 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainable deep learning for insights in El Nino and river flows
Jan 12, 2022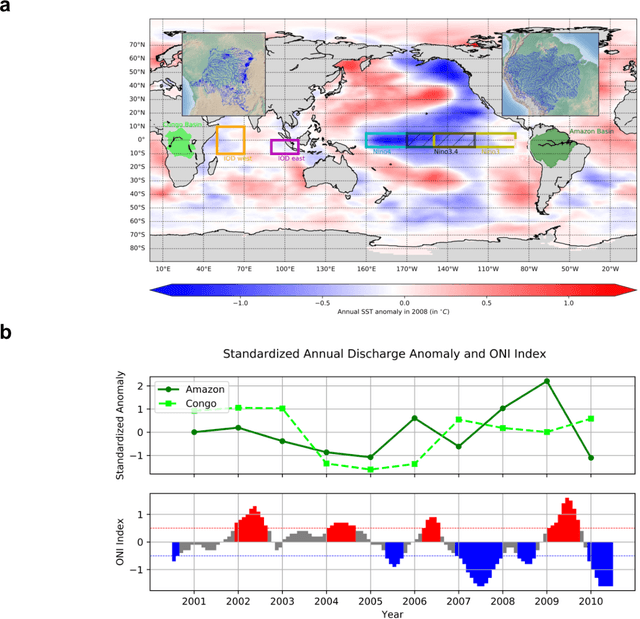
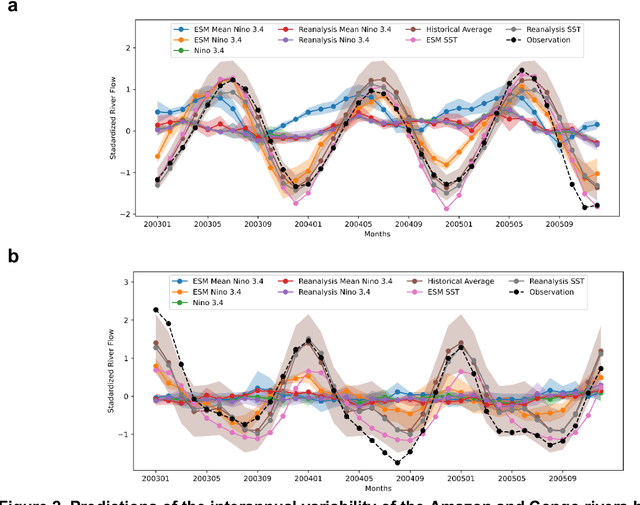
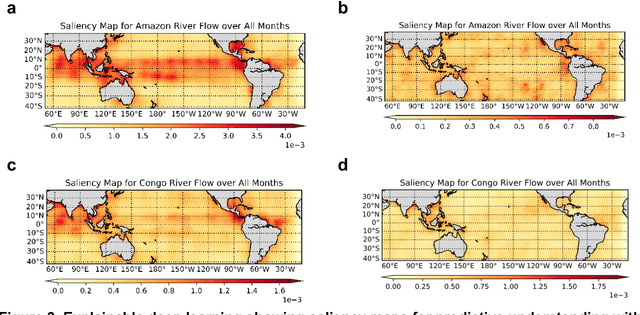
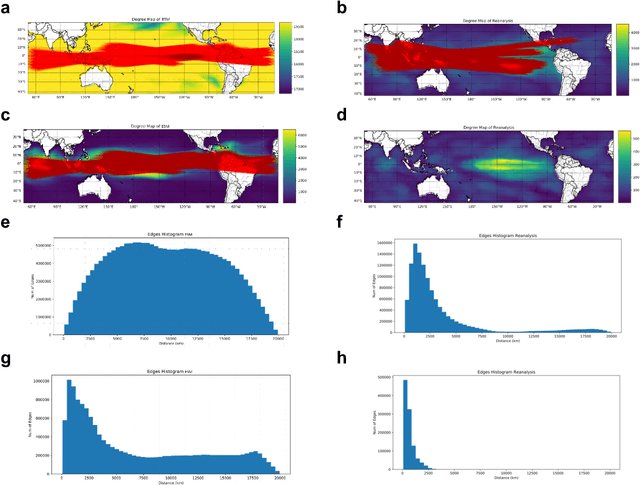
The El Nino Southern Oscillation (ENSO) is a semi-periodic fluctuation in sea surface temperature (SST) over the tropical central and eastern Pacific Ocean that influences interannual variability in regional hydrology across the world through long-range dependence or teleconnections. Recent research has demonstrated the value of Deep Learning (DL) methods for improving ENSO prediction as well as Complex Networks (CN) for understanding teleconnections. However, gaps in predictive understanding of ENSO-driven river flows include the black box nature of DL, the use of simple ENSO indices to describe a complex phenomenon and translating DL-based ENSO predictions to river flow predictions. Here we show that eXplainable DL (XDL) methods, based on saliency maps, can extract interpretable predictive information contained in global SST and discover novel SST information regions and dependence structures relevant for river flows which, in tandem with climate network constructions, enable improved predictive understanding. Our results reveal additional information content in global SST beyond ENSO indices, develop new understanding of how SSTs influence river flows, and generate improved river flow predictions with uncertainties. Observations, reanalysis data, and earth system model simulations are used to demonstrate the value of the XDL-CN based methods for future interannual and decadal scale climate projections.
Evaluating Combinatorial Generalization in Variational Autoencoders
Nov 11, 2019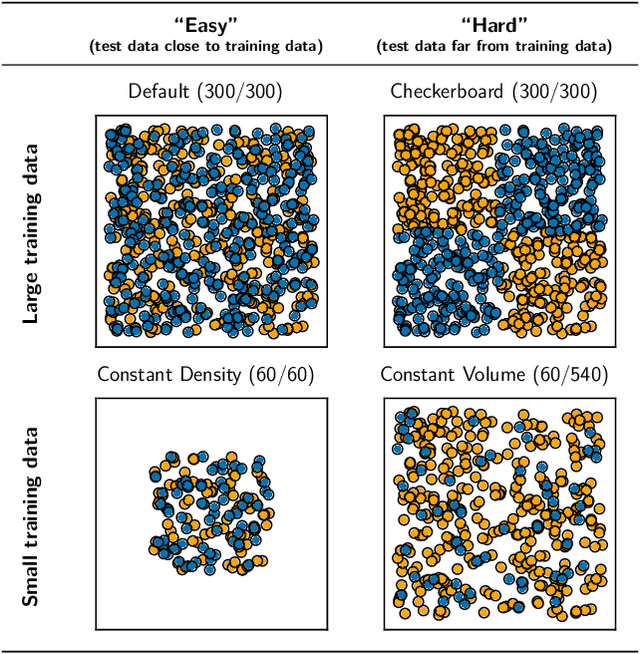
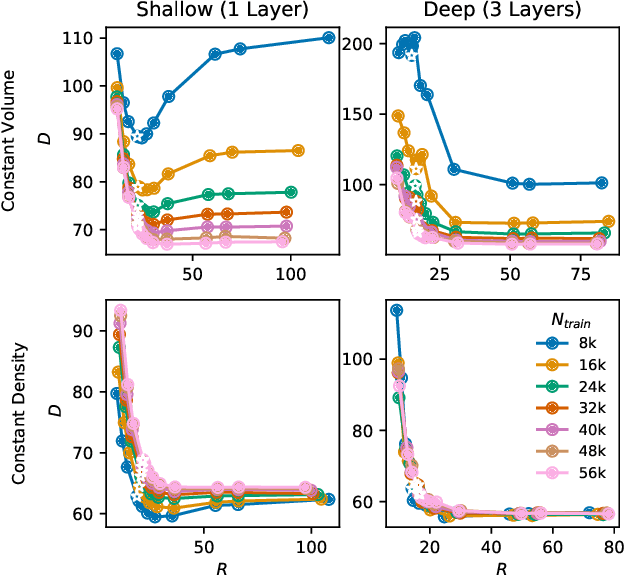

We evaluate the ability of variational autoencoders to generalize to unseen examples in domains with a large combinatorial space of feature values. Our experiments systematically evaluate the effect of network width, depth, regularization, and the typical distance between the training and test examples. Increasing network capacity benefits generalization in easy problems, where test-set examples are similar to training examples. In more difficult problems, increasing capacity deteriorates generalization when optimizing the standard VAE objective, but once again improves generalization when we decrease the KL regularization. Our results establish that interplay between model capacity and KL regularization is not clear cut; we need to take the typical distance between train and test examples into account when evaluating generalization.
Iterative Spectral Method for Alternative Clustering
Sep 08, 2019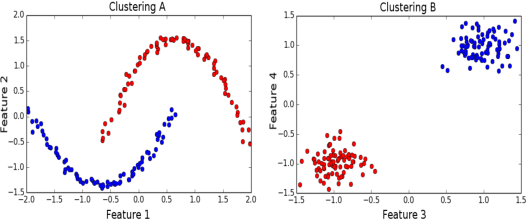
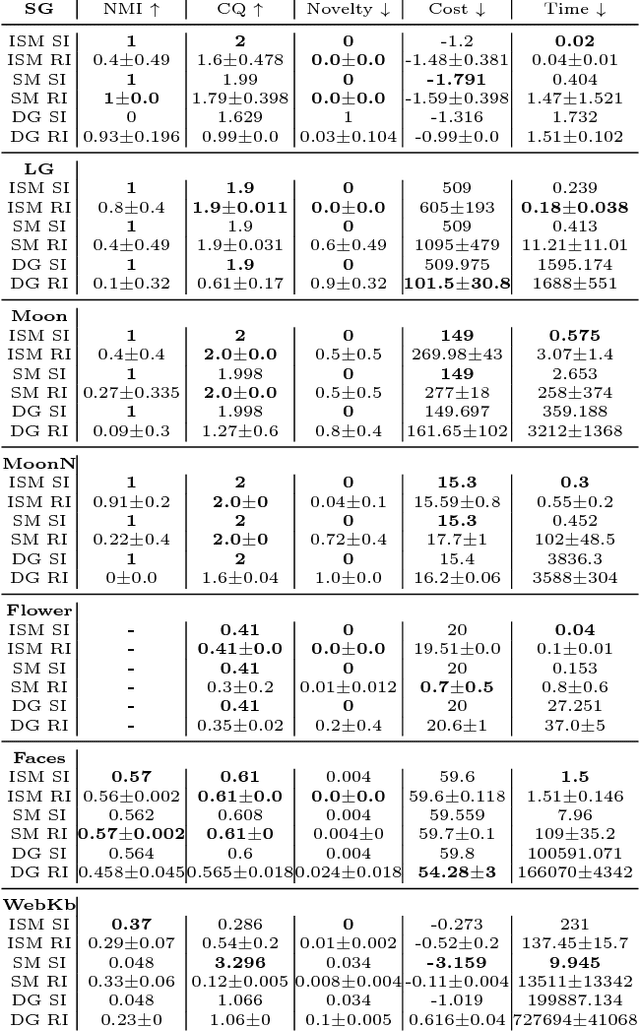
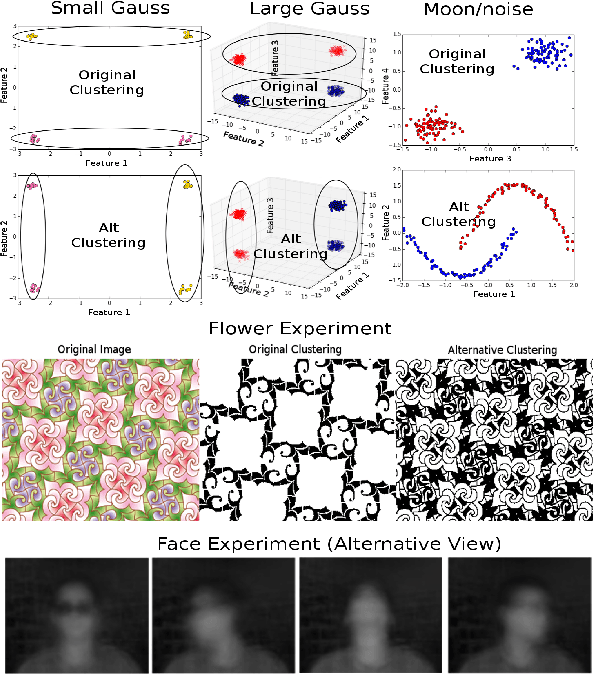

Given a dataset and an existing clustering as input, alternative clustering aims to find an alternative partition. One of the state-of-the-art approaches is Kernel Dimension Alternative Clustering (KDAC). We propose a novel Iterative Spectral Method (ISM) that greatly improves the scalability of KDAC. Our algorithm is intuitive, relies on easily implementable spectral decompositions, and comes with theoretical guarantees. Its computation time improves upon existing implementations of KDAC by as much as 5 orders of magnitude.
Adaptive Nonparametric Variational Autoencoder
Jun 07, 2019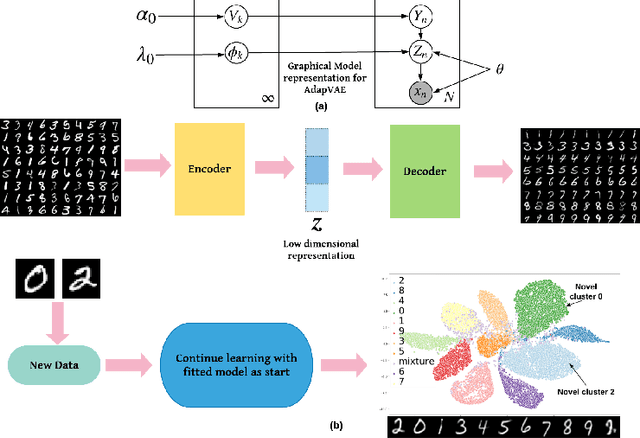


Clustering is used to find structure in unlabeled data by grouping similar objects together. Cluster analysis depends on the definition of similarity in the feature space. In this paper, we propose an Adaptive Nonparametric Variational Autoencoder (AdapVAE) to perform end-to-end feature learning from raw data jointly with cluster membership learning through a Nonparametric Bayesian modeling framework with deep neural networks. It has the advantage of avoiding pre-definition of similarity or feature engineering. Our model relaxes the constraint of fixing the number of clusters in advance by assigning a Dirichlet Process prior on the latent representation in a low-dimensional feature space. It can adaptively detect novel clusters when new data arrives based on a learned model from historical data in an online unsupervised learning setting. We develop a joint online variational inference algorithm to learn feature representations and cluster assignments via iteratively optimizing the evidence lower bound (ELBO). Our experimental results demonstrate the capacity of our modelling framework to learn the number of clusters automatically using data, the flexibility to detect novel clusters with emerging data adaptively, the ability of high quality reconstruction and generation of samples without supervised information and the improvement over state-of-the-art end-to-end clustering methods in terms of accuracy on both image and text corpora benchmark datasets.
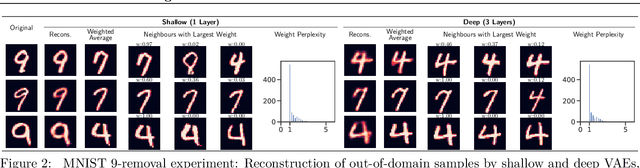
Can VAEs Generate Novel Examples?
Dec 22, 2018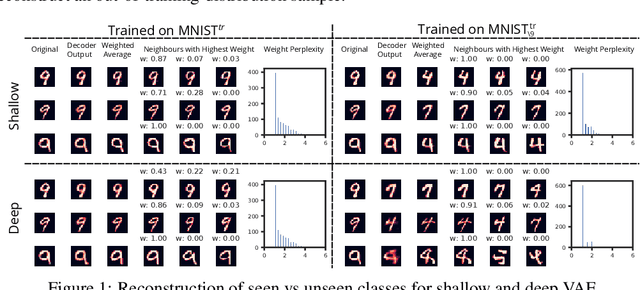
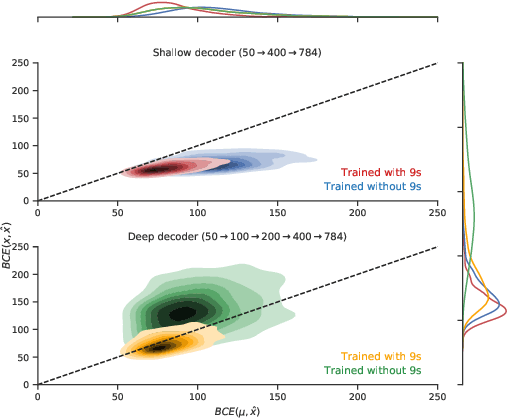

An implicit goal in works on deep generative models is that such models should be able to generate novel examples that were not previously seen in the training data. In this paper, we investigate to what extent this property holds for widely employed variational autoencoder (VAE) architectures. VAEs maximize a lower bound on the log marginal likelihood, which implies that they will in principle overfit the training data when provided with a sufficiently expressive decoder. In the limit of an infinite capacity decoder, the optimal generative model is a uniform mixture over the training data. More generally, an optimal decoder should output a weighted average over the examples in the training data, where the magnitude of the weights is determined by the proximity in the latent space. This leads to the hypothesis that, for a sufficiently high capacity encoder and decoder, the VAE decoder will perform nearest-neighbor matching according to the coordinates in the latent space. To test this hypothesis, we investigate generalization on the MNIST dataset. We consider both generalization to new examples of previously seen classes, and generalization to the classes that were withheld from the training set. In both cases, we find that reconstructions are closely approximated by nearest neighbors for higher-dimensional parameterizations. When generalizing to unseen classes however, lower-dimensional parameterizations offer a clear advantage.
A Multiresolution Convolutional Neural Network with Partial Label Training for Annotating Reflectance Confocal Microscopy Images of Skin
Aug 23, 2018
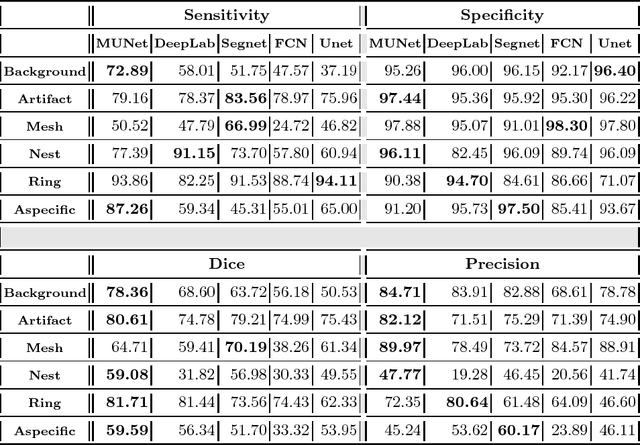
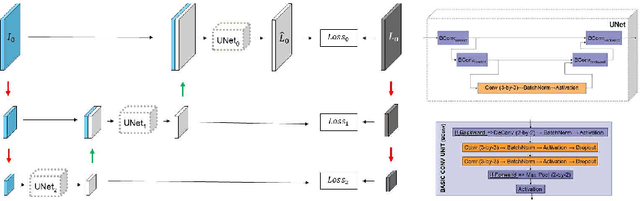

We describe a new multiresolution "nested encoder-decoder" convolutional network architecture and use it to annotate morphological patterns in reflectance confocal microscopy (RCM) images of human skin for aiding cancer diagnosis. Skin cancers are the most common types of cancers, melanoma being the deadliest among them. RCM is an effective, non-invasive pre-screening tool for skin cancer diagnosis, with the required cellular resolution. However, images are complex, low-contrast, and highly variable, so that clinicians require months to years of expert-level training to be able to make accurate assessments. In this paper, we address classifying 4 key clinically important structural/textural patterns in RCM images. The occurrence and morphology of these patterns are used by clinicians for diagnosis of melanomas. The large size of RCM images, the large variance of pattern size, the large-scale range over which patterns appear, the class imbalance in collected images, and the lack of fully-labeled images all make this a challenging problem to address, even with automated machine learning tools. We designed a novel nested U-net architecture to cope with these challenges, and a selective loss function to handle partial labeling. Trained and tested on 56 melanoma-suspicious, partially labeled, 12k x 12k pixel images, our network automatically annotated diagnostic patterns with high sensitivity and specificity, providing consistent labels for unlabeled sections of the test images. Providing such annotation will aid clinicians in achieving diagnostic accuracy, and perhaps more important, dramatically facilitate clinical training, thus enabling much more rapid adoption of RCM into widespread clinical use process. In addition, our adaptation of U-net architecture provides an intrinsically multiresolution deep network that may be useful in other challenging biomedical image analysis applications.
Delineation of Skin Strata in Reflectance Confocal Microscopy Images using Recurrent Convolutional Networks with Toeplitz Attention
Dec 01, 2017
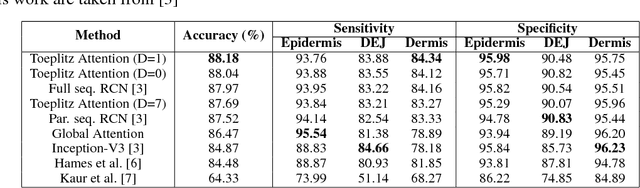
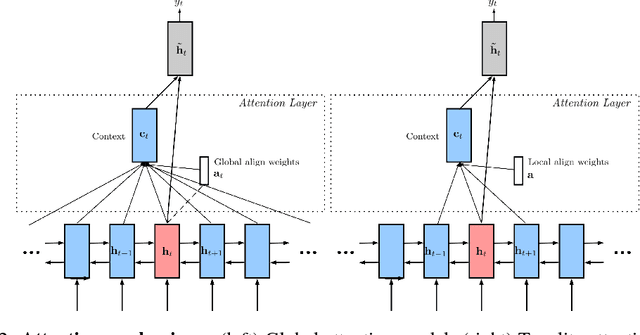
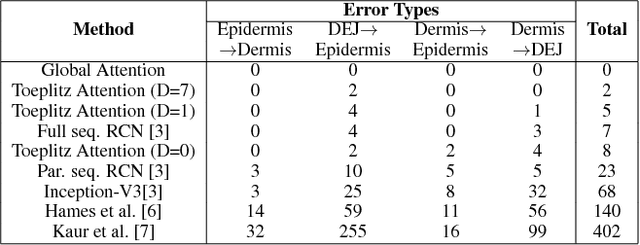
Reflectance confocal microscopy (RCM) is an effective, non-invasive pre-screening tool for skin cancer diagnosis, but it requires extensive training and experience to assess accurately. There are few quantitative tools available to standardize image acquisition and analysis, and the ones that are available are not interpretable. In this study, we use a recurrent neural network with attention on convolutional network features. We apply it to delineate skin strata in vertically-oriented stacks of transverse RCM image slices in an interpretable manner. We introduce a new attention mechanism called Toeplitz attention, which constrains the attention map to have a Toeplitz structure. Testing our model on an expert labeled dataset of 504 RCM stacks, we achieve 88.17% image-wise classification accuracy, which is the current state-of-art.
Asymptotic Analysis of Objectives based on Fisher Information in Active Learning
Oct 14, 2016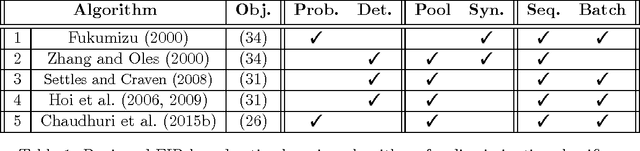

Obtaining labels can be costly and time-consuming. Active learning allows a learning algorithm to intelligently query samples to be labeled for efficient learning. Fisher information ratio (FIR) has been used as an objective for selecting queries in active learning. However, little is known about the theory behind the use of FIR for active learning. There is a gap between the underlying theory and the motivation of its usage in practice. In this paper, we attempt to fill this gap and provide a rigorous framework for analyzing existing FIR-based active learning methods. In particular, we show that FIR can be asymptotically viewed as an upper bound of the expected variance of the log-likelihood ratio. Additionally, our analysis suggests a unifying framework that not only enables us to make theoretical comparisons among the existing querying methods based on FIR, but also allows us to give insight into the development of new active learning approaches based on this objective.
Multi-task Learning with Weak Class Labels: Leveraging iEEG to Detect Cortical Lesions in Cryptogenic Epilepsy
Jul 30, 2016
Multi-task learning (MTL) is useful for domains in which data originates from multiple sources that are individually under-sampled. MTL methods are able to learn classification models that have higher performance as compared to learning a single model by aggregating all the data together or learning a separate model for each data source. The performance of these methods relies on label accuracy. We address the problem of simultaneously learning multiple classifiers in the MTL framework when the training data has imprecise labels. We assume that there is an additional source of information that provides a score for each instance which reflects the certainty about its label. Modeling this score as being generated by an underlying ranking function, we augment the MTL framework with an added layer of supervision. This results in new MTL methods that are able to learn accurate classifiers while preserving the domain structure provided through the rank information. We apply these methods to the task of detecting abnormal cortical regions in the MRIs of patients suffering from focal epilepsy whose MRI were read as normal by expert neuroradiologists. In addition to the noisy labels provided by the results of surgical resection, we employ the results of an invasive intracranial-EEG exam as an additional source of label information. Our proposed methods are able to successfully detect abnormal regions for all patients in our dataset and achieve a higher performance as compared to baseline methods.