 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearn2Reg: comprehensive multi-task medical image registration challenge, dataset and evaluation in the era of deep learning
Dec 23, 2021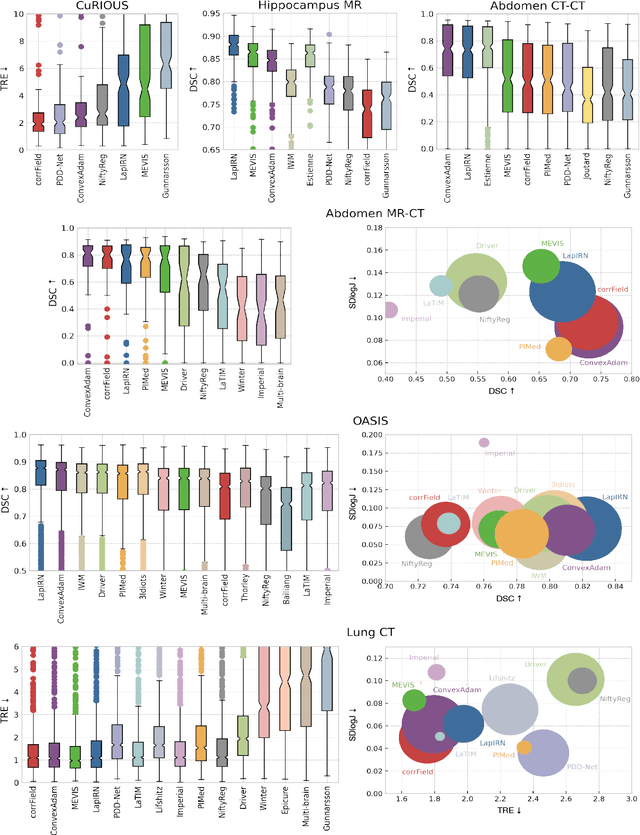
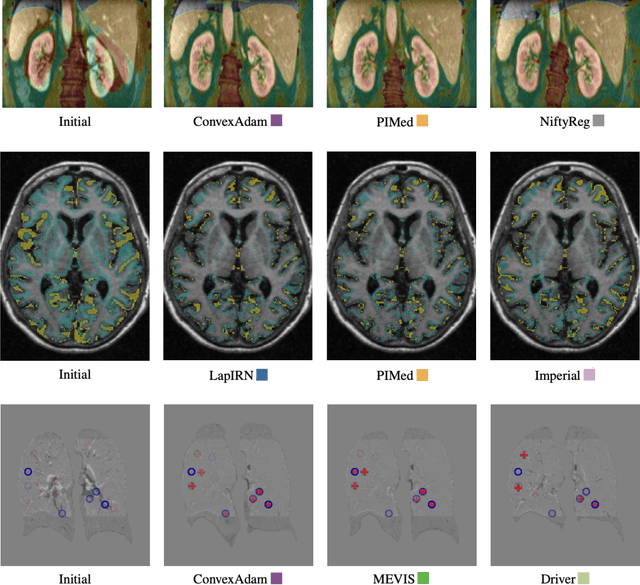
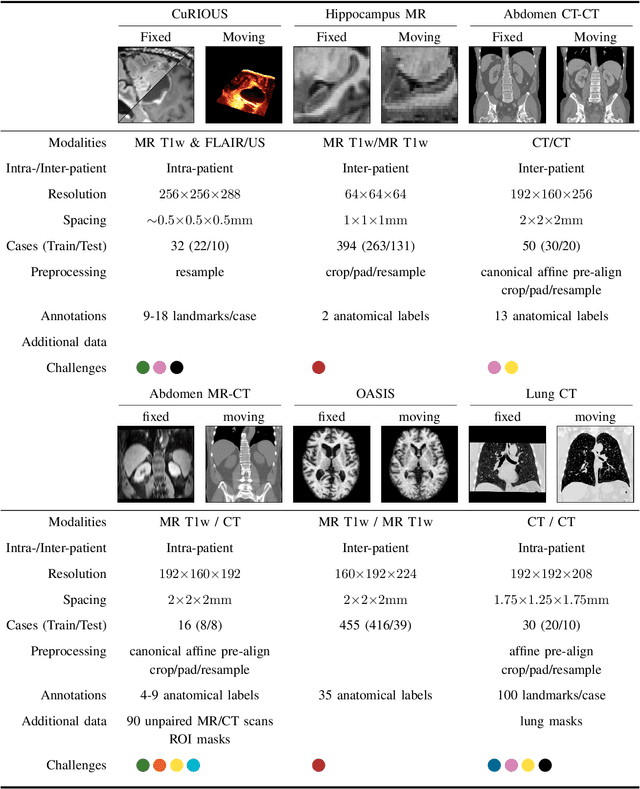
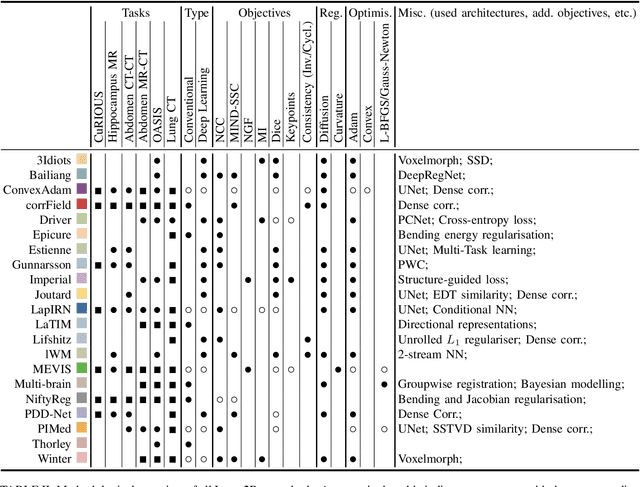
Image registration is a fundamental medical image analysis task, and a wide variety of approaches have been proposed. However, only a few studies have comprehensively compared medical image registration approaches on a wide range of clinically relevant tasks, in part because of the lack of availability of such diverse data. This limits the development of registration methods, the adoption of research advances into practice, and a fair benchmark across competing approaches. The Learn2Reg challenge addresses these limitations by providing a multi-task medical image registration benchmark for comprehensive characterisation of deformable registration algorithms. A continuous evaluation will be possible at https://learn2reg.grand-challenge.org. Learn2Reg covers a wide range of anatomies (brain, abdomen, and thorax), modalities (ultrasound, CT, MR), availability of annotations, as well as intra- and inter-patient registration evaluation. We established an easily accessible framework for training and validation of 3D registration methods, which enabled the compilation of results of over 65 individual method submissions from more than 20 unique teams. We used a complementary set of metrics, including robustness, accuracy, plausibility, and runtime, enabling unique insight into the current state-of-the-art of medical image registration. This paper describes datasets, tasks, evaluation methods and results of the challenge, and the results of further analysis of transferability to new datasets, the importance of label supervision, and resulting bias.
Adapt Everywhere: Unsupervised Adaptation of Point-Clouds and Entropy Minimisation for Multi-modal Cardiac Image Segmentation
Mar 15, 2021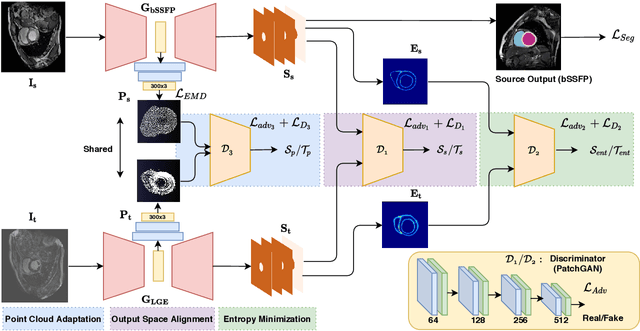
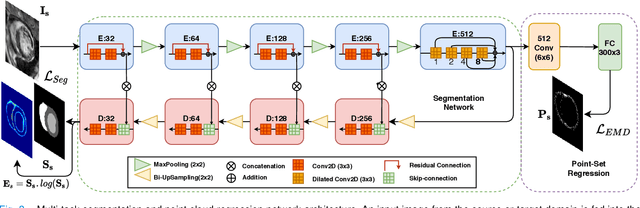
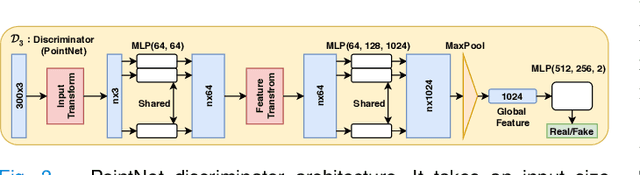
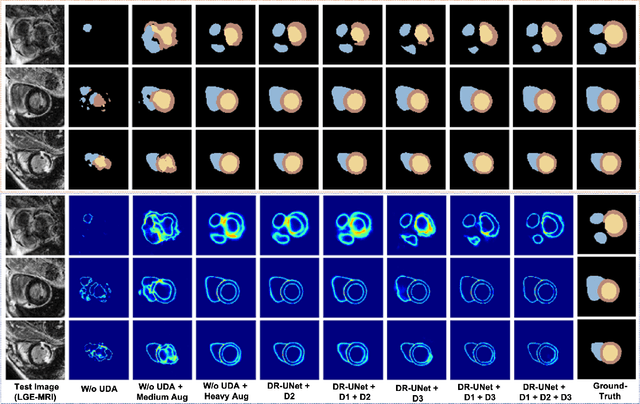
Deep learning models are sensitive to domain shift phenomena. A model trained on images from one domain cannot generalise well when tested on images from a different domain, despite capturing similar anatomical structures. It is mainly because the data distribution between the two domains is different. Moreover, creating annotation for every new modality is a tedious and time-consuming task, which also suffers from high inter- and intra- observer variability. Unsupervised domain adaptation (UDA) methods intend to reduce the gap between source and target domains by leveraging source domain labelled data to generate labels for the target domain. However, current state-of-the-art (SOTA) UDA methods demonstrate degraded performance when there is insufficient data in source and target domains. In this paper, we present a novel UDA method for multi-modal cardiac image segmentation. The proposed method is based on adversarial learning and adapts network features between source and target domain in different spaces. The paper introduces an end-to-end framework that integrates: a) entropy minimisation, b) output feature space alignment and c) a novel point-cloud shape adaptation based on the latent features learned by the segmentation model. We validated our method on two cardiac datasets by adapting from the annotated source domain, bSSFP-MRI (balanced Steady-State Free Procession-MRI), to the unannotated target domain, LGE-MRI (Late-gadolinium enhance-MRI), for the multi-sequence dataset; and from MRI (source) to CT (target) for the cross-modality dataset. The results highlighted that by enforcing adversarial learning in different parts of the network, the proposed method delivered promising performance, compared to other SOTA methods.
Spatio-temporal Multi-task Learning for Cardiac MRI Left Ventricle Quantification
Dec 24, 2020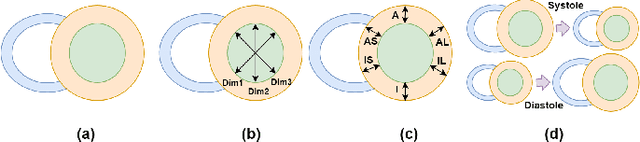
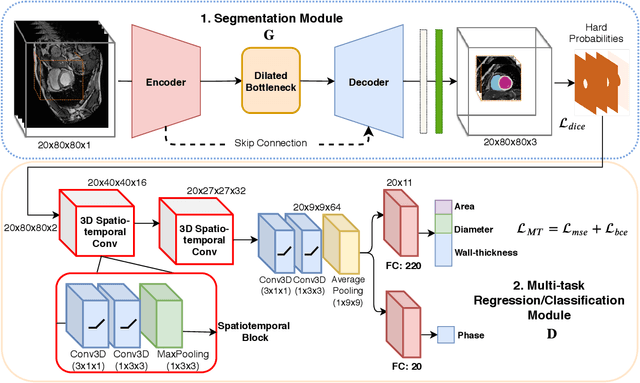
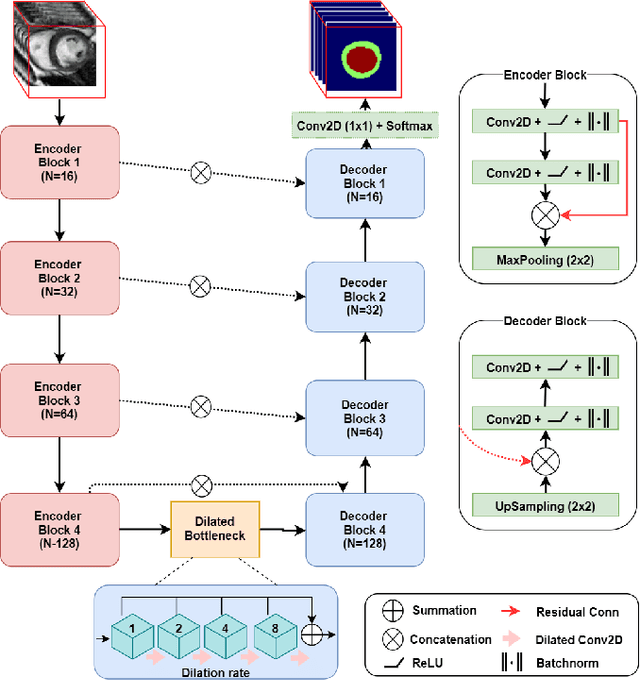
Quantitative assessment of cardiac left ventricle (LV) morphology is essential to assess cardiac function and improve the diagnosis of different cardiovascular diseases. In current clinical practice, LV quantification depends on the measurement of myocardial shape indices, which is usually achieved by manual contouring of the endo- and epicardial. However, this process subjected to inter and intra-observer variability, and it is a time-consuming and tedious task. In this paper, we propose a spatio-temporal multi-task learning approach to obtain a complete set of measurements quantifying cardiac LV morphology, regional-wall thickness (RWT), and additionally detecting the cardiac phase cycle (systole and diastole) for a given 3D Cine-magnetic resonance (MR) image sequence. We first segment cardiac LVs using an encoder-decoder network and then introduce a multitask framework to regress 11 LV indices and classify the cardiac phase, as parallel tasks during model optimization. The proposed deep learning model is based on the 3D spatio-temporal convolutions, which extract spatial and temporal features from MR images. We demonstrate the efficacy of the proposed method using cine-MR sequences of 145 subjects and comparing the performance with other state-of-the-art quantification methods. The proposed method obtained high prediction accuracy, with an average mean absolute error (MAE) of 129 $mm^2$, 1.23 $mm$, 1.76 $mm$, Pearson correlation coefficient (PCC) of 96.4%, 87.2%, and 97.5% for LV and myocardium (Myo) cavity regions, 6 RWTs, 3 LV dimensions, and an error rate of 9.0\% for phase classification. The experimental results highlight the robustness of the proposed method, despite varying degrees of cardiac morphology, image appearance, and low contrast in the cardiac MR sequences.
Cardiac Segmentation on Late Gadolinium Enhancement MRI: A Benchmark Study from Multi-Sequence Cardiac MR Segmentation Challenge
Jun 22, 2020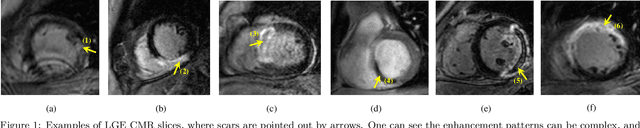
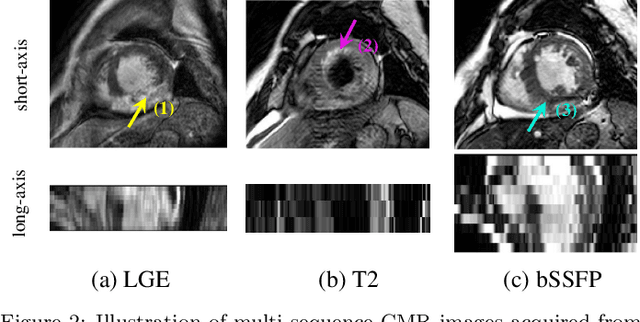

Accurate computing, analysis and modeling of the ventricles and myocardium from medical images are important, especially in the diagnosis and treatment management for patients suffering from myocardial infarction (MI). Late gadolinium enhancement (LGE) cardiac magnetic resonance (CMR) provides an important protocol to visualize MI. However, automated segmentation of LGE CMR is still challenging, due to the indistinguishable boundaries, heterogeneous intensity distribution and complex enhancement patterns of pathological myocardium from LGE CMR. Furthermore, compared with the other sequences LGE CMR images with gold standard labels are particularly limited, which represents another obstacle for developing novel algorithms for automatic segmentation of LGE CMR. This paper presents the selective results from the Multi-Sequence Cardiac MR (MS-CMR) Segmentation challenge, in conjunction with MICCAI 2019. The challenge offered a data set of paired MS-CMR images, including auxiliary CMR sequences as well as LGE CMR, from 45 patients who underwent cardiomyopathy. It was aimed to develop new algorithms, as well as benchmark existing ones for LGE CMR segmentation and compare them objectively. In addition, the paired MS-CMR images could enable algorithms to combine the complementary information from the other sequences for the segmentation of LGE CMR. Nine representative works were selected for evaluation and comparisons, among which three methods are unsupervised methods and the other six are supervised. The results showed that the average performance of the nine methods was comparable to the inter-observer variations. The success of these methods was mainly attributed to the inclusion of the auxiliary sequences from the MS-CMR images, which provide important label information for the training of deep neural networks.
A Global Benchmark of Algorithms for Segmenting Late Gadolinium-Enhanced Cardiac Magnetic Resonance Imaging
May 07, 2020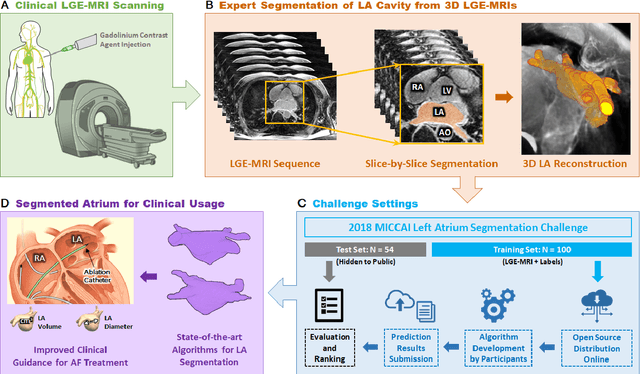
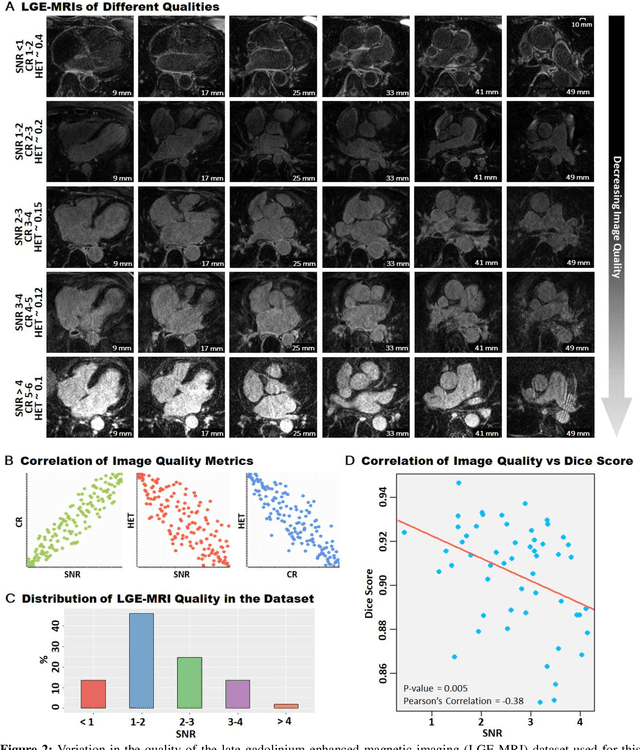
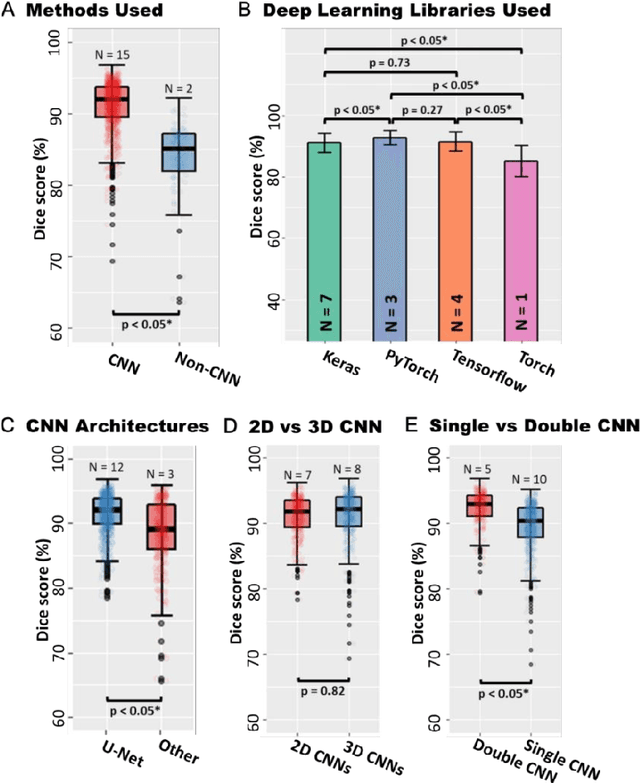
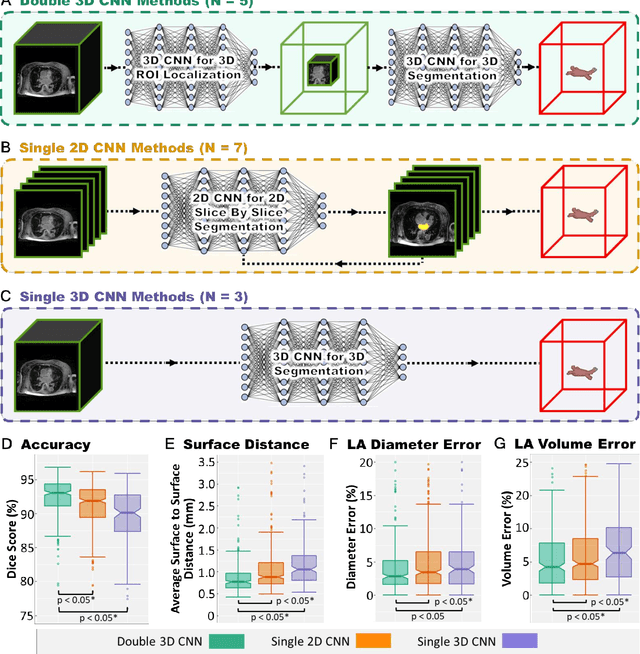
Segmentation of cardiac images, particularly late gadolinium-enhanced magnetic resonance imaging (LGE-MRI) widely used for visualizing diseased cardiac structures, is a crucial first step for clinical diagnosis and treatment. However, direct segmentation of LGE-MRIs is challenging due to its attenuated contrast. Since most clinical studies have relied on manual and labor-intensive approaches, automatic methods are of high interest, particularly optimized machine learning approaches. To address this, we organized the "2018 Left Atrium Segmentation Challenge" using 154 3D LGE-MRIs, currently the world's largest cardiac LGE-MRI dataset, and associated labels of the left atrium segmented by three medical experts, ultimately attracting the participation of 27 international teams. In this paper, extensive analysis of the submitted algorithms using technical and biological metrics was performed by undergoing subgroup analysis and conducting hyper-parameter analysis, offering an overall picture of the major design choices of convolutional neural networks (CNNs) and practical considerations for achieving state-of-the-art left atrium segmentation. Results show the top method achieved a dice score of 93.2% and a mean surface to a surface distance of 0.7 mm, significantly outperforming prior state-of-the-art. Particularly, our analysis demonstrated that double, sequentially used CNNs, in which a first CNN is used for automatic region-of-interest localization and a subsequent CNN is used for refined regional segmentation, achieved far superior results than traditional methods and pipelines containing single CNNs. This large-scale benchmarking study makes a significant step towards much-improved segmentation methods for cardiac LGE-MRIs, and will serve as an important benchmark for evaluating and comparing the future works in the field.
The Effect of Data Augmentation on Classification of Atrial Fibrillation in Short Single-Lead ECG Signals Using Deep Neural Networks
Feb 13, 2020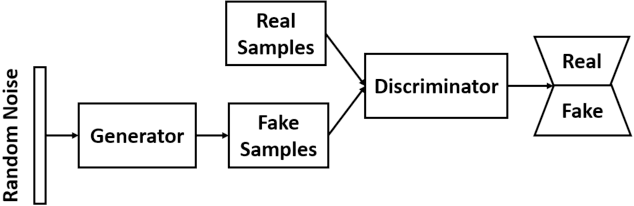
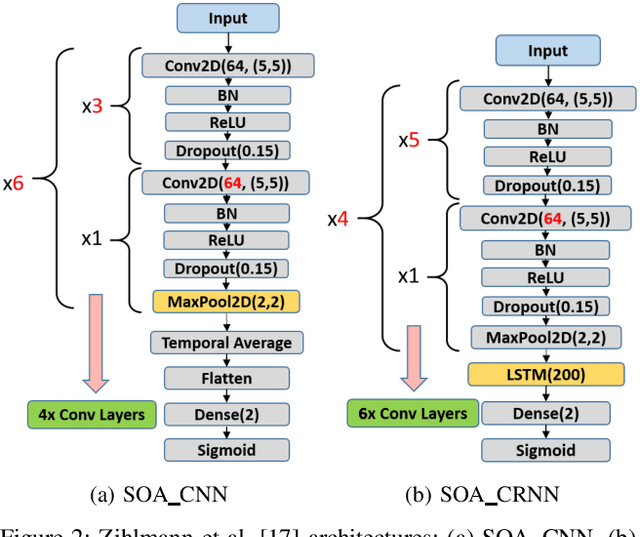
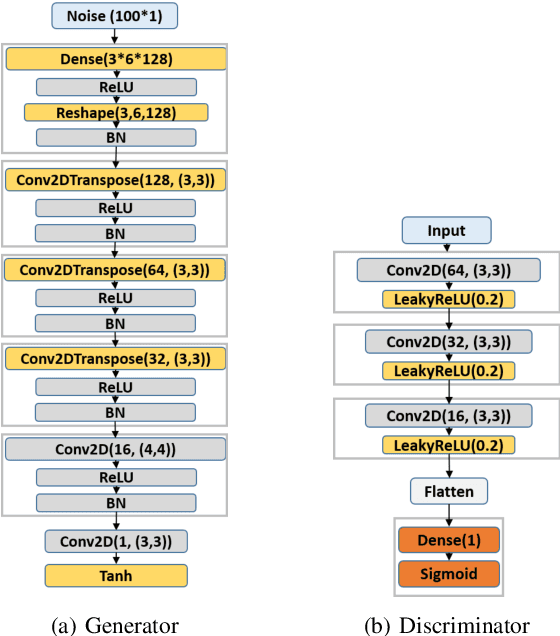
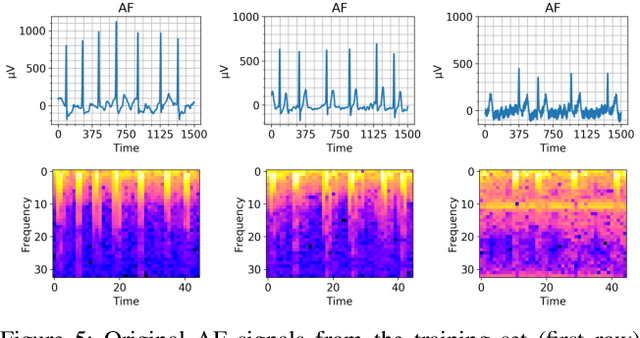
Cardiovascular diseases are the most common cause of mortality worldwide. Detection of atrial fibrillation (AF) in the asymptomatic stage can help prevent strokes. It also improves clinical decision making through the delivery of suitable treatment such as, anticoagulant therapy, in a timely manner. The clinical significance of such early detection of AF in electrocardiogram (ECG) signals has inspired numerous studies in recent years, of which many aim to solve this task by leveraging machine learning algorithms. ECG datasets containing AF samples, however, usually suffer from severe class imbalance, which if unaccounted for, affects the performance of classification algorithms. Data augmentation is a popular solution to tackle this problem. In this study, we investigate the impact of various data augmentation algorithms, e.g., oversampling, Gaussian Mixture Models (GMMs) and Generative Adversarial Networks (GANs), on solving the class imbalance problem. These algorithms are quantitatively and qualitatively evaluated, compared and discussed in detail. The results show that deep learning-based AF signal classification methods benefit more from data augmentation using GANs and GMMs, than oversampling. Furthermore, the GAN results in circa $3\%$ better AF classification accuracy in average while performing comparably to the GMM in terms of f1-score.
COPD Classification in CT Images Using a 3D Convolutional Neural Network
Jan 04, 2020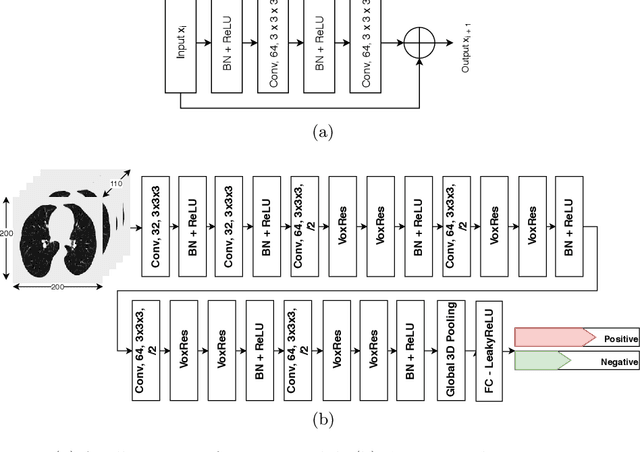
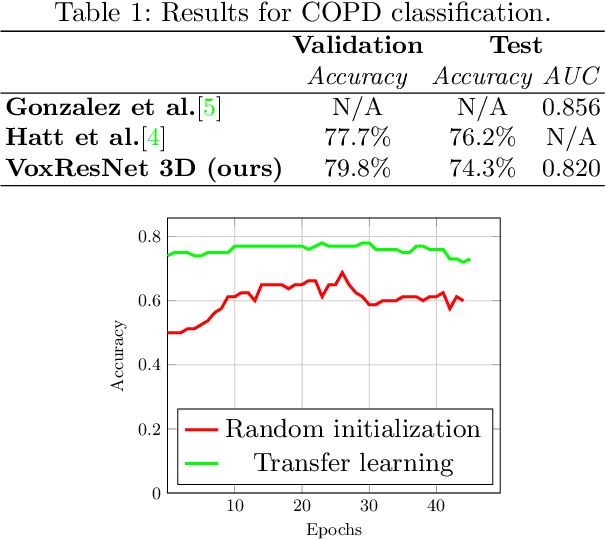


Chronic obstructive pulmonary disease (COPD) is a lung disease that is not fully reversible and one of the leading causes of morbidity and mortality in the world. Early detection and diagnosis of COPD can increase the survival rate and reduce the risk of COPD progression in patients. Currently, the primary examination tool to diagnose COPD is spirometry. However, computed tomography (CT) is used for detecting symptoms and sub-type classification of COPD. Using different imaging modalities is a difficult and tedious task even for physicians and is subjective to inter-and intra-observer variations. Hence, developing meth-ods that can automatically classify COPD versus healthy patients is of great interest. In this paper, we propose a 3D deep learning approach to classify COPD and emphysema using volume-wise annotations only. We also demonstrate the impact of transfer learning on the classification of emphysema using knowledge transfer from a pre-trained COPD classification model.
Deep Learning-based Denoising of Mammographic Images using Physics-driven Data Augmentation
Dec 11, 2019


Mammography is using low-energy X-rays to screen the human breast and is utilized by radiologists to detect breast cancer. Typically radiologists require a mammogram with impeccable image quality for an accurate diagnosis. In this study, we propose a deep learning method based on Convolutional Neural Networks (CNNs) for mammogram denoising to improve the image quality. We first enhance the noise level and employ Anscombe Transformation (AT) to transform Poisson noise to white Gaussian noise. With this data augmentation, a deep residual network is trained to learn the noise map of the noisy images. We show, that the proposed method can remove not only simulated but also real noise. Furthermore, we also compare our results with state-of-the-art denoising methods, such as BM3D and DNCNN. In an early investigation, we achieved qualitatively better mammogram denoising results.
Automated Multi-sequence Cardiac MRI Segmentation Using Supervised Domain Adaptation
Aug 21, 2019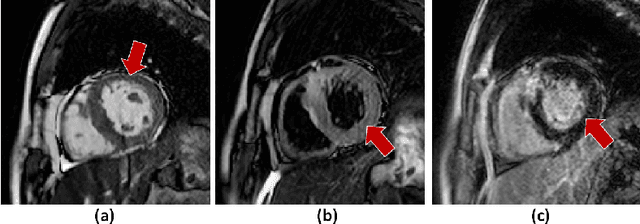

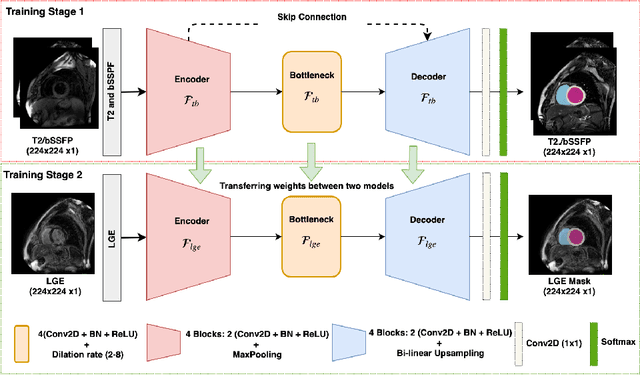
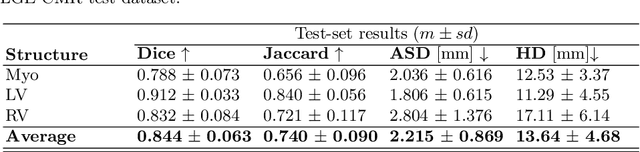
Left ventricle segmentation and morphological assessment are essential for improving diagnosis and our understanding of cardiomyopathy, which in turn is imperative for reducing risk of myocardial infarctions in patients. Convolutional neural network (CNN) based methods for cardiac magnetic resonance (CMR) image segmentation rely on supervision with pixel-level annotations, and may not generalize well to images from a different domain. These methods are typically sensitive to variations in imaging protocols and data acquisition. Since annotating multi-sequence CMR images is tedious and subject to inter- and intra-observer variations, developing methods that can automatically adapt from one domain to the target domain is of great interest. In this paper, we propose an approach for domain adaptation in multi-sequence CMR segmentation task using transfer learning that combines multi-source image information. We first train an encoder-decoder CNN on T2-weighted and balanced-Steady State Free Precession (bSSFP) MR images with pixel-level annotation and fine-tune the same network with a limited number of Late Gadolinium Enhanced-MR (LGE-MR) subjects, to adapt the domain features. The domain-adapted network was trained with just four LGE-MR training samples and obtained an average Dice score of $\sim$85.0\% on the test set comprises of 40 LGE-MR subjects. The proposed method significantly outperformed a network without adaptation trained from scratch on the same set of LGE-MR training data.
A 2D dilated residual U-Net for multi-organ segmentation in thoracic CT
May 19, 2019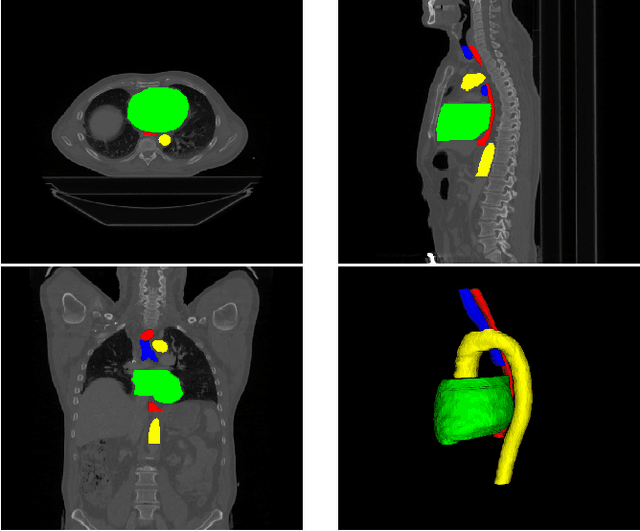
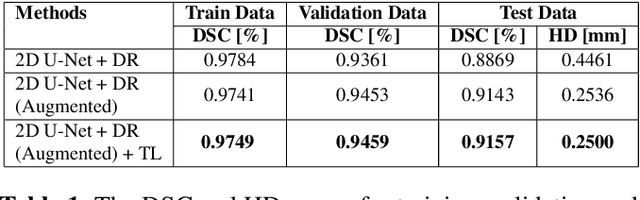
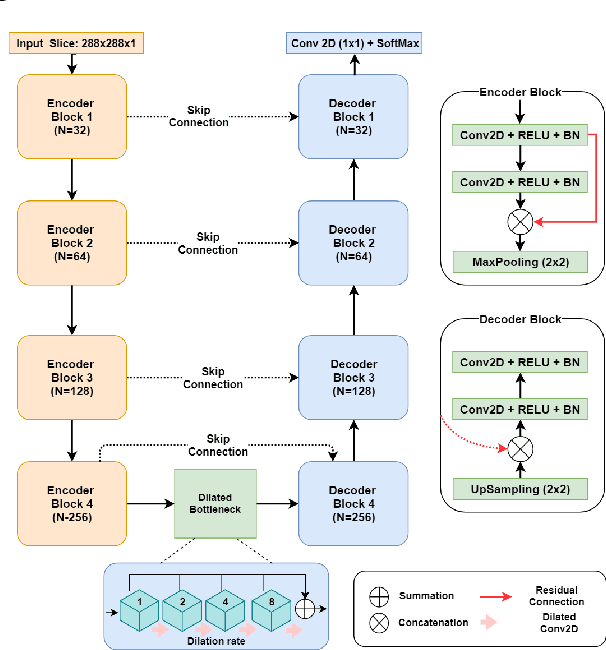

Automatic segmentation of organs-at-risk (OAR) in computed tomography (CT) is an essential part of planning effective treatment strategies to combat lung and esophageal cancer. Accurate segmentation of organs surrounding tumours helps account for the variation in position and morphology inherent across patients, thereby facilitating adaptive and computer-assisted radiotherapy. Although manual delineation of OARs is still highly prevalent, it is prone to errors due to complex variations in the shape and position of organs across patients, and low soft tissue contrast between neighbouring organs in CT images. Recently, deep convolutional neural networks (CNNs) have gained tremendous traction and achieved state-of-the-art results in medical image segmentation. In this paper, we propose a deep learning framework to segment OARs in thoracic CT images, specifically for the: heart, esophagus, trachea and aorta. Our approach employs dilated convolutions and aggregated residual connections in the bottleneck of a U-Net styled network, which incorporates global context and dense information. Our method achieved an overall Dice score of 91.57% on 20 unseen test samples from the ISBI 2019 SegTHOR challenge.