 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelative Entropy Regularized Policy Iteration
Dec 05, 2018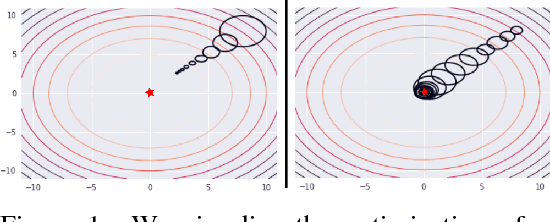
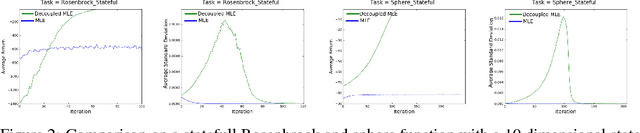

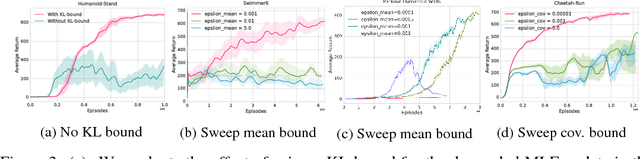
We present an off-policy actor-critic algorithm for Reinforcement Learning (RL) that combines ideas from gradient-free optimization via stochastic search with learned action-value function. The result is a simple procedure consisting of three steps: i) policy evaluation by estimating a parametric action-value function; ii) policy improvement via the estimation of a local non-parametric policy; and iii) generalization by fitting a parametric policy. Each step can be implemented in different ways, giving rise to several algorithm variants. Our algorithm draws on connections to existing literature on black-box optimization and 'RL as an inference' and it can be seen either as an extension of the Maximum a Posteriori Policy Optimisation algorithm (MPO) [Abdolmaleki et al., 2018a], or as an extension of Trust Region Covariance Matrix Adaptation Evolutionary Strategy (CMA-ES) [Abdolmaleki et al., 2017b; Hansen et al., 1997] to a policy iteration scheme. Our comparison on 31 continuous control tasks from parkour suite [Heess et al., 2017], DeepMind control suite [Tassa et al., 2018] and OpenAI Gym [Brockman et al., 2016] with diverse properties, limited amount of compute and a single set of hyperparameters, demonstrate the effectiveness of our method and the state of art results. Videos, summarizing results, can be found at goo.gl/HtvJKR .
Sim-to-Real: Learning Agile Locomotion For Quadruped Robots
May 16, 2018

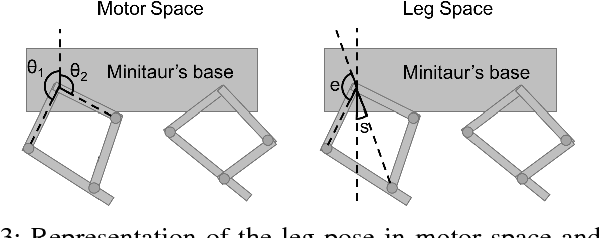
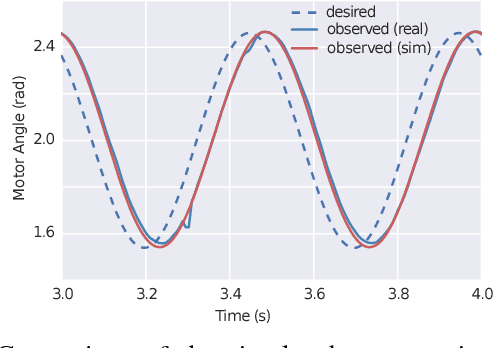
Designing agile locomotion for quadruped robots often requires extensive expertise and tedious manual tuning. In this paper, we present a system to automate this process by leveraging deep reinforcement learning techniques. Our system can learn quadruped locomotion from scratch using simple reward signals. In addition, users can provide an open loop reference to guide the learning process when more control over the learned gait is needed. The control policies are learned in a physics simulator and then deployed on real robots. In robotics, policies trained in simulation often do not transfer to the real world. We narrow this reality gap by improving the physics simulator and learning robust policies. We improve the simulation using system identification, developing an accurate actuator model and simulating latency. We learn robust controllers by randomizing the physical environments, adding perturbations and designing a compact observation space. We evaluate our system on two agile locomotion gaits: trotting and galloping. After learning in simulation, a quadruped robot can successfully perform both gaits in the real world.
Transfer Learning with Binary Neural Networks
Nov 29, 2017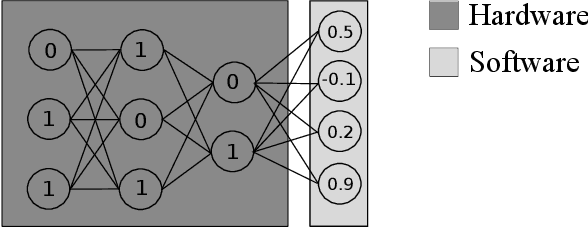
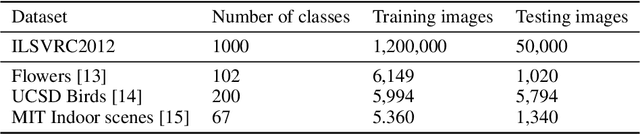
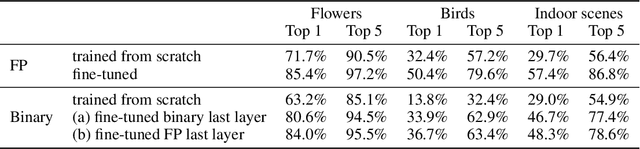
Previous work has shown that it is possible to train deep neural networks with low precision weights and activations. In the extreme case it is even possible to constrain the network to binary values. The costly floating point multiplications are then reduced to fast logical operations. High end smart phones such as Google's Pixel 2 and Apple's iPhone X are already equipped with specialised hardware for image processing and it is very likely that other future consumer hardware will also have dedicated accelerators for deep neural networks. Binary neural networks are attractive in this case because the logical operations are very fast and efficient when implemented in hardware. We propose a transfer learning based architecture where we first train a binary network on Imagenet and then retrain part of the network for different tasks while keeping most of the network fixed. The fixed binary part could be implemented in a hardware accelerator while the last layers of the network are evaluated in software. We show that a single binary neural network trained on the Imagenet dataset can indeed be used as a feature extractor for other datasets.
Decoupled Learning of Environment Characteristics for Safe Exploration
Aug 09, 2017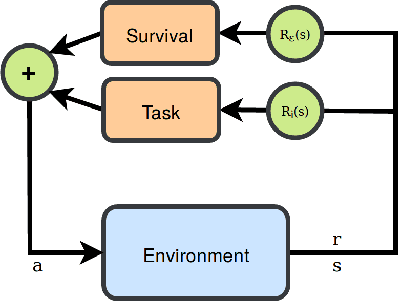

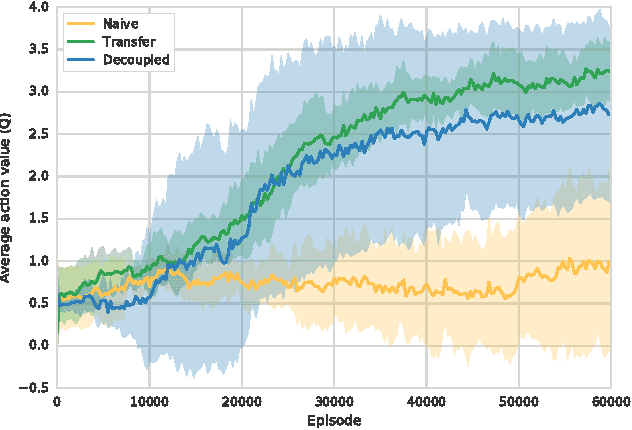
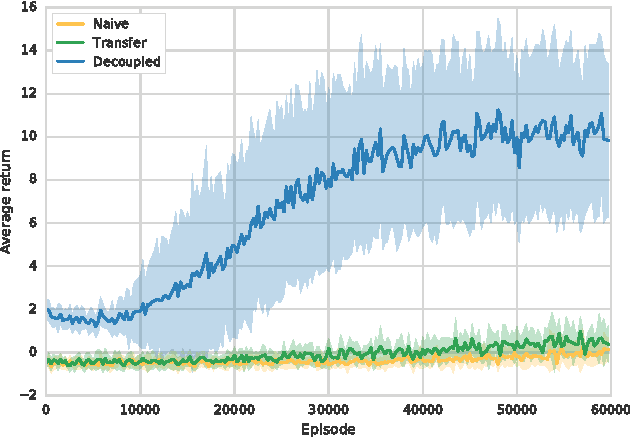
Reinforcement learning is a proven technique for an agent to learn a task. However, when learning a task using reinforcement learning, the agent cannot distinguish the characteristics of the environment from those of the task. This makes it harder to transfer skills between tasks in the same environment. Furthermore, this does not reduce risk when training for a new task. In this paper, we introduce an approach to decouple the environment characteristics from the task-specific ones, allowing an agent to develop a sense of survival. We evaluate our approach in an environment where an agent must learn a sequence of collection tasks, and show that decoupled learning allows for a safer utilization of prior knowledge.
Sensor Fusion for Robot Control through Deep Reinforcement Learning
Mar 13, 2017
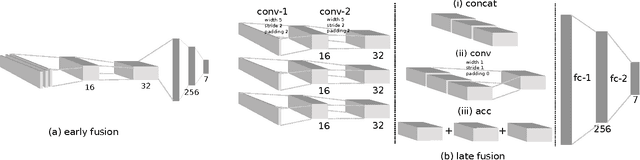
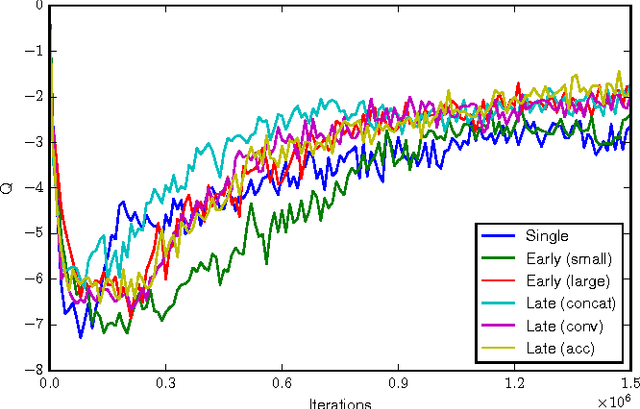
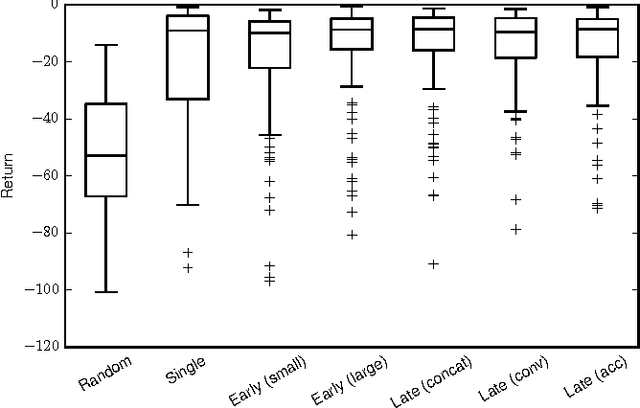
Deep reinforcement learning is becoming increasingly popular for robot control algorithms, with the aim for a robot to self-learn useful feature representations from unstructured sensory input leading to the optimal actuation policy. In addition to sensors mounted on the robot, sensors might also be deployed in the environment, although these might need to be accessed via an unreliable wireless connection. In this paper, we demonstrate deep neural network architectures that are able to fuse information coming from multiple sensors and are robust to sensor failures at runtime. We evaluate our method on a search and pick task for a robot both in simulation and the real world.
Lazy Evaluation of Convolutional Filters
May 27, 2016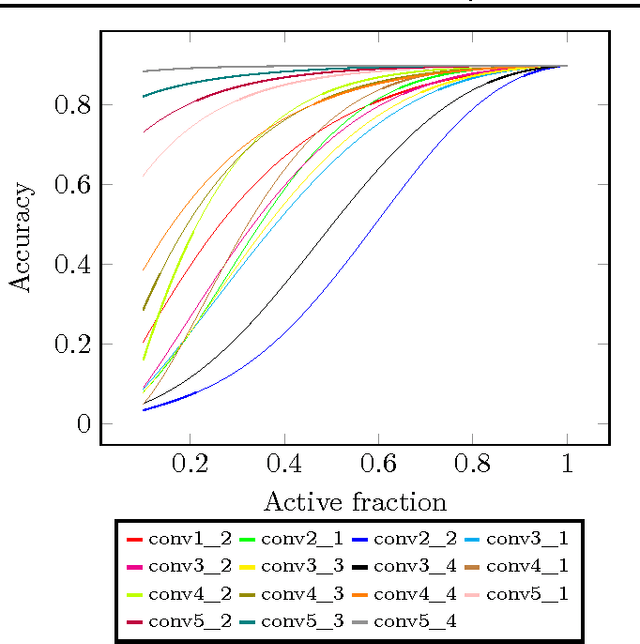
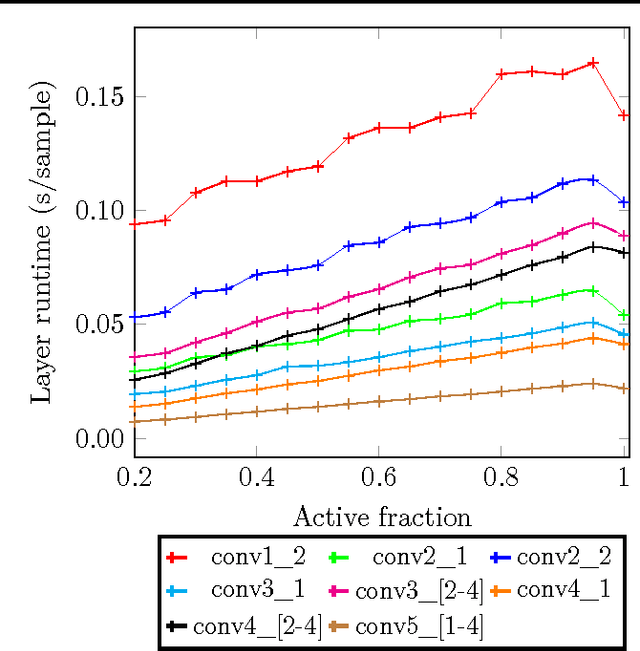
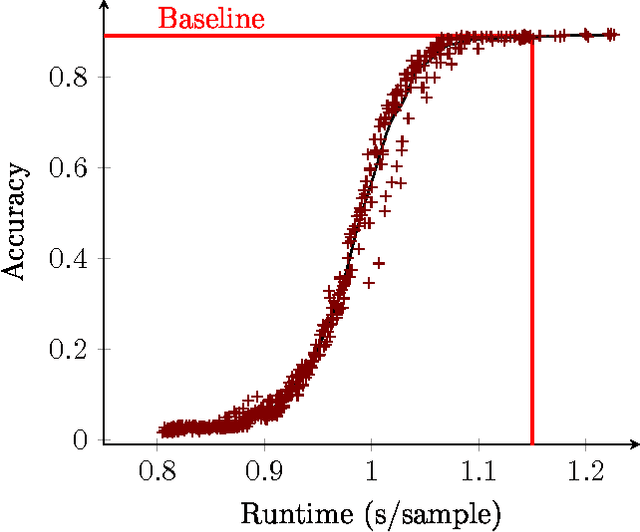
In this paper we propose a technique which avoids the evaluation of certain convolutional filters in a deep neural network. This allows to trade-off the accuracy of a deep neural network with the computational and memory requirements. This is especially important on a constrained device unable to hold all the weights of the network in memory.
Efficiency Evaluation of Character-level RNN Training Schedules
May 09, 2016
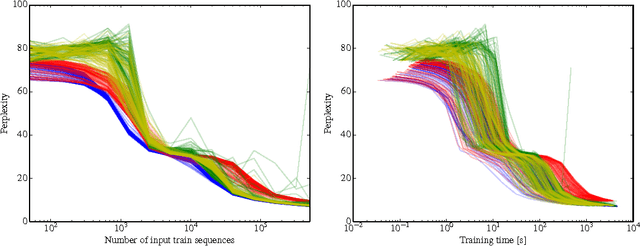
We present four training and prediction schedules from the same character-level recurrent neural network. The efficiency of these schedules is tested in terms of model effectiveness as a function of training time and amount of training data seen. We show that the choice of training and prediction schedule potentially has a considerable impact on the prediction effectiveness for a given training budget.
Learning Semantic Similarity for Very Short Texts
Dec 02, 2015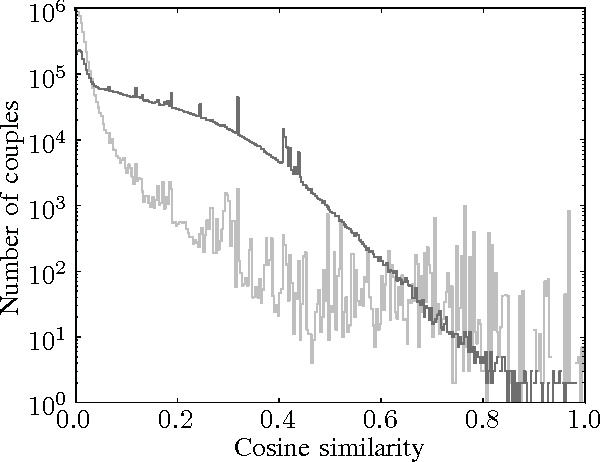
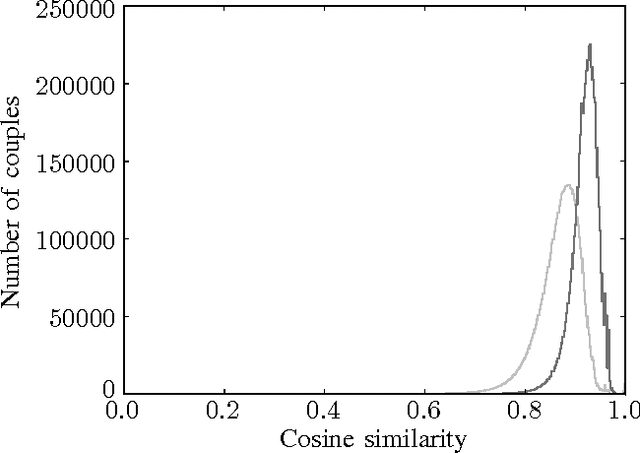
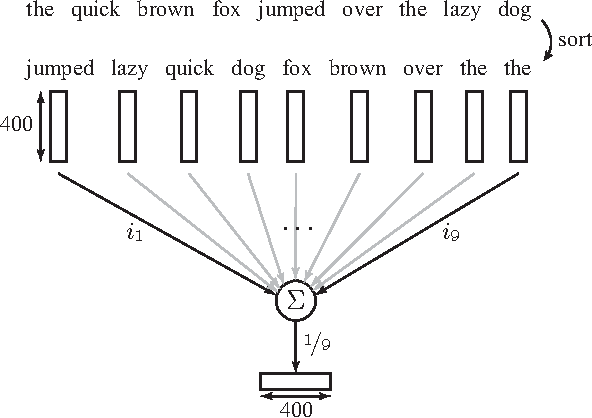
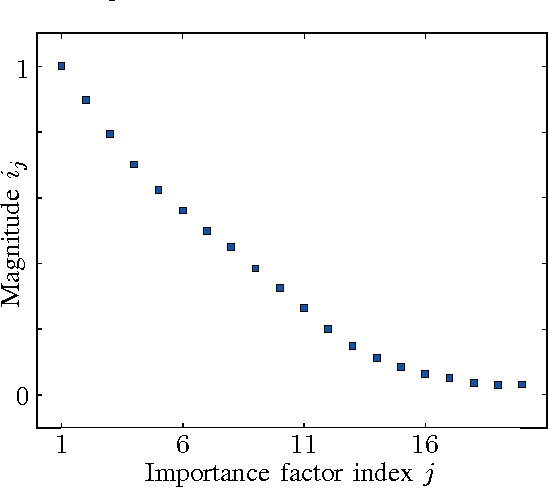
Levering data on social media, such as Twitter and Facebook, requires information retrieval algorithms to become able to relate very short text fragments to each other. Traditional text similarity methods such as tf-idf cosine-similarity, based on word overlap, mostly fail to produce good results in this case, since word overlap is little or non-existent. Recently, distributed word representations, or word embeddings, have been shown to successfully allow words to match on the semantic level. In order to pair short text fragments - as a concatenation of separate words - an adequate distributed sentence representation is needed, in existing literature often obtained by naively combining the individual word representations. We therefore investigated several text representations as a combination of word embeddings in the context of semantic pair matching. This paper investigates the effectiveness of several such naive techniques, as well as traditional tf-idf similarity, for fragments of different lengths. Our main contribution is a first step towards a hybrid method that combines the strength of dense distributed representations - as opposed to sparse term matching - with the strength of tf-idf based methods to automatically reduce the impact of less informative terms. Our new approach outperforms the existing techniques in a toy experimental set-up, leading to the conclusion that the combination of word embeddings and tf-idf information might lead to a better model for semantic content within very short text fragments.