 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCredit-assigned Policy Gradient for Early Stage Retrieval in Two-stage Ranking
May 25, 2026Large-scale search, recommendation, and retrieval-augmented generation (RAG) systems typically employ a two-stage architecture: an early-stage ranker (ESR) generates a candidate set, which is subsequently re-ranked by a late-stage ranker (LSR). While there are many reinforcement learning (RL) methods for training the LSR, end-to-end training of the ESR has proven challenging. In particular, naive application of "vanilla" policy gradient (V-PG) is not scalable for candidate-set sizes relevant for practical use due to exploding variance. This issue arises because V-PG propagates the gradient to the joint probability of the candidate sets, ignoring the contribution of each specific item in the candidate set to the reward. To mitigate this issue, we propose a novel "credit-assigned" policy gradient (CA-PG), which computes gradients with respect to the probability that the target item is chosen in any candidate set, i.e. marginalizing over all candidate sets that contain it. Our theoretical analysis reveals that CA-PG significantly reduces the variance of V-PG by marginalizing over the specific composition of the candidate set, while preserving the ability to learn the correct ranking of items under a reasonably aligned LSR policy. Experiments on both synthetic and real-world data demonstrate that CA-PG improves the convergence speed and training stability for ESRs utilizing the canonical Plackett-Luce model, especially when the candidate-set size is large.
Billion-Scale Graph Foundation Models
Feb 04, 2026Graph-structured data underpins many critical applications. While foundation models have transformed language and vision via large-scale pretraining and lightweight adaptation, extending this paradigm to general, real-world graphs is challenging. In this work, we present Graph Billion- Foundation-Fusion (GraphBFF): the first end-to-end recipe for building billion-parameter Graph Foundation Models (GFMs) for arbitrary heterogeneous, billion-scale graphs. Central to the recipe is the GraphBFF Transformer, a flexible and scalable architecture designed for practical billion-scale GFMs. Using the GraphBFF, we present the first neural scaling laws for general graphs and show that loss decreases predictably as either model capacity or training data scales, depending on which factor is the bottleneck. The GraphBFF framework provides concrete methodologies for data batching, pretraining, and fine-tuning for building GFMs at scale. We demonstrate the effectiveness of the framework with an evaluation of a 1.4 billion-parameter GraphBFF Transformer pretrained on one billion samples. Across ten diverse, real-world downstream tasks on graphs unseen during training, spanning node- and link-level classification and regression, GraphBFF achieves remarkable zero-shot and probing performance, including in few-shot settings, with large margins of up to 31 PRAUC points. Finally, we discuss key challenges and open opportunities for making GFMs a practical and principled foundation for graph learning at industrial scale.
Harm Mitigation in Recommender Systems under User Preference Dynamics
Jun 14, 2024



We consider a recommender system that takes into account the interplay between recommendations, the evolution of user interests, and harmful content. We model the impact of recommendations on user behavior, particularly the tendency to consume harmful content. We seek recommendation policies that establish a tradeoff between maximizing click-through rate (CTR) and mitigating harm. We establish conditions under which the user profile dynamics have a stationary point, and propose algorithms for finding an optimal recommendation policy at stationarity. We experiment on a semi-synthetic movie recommendation setting initialized with real data and observe that our policies outperform baselines at simultaneously maximizing CTR and mitigating harm.
Efficient Online Crowdsourcing with Complex Annotations
Jan 25, 2024



Crowdsourcing platforms use various truth discovery algorithms to aggregate annotations from multiple labelers. In an online setting, however, the main challenge is to decide whether to ask for more annotations for each item to efficiently trade off cost (i.e., the number of annotations) for quality of the aggregated annotations. In this paper, we propose a novel approach for general complex annotation (such as bounding boxes and taxonomy paths), that works in an online crowdsourcing setting. We prove that the expected average similarity of a labeler is linear in their accuracy \emph{conditional on the reported label}. This enables us to infer reported label accuracy in a broad range of scenarios. We conduct extensive evaluations on real-world crowdsourcing data from Meta and show the effectiveness of our proposed online algorithms in improving the cost-quality trade-off.
Friend or Faux: Graph-Based Early Detection of Fake Accounts on Social Networks
Apr 09, 2020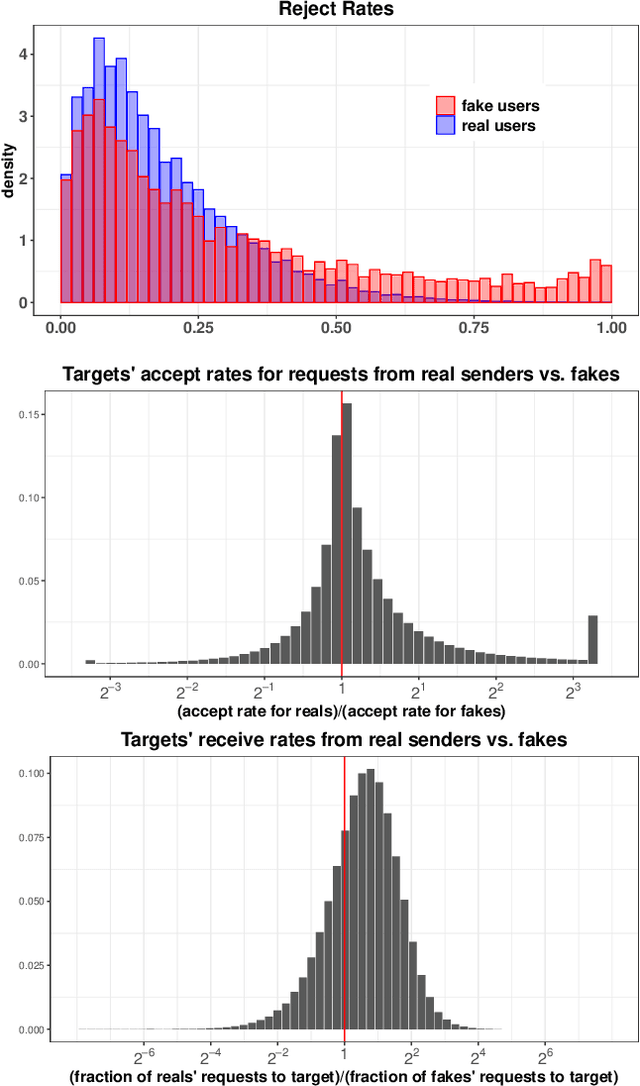

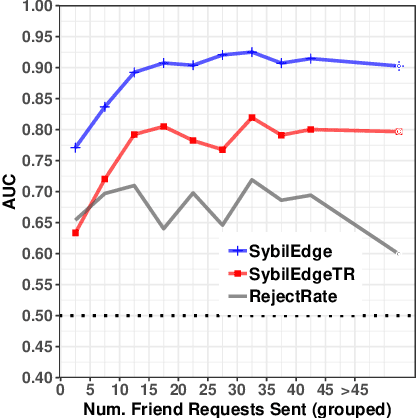
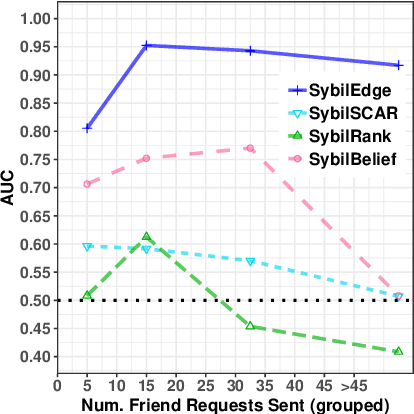
In this paper, we study the problem of early detection of fake user accounts on social networks based solely on their network connectivity with other users. Removing such accounts is a core task for maintaining the integrity of social networks, and early detection helps to reduce the harm that such accounts inflict. However, new fake accounts are notoriously difficult to detect via graph-based algorithms, as their small number of connections are unlikely to reflect a significant structural difference from those of new real accounts. We present the SybilEdge algorithm, which determines whether a new user is a fake account (`sybil') by aggregating over (I) her choices of friend request targets and (II) these targets' respective responses. SybilEdge performs this aggregation giving more weight to a user's choices of targets to the extent that these targets are preferred by other fakes versus real users, and also to the extent that these targets respond differently to fakes versus real users. We show that SybilEdge rapidly detects new fake users at scale on the Facebook network and outperforms state-of-the-art algorithms. We also show that SybilEdge is robust to label noise in the training data, to different prevalences of fake accounts in the network, and to several different ways fakes can select targets for their friend requests. To our knowledge, this is the first time a graph-based algorithm has been shown to achieve high performance (AUC>0.9) on new users who have only sent a small number of friend requests.
Recommending with an Agenda: Active Learning of Private Attributes using Matrix Factorization
Jul 30, 2014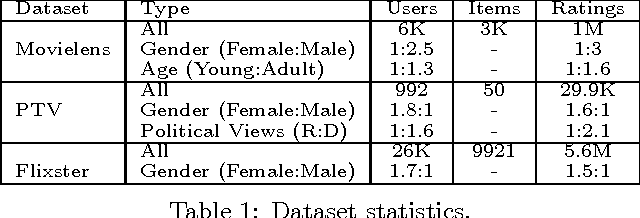
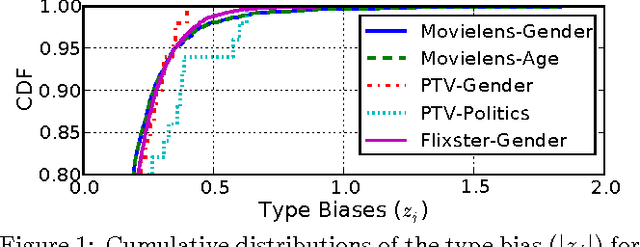
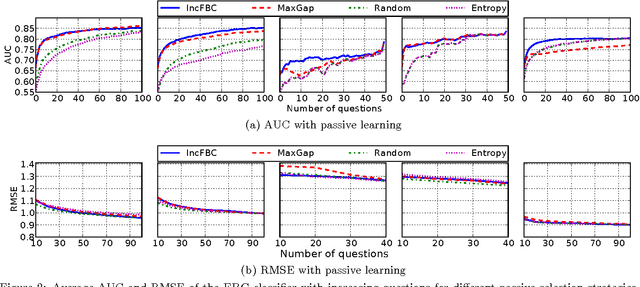
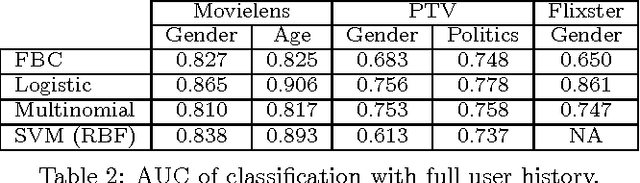
Recommender systems leverage user demographic information, such as age, gender, etc., to personalize recommendations and better place their targeted ads. Oftentimes, users do not volunteer this information due to privacy concerns, or due to a lack of initiative in filling out their online profiles. We illustrate a new threat in which a recommender learns private attributes of users who do not voluntarily disclose them. We design both passive and active attacks that solicit ratings for strategically selected items, and could thus be used by a recommender system to pursue this hidden agenda. Our methods are based on a novel usage of Bayesian matrix factorization in an active learning setting. Evaluations on multiple datasets illustrate that such attacks are indeed feasible and use significantly fewer rated items than static inference methods. Importantly, they succeed without sacrificing the quality of recommendations to users.
Privacy Tradeoffs in Predictive Analytics
Mar 31, 2014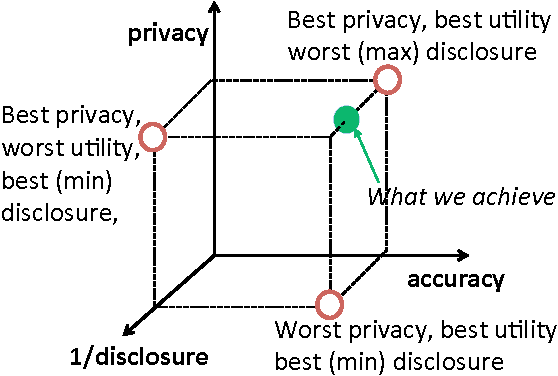
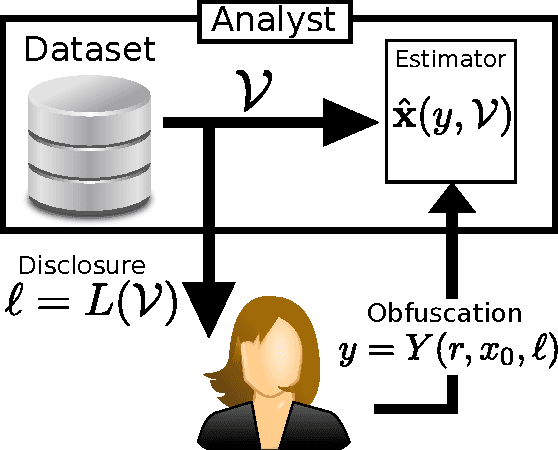
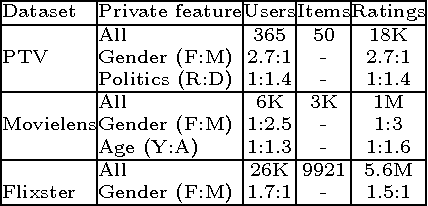
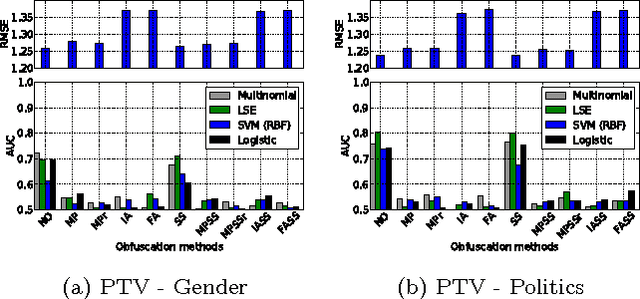
Online services routinely mine user data to predict user preferences, make recommendations, and place targeted ads. Recent research has demonstrated that several private user attributes (such as political affiliation, sexual orientation, and gender) can be inferred from such data. Can a privacy-conscious user benefit from personalization while simultaneously protecting her private attributes? We study this question in the context of a rating prediction service based on matrix factorization. We construct a protocol of interactions between the service and users that has remarkable optimality properties: it is privacy-preserving, in that no inference algorithm can succeed in inferring a user's private attribute with a probability better than random guessing; it has maximal accuracy, in that no other privacy-preserving protocol improves rating prediction; and, finally, it involves a minimal disclosure, as the prediction accuracy strictly decreases when the service reveals less information. We extensively evaluate our protocol using several rating datasets, demonstrating that it successfully blocks the inference of gender, age and political affiliation, while incurring less than 5% decrease in the accuracy of rating prediction.