 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWaypoint Planning Networks
May 01, 2021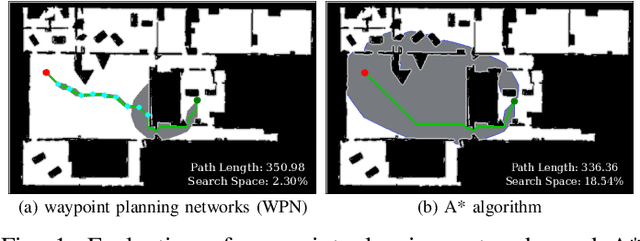
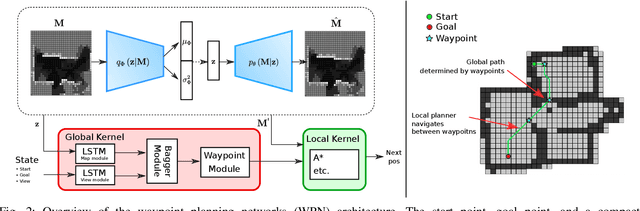
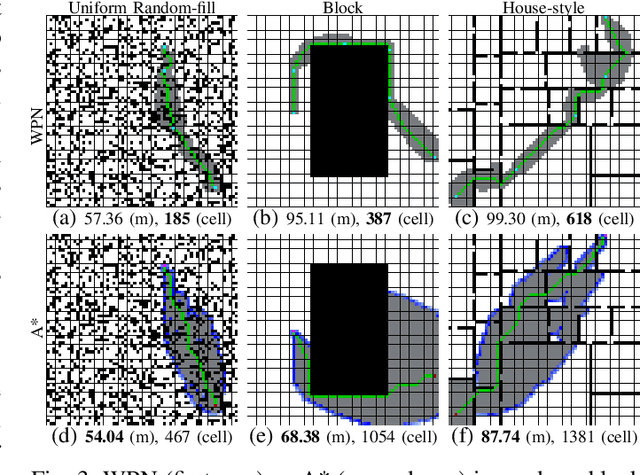
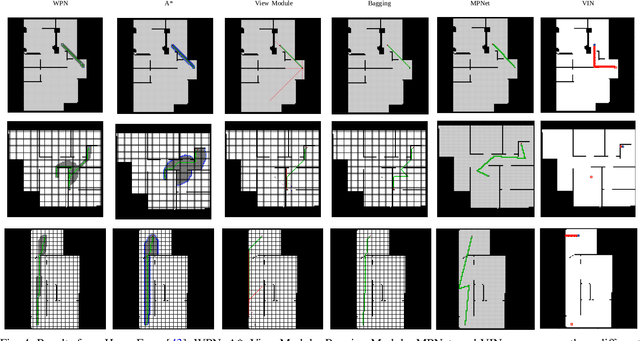
With the recent advances in machine learning, path planning algorithms are also evolving; however, the learned path planning algorithms often have difficulty competing with success rates of classic algorithms. We propose waypoint planning networks (WPN), a hybrid algorithm based on LSTMs with a local kernel - a classic algorithm such as A*, and a global kernel using a learned algorithm. WPN produces a more computationally efficient and robust solution. We compare WPN against A*, as well as related works including motion planning networks (MPNet) and value iteration networks (VIN). In this paper, the design and experiments have been conducted for 2D environments. Experimental results outline the benefits of WPN, both in efficiency and generalization. It is shown that WPN's search space is considerably less than A*, while being able to generate near optimal results. Additionally, WPN works on partial maps, unlike A* which needs the full map in advance. The code is available online.
SIMstack: A Generative Shape and Instance Model for Unordered Object Stacks
Mar 30, 2021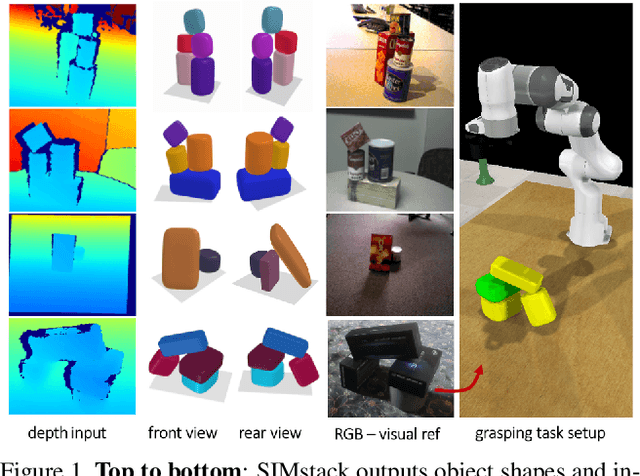
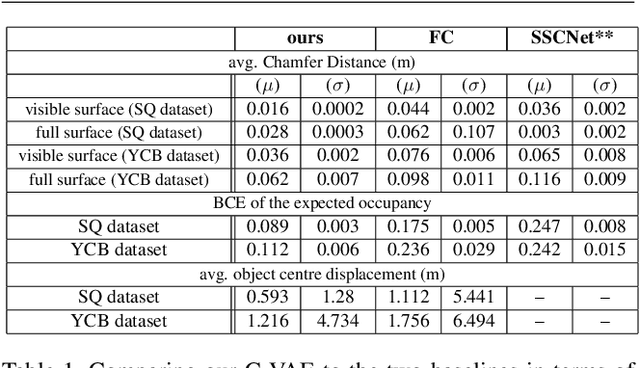
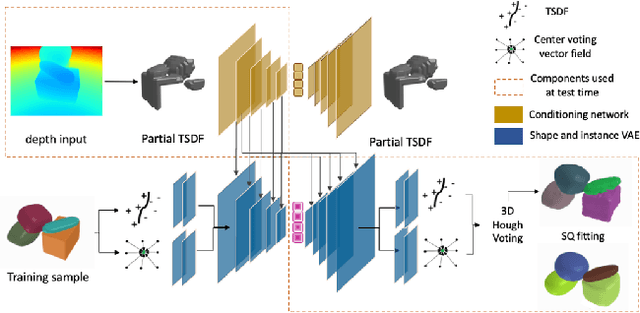

By estimating 3D shape and instances from a single view, we can capture information about an environment quickly, without the need for comprehensive scanning and multi-view fusion. Solving this task for composite scenes (such as object stacks) is challenging: occluded areas are not only ambiguous in shape but also in instance segmentation; multiple decompositions could be valid. We observe that physics constrains decomposition as well as shape in occluded regions and hypothesise that a latent space learned from scenes built under physics simulation can serve as a prior to better predict shape and instances in occluded regions. To this end we propose SIMstack, a depth-conditioned Variational Auto-Encoder (VAE), trained on a dataset of objects stacked under physics simulation. We formulate instance segmentation as a centre voting task which allows for class-agnostic detection and doesn't require setting the maximum number of objects in the scene. At test time, our model can generate 3D shape and instance segmentation from a single depth view, probabilistically sampling proposals for the occluded region from the learned latent space. Our method has practical applications in providing robots some of the ability humans have to make rapid intuitive inferences of partially observed scenes. We demonstrate an application for precise (non-disruptive) object grasping of unknown objects from a single depth view.
End-to-End Egospheric Spatial Memory
Feb 17, 2021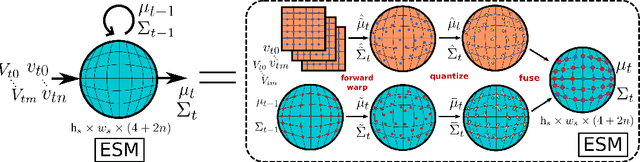
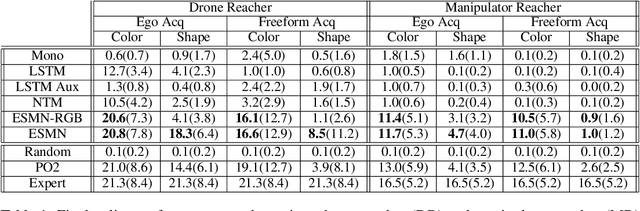
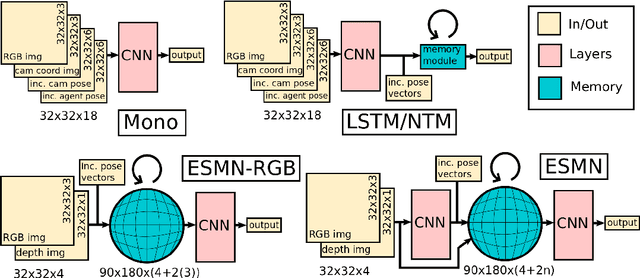
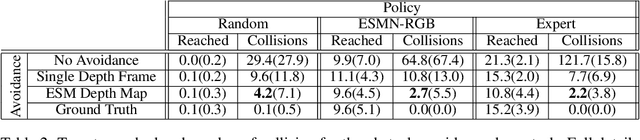
Spatial memory, or the ability to remember and recall specific locations and objects, is central to autonomous agents' ability to carry out tasks in real environments. However, most existing artificial memory modules are not very adept at storing spatial information. We propose a parameter-free module, Egospheric Spatial Memory (ESM), which encodes the memory in an ego-sphere around the agent, enabling expressive 3D representations. ESM can be trained end-to-end via either imitation or reinforcement learning, and improves both training efficiency and final performance against other memory baselines on both drone and manipulator visuomotor control tasks. The explicit egocentric geometry also enables us to seamlessly combine the learned controller with other non-learned modalities, such as local obstacle avoidance. We further show applications to semantic segmentation on the ScanNet dataset, where ESM naturally combines image-level and map-level inference modalities. Through our broad set of experiments, we show that ESM provides a general computation graph for embodied spatial reasoning, and the module forms a bridge between real-time mapping systems and differentiable memory architectures. Implementation at: https://github.com/ivy-dl/memory.
Ivy: Templated Deep Learning for Inter-Framework Portability
Feb 15, 2021

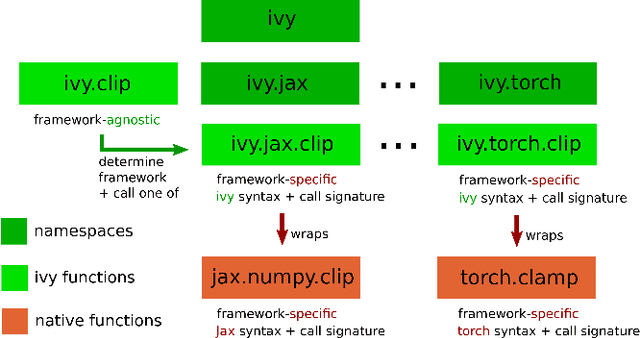

We introduce Ivy, a templated Deep Learning (DL) framework which abstracts existing DL frameworks such that their core functions all exhibit consistent call signatures, syntax and input-output behaviour. Ivy allows high-level framework-agnostic functions to be implemented through the use of framework templates. The framework templates act as placeholders for the specific framework at development time, which are then determined at runtime. The portability of Ivy functions enables their use in projects of any supported framework. Ivy currently supports TensorFlow, PyTorch, MXNet, Jax and NumPy. Alongside Ivy, we release four pure-Ivy libraries for mechanics, 3D vision, robotics, and differentiable environments. Through our evaluations, we show that Ivy can significantly reduce lines of code with a runtime overhead of less than 1% in most cases. We welcome developers to join the Ivy community by writing their own functions, layers and libraries in Ivy, maximizing their audience and helping to accelerate DL research through the creation of lifelong inter-framework codebases. More information can be found at https://ivy-dl.org.
MoreFusion: Multi-object Reasoning for 6D Pose Estimation from Volumetric Fusion
Apr 09, 2020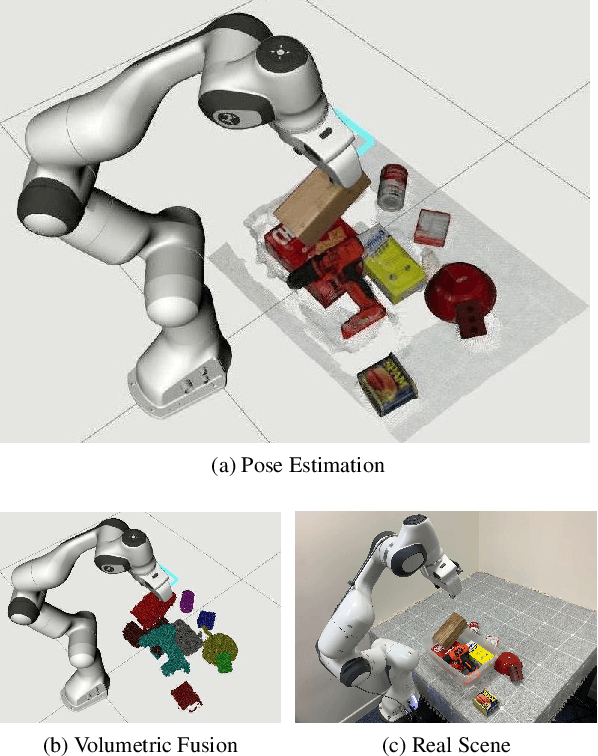
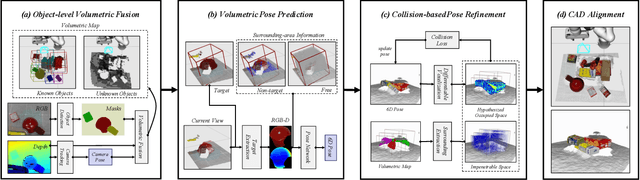
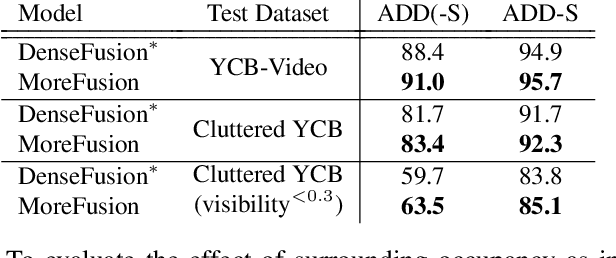

Robots and other smart devices need efficient object-based scene representations from their on-board vision systems to reason about contact, physics and occlusion. Recognized precise object models will play an important role alongside non-parametric reconstructions of unrecognized structures. We present a system which can estimate the accurate poses of multiple known objects in contact and occlusion from real-time, embodied multi-view vision. Our approach makes 3D object pose proposals from single RGB-D views, accumulates pose estimates and non-parametric occupancy information from multiple views as the camera moves, and performs joint optimization to estimate consistent, non-intersecting poses for multiple objects in contact. We verify the accuracy and robustness of our approach experimentally on 2 object datasets: YCB-Video, and our own challenging Cluttered YCB-Video. We demonstrate a real-time robotics application where a robot arm precisely and orderly disassembles complicated piles of objects, using only on-board RGB-D vision.
Learning One-Shot Imitation from Humans without Humans
Nov 04, 2019
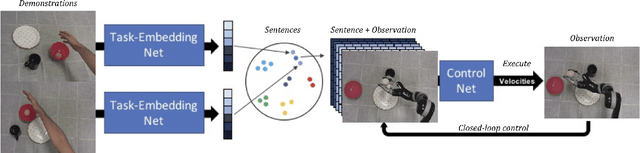

Humans can naturally learn to execute a new task by seeing it performed by other individuals once, and then reproduce it in a variety of configurations. Endowing robots with this ability of imitating humans from third person is a very immediate and natural way of teaching new tasks. Only recently, through meta-learning, there have been successful attempts to one-shot imitation learning from humans; however, these approaches require a lot of human resources to collect the data in the real world to train the robot. But is there a way to remove the need for real world human demonstrations during training? We show that with Task-Embedded Control Networks, we can infer control polices by embedding human demonstrations that can condition a control policy and achieve one-shot imitation learning. Importantly, we do not use a real human arm to supply demonstrations during training, but instead leverage domain randomisation in an application that has not been seen before: sim-to-real transfer on humans. Upon evaluating our approach on pushing and placing tasks in both simulation and in the real world, we show that in comparison to a system that was trained on real-world data we are able to achieve similar results by utilising only simulation data.
RLBench: The Robot Learning Benchmark & Learning Environment
Sep 26, 2019
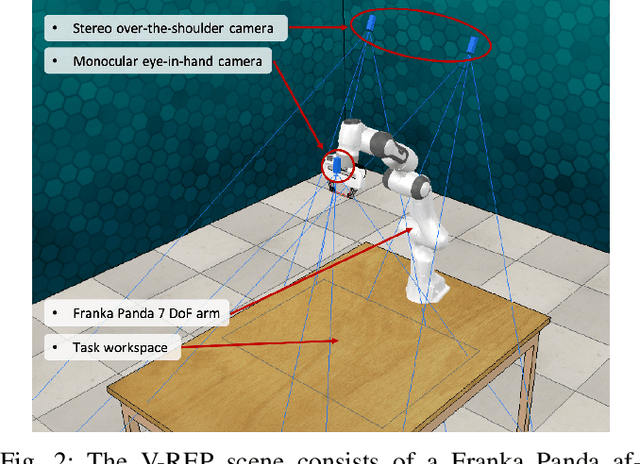
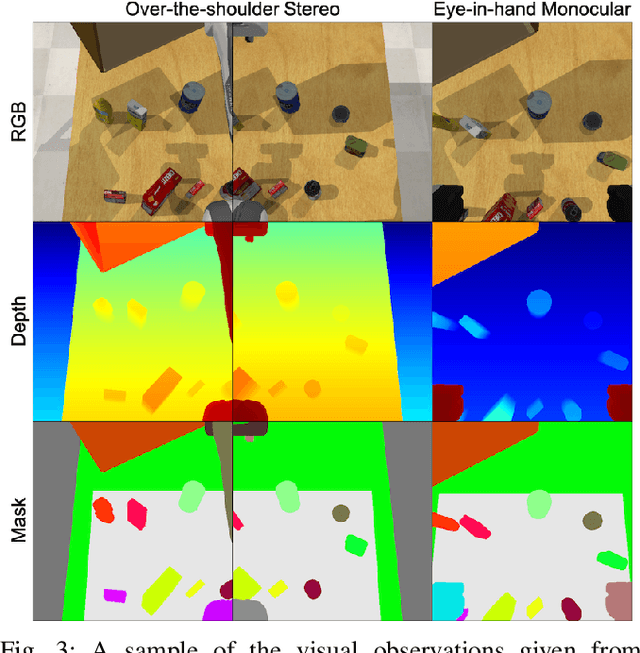
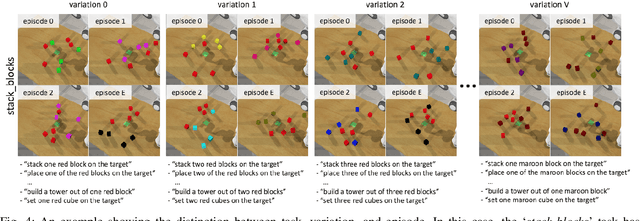
We present a challenging new benchmark and learning-environment for robot learning: RLBench. The benchmark features 100 completely unique, hand-designed tasks ranging in difficulty, from simple target reaching and door opening, to longer multi-stage tasks, such as opening an oven and placing a tray in it. We provide an array of both proprioceptive observations and visual observations, which include rgb, depth, and segmentation masks from an over-the-shoulder stereo camera and an eye-in-hand monocular camera. Uniquely, each task comes with an infinite supply of demos through the use of motion planners operating on a series of waypoints given during task creation time; enabling an exciting flurry of demonstration-based learning. RLBench has been designed with scalability in mind; new tasks, along with their motion-planned demos, can be easily created and then verified by a series of tools, allowing users to submit their own tasks to the RLBench task repository. This large-scale benchmark aims to accelerate progress in a number of vision-guided manipulation research areas, including: reinforcement learning, imitation learning, multi-task learning, geometric computer vision, and in particular, few-shot learning. With the benchmark's breadth of tasks and demonstrations, we propose the first large-scale few-shot challenge in robotics. We hope that the scale and diversity of RLBench offers unparalleled research opportunities in the robot learning community and beyond.
PyRep: Bringing V-REP to Deep Robot Learning
Jun 26, 2019

PyRep is a toolkit for robot learning research, built on top of the virtual robotics experimentation platform (V-REP). Through a series of modifications and additions, we have created a tailored version of V-REP built with robot learning in mind. The new PyRep toolkit offers three improvements: (1) a simple and flexible API for robot control and scene manipulation, (2) a new rendering engine, and (3) speed boosts upwards of 10,000x in comparison to the previous Python Remote API. With these improvements, we believe PyRep is the ideal toolkit to facilitate rapid prototyping of learning algorithms in the areas of reinforcement learning, imitation learning, state estimation, mapping, and computer vision.
Sim-to-Real via Sim-to-Sim: Data-efficient Robotic Grasping via Randomized-to-Canonical Adaptation Networks
Mar 25, 2019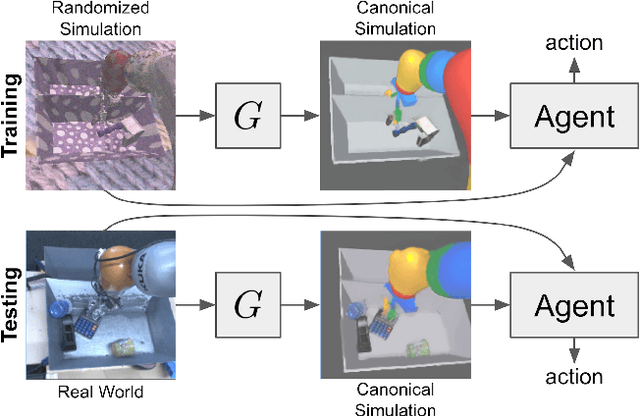
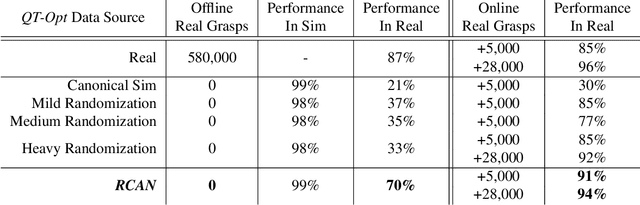


Real world data, especially in the domain of robotics, is notoriously costly to collect. One way to circumvent this can be to leverage the power of simulation to produce large amounts of labelled data. However, training models on simulated images does not readily transfer to real-world ones. Using domain adaptation methods to cross this "reality gap" requires a large amount of unlabelled real-world data, whilst domain randomization alone can waste modeling power. In this paper, we present Randomized-to-Canonical Adaptation Networks (RCANs), a novel approach to crossing the visual reality gap that uses no real-world data. Our method learns to translate randomized rendered images into their equivalent non-randomized, canonical versions. This in turn allows for real images to also be translated into canonical sim images. We demonstrate the effectiveness of this sim-to-real approach by training a vision-based closed-loop grasping reinforcement learning agent in simulation, and then transferring it to the real world to attain 70% zero-shot grasp success on unseen objects, a result that almost doubles the success of learning the same task directly on domain randomization alone. Additionally, by joint finetuning in the real-world with only 5,000 real-world grasps, our method achieves 91%, attaining comparable performance to a state-of-the-art system trained with 580,000 real-world grasps, resulting in a reduction of real-world data by more than 99%.
Sim-to-Real Reinforcement Learning for Deformable Object Manipulation
Oct 08, 2018


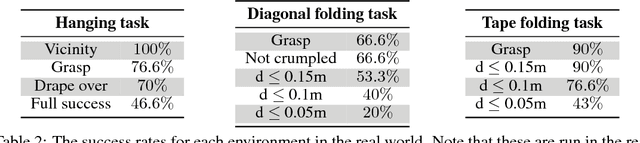
We have seen much recent progress in rigid object manipulation, but interaction with deformable objects has notably lagged behind. Due to the large configuration space of deformable objects, solutions using traditional modelling approaches require significant engineering work. Perhaps then, bypassing the need for explicit modelling and instead learning the control in an end-to-end manner serves as a better approach? Despite the growing interest in the use of end-to-end robot learning approaches, only a small amount of work has focused on their applicability to deformable object manipulation. Moreover, due to the large amount of data needed to learn these end-to-end solutions, an emerging trend is to learn control policies in simulation and then transfer them over to the real world. To-date, no work has explored whether it is possible to learn and transfer deformable object policies. We believe that if sim-to-real methods are to be employed further, then it should be possible to learn to interact with a wide variety of objects, and not only rigid objects. In this work, we use a combination of state-of-the-art deep reinforcement learning algorithms to solve the problem of manipulating deformable objects (specifically cloth). We evaluate our approach on three tasks --- folding a towel up to a mark, folding a face towel diagonally, and draping a piece of cloth over a hanger. Our agents are fully trained in simulation with domain randomisation, and then successfully deployed in the real world without having seen any real deformable objects.