 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSubmodular Maximization via Taylor Series Approximation
Jan 19, 2021
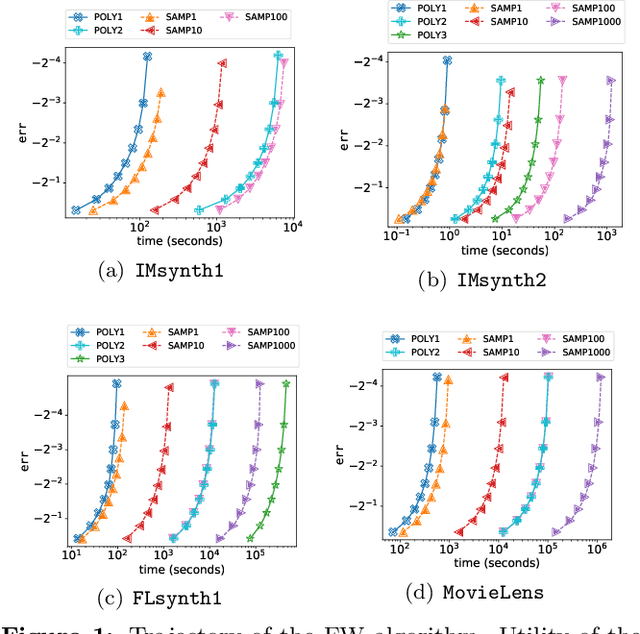

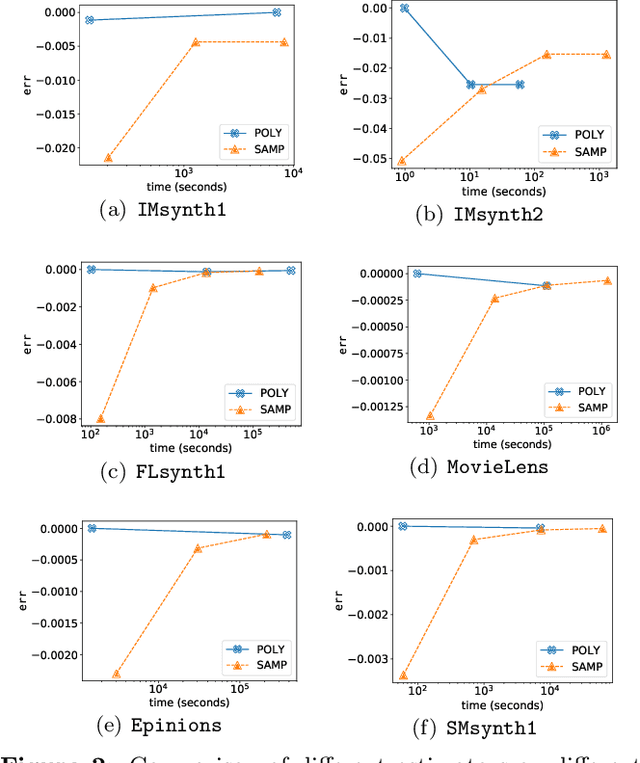
We study submodular maximization problems with matroid constraints, in particular, problems where the objective can be expressed via compositions of analytic and multilinear functions. We show that for functions of this form, the so-called continuous greedy algorithm attains a ratio arbitrarily close to $(1-1/e) \approx 0.63$ using a deterministic estimation via Taylor series approximation. This drastically reduces execution time over prior art that uses sampling.
Open-World Class Discovery with Kernel Networks
Dec 13, 2020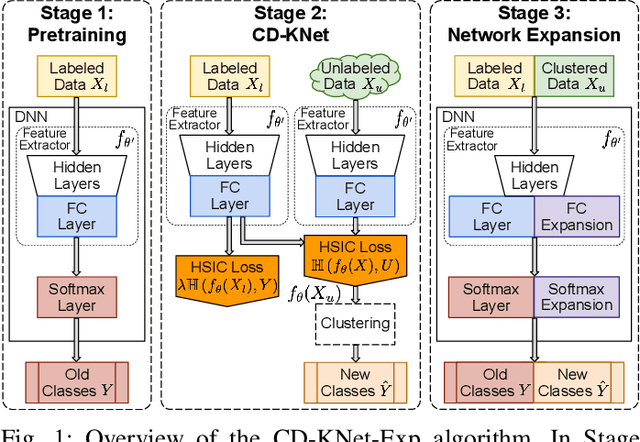
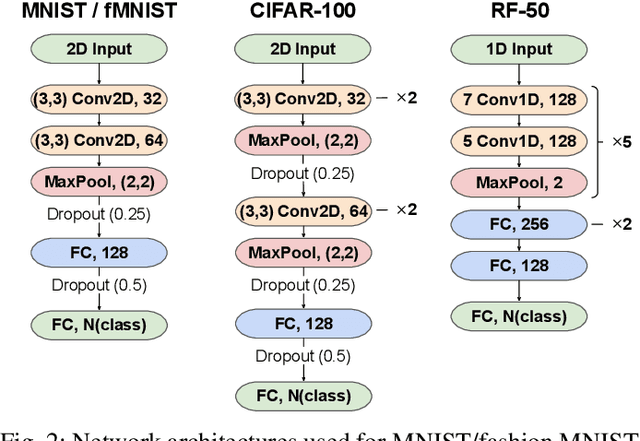


We study an Open-World Class Discovery problem in which, given labeled training samples from old classes, we need to discover new classes from unlabeled test samples. There are two critical challenges to addressing this paradigm: (a) transferring knowledge from old to new classes, and (b) incorporating knowledge learned from new classes back to the original model. We propose Class Discovery Kernel Network with Expansion (CD-KNet-Exp), a deep learning framework, which utilizes the Hilbert Schmidt Independence Criterion to bridge supervised and unsupervised information together in a systematic way, such that the learned knowledge from old classes is distilled appropriately for discovering new classes. Compared to competing methods, CD-KNet-Exp shows superior performance on three publicly available benchmark datasets and a challenging real-world radio frequency fingerprinting dataset.
Learn-Prune-Share for Lifelong Learning
Dec 13, 2020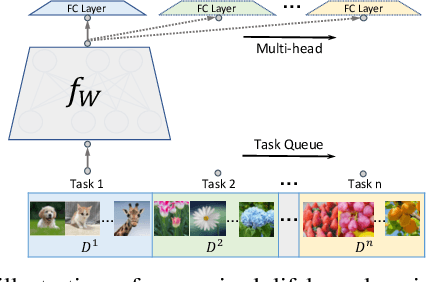
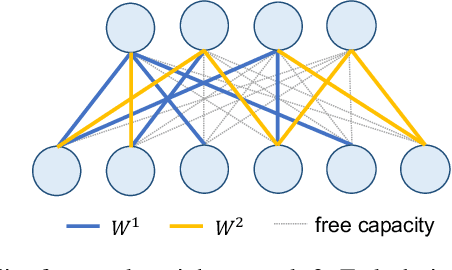
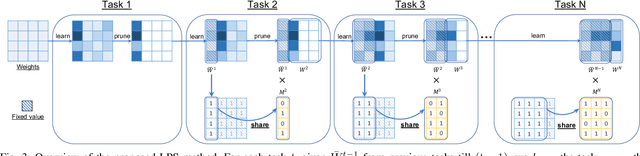
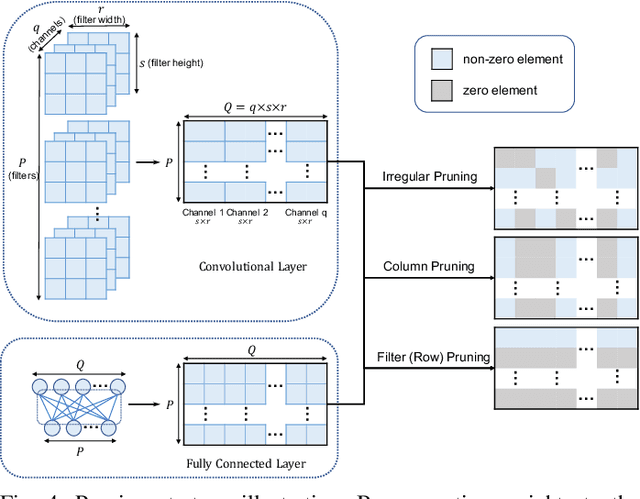
In lifelong learning, we wish to maintain and update a model (e.g., a neural network classifier) in the presence of new classification tasks that arrive sequentially. In this paper, we propose a learn-prune-share (LPS) algorithm which addresses the challenges of catastrophic forgetting, parsimony, and knowledge reuse simultaneously. LPS splits the network into task-specific partitions via an ADMM-based pruning strategy. This leads to no forgetting, while maintaining parsimony. Moreover, LPS integrates a novel selective knowledge sharing scheme into this ADMM optimization framework. This enables adaptive knowledge sharing in an end-to-end fashion. Comprehensive experimental results on two lifelong learning benchmark datasets and a challenging real-world radio frequency fingerprinting dataset are provided to demonstrate the effectiveness of our approach. Our experiments show that LPS consistently outperforms multiple state-of-the-art competitors.
Bandits Under The Influence (Extended Version)
Sep 21, 2020
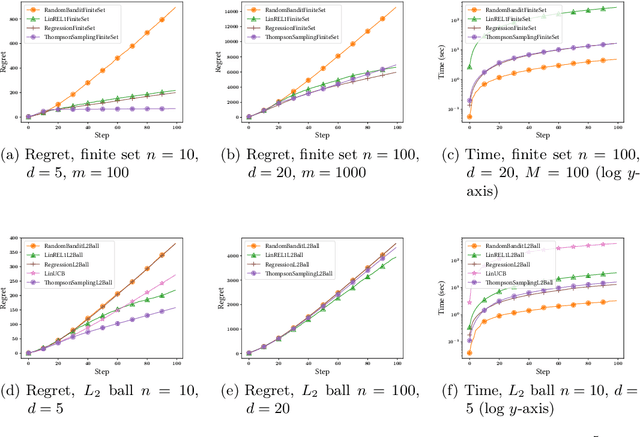

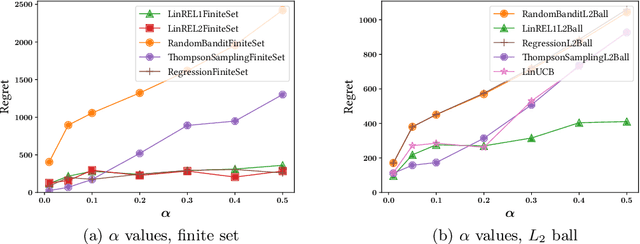
Recommender systems should adapt to user interests as the latter evolve. A prevalent cause for the evolution of user interests is the influence of their social circle. In general, when the interests are not known, online algorithms that explore the recommendation space while also exploiting observed preferences are preferable. We present online recommendation algorithms rooted in the linear multi-armed bandit literature. Our bandit algorithms are tailored precisely to recommendation scenarios where user interests evolve under social influence. In particular, we show that our adaptations of the classic LinREL and Thompson Sampling algorithms maintain the same asymptotic regret bounds as in the non-social case. We validate our approach experimentally using both synthetic and real datasets.
Iterative Spectral Method for Alternative Clustering
Sep 08, 2019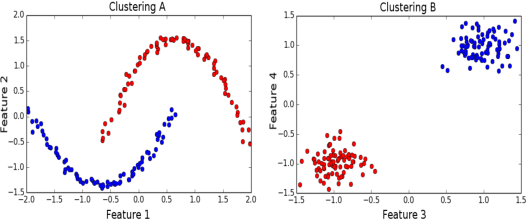
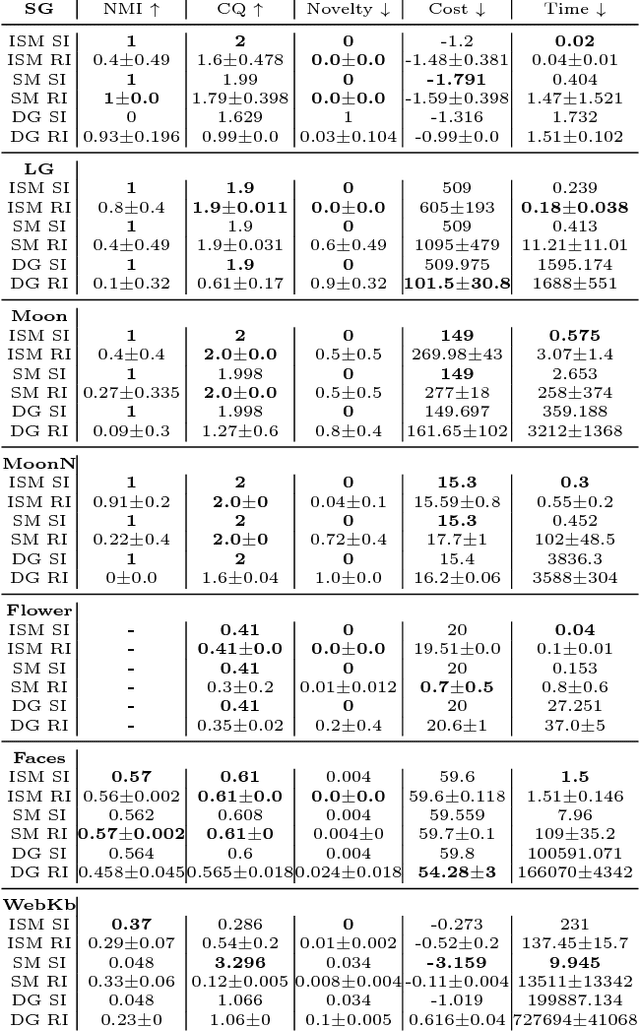
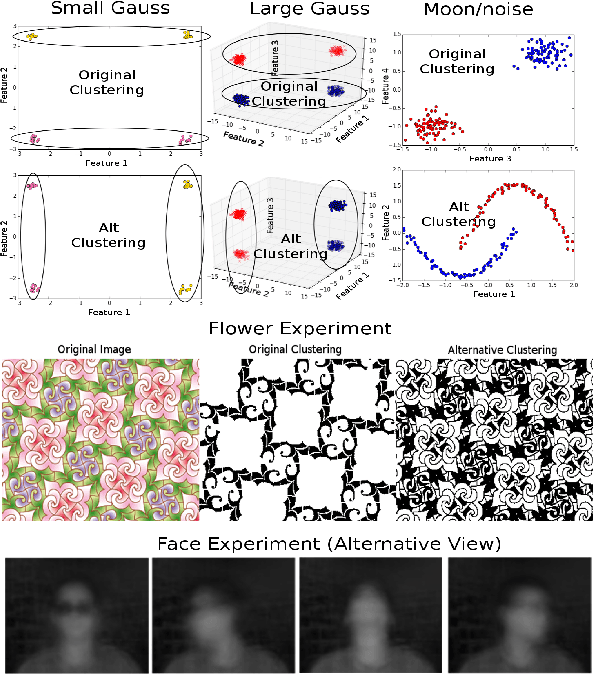

Given a dataset and an existing clustering as input, alternative clustering aims to find an alternative partition. One of the state-of-the-art approaches is Kernel Dimension Alternative Clustering (KDAC). We propose a novel Iterative Spectral Method (ISM) that greatly improves the scalability of KDAC. Our algorithm is intuitive, relies on easily implementable spectral decompositions, and comes with theoretical guarantees. Its computation time improves upon existing implementations of KDAC by as much as 5 orders of magnitude.
Deep Kernel Learning for Clustering
Aug 09, 2019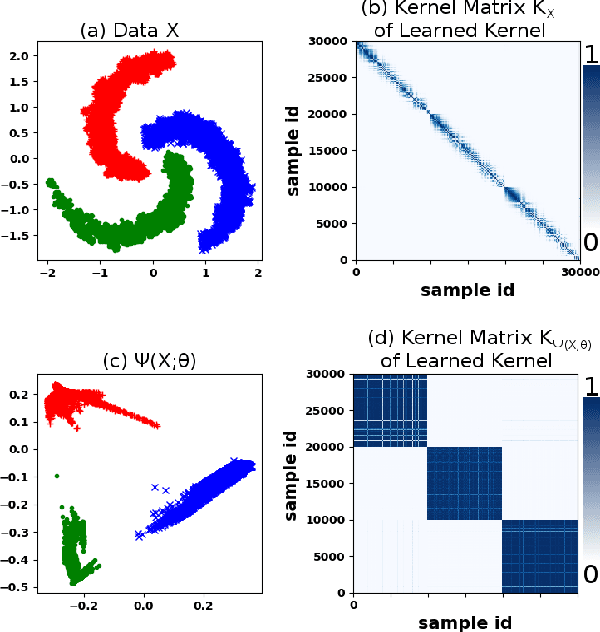

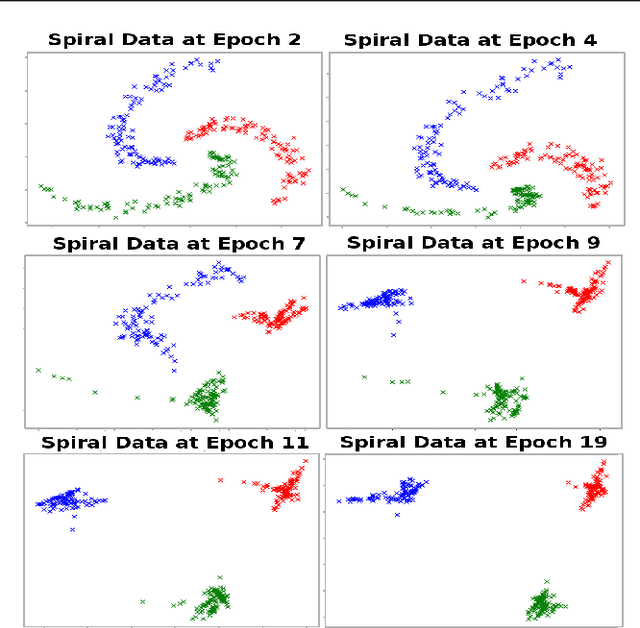
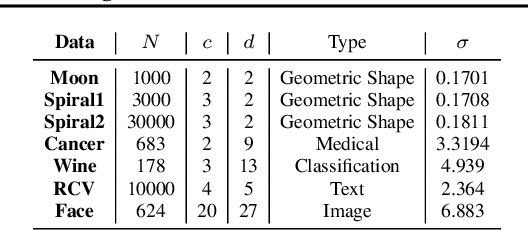
We propose a deep learning approach for discovering kernels tailored to identifying clusters over sample data. Our neural network produces sample embeddings that are motivated by--and are at least as expressive as--spectral clustering. Our training objective, based on the Hilbert Schmidt Information Criterion, can be optimized via gradient adaptations on the Stiefel manifold, leading to significant acceleration over spectral methods relying on eigendecompositions. Finally, our trained embedding can be directly applied to out-of-sample data. We show experimentally that our approach outperforms several state-of-the-art deep clustering methods, as well as traditional approaches such as $k$-means and spectral clustering over a broad array of real-life and synthetic datasets.
Accelerated Experimental Design for Pairwise Comparisons
Jan 18, 2019

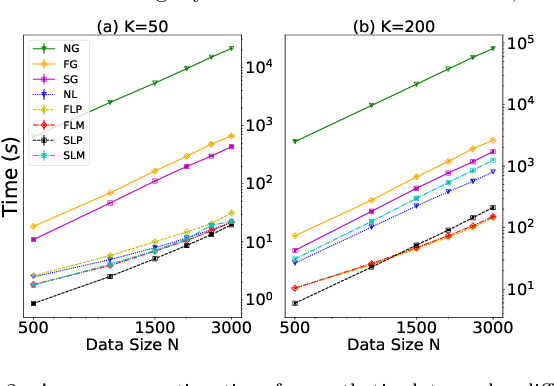
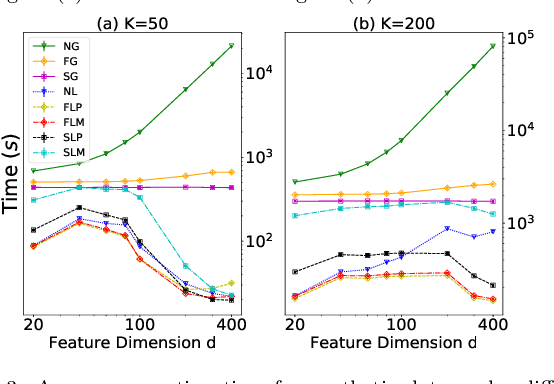
Pairwise comparison labels are more informative and less variable than class labels, but generating them poses a challenge: their number grows quadratically in the dataset size. We study a natural experimental design objective, namely, D-optimality, that can be used to identify which $K$ pairwise comparisons to generate. This objective is known to perform well in practice, and is submodular, making the selection approximable via the greedy algorithm. A na\"ive greedy implementation has $O(N^2d^2K)$ complexity, where $N$ is the dataset size, $d$ is the feature space dimension, and $K$ is the number of generated comparisons. We show that, by exploiting the inherent geometry of the dataset--namely, that it consists of pairwise comparisons--the greedy algorithm's complexity can be reduced to $O(N^2(K+d)+N(dK+d^2) +d^2K).$ We apply the same acceleration also to the so-called lazy greedy algorithm. When combined, the above improvements lead to an execution time of less than 1 hour for a dataset with $10^8$ comparisons; the na\"ive greedy algorithm on the same dataset would require more than 10 days to terminate.
ORACLE: Optimized Radio clAssification through Convolutional neuraL nEtworks
Dec 03, 2018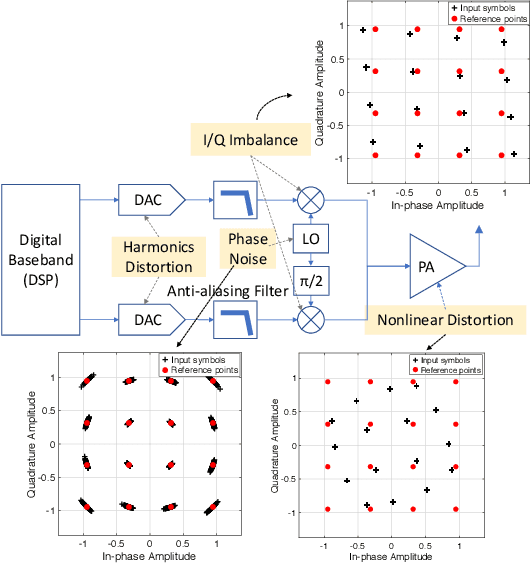
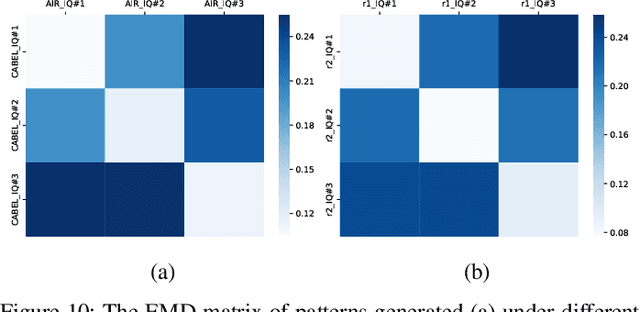
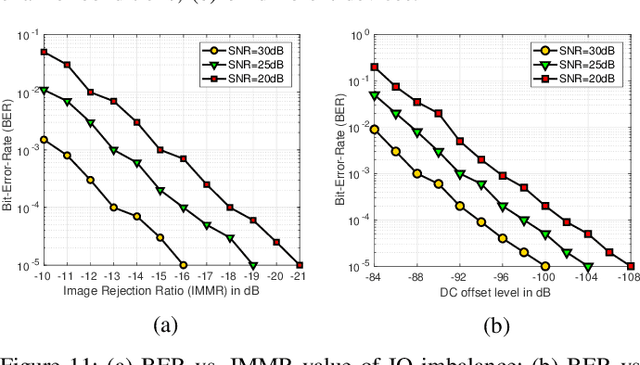
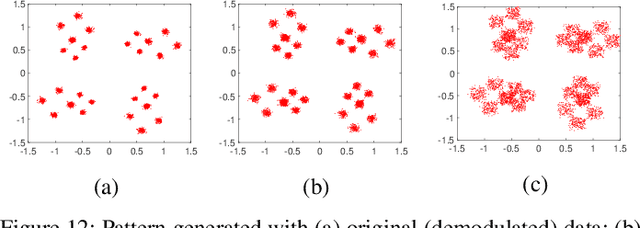
This paper describes the architecture and performance of ORACLE, an approach for detecting a unique radio from a large pool of bit-similar devices (same hardware, protocol, physical address, MAC ID) using only IQ samples at the physical layer. ORACLE trains a convolutional neural network (CNN) that balances computational time and accuracy, showing 99\% classification accuracy for a 16-node USRP X310 SDR testbed and an external database of $>$100 COTS WiFi devices. Our work makes the following contributions: (i) it studies the hardware-centric features within the transmitter chain that causes IQ sample variations; (ii) for an idealized static channel environment, it proposes a CNN architecture requiring only raw IQ samples accessible at the front-end, without channel estimation or prior knowledge of the communication protocol; (iii) for dynamic channels, it demonstrates a principled method of feedback-driven transmitter-side modifications that uses channel estimation at the receiver to increase differentiability for the CNN classifier. The key innovation here is to intentionally introduce controlled imperfections on the transmitter side through software directives, while minimizing the change in bit error rate. Unlike previous work that imposes constant environmental conditions, ORACLE adopts the `train once deploy anywhere' paradigm with near-perfect device classification accuracy.
Deep feature transfer between localization and segmentation tasks
Nov 10, 2018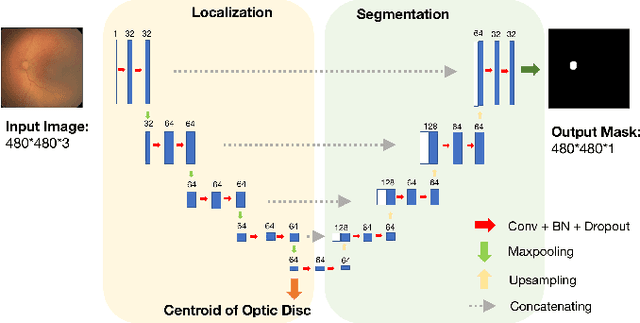
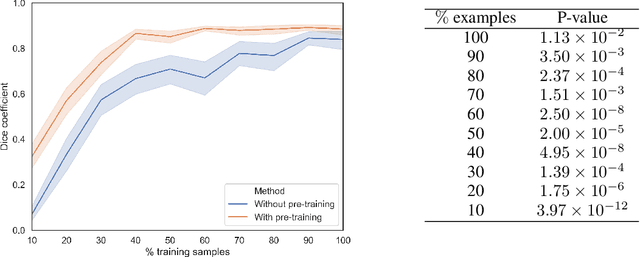
In this paper, we propose a new pre-training scheme for U-net based image segmentation. We first train the encoding arm as a localization network to predict the center of the target, before extending it into a U-net architecture for segmentation. We apply our proposed method to the problem of segmenting the optic disc from fundus photographs. Our work shows that the features learned by encoding arm can be transferred to the segmentation network to reduce the annotation burden. We propose that an approach could have broad utility for medical image segmentation, and alleviate the burden of delineating complex structures by pre-training on annotations that are much easier to acquire.
Learning Combinations of Sigmoids Through Gradient Estimation
Jan 17, 2018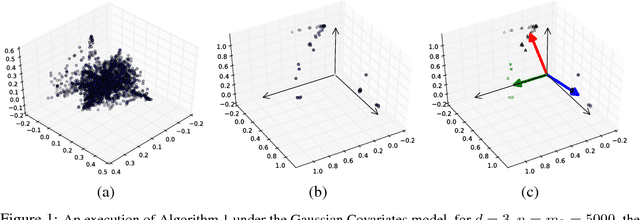
We develop a new approach to learn the parameters of regression models with hidden variables. In a nutshell, we estimate the gradient of the regression function at a set of random points, and cluster the estimated gradients. The centers of the clusters are used as estimates for the parameters of hidden units. We justify this approach by studying a toy model, whereby the regression function is a linear combination of sigmoids. We prove that indeed the estimated gradients concentrate around the parameter vectors of the hidden units, and provide non-asymptotic bounds on the number of required samples. To the best of our knowledge, no comparable guarantees have been proven for linear combinations of sigmoids.