressive performance on various downstream tasks in a zero-short manner. Computer vision (CV) area might follow the natural language processing (NLP) area to embark on a path from task-specific vision models toward foundation models. However, deep vision models are widely recognized as vulnerable to adversarial examples, which fool the model to make wrong predictions with imperceptible perturbation. Such vulnerability to adversarial attacks causes serious concerns when applying deep models to security-sensitive applications. Therefore, it is critical to know whether the vision foundation model SAM can also be fooled by adversarial attacks. To the best of our knowledge, our work is the first of its kind to conduct a comprehensive investigation on how to attack SAM with adversarial examples. With the basic attack goal set to mask removal, we investigate the adversarial robustness of SAM in the full white-box setting and transfer-based black-box settings. Beyond the basic goal of mask removal, we further investigate and find that it is possible to generate any desired mask by the adversarial attack.
Segment Anything Model Meets Glass: Mirror and Transparent Objects Cannot Be Easily Detected
Apr 29, 2023



Meta AI Research has recently released SAM (Segment Anything Model) which is trained on a large segmentation dataset of over 1 billion masks. As a foundation model in the field of computer vision, SAM (Segment Anything Model) has gained attention for its impressive performance in generic object segmentation. Despite its strong capability in a wide range of zero-shot transfer tasks, it remains unknown whether SAM can detect things in challenging setups like transparent objects. In this work, we perform an empirical evaluation of two glass-related challenging scenarios: mirror and transparent objects. We found that SAM often fails to detect the glass in both scenarios, which raises concern for deploying the SAM in safety-critical situations that have various forms of glass.
A Survey on Graph Diffusion Models: Generative AI in Science for Molecule, Protein and Material
Apr 04, 2023



Diffusion models have become a new SOTA generative modeling method in various fields, for which there are multiple survey works that provide an overall survey. With the number of articles on diffusion models increasing exponentially in the past few years, there is an increasing need for surveys of diffusion models on specific fields. In this work, we are committed to conducting a survey on the graph diffusion models. Even though our focus is to cover the progress of diffusion models in graphs, we first briefly summarize how other generative modeling methods are used for graphs. After that, we introduce the mechanism of diffusion models in various forms, which facilitates the discussion on the graph diffusion models. The applications of graph diffusion models mainly fall into the category of AI-generated content (AIGC) in science, for which we mainly focus on how graph diffusion models are utilized for generating molecules and proteins but also cover other cases, including materials design. Moreover, we discuss the issue of evaluating diffusion models in the graph domain and the existing challenges.
One Small Step for Generative AI, One Giant Leap for AGI: A Complete Survey on ChatGPT in AIGC Era
Apr 04, 2023OpenAI has recently released GPT-4 (a.k.a. ChatGPT plus), which is demonstrated to be one small step for generative AI (GAI), but one giant leap for artificial general intelligence (AGI). Since its official release in November 2022, ChatGPT has quickly attracted numerous users with extensive media coverage. Such unprecedented attention has also motivated numerous researchers to investigate ChatGPT from various aspects. According to Google scholar, there are more than 500 articles with ChatGPT in their titles or mentioning it in their abstracts. Considering this, a review is urgently needed, and our work fills this gap. Overall, this work is the first to survey ChatGPT with a comprehensive review of its underlying technology, applications, and challenges. Moreover, we present an outlook on how ChatGPT might evolve to realize general-purpose AIGC (a.k.a. AI-generated content), which will be a significant milestone for the development of AGI.
A Survey on Audio Diffusion Models: Text To Speech Synthesis and Enhancement in Generative AI
Apr 02, 2023



Generative AI has demonstrated impressive performance in various fields, among which speech synthesis is an interesting direction. With the diffusion model as the most popular generative model, numerous works have attempted two active tasks: text to speech and speech enhancement. This work conducts a survey on audio diffusion model, which is complementary to existing surveys that either lack the recent progress of diffusion-based speech synthesis or highlight an overall picture of applying diffusion model in multiple fields. Specifically, this work first briefly introduces the background of audio and diffusion model. As for the text-to-speech task, we divide the methods into three categories based on the stage where diffusion model is adopted: acoustic model, vocoder and end-to-end framework. Moreover, we categorize various speech enhancement tasks by either certain signals are removed or added into the input speech. Comparisons of experimental results and discussions are also covered in this survey.
Analyzing Effects of Mixed Sample Data Augmentation on Model Interpretability
Mar 26, 2023Data augmentation strategies are actively used when training deep neural networks (DNNs). Recent studies suggest that they are effective at various tasks. However, the effect of data augmentation on DNNs' interpretability is not yet widely investigated. In this paper, we explore the relationship between interpretability and data augmentation strategy in which models are trained with different data augmentation methods and are evaluated in terms of interpretability. To quantify the interpretability, we devise three evaluation methods based on alignment with humans, faithfulness to the model, and the number of human-recognizable concepts in the model. Comprehensive experiments show that models trained with mixed sample data augmentation show lower interpretability, especially for CutMix and SaliencyMix augmentations. This new finding suggests that it is important to carefully adopt mixed sample data augmentation due to the impact on model interpretability, especially in mission-critical applications.
A Complete Survey on Generative AI : Is ChatGPT from GPT-4 to GPT-5 All You Need?
Mar 21, 2023



As ChatGPT goes viral, generative AI (AIGC, a.k.a AI-generated content) has made headlines everywhere because of its ability to analyze and create text, images, and beyond. With such overwhelming media coverage, it is almost impossible for us to miss the opportunity to glimpse AIGC from a certain angle. In the era of AI transitioning from pure analysis to creation, it is worth noting that ChatGPT, with its most recent language model GPT-4, is just a tool out of numerous AIGC tasks. Impressed by the capability of the ChatGPT, many people are wondering about its limits: can GPT-5 (or other future GPT variants) help ChatGPT unify all AIGC tasks for diversified content creation? Toward answering this question, a comprehensive review of existing AIGC tasks is needed. As such, our work comes to fill this gap promptly by offering a first look at AIGC, ranging from its techniques to applications. Modern generative AI relies on various technical foundations, ranging from model architecture and self-supervised pretraining to generative modeling methods (like GAN and diffusion models). After introducing the fundamental techniques, this work focuses on the technological development of various AIGC tasks based on their output type, including text, images, videos, 3D content, etc., which depicts the full potential of ChatGPT's future. Moreover, we summarize their significant applications in some mainstream industries, such as education and creativity content. Finally, we discuss the challenges currently faced and present an outlook on how generative AI might evolve in the near future.
ZooD: Exploiting Model Zoo for Out-of-Distribution Generalization
Oct 17, 2022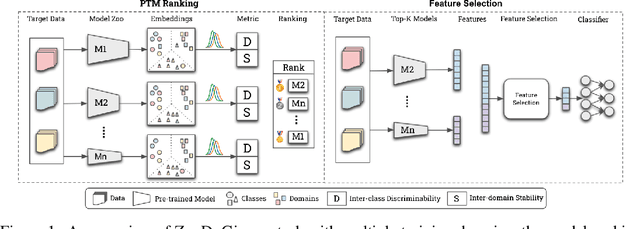

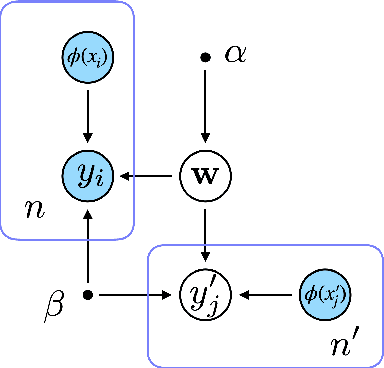
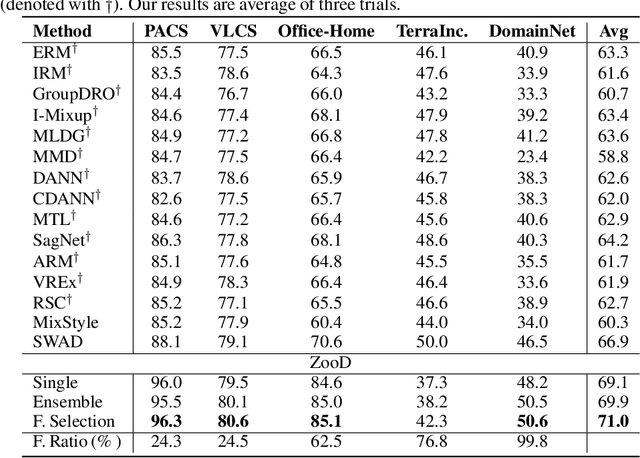
Recent advances on large-scale pre-training have shown great potentials of leveraging a large set of Pre-Trained Models (PTMs) for improving Out-of-Distribution (OoD) generalization, for which the goal is to perform well on possible unseen domains after fine-tuning on multiple training domains. However, maximally exploiting a zoo of PTMs is challenging since fine-tuning all possible combinations of PTMs is computationally prohibitive while accurate selection of PTMs requires tackling the possible data distribution shift for OoD tasks. In this work, we propose ZooD, a paradigm for PTMs ranking and ensemble with feature selection. Our proposed metric ranks PTMs by quantifying inter-class discriminability and inter-domain stability of the features extracted by the PTMs in a leave-one-domain-out cross-validation manner. The top-K ranked models are then aggregated for the target OoD task. To avoid accumulating noise induced by model ensemble, we propose an efficient variational EM algorithm to select informative features. We evaluate our paradigm on a diverse model zoo consisting of 35 models for various OoD tasks and demonstrate: (i) model ranking is better correlated with fine-tuning ranking than previous methods and up to 9859x faster than brute-force fine-tuning; (ii) OoD generalization after model ensemble with feature selection outperforms the state-of-the-art methods and the accuracy on most challenging task DomainNet is improved from 46.5\% to 50.6\%. Furthermore, we provide the fine-tuning results of 35 PTMs on 7 OoD datasets, hoping to help the research of model zoo and OoD generalization. Code will be available at https://gitee.com/mindspore/models/tree/master/research/cv/zood.
MixACM: Mixup-Based Robustness Transfer via Distillation of Activated Channel Maps
Nov 09, 2021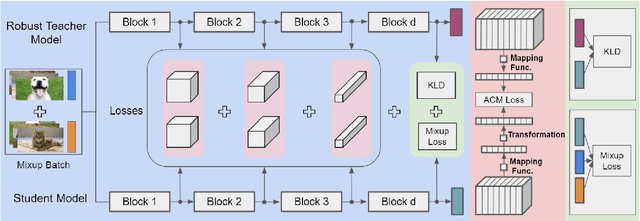
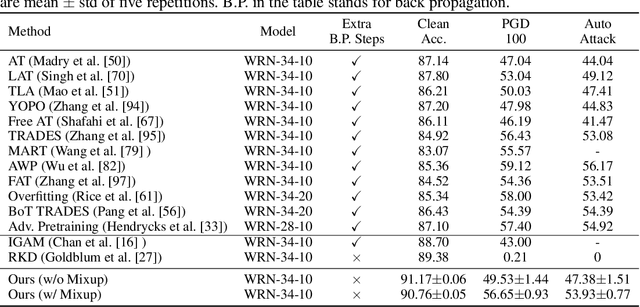

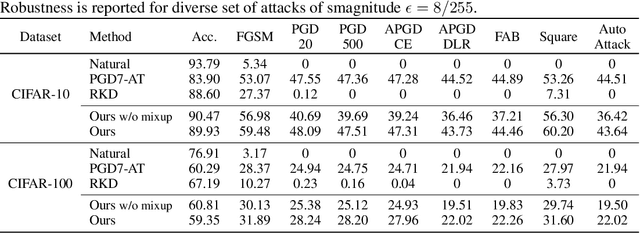
Deep neural networks are susceptible to adversarially crafted, small and imperceptible changes in the natural inputs. The most effective defense mechanism against these examples is adversarial training which constructs adversarial examples during training by iterative maximization of loss. The model is then trained to minimize the loss on these constructed examples. This min-max optimization requires more data, larger capacity models, and additional computing resources. It also degrades the standard generalization performance of a model. Can we achieve robustness more efficiently? In this work, we explore this question from the perspective of knowledge transfer. First, we theoretically show the transferability of robustness from an adversarially trained teacher model to a student model with the help of mixup augmentation. Second, we propose a novel robustness transfer method called Mixup-Based Activated Channel Maps (MixACM) Transfer. MixACM transfers robustness from a robust teacher to a student by matching activated channel maps generated without expensive adversarial perturbations. Finally, extensive experiments on multiple datasets and different learning scenarios show our method can transfer robustness while also improving generalization on natural images.