 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSwin Transformer: Hierarchical Vision Transformer using Shifted Windows
Mar 25, 2021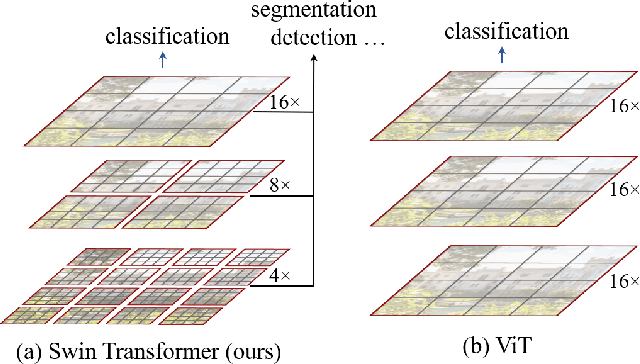
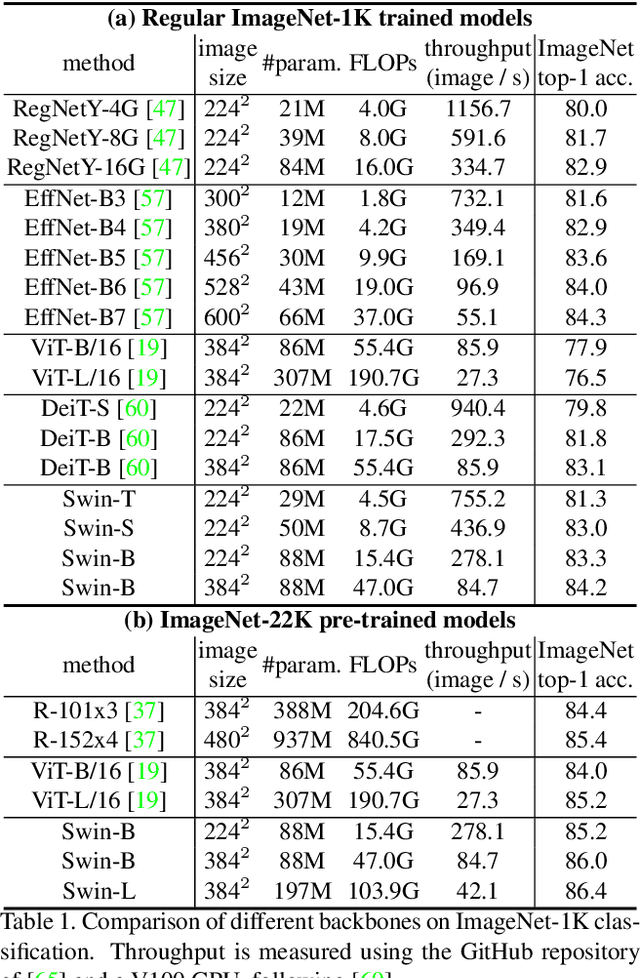
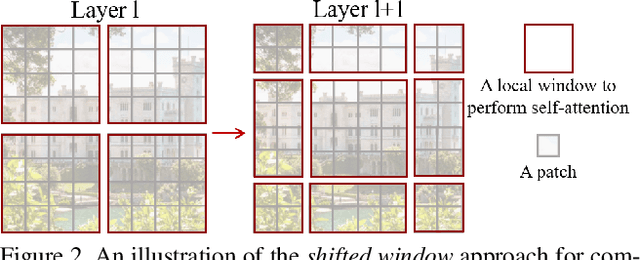
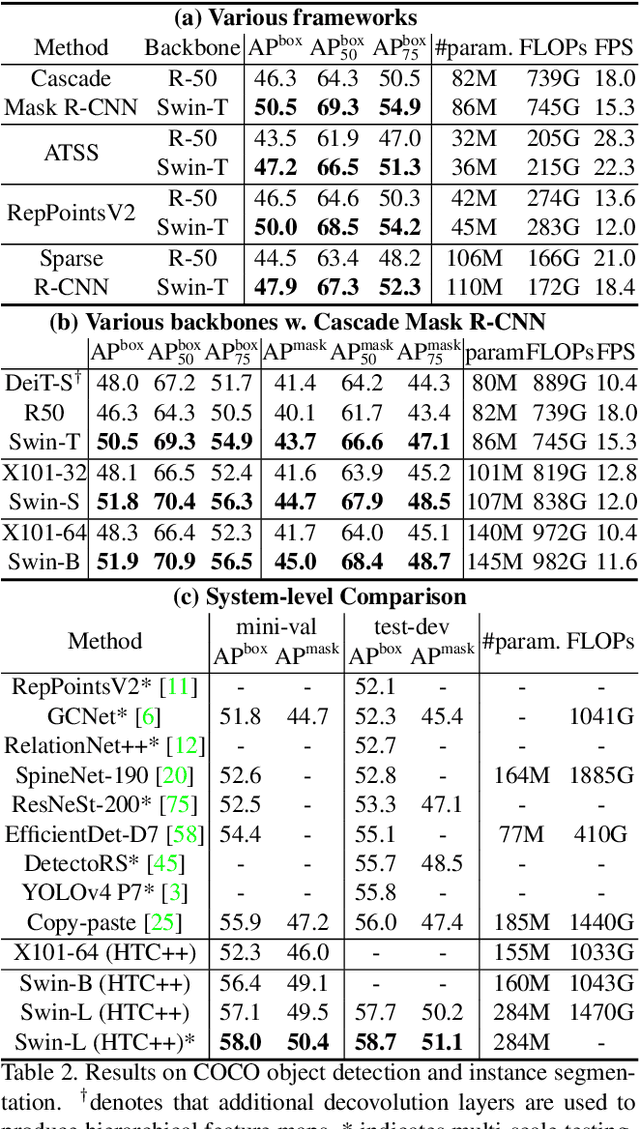
This paper presents a new vision Transformer, called Swin Transformer, that capably serves as a general-purpose backbone for computer vision. Challenges in adapting Transformer from language to vision arise from differences between the two domains, such as large variations in the scale of visual entities and the high resolution of pixels in images compared to words in text. To address these differences, we propose a hierarchical Transformer whose representation is computed with shifted windows. The shifted windowing scheme brings greater efficiency by limiting self-attention computation to non-overlapping local windows while also allowing for cross-window connection. This hierarchical architecture has the flexibility to model at various scales and has linear computational complexity with respect to image size. These qualities of Swin Transformer make it compatible with a broad range of vision tasks, including image classification (86.4 top-1 accuracy on ImageNet-1K) and dense prediction tasks such as object detection (58.7 box AP and 51.1 mask AP on COCO test-dev) and semantic segmentation (53.5 mIoU on ADE20K val). Its performance surpasses the previous state-of-the-art by a large margin of +2.7 box AP and +2.6 mask AP on COCO, and +3.2 mIoU on ADE20K, demonstrating the potential of Transformer-based models as vision backbones. The code and models will be made publicly available at~\url{https://github.com/microsoft/Swin-Transformer}.
Instance Localization for Self-supervised Detection Pretraining
Feb 16, 2021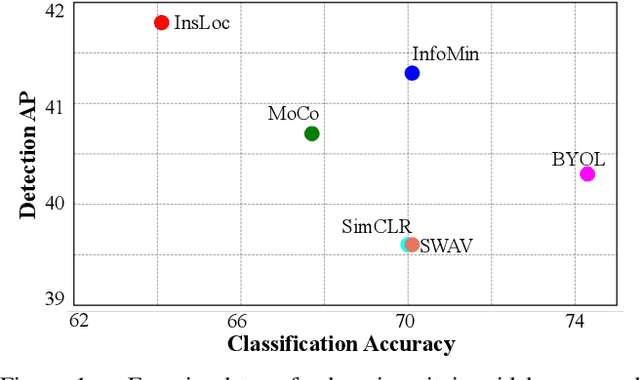
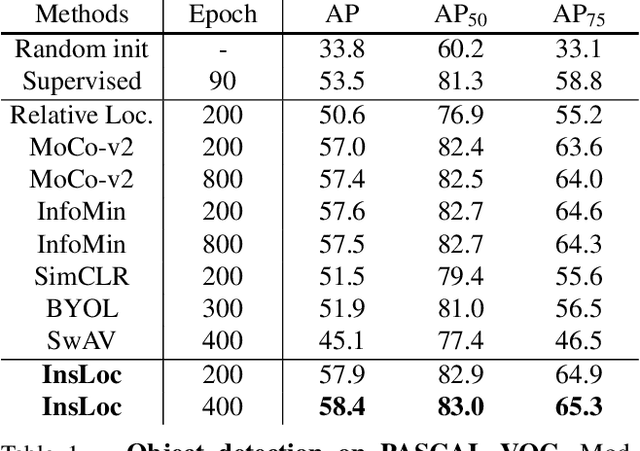
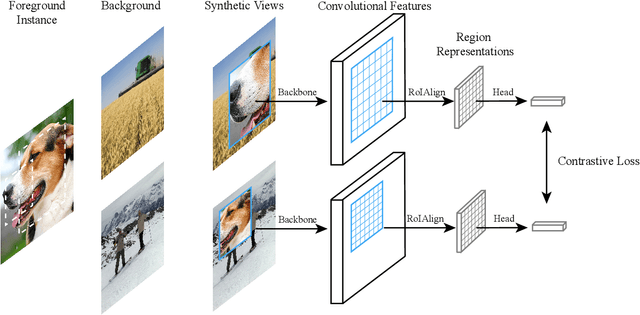
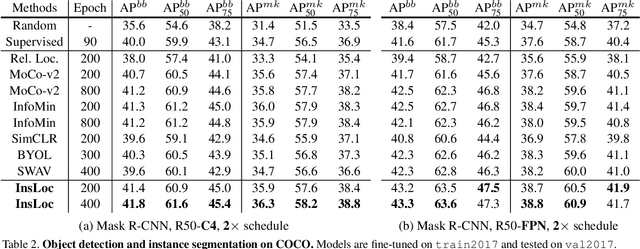
Prior research on self-supervised learning has led to considerable progress on image classification, but often with degraded transfer performance on object detection. The objective of this paper is to advance self-supervised pretrained models specifically for object detection. Based on the inherent difference between classification and detection, we propose a new self-supervised pretext task, called instance localization. Image instances are pasted at various locations and scales onto background images. The pretext task is to predict the instance category given the composited images as well as the foreground bounding boxes. We show that integration of bounding boxes into pretraining promotes better task alignment and architecture alignment for transfer learning. In addition, we propose an augmentation method on the bounding boxes to further enhance the feature alignment. As a result, our model becomes weaker at Imagenet semantic classification but stronger at image patch localization, with an overall stronger pretrained model for object detection. Experimental results demonstrate that our approach yields state-of-the-art transfer learning results for object detection on PASCAL VOC and MSCOCO.
Learning Monocular Depth in Dynamic Scenes via Instance-Aware Projection Consistency
Feb 04, 2021

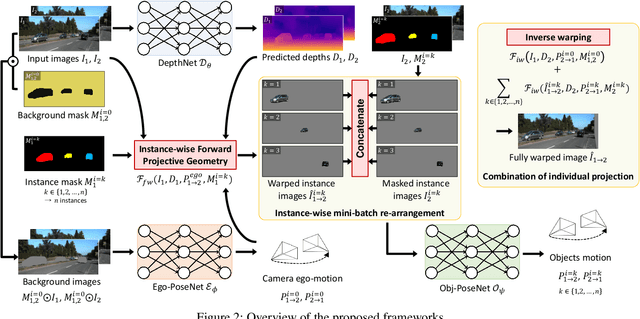
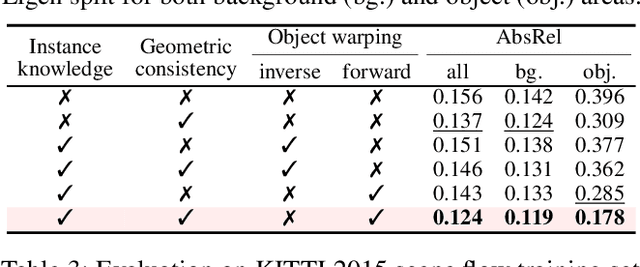
We present an end-to-end joint training framework that explicitly models 6-DoF motion of multiple dynamic objects, ego-motion and depth in a monocular camera setup without supervision. Our technical contributions are three-fold. First, we highlight the fundamental difference between inverse and forward projection while modeling the individual motion of each rigid object, and propose a geometrically correct projection pipeline using a neural forward projection module. Second, we design a unified instance-aware photometric and geometric consistency loss that holistically imposes self-supervisory signals for every background and object region. Lastly, we introduce a general-purpose auto-annotation scheme using any off-the-shelf instance segmentation and optical flow models to produce video instance segmentation maps that will be utilized as input to our training pipeline. These proposed elements are validated in a detailed ablation study. Through extensive experiments conducted on the KITTI and Cityscapes dataset, our framework is shown to outperform the state-of-the-art depth and motion estimation methods. Our code, dataset, and models are available at https://github.com/SeokjuLee/Insta-DM .
Global Context Networks
Dec 24, 2020
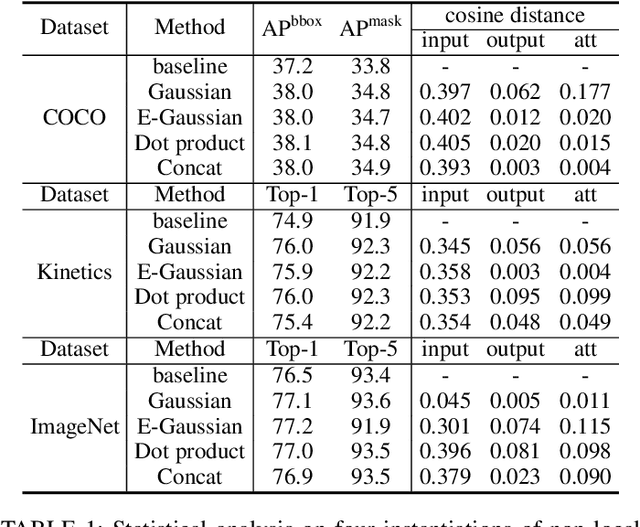

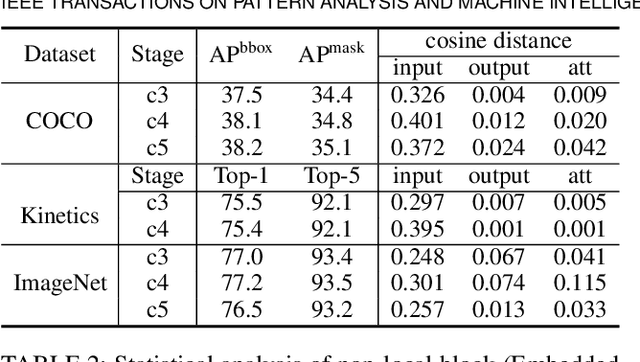
The Non-Local Network (NLNet) presents a pioneering approach for capturing long-range dependencies within an image, via aggregating query-specific global context to each query position. However, through a rigorous empirical analysis, we have found that the global contexts modeled by the non-local network are almost the same for different query positions. In this paper, we take advantage of this finding to create a simplified network based on a query-independent formulation, which maintains the accuracy of NLNet but with significantly less computation. We further replace the one-layer transformation function of the non-local block by a two-layer bottleneck, which further reduces the parameter number considerably. The resulting network element, called the global context (GC) block, effectively models global context in a lightweight manner, allowing it to be applied at multiple layers of a backbone network to form a global context network (GCNet). Experiments show that GCNet generally outperforms NLNet on major benchmarks for various recognition tasks. The code and network configurations are available at https://github.com/xvjiarui/GCNet.
Propagate Yourself: Exploring Pixel-Level Consistency for Unsupervised Visual Representation Learning
Nov 19, 2020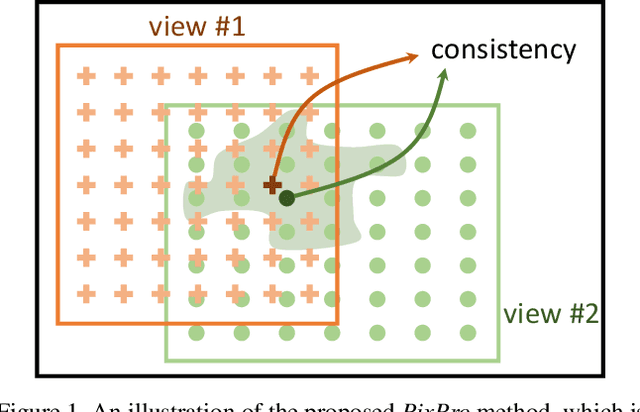
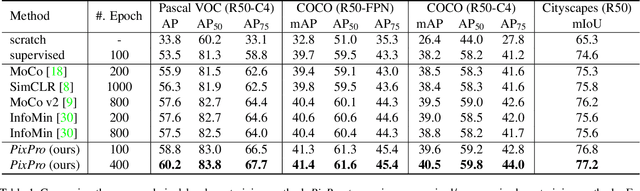
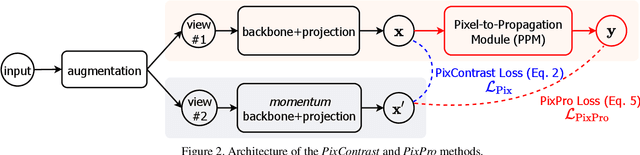
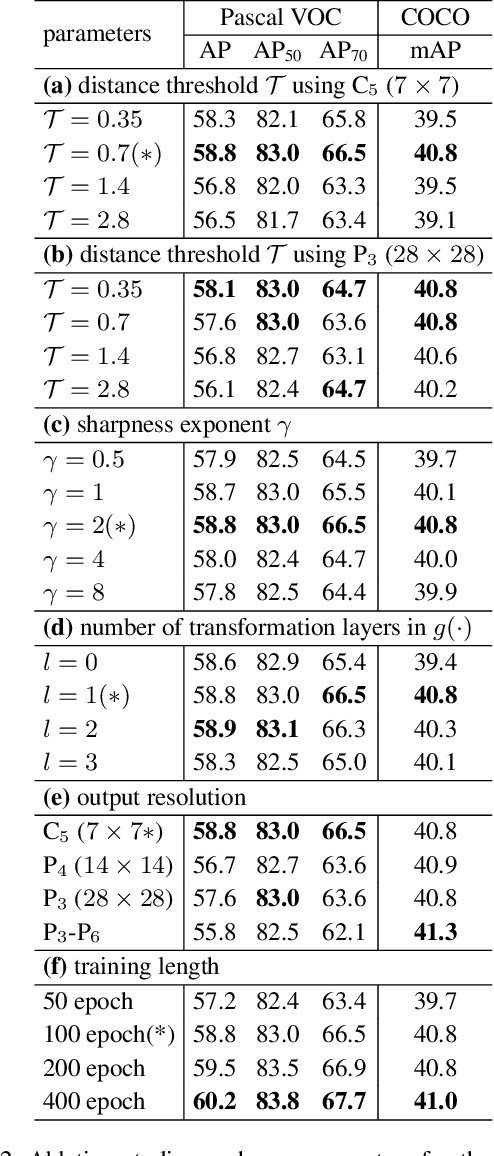
Contrastive learning methods for unsupervised visual representation learning have reached remarkable levels of transfer performance. We argue that the power of contrastive learning has yet to be fully unleashed, as current methods are trained only on instance-level pretext tasks, leading to representations that may be sub-optimal for downstream tasks requiring dense pixel predictions. In this paper, we introduce pixel-level pretext tasks for learning dense feature representations. The first task directly applies contrastive learning at the pixel level. We additionally propose a pixel-to-propagation consistency task that produces better results, even surpassing the state-of-the-art approaches by a large margin. Specifically, it achieves 60.2 AP, 41.4 / 40.5 mAP and 77.2 mIoU when transferred to Pascal VOC object detection (C4), COCO object detection (FPN / C4) and Cityscapes semantic segmentation using a ResNet-50 backbone network, which are 2.6 AP, 0.8 / 1.0 mAP and 1.0 mIoU better than the previous best methods built on instance-level contrastive learning. Moreover, the pixel-level pretext tasks are found to be effective for pre-training not only regular backbone networks but also head networks used for dense downstream tasks, and are complementary to instance-level contrastive methods. These results demonstrate the strong potential of defining pretext tasks at the pixel level, and suggest a new path forward in unsupervised visual representation learning.
Object-based Illumination Estimation with Rendering-aware Neural Networks
Aug 06, 2020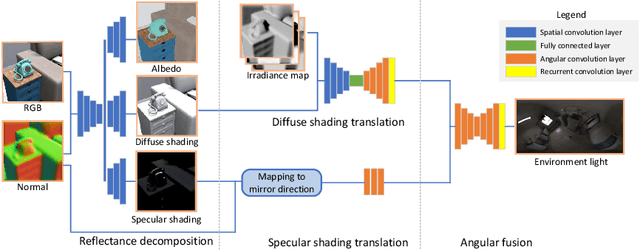
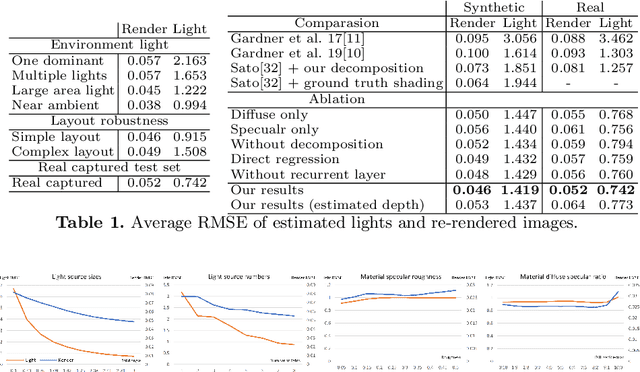


We present a scheme for fast environment light estimation from the RGBD appearance of individual objects and their local image areas. Conventional inverse rendering is too computationally demanding for real-time applications, and the performance of purely learning-based techniques may be limited by the meager input data available from individual objects. To address these issues, we propose an approach that takes advantage of physical principles from inverse rendering to constrain the solution, while also utilizing neural networks to expedite the more computationally expensive portions of its processing, to increase robustness to noisy input data as well as to improve temporal and spatial stability. This results in a rendering-aware system that estimates the local illumination distribution at an object with high accuracy and in real time. With the estimated lighting, virtual objects can be rendered in AR scenarios with shading that is consistent to the real scene, leading to improved realism.
Detecting Human-Object Interactions with Action Co-occurrence Priors
Jul 27, 2020
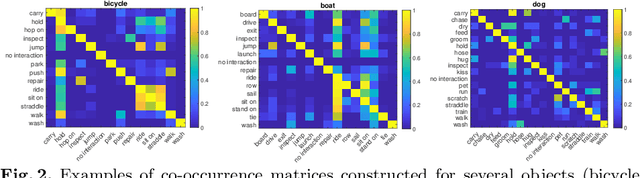
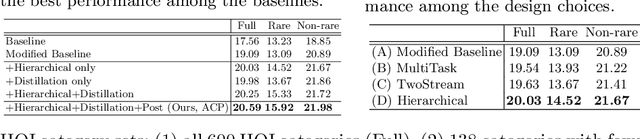
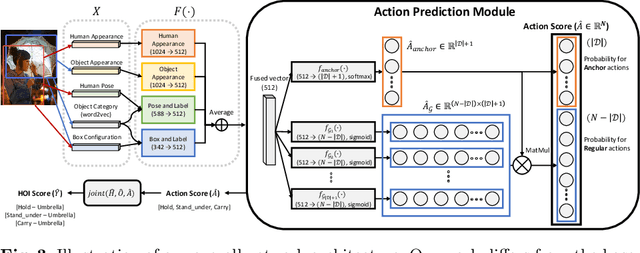
A common problem in human-object interaction (HOI) detection task is that numerous HOI classes have only a small number of labeled examples, resulting in training sets with a long-tailed distribution. The lack of positive labels can lead to low classification accuracy for these classes. Towards addressing this issue, we observe that there exist natural correlations and anti-correlations among human-object interactions. In this paper, we model the correlations as action co-occurrence matrices and present techniques to learn these priors and leverage them for more effective training, especially in rare classes. The utility of our approach is demonstrated experimentally, where the performance of our approach exceeds the state-of-the-art methods on both of the two leading HOI detection benchmark datasets, HICO-Det and V-COCO.
SRNet: Improving Generalization in 3D Human Pose Estimation with a Split-and-Recombine Approach
Jul 18, 2020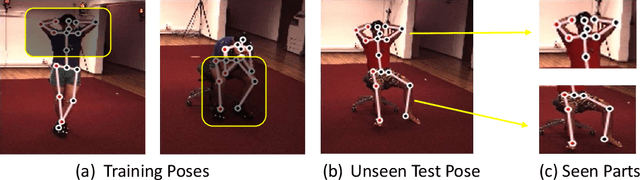
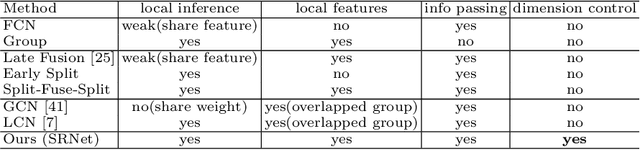

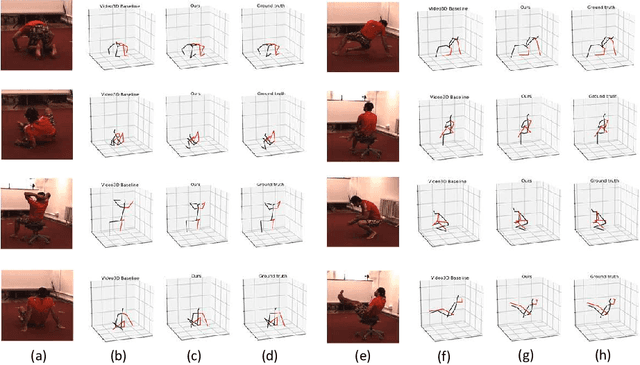
Human poses that are rare or unseen in a training set are challenging for a network to predict. Similar to the long-tailed distribution problem in visual recognition, the small number of examples for such poses limits the ability of networks to model them. Interestingly, local pose distributions suffer less from the long-tail problem, i.e., local joint configurations within a rare pose may appear within other poses in the training set, making them less rare. We propose to take advantage of this fact for better generalization to rare and unseen poses. To be specific, our method splits the body into local regions and processes them in separate network branches, utilizing the property that a joint position depends mainly on the joints within its local body region. Global coherence is maintained by recombining the global context from the rest of the body into each branch as a low-dimensional vector. With the reduced dimensionality of less relevant body areas, the training set distribution within network branches more closely reflects the statistics of local poses instead of global body poses, without sacrificing information important for joint inference. The proposed split-and-recombine approach, called SRNet, can be easily adapted to both single-image and temporal models, and it leads to appreciable improvements in the prediction of rare and unseen poses.
RepPoints V2: Verification Meets Regression for Object Detection
Jul 16, 2020
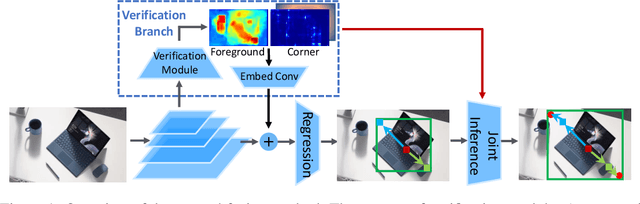
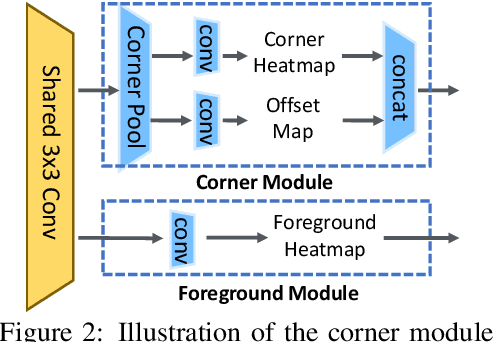
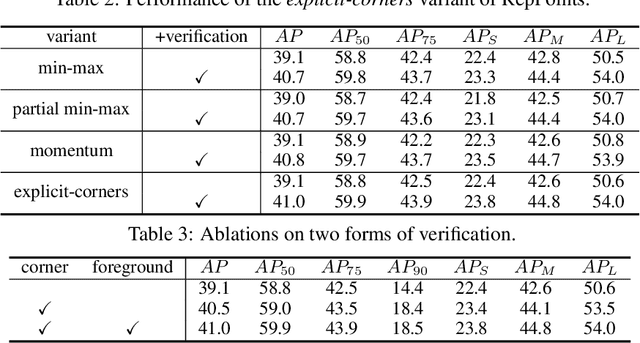
Verification and regression are two general methodologies for prediction in neural networks. Each has its own strengths: verification can be easier to infer accurately, and regression is more efficient and applicable to continuous target variables. Hence, it is often beneficial to carefully combine them to take advantage of their benefits. In this paper, we take this philosophy to improve state-of-the-art object detection, specifically by RepPoints. Though RepPoints provides high performance, we find that its heavy reliance on regression for object localization leaves room for improvement. We introduce verification tasks into the localization prediction of RepPoints, producing RepPoints v2, which provides consistent improvements of about 2.0 mAP over the original RepPoints on the COCO object detection benchmark using different backbones and training methods. RepPoints v2 also achieves 52.1 mAP on COCO \texttt{test-dev} by a single model. Moreover, we show that the proposed approach can more generally elevate other object detection frameworks as well as applications such as instance segmentation. The code is available at https://github.com/Scalsol/RepPointsV2.
Point-Set Anchors for Object Detection, Instance Segmentation and Pose Estimation
Jul 14, 2020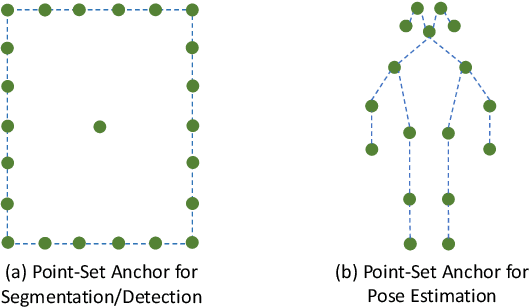

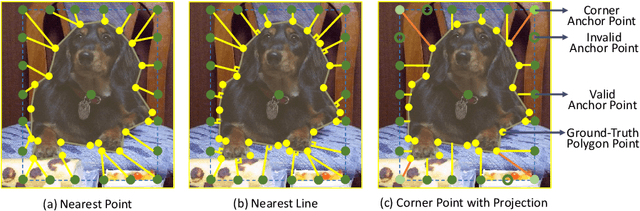

A recent approach for object detection and human pose estimation is to regress bounding boxes or human keypoints from a central point on the object or person. While this center-point regression is simple and efficient, we argue that the image features extracted at a central point contain limited information for predicting distant keypoints or bounding box boundaries, due to object deformation and scale/orientation variation. To facilitate inference, we propose to instead perform regression from a set of points placed at more advantageous positions. This point set is arranged to reflect a good initialization for the given task, such as modes in the training data for pose estimation, which lie closer to the ground truth than the central point and provide more informative features for regression. As the utility of a point set depends on how well its scale, aspect ratio and rotation matches the target, we adopt the anchor box technique of sampling these transformations to generate additional point-set candidates. We apply this proposed framework, called Point-Set Anchors, to object detection, instance segmentation, and human pose estimation. Our results show that this general-purpose approach can achieve performance competitive with state-of-the-art methods for each of these tasks.